目录
- PTQ与QAT
- 前言
- 1. TensorRT量化
- 2. PTQ
- 3. QAT
- 4. QAT实战
- 4.1 环境配置
- 4.2 pytorch_quantization简单示例
- 4.3 自动插入QDQ节点
- 总结
PTQ与QAT
前言
手写AI推出的全新TensorRT模型量化课程,链接。记录下个人学习笔记,仅供自己参考。
本次课程为第四课,主要讲解PTQ与QAT。这里推荐一篇文章 量化番外篇-TensorRT-8的量化细节 以下大部分内容都是 copy 自它,强烈建议阅读原文!!!
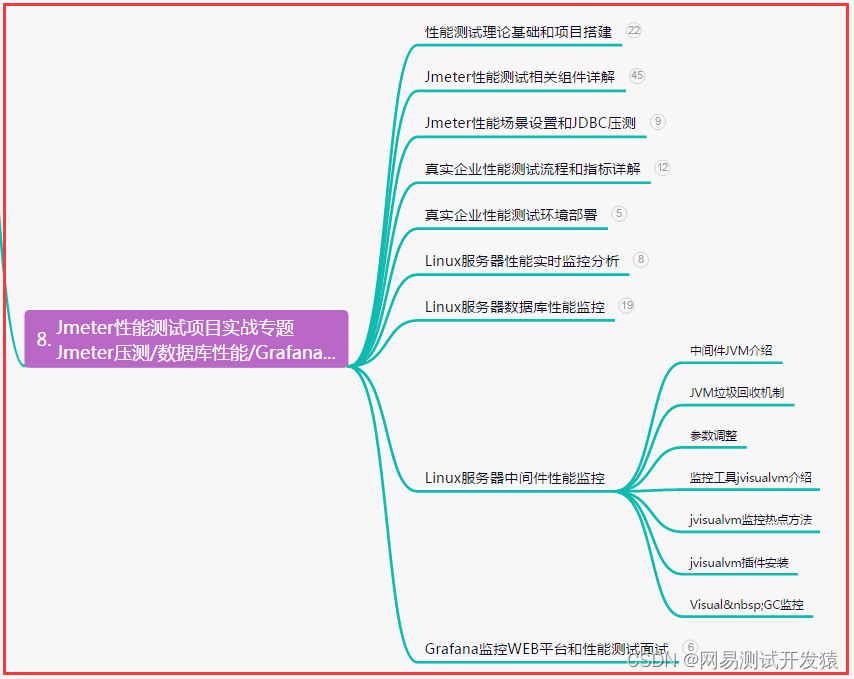
课程大纲可看下面的思维导图

1. TensorRT量化
TensorRT有两种量化模式,分别是 implicitly 以及 explicitly 量化。前者是隐式量化,在 trt7 版本之前用的比较多。而后者是显示量化,在 trt8 版本后才完全支持,具体就是可以加载带有 QDQ 信息的模型然后生成对应量化版本的 engine。
2. PTQ
PTQ(Post-Training Quantization) 即训练后量化也叫隐式量化,tensorRT 的训练后量化算法第一次公布在 2017 年,NVIDIA 放出了使用交叉熵量化的一个 PPT,简单说明了其量化原理和流程,其思想集中在 tensorRT 内部可供用户去使用。对用户是闭源的,我们只能通过 tensorRT 提供的 API 去量化。
PTQ 量化不需要训练,只需要提供一些样本图片,然后在已经训练好的模型上进行校准,统计出来需要的每一层的 scale 就可以实现量化了,大概流程如下:
- 在准备好的校准数据集上评估预训练模型
- 使用校准数据来校准模型(校准数据可以是训练集的子集)
- 计算网络中权重和激活的动态范围用来算出量化参数(q-params)
- 使用 q-params 量化网络并执行推理

具体使用就是我们导出 ONNX 模型,转换为 engine 的过程中使用 tensorRT 提供的 Calibration 方法去校准,这个使用起来比较简单。可以直接使用 tensorRT 官方提供的 trtexec 工具去实现,也可以使用它提供的 Python 或者 C++ 的 API 接口去实现。
目前 tensorRT 提供了多种校准方法,分别适合于不同的任务:
- EntropyCalibratorV2
- 适合于基于 CNN 的网络
Entropy calibration chooses the tensor’s scale factor to optimize the quantized tensor’s information-theoretic content, and usually suppresses outliers in the distribution. This is the current and recommended entropy calibrator and is required for DLA. Calibration happens before Layer fusion by default. It is recommended for CNN-based networks.
- MinMaxCalibrator
- 适合于 NLP 任务,如BERT
This calibrator uses the entire range of the activation distribution to determine the scale factor. It seems to work better for NLP tasks. Calibration happens before Layer fusion by default. This is recommended for networks such as NVIDIA BERT (an optimized version of Google’s official implementation).
- EntropyCalibrator
- 老版的 entropy calibrator
This is the original entropy calibrator. It is less complicated to use than the LegacyCalibrator and typically produces better results. Calibration happens after Layer fusion by default.
- LegacyCalibrator
This calibrator is for compatibility with TensorRT 2.0 EA. This calibrator requires user parameterization and is provided as a fallback option if the other calibrators yield poor results. Calibration happens after Layer fusion by default. You can customize this calibrator to implement percentile max, for example, 99.99% percentile max is observed to have best accuracy for NVIDIA BERT.
通过上述这些校准算法进行 PTQ 量化时,tensorRT 会在优化网络的时候尝试 INT8 精度,假设某一层在 INT8 精度下速度优于默认精度(FP32或者FP16),则有限使用 INT8。
值得注意的是,PTQ 量化中我们无法控制某一层的精度,因为 tensorRT 是以速度优化为优先的,很可能某一层你想让它跑 INT8 结果却是 FP16。当然 PTQ 优点是流程简单,速度快。
3. QAT
QAT(Quantization Aware Training) 即训练中量化也叫显式量化。它是 tensorRT8 的一个新特性,这个特性其实是指 tensorRT 有直接加载 QAT 模型的能力。而 QAT 模型在这里是指包含 QDQ 操作的量化模型,而 QDQ 操作就是指量化和反量化操作。
实际上 QAT 过程和 tensorRT 没有太大关系,tensorRT 只是一个推理框架,实际的训练中量化操作一般都是在训练框架中去做,比如我们熟悉的 Pytorch。(当然也不排除之后一些推理框架也会有训练功能,因此同样可以在推理框架中做)
tensorRT-8 可以显式地加载包含有 QAT 量化信息的 ONNX 模型,实现一系列优化后,可以生成 INT8 的 engine。
QAT 量化需要插入 QAT 算子且需要训练进行微调,大概流程如下
- 准备一个预训练模型
- 在模型中添加 QAT 算子
- 微调带有 QAT 算子的模型
- 将微调后模型的量化参数即 q-params 存储下来
- 量化模型执行推理

带有 QAT 量化信息的模型如下图所示:

从上图中我们可以看到带 QAT 量化信息的模型中有 QuantizeLinear 和 DequantizeLinear 模块,也就是对应的 QDQ 模块,它包含了该层和该激活值的量化 scale 和 zero-point。什么是 QDQ 呢?QDQ 其实就是 Q(量化) 和 DQ(反量化)两个 op,在网络中通常作为模拟量化的 op,如下图所示:

QDQ 模块会参与训练,负责将输入的 FP32 张量量化为 INT8,随后再进行反量化将 INT8 的张量再变为 FP32。值得注意的是,实际网络中训练使用的精度还是 FP32,只不过这个量化算子在训练中可以学习到量化和反量化的尺度信息,这样训练的时候就可以让模型权重和量化参数更好地适应量化过程(scale参数也是可以学习的),量化后地精度也相对更高一些。
QAT 量化中最重要的就是 FQ(Fake-Quan) 量化算子即 QDQ 算子,它负责将输入该算子的参数先进行量化操作然后进行反量化操作,记录其中的 scale,具体可见下图3-4
假设现在我们有一个网络,其精度是 FP32 即输入和权重是 FP32:

我们可以在模型中插入 FQ 算子,它会将 FP32 精度的输入和权重转化为 INT8 再转回 FP32,并记住转换过程中的尺度信息:

而这些 FQ 算子在 ONNX 模型中可以表示为 QDQ 算子:

那么 QDQ 算子到底做了什么事情呢?其实就是我们之前提到的量化和反量化过程,假设输入为 3x3,其 QDQ 算子会做如下计算:

QDQ 的用途主要体现在两方面:
- 第一个是可以存储量化信息,比如 scale 和 zero_point,这些信息可以放在 Q 和 DQ 操作中
- 第二个是可以当作是显示指定哪一层是量化层,我们可以默认认为包在 QDQ 操作中间的 op 都是 INT8 类型的 op,也就是我们需要量化的 op
比如下图,可以通过 QDQ 的位置来决定每一层 op 的精度:

因此对比显式量化(explicitly),tensorRT的隐式量化(implicitly)就没有那么直接,在 tensorRT-8 版本之前我们一般都是借助 tensorRT 的内部量化算法去量化(闭源),在构建 engine 的时候传入图像进行校准,执行的是训练后量化(PTQ)的过程。
而有了 QDQ 信息,tensorRT 在解析模型的时候会根据 QDQ 的位置找到可量化的 op,然后与 QDQ 融合(吸收尺度信息到 op 中):

融合后的算子就是实打实的 INT8 算子,经过一系列的融合优化后,最终生成量化版的 engine:

总的来说,tensorRT 加载 QAT 的 ONNX 模型并进行优化的总体流程如下:

因为 tensorRT8 可以直接加载通过 QAT 量化后导出为 onnx 的模型,官方也提供了 Pytorch 量化配套工具,可谓是一步到位。
tensorRT 的量化性能是非常好的,可能有些模型或者 op 已经被其他库超越(比如openppl或者tvm),不过tensorRT 胜在支持的比较广泛,用户很多,大部分模型都有前人踩过坑,经验相对较多些,而且支持动态 shape,适用的场景也较多。
不过 tensorRT 也有缺点,就是自定义的 INT8 插件支持度不高,很多坑要踩,也就是自己添加新的 op 难度稍大一些。对于某些层不支持或者有 bug 的情况,除了在 issue 中催一下官方尽快更新之外,也没有其它办法了。
4. QAT实战
4.1 环境配置
本次代码参考自https://github.com/NVIDIA/TensorRT/tree/release/8.6/tools/pytorch-quantization
需要安装 pytorch-quantization 包来用于后续的工作,安装指令如下:
pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
4.2 pytorch_quantization简单示例
我们利用 pytorch-quantization 第三方库来写一个简单的示例,其代码如下:
from pytorch_quantization import tensor_quant
import torch
torch.manual_seed(123456)
x = torch.rand(10)
fake_x = tensor_quant.fake_tensor_quant(x, x.abs().max()) # FQ算子
print(x)
print(fake_x)
其输出如下:
tensor([0.5043, 0.8178, 0.4798, 0.9201, 0.6819, 0.6900, 0.6925, 0.3804, 0.4479,
0.4954])
tensor([0.5071, 0.8187, 0.4782, 0.9201, 0.6810, 0.6883, 0.6955, 0.3840, 0.4492,
0.4927])
上述示例代码利用 tensor_quant 模块中的 fake_tensor_quant 函数对输入的 tensor 进行 FQ 操作,即 QDQ 操作,其内部的具体实现就是我们之前课程中提到的对称量化.
4.3 自动插入QDQ节点
我们使用 pytorch-quantization 的 API 来实现对 resnet 网络所有节点的 QDQ 算子插入,其示例代码如下:
import torch
import torchvision
from pytorch_quantization import tensor_quant, quant_modules
from pytorch_quantization import nn as quant_nn
quant_modules.initialize()
model = torchvision.models.resnet18()
model.cuda()
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet18.onnx', opset_version=13)
上述示例代码通过指定 quant_nn.TensorQuantizer.use_fb_fake_quant 来将 resnet18 模型中的所有节点替换为 QDQ 算子,并导出为 ONNX 格式的模型文件,实现了模型的量化。值得注意的是:
quant_modules.initialize()函数会把 PyTorch-Quantization 库中所有的量化算子按照数据类型、位宽等特性进行分类,并将其保存在全局变量_DEFAULT_QUANT_MAP中- 导出的带有 QDQ 节点的 ONNX 模型中,对于输入 input 的整个 tensor 是共用一个 scale,而对于权重 weight 则是每个 channel 共用一个 scale
- 导出的带有 QDQ 节点的 ONNX 模型中,
x_zero_point是之前量化课程中提到的偏移量,其值为0,因为整个量化过程是对称量化,其偏移量 Z 为0
总结
本次课程介绍了 tensorRT 中两种量化模式即 PTQ 和 QAT,其中 PTQ 为训练后量化,在 tensorRT-7 版本之前比较流行,它主要通过校准方法利用校准数据对预训练后的模型进行量化,其流程简单、速度快,但是我们无法控制某一层的精度。QAT 为训练后量化,是 tensorRT-8 的一个新特性,即通过在训练过程中插入 QDQ 节点,然后量化过程中使用 QDQ 节点的 scale 等信息完成量化过程,QAT 量化较为麻烦,需要插入 QDQ 节点还需要微调,但是它的精度损失小且能够控制每一层的精度。
接着我们利用 pytorch-quantization 第三方库实现了对 resnet 网络自动插入 QDQ 节点,其中内部的整个量化过程其实就是我们之前课程中讲到的知识,包括对称量化、非对称量化,动态范围的选取等等,掌握之前的知识有利于我们更快的理解其 API 原理的实现,而不是仅仅做一个调包侠😂
下次课程我们将学习更多定制化的操作,比如量化过程中怎么根据自己的需求控制某些层需要去量化,某些层不需要;对于自定义的层又该如何去进行量化,期待下次课程!!!😄