任务1:数据预处理
表格数据资源如下百度网盘👇
链接:https://pan.baidu.com/s/1Ry8emM-daxoegF1di4FRyw 提取码:jimb
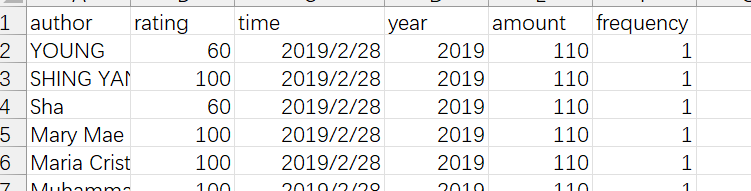
author:用户名rating:消费后打的分time:消费时间year:消费年份amount:消费金额frequency:当前日期下的消费次数
#导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
# 加上此语句是为了避免图像无法在jupyter notebook中正常显示
%matplotlib inline
# 此语句是为了使中文能正常显示
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
# 读取数据并查看
df = pd.read_csv('kelu.csv')
df
# 查看各列基本情况
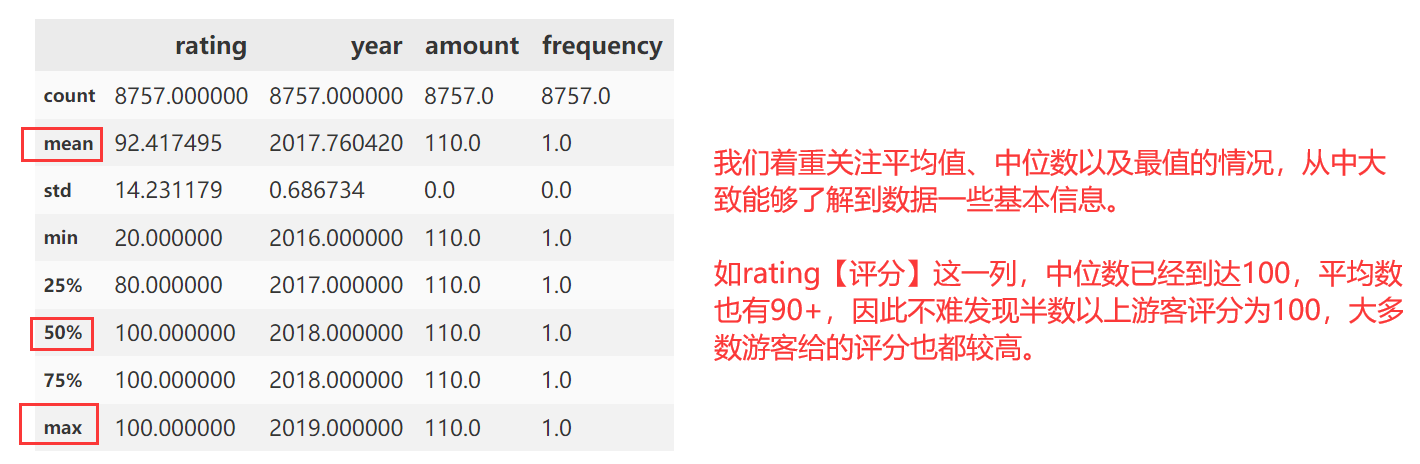
df.describe()
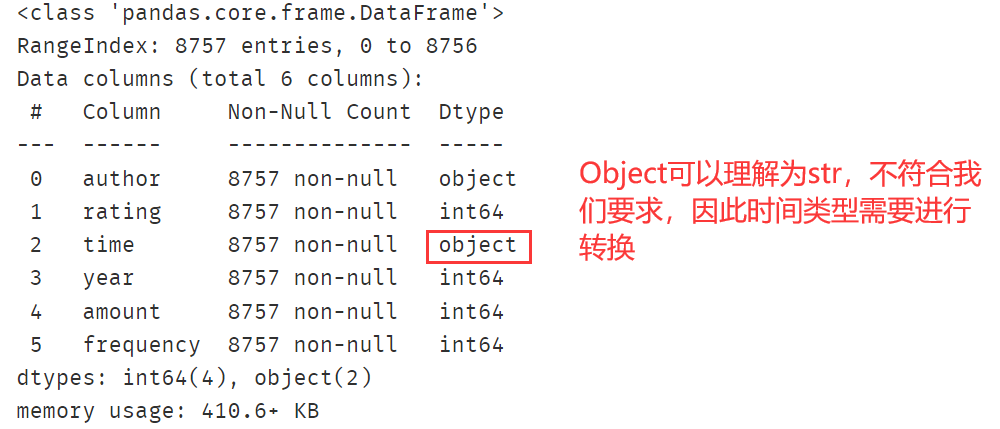
# 查看各列数据格式,看看是否有需要调整的部分
# 【比如假设时间为字符串类型则需要调整为日期型】
df.info()
# 将time列转换为日期格式
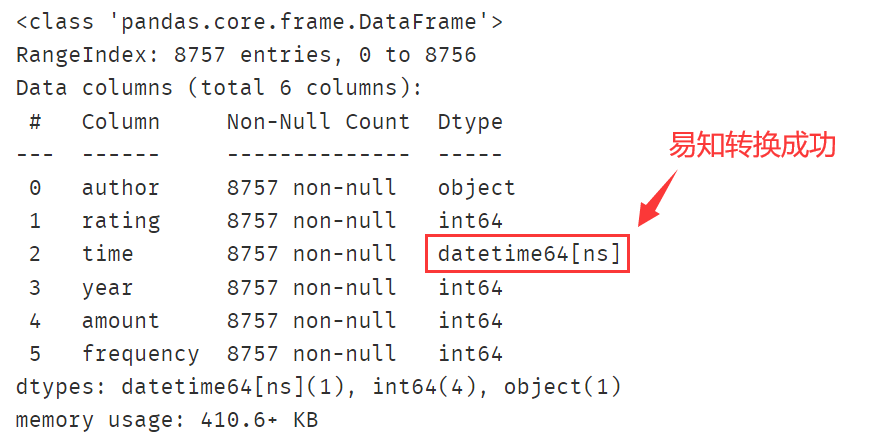
df['time'] = pd.to_datetime(df['time'],format='%Y/%m/%d')
# 查看是否成功
df.info()
任务2:每天票售票量分析
# 想要知道每天卖出了多少票,只需要以time作为分组依据再对每组的个数进行计数即可
# 因为time具体到天,以其作为分组依据实则就是以天数作为分组依据
# 分组后使用聚合函数count对任意一列进行计数即可【因为每一列都没有空值】
df1 = df.groupby('time')['frequency'].count()
# 使用matplotlib进行绘制并展示
plt.title('观景台每日售票数统计')
plt.plot(df1)
plt.show()
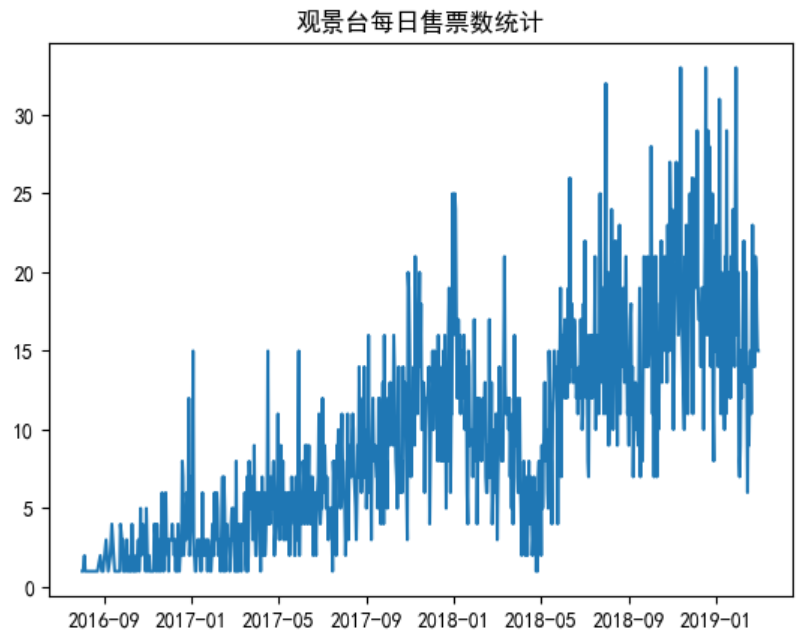
- 整体来看每日销量呈现上升趋势,但是在
18年5月份前后出现一次较大的波动,销量急剧下滑,猜测可能遭遇自然灾害 16年9月~17年1月,销量非常低,每天平均2-3张门票,猜测是观景台刚刚开放,名声还不大
任务3:每月售票量分析
# 取df['time']中的年份与月份信息保存到month这一列中
# datetime64[M]意思是精度精确至月份【此时“日”的信息统一为01,可输出查看】
df['month'] = df['time'].values.astype('datetime64[M]')
# 按照month这列分组其实就是按照月份进行分组,接着找任意列进行组计数
df2 = df.groupby('month')['frequency'].count()
# 设置画布大小
plt.figure(figsize=(8,4))
plt.plot(df2)
plt.xlabel('月份')
plt.ylabel('销售数量')
plt.title('16~19年每月销量分析')
plt.show()
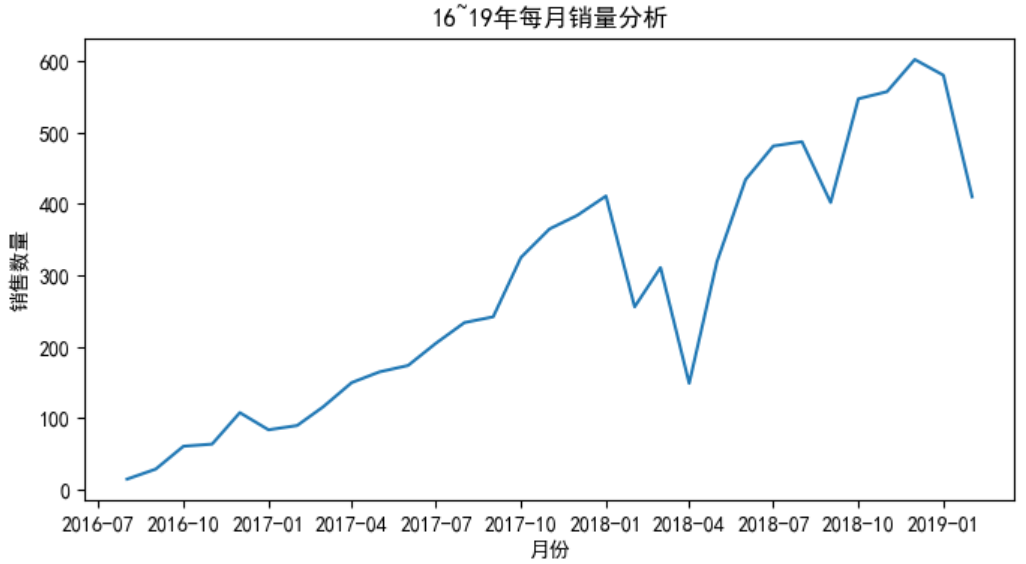
月份整体销量依然呈现上升趋势,但是在18年2,3,4月份月销量下滑明显,推测与自然灾害有关【月销量趋势与日销量趋势会有一定关系】
任务4:用户购买量与消费金额分析
# df是经过预处理的原始数据,后边会多次用到,不再赘述
# 按照游客分组,统计每个游客的购买次数【reset_index使得行索引重置】
grouped_count_author = df.groupby('author')['frequency'].count().reset_index()
# 按照游客分组,统计每个游客的消费金额
grouped_sum_amount = df.groupby('author')['amount'].sum().reset_index()
# merge函数类似于SQL中的表连接,具体啥情况可以动手试试
# left:左表
# right:右表
# on:关联字段
# how:inner(默认值,交集)|outer(并集)|left(只保留左侧)|right(只保留右侧)
user_purchase_retention = pd.merge(left=grouped_count_author,
right=grouped_sum_amount,
on='author',
how='inner')
# 绘制散点图,x轴是购买次数,y轴是总金额
plt.scatter(x=user_purchase_retention['frequency'],y=user_purchase_retention['amount'])
plt.title('用户的购买次数和消费金额关系图')
# 可通过user_purchase_retention['frequency']查看最大值从而确定x轴边界
plt.xticks(ticks=np.arange(0,20,step=2))
plt.xlabel('购票次数')
plt.ylabel('消费金额')
plt.show()
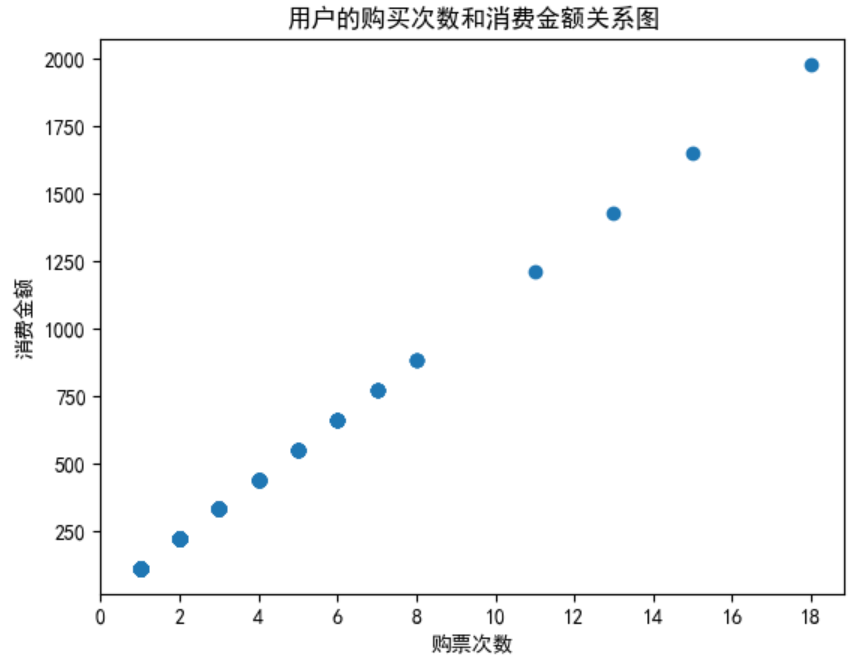
肉眼观察不难发现散点图是线性回归的,即斜率固定,此处的斜率代表的就是门票单价
任务5:用户购买门票两次及以上情况分析
# 按照author分组后再对frequency列计数即可得到每个用户购票次数
df2 = df.groupby('author')['frequency'].count().reset_index()
# 二次筛选,选取购买次数2次以上的部分,并且只要frequency这列【为直方图做准备】
df3 = df2[df2['frequency']>=2]['frequency']
# 直方图只需要传入一个参数x,其会将相同内容进行计数累加作为y轴,x轴即传入的Series中的不同值
# bins越大,柱子越细,按需要设置即可
# edgecolor设置直方图边界颜色
plt.hist(x=df3,bins=20,edgecolor='black')
plt.xlabel('购买数量')
plt.ylabel('人数')
plt.title('购买门票在2次及以上的用户数量')
plt.show()
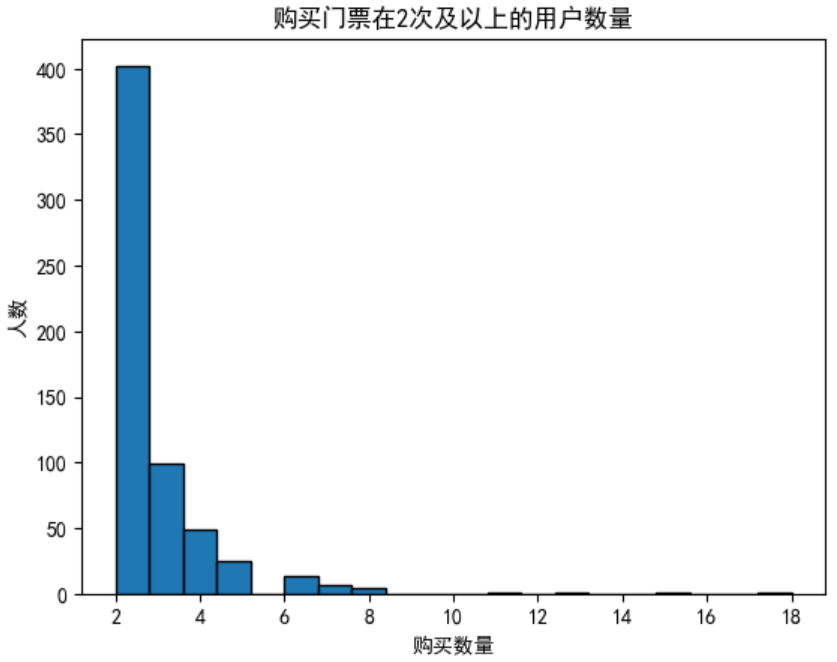
由于购买一次的用户是大多数,因此此处不再赘述,同时由上图可知,购买六次及以上的人数非常少,几乎可以忽略不记,推测是一个景点来太多次就没意思了🤔
任务6:购买次数2~5次用户占比分析
注意!此处占比是除去购买
1次用户后的占比
# 过滤出购买次数>=2次并且<=5次的用户
# df2是👆任务5得到的表,其frequency列为每个用户的购买次数
# df4是其中购买次数大于等于2的用户
df4 = df2[df2['frequency']>=2].reset_index()
# 在购买次数>=2的基础上二次过滤,得到>=2且<=5的用户
# 根据frequency进行分组,同时对相同分组的部分进行计数,即不同购买次数对应的人数
values = df4[df4['frequency']<=5].groupby('frequency')['frequency'].count()
# 手动建立饼图标签
labels=['购买2次','购买3次','购买4次','购买5次']
# 饼图x标签数据需要为list,因此强制转换,labels标签设立各部分名称
# autopct设置占比精度,%1.xf%% 为保留x位小数
plt.pie(x=list(values),labels=labels,autopct='%1.2f%%')
plt.title('购买次数在2~5次之间的人数占比')
# 设置图例
plt.legend()
plt.show()
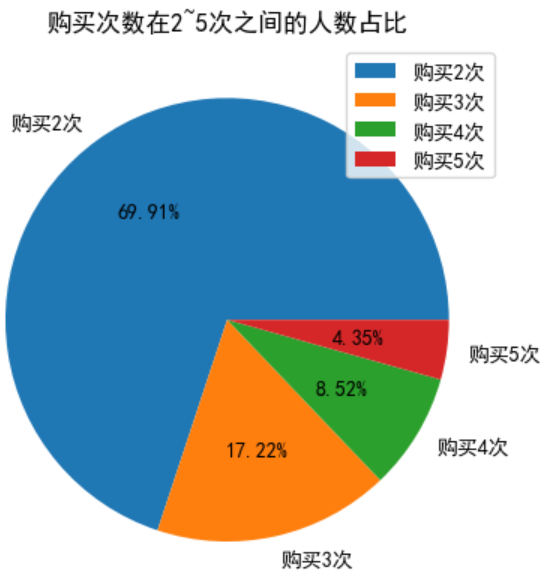
任务7:用户单月复购率分析
复购率:在某一时间窗口内(多指一个月)内消费次数在两次及以上的用户在总消费用户的占比
# 复购率:在某一时间窗口内(多指一个月)内消费次数在两次及以上的用户在总消费用户的占比
# 透视表,可以理解为同时对index与columns分组,一个是行索引,一个是列索引
# 行列索引指向的值为分组后对frequency列执行aggfunc的结果
# 存放的值实际上是每个用户在每个月份的购票次数,若没有购票则值为NaN
pivot_count = df.pivot_table(index='author',
columns='month',
values='frequency',
aggfunc='count')
# 将NaN值用0填充
pivot_count = pivot_count.fillna(0)
# 接下来只可能有以下三种情况:
# 消费次数>1,为复购用户,用1表示
# 消费次数=1,为非复购用户,用0表示
# 消费次数=0, 未消费用户,用NaN表示
# applymap会将规则应用于所有DataFrame中的元素
# 匿名表达式意思为:如果x大于1,则返回1;x等于0,则返回NaN;其余返回0
pivot_count = pivot_count.applymap(lambda x: 1 if x>1 else np.NAN if x==0 else 0)
# sum和count函数是对每列的情况进行聚合,因为是百分比,所以需要乘上100
# count不会统计NaN值
repurchase_rate = (pivot_count.sum()/pivot_count.count())*100
plt.figure(figsize=(10,4))
# 将Series的索引列充当X轴,值充当Y轴,绘制折线图
plt.plot(repurchase_rate)
plt.xlabel('时间(月)')
plt.ylabel('百分比(%)')
plt.title('16~19年每月用户复购率')
plt.show()
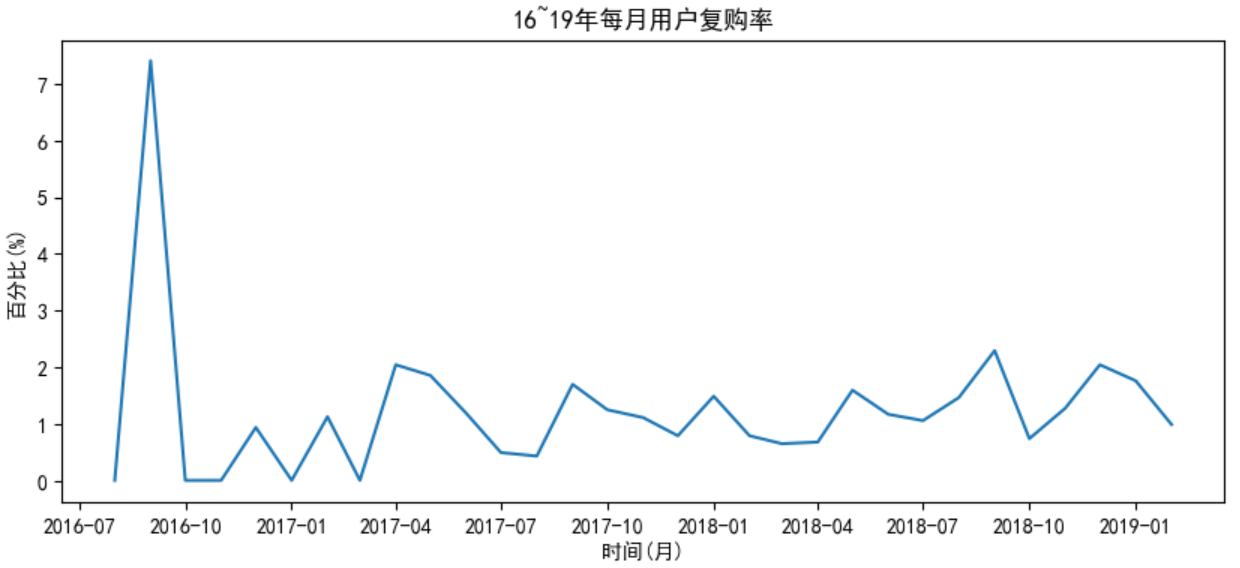
任务8:用户每月复购人数分析
plt.figure(figsize=(10,4))
# sum即每个月购票人数
plt.plot(pivot_count.sum())
plt.xlabel('时间/月')
plt.ylabel('复购人数')
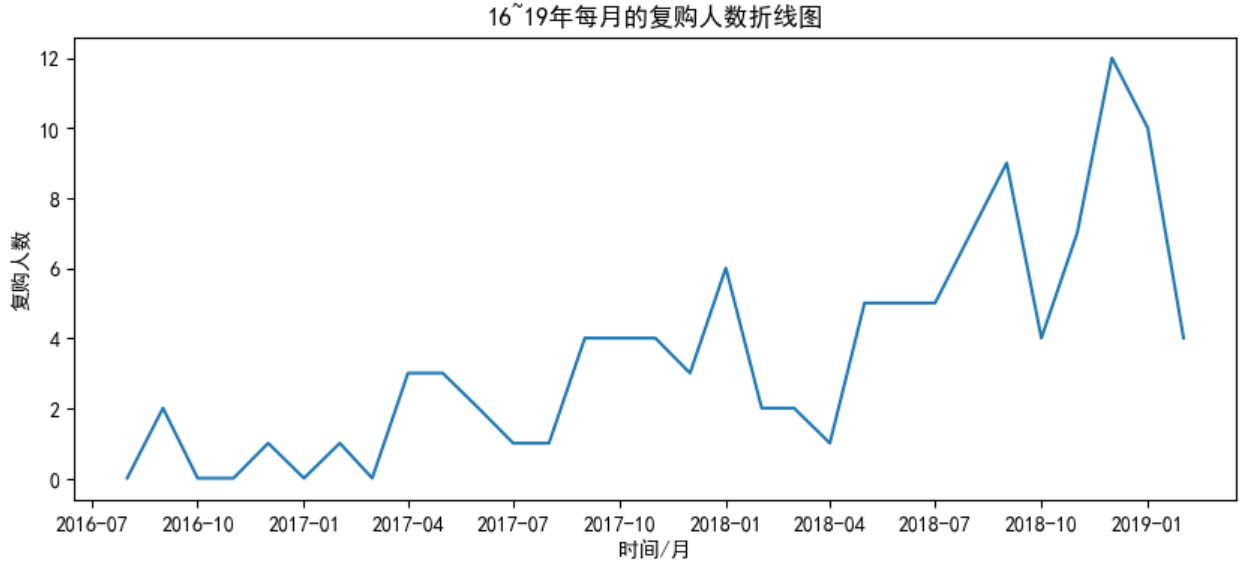
plt.title('16~19年每月的复购人数折线图')
plt.show()
任务9:用户回购率分析
回购率:在某一个时间窗口内消费过的用户,在下一个时间窗口仍旧消费的占比
举个例子,当前月消费用户人数
1000人,其中200人在下一个月仍旧进行了消费,回购率200/1000=20%
# 透视表,任务7中有介绍过,此处省略
pivot_purchase = df.pivot_table(index='author',
columns='month',
values='frequency',
aggfunc='count'
).fillna(0)
# 传入的data是每个用户在每个月的消费次数
def purchase_return(data):
# 存储每一个月回购状态
status = []
# 遍历每一个月【最后一个月除外,因为最后最后一个月没有回购这个说法】
# 月份长度可以通过len(pivot_purchase.columns)得到
for i in range(30):
# 说明本月有消费
if data[i] == 1:
# 如果下个月还有消费,则是回购用户
if data[i+1] ==1:
# 状态1表示当前月是有回购的
status.append(1)
else:
# 当前月消费了但是下个月未消费自然是非回购用户,用0表示
status.append(0)
# 当前月就没有消费,所以不必再判断下个月,直接赋值NaN
else:
status.append(np.NaN)
# 最后一个月单独处理,状态是NaN
status.append(np.NaN)
# 将处理好的列表转换为Series,索引与列名一致,便于替换原数据
return pd.Series(status,pivot_purchase.columns)
# apply函数操作单位是DataFrame的行或列,由参数axis指定【默认为列】
# 此处的意思为:对pivot_count的每一行数据执行purchase_return函数
pivot_purchase_return = pivot_purchase.apply(purchase_return,axis=1)
# 当前月份的回购率 = 所有用户的回购情况/当月有消费的用户数【count不会统计NaN值】
rate = pivot_purchase_return.sum()/pivot_purchase_return.count()*100
plt.figure(figsize=(10,4))
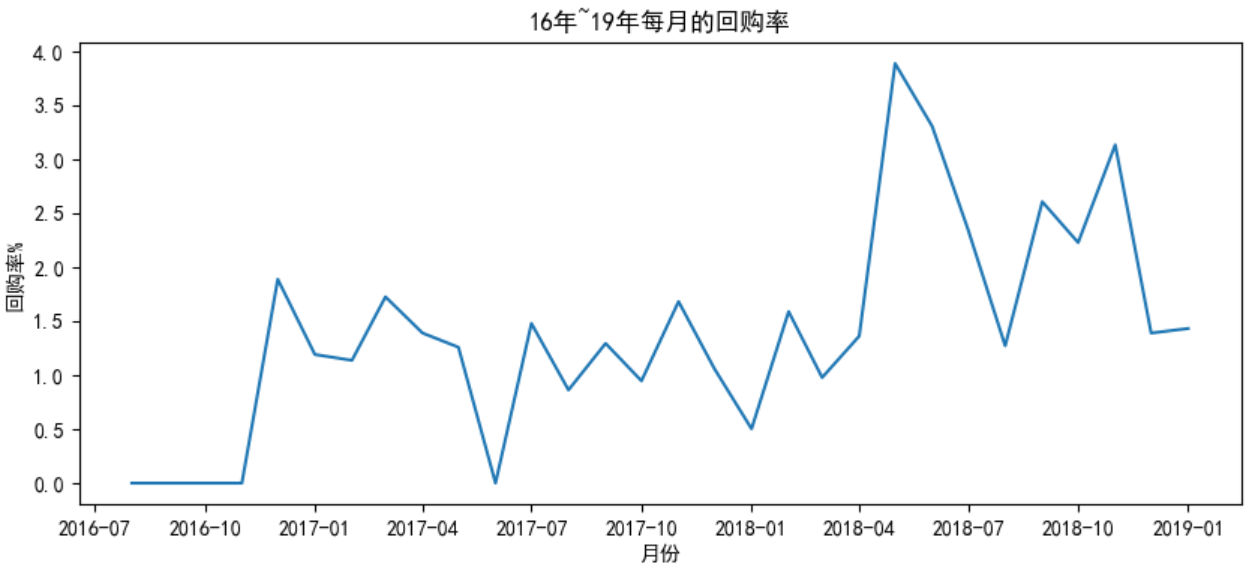
plt.plot(rate)
plt.title('16年~19年每月的回购率')
plt.xlabel('月份')
plt.ylabel('回购率%')
plt.show()
任务10:用户回购人数分析
# sum得到的是每个月所有回购人数的Series,索引为月份
pivot_purchase_return_sum = pivot_purchase_return.sum()
plt.figure(figsize=(10,4))
# 索引被充当X轴,值充当Y轴
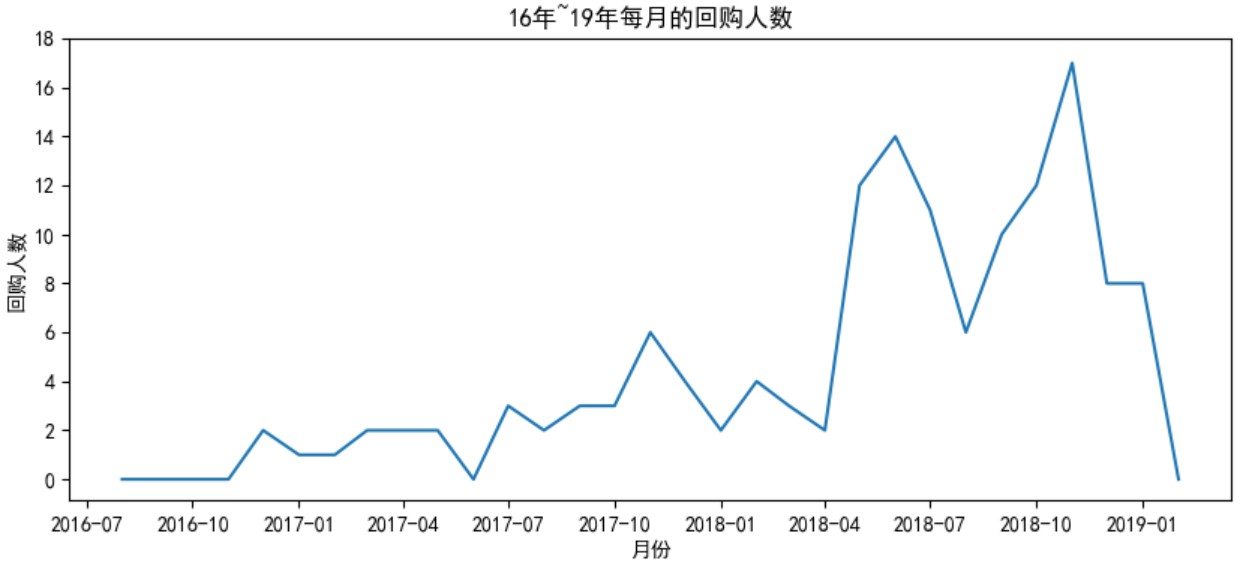
plt.plot(pivot_purchase_return_sum)
plt.title('16年~19年每月的回购人数')
plt.xlabel('月份')
plt.yticks(np.arange(0,20,step=2))
plt.ylabel('回购人数')
plt.show()
任务11:用户生命周期分析
每一个用户最后一个购买商品的时间减去用户第一次购买商品的时间,转换成天数,即为生命周期
# 根据用户进行分类可以得到一个用户所有的购买时间
# 选择时间当中最小值即第一次购买的时间;最大值即最后一次购买时间
time_min = df.groupby('author')['time'].min()
time_max = df.groupby('author')['time'].max()
# 二者相减得到的即生命周期
life_time = (time_max-time_min).reset_index()
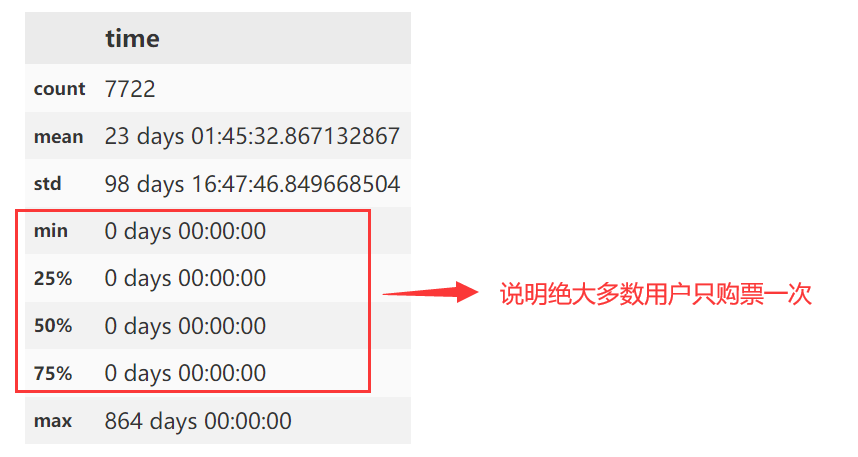
# 查看生命周期基本情况
life_time.describe()
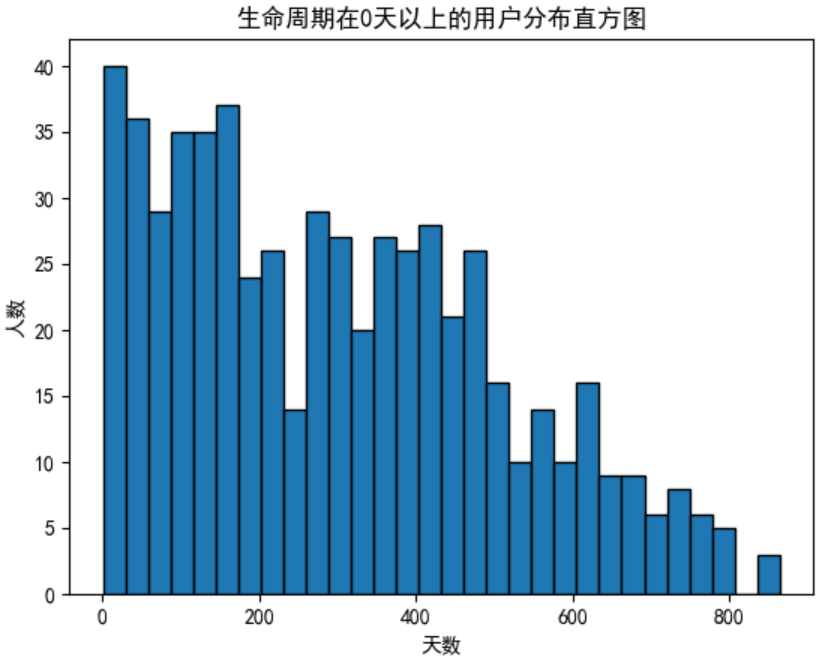
任务12:生命周期大于0天的用户分析
生命周期等于
0天的用户占据绝大多数,若将其包括则绘制直方图时视觉效果不佳,因此此处不对其进行绘制
# 过滤得到生命周期大于0的用户
life_time_gt_zero = life_time[life_time['life_time']>0]['life_time']
# 宽度= (最大值-最小值)/bins
# 一定范围的人数会被统计到一个直方图柱形中
plt.hist(x=life_time_gt_zero,bins=30,edgecolor='black')
plt.xlabel('天数')
plt.ylabel('人数')
plt.title('生命周期在0天以上的用户分布直方图')
plt.show()
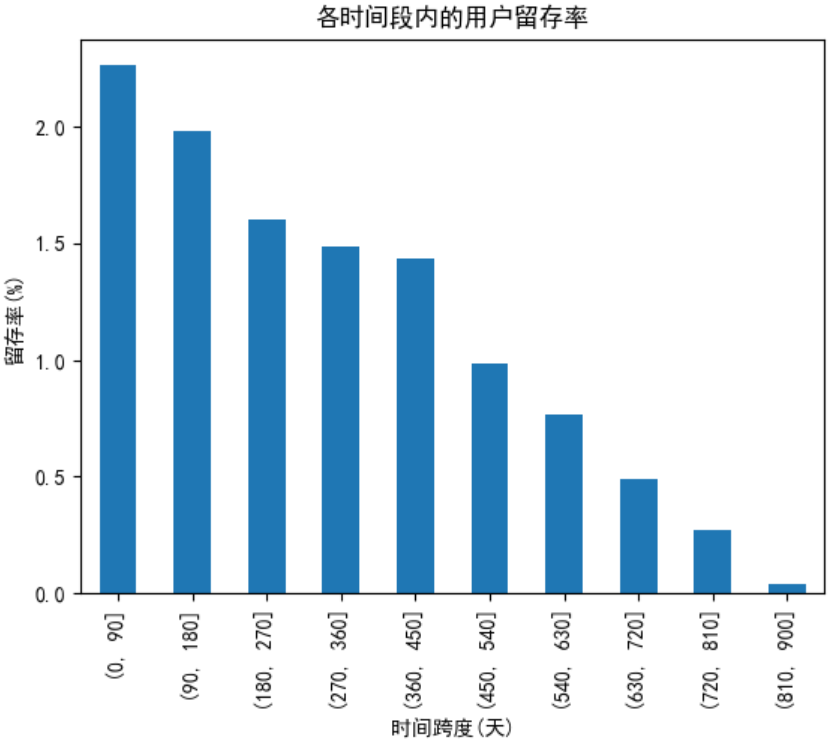
任务13:用户各时间段留存率分析
- 留存天数:当下消费时间距离第一次消费的时间差
- 留存用户:在不同时间有消费的用户
- 留存率:当前时间段的留存用户数/总用户数
# time_min是任务12中得到的Series结构,存储每个用户第一次消费时间的
# reset_index()将Series转换为DataFrame【原先的索引和值都被拿来作为列值】
time_min_df = time_min.reset_index()
# merge函数在任务4有介绍过,此处不再赘述
# 目标是为原始数据增加当前用户第一次消费的时间,因此可以以author作为关键字进行内连接
# 由于两个表都有time这列,内连接时可为它们自定义后缀名,以防混乱
user_purchase_retention = pd.merge(left=df,right=time_min_df,how='inner',on='author',suffixes=('','_min'))
# 计算留存天数【当前消费时间 - 第一次消费时间】
user_purchase_retention['time_diff'] = user_purchase_retention['time']-user_purchase_retention['time_min']
# time_diff是时间类型,单位是天,将其转成数值,保留一位小数并重新赋值回来
user_purchase_retention['time_diff'] = user_purchase_retention['time_diff'].apply(lambda x:x/np.timedelta64(1,'D'))
# 使用列表表达式生成间隔90天,共计900天的列表【后续需要配合pd.cut生成区间】
bin = [i*90 for i in range(11)]
# cut函数可以判断当前数值属于哪个区间【前开后闭】,并返回这个区间,用time_diff_bin列进行装载
user_purchase_retention['time_diff_bin'] = pd.cut(user_purchase_retention['time_diff'],bin)
# 统计每个游客,在不同的时间段内的消费频率和值(便于稍后判断该用户在某个区间内是不是留存用户)
# 按照author与time_diff_bin进行分组,同时聚合时对frequency使用sum,即每个用户在不同时间段的消费总数
# 分组后会进行压缩,排版不好看,因此使用unstack(),意思为不进行压缩
pivot_retention = user_purchase_retention.groupby(['author','time_diff_bin'])['frequency'].sum().unstack()
# 值为NaN意味着该用户在当前时间段不是存留用户,用0表示
pivot_retention_trans = pivot_retention.fillna(0)
# 值如果大于0则说明当前用户在此时间段是存留用户,用1表示
pivot_retention_trans = pivot_retention_trans.applymap(lambda x:1 if x>0 else 0)
# 留存率【留存用户数/总用户数】
retention_rate = pivot_retention_trans.sum()/pivot_retention_trans.count()*100
# 利用pandas自带的工具进行柱状图绘制【索引为x轴,y为对应值】
retention_rate.plot.bar()
plt.xlabel('时间跨度(天)')
plt.ylabel('留存率(%)')
plt.title('各时间段内的用户留存率')
plt.show()