1.1.1.1 整装待发
- 近年来数据存储和数据处理的能力都产生了飞跃,为数据挖掘奠定了基础。
- 虽然数据量大,但是真正有用的信息少
2.1.2.1 学而不思则罔
- 是多学科(机器学习、人工智能、模式识别、统计学)的交叉领域
- 如何学习数据挖掘?:认真听课、积极讨论+课后延伸阅读(提供灵感)+写代码
- 不是去记住理论,网上都查得到,一定要学会如何思考
3.1.3.1 知行合一
1、数据
- 什么是数据?:定量或者定性的属性值(比如一个人身高、体重、年龄等)是最底层的表现形式,而信息会高一级,数据要做一些处理后才能转化为信息
- 数据类型:连续型、离散型、符号型
- 存储形式
- 物理存储:都是二进制存储
- 逻辑存储:比如星型、网络型等
- 主要问题:数据类型转化、数据的错误
2、大数据
- 什么是大数据?:
- 说法一:数据量大(Tb->Zb)、高速流动(Batch->Streaming Data)、数据种类多(结构化数据->非结构化数据)
- 说法二:数据量大到传统的数据处理软件都无法处理
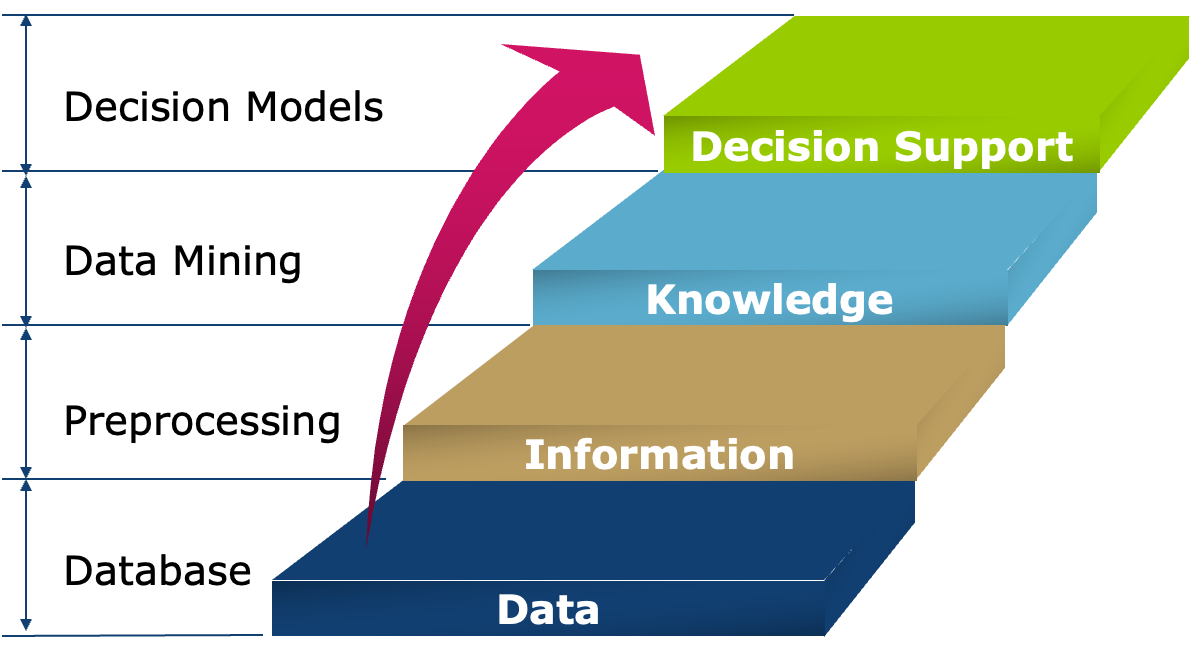
4.1.4.1 从数据到知识
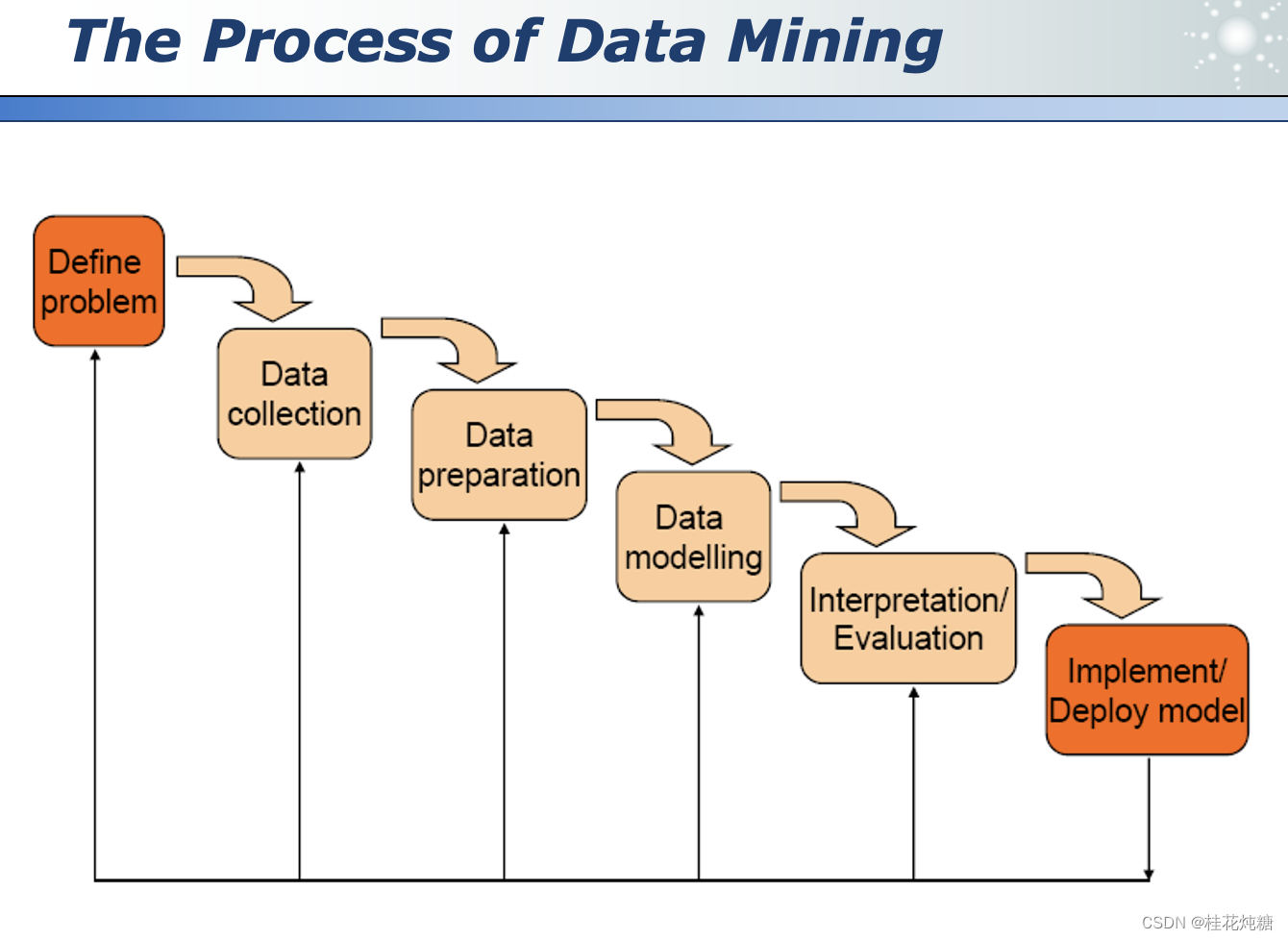
什么是数据挖掘?:是从海量、不完整、有噪声的数据中自动提取有趣且潜在有用信息的过程
注:不是完全自动的过程,需要人为参与(比如相关领域的知识、数据收集和预处理等)
5.1.5.1 分类问题
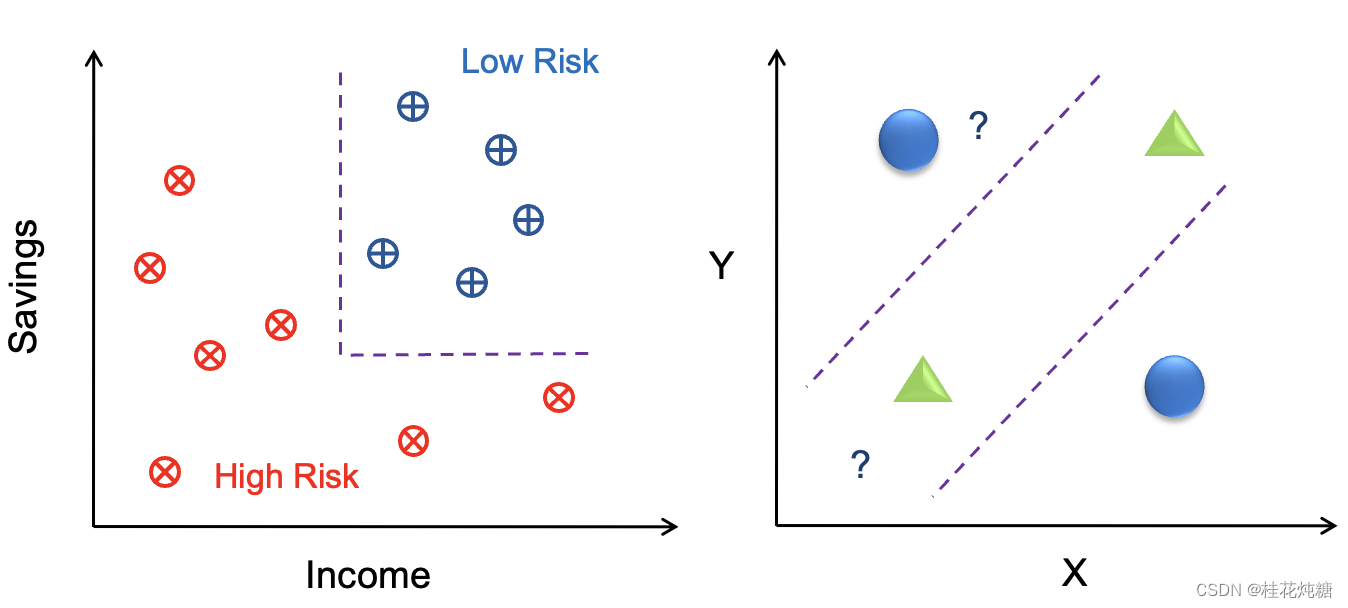
- 什么是分类?是根据一个或多个特征(称为变量)的信息和已知标签训练得到模型,然后对未知标签进行分类
- 分类算法:决策树、k-nearest neightbours、神经网络、支持向量机
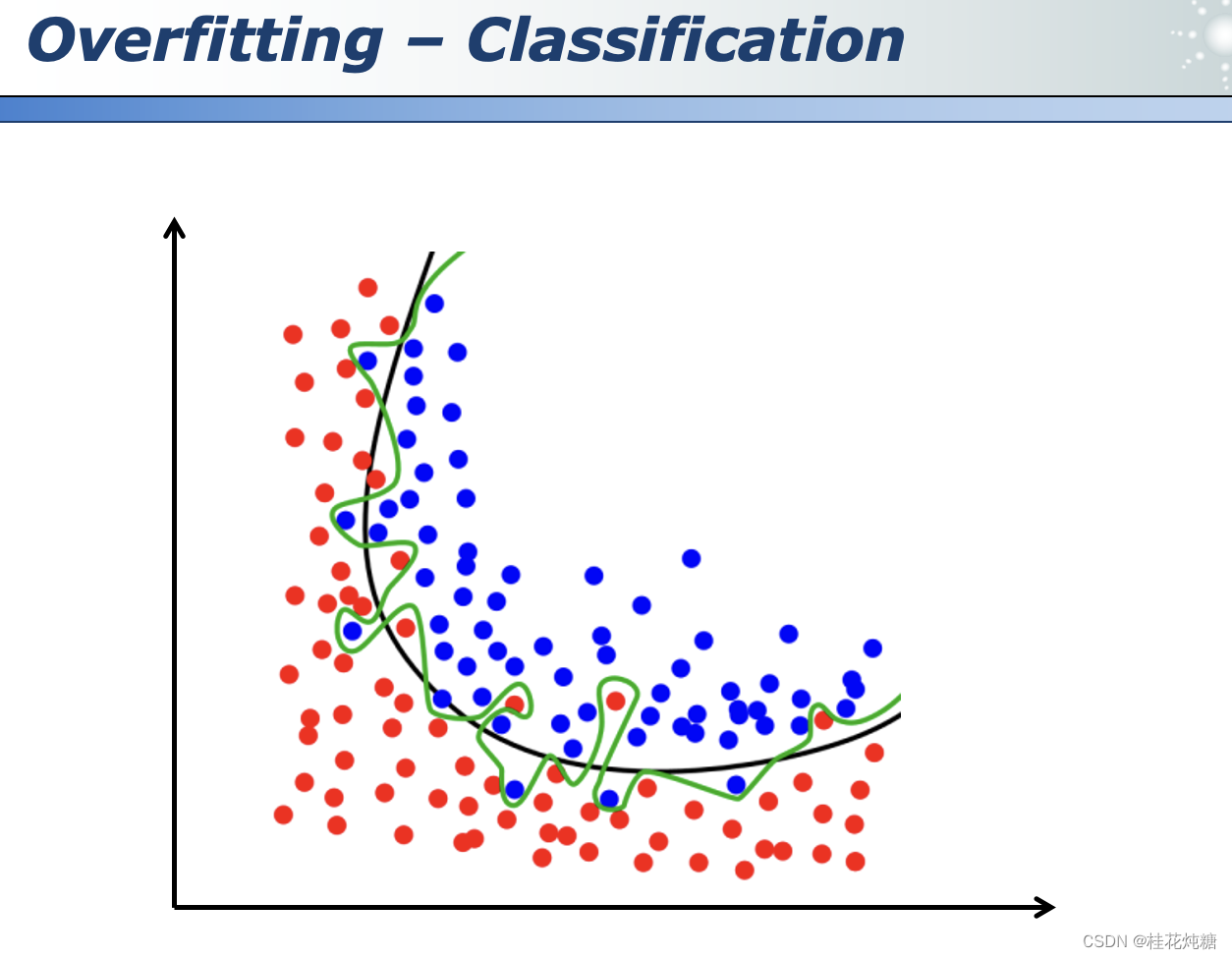
- 其实就是寻找分界面,对空间进行划分(直线、曲线、复杂的圆或多条线等),分界面尽量选择平滑而不是过于复杂的,避免过拟合
- 将数据化为训练集和测试集,训练集用于生成模型,测试集用于对模型进行评估
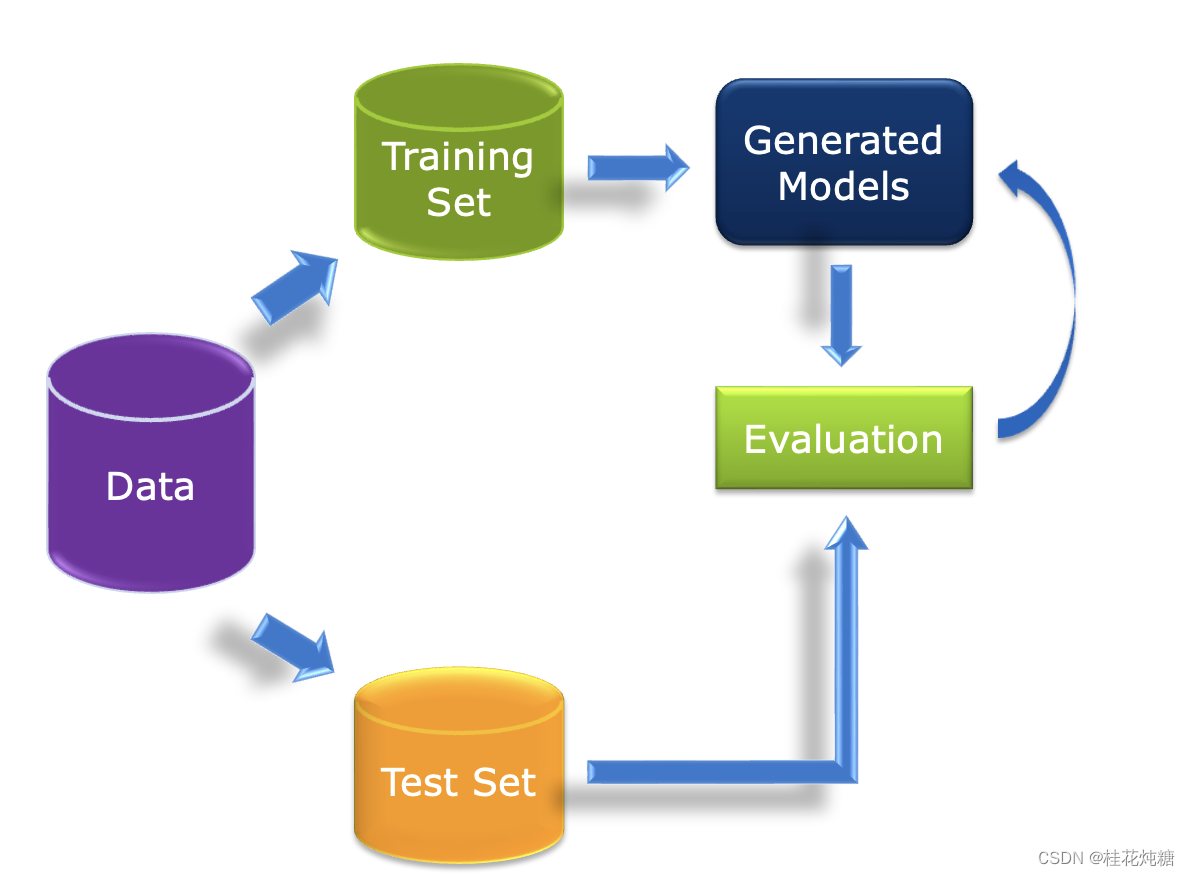
- 混淆矩阵


![[附源码]计算机毕业设计springboot酒店在线预约咨询小程序](https://img-blog.csdnimg.cn/afb8efc8401f4053bf3f6d257e6674e4.png)

![一、Vue3基础[组件(props、事件、插槽)]](https://img-blog.csdnimg.cn/13d08aaa40d14bcdaa9ae0eb3506bc8a.png)