目录
前言:
一:冒泡排序
基础思路
完整排序
时间复杂度分析
二:递归实现快速排序
基础思路
单趟排序
(1)双向扫描法
(2)挖坑法
(3)前后指针法(推荐这种)
完整排序
时间复杂度分析
优化
(1)三数取中
(2)小区间优化
三:非递归实现快速排序
基础思路
完整排序
四:效率对比
前言:
本文的排序都是升序,降序反过来就行
交换排序
基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位 置。交换排序的特点是:将键值较大的数据向序列的尾部移动,键值较小的数据向序列的前部移 动。冒泡排序和快速排序就属于交换排序。
一:冒泡排序
基础思路
1.从第一个元素开始,一直到最后一个元素,重复以下的步骤:
2.每次比较相邻的两个元素,如果第一个元素大于第二个元素,则交换它们的位置;
3.经过一轮遍历之后,最后一个元素一定是当前未排序部分中最大的元素,因此可以减少下一轮遍历的比较次数;
4.重复上述步骤,直到所有元素都按照升序排列。
完整排序
代码:
//冒泡排序 void BubbleSort(int* a, int n) { int i = 0; int j = 0; for (i = 0; i < n; i++) { //设计一个标志,如果没有进入循环说明后面已经有序,跳出循环 int exchange = 0; for (j = 1; j < n - i; j++) { if (a[j] < a[j - 1]) { swap(&a[j], &a[j - 1]); exchange = 1; } } if (exchange == 0) { break; } } }图解:
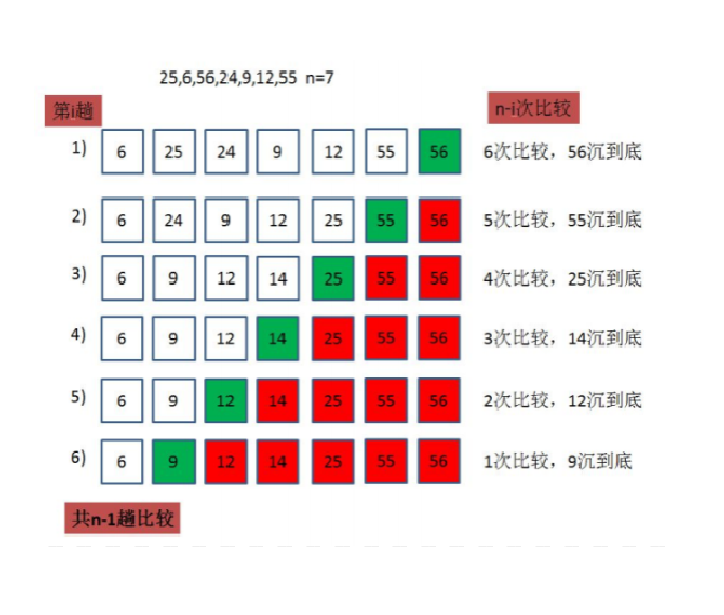
时间复杂度分析
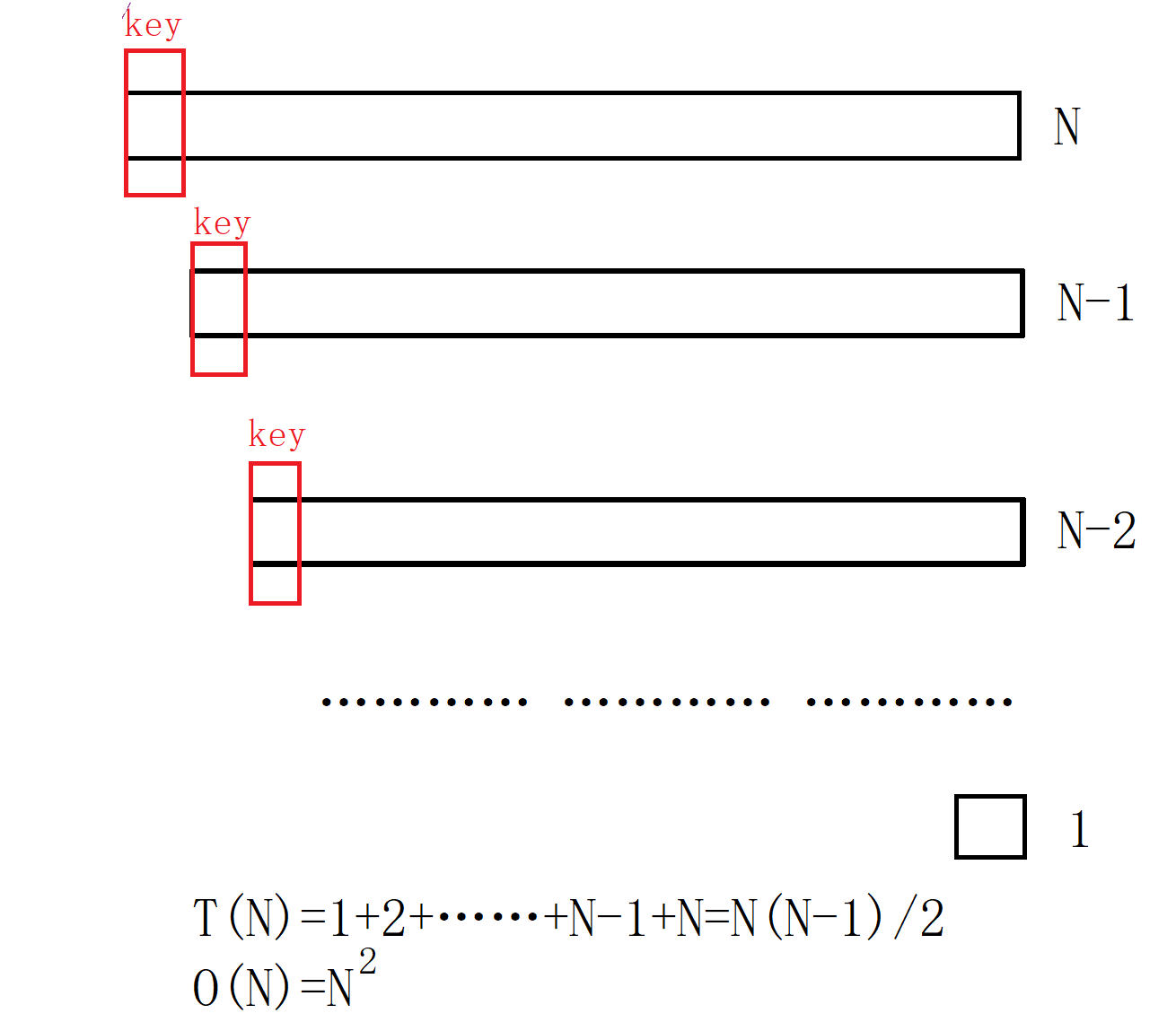
在冒泡排序过程中,需要进行n-1次遍历
每次遍历需要比较相邻的两个元素并可能交换位置,也就是说每次遍历会固定一个最大(小)元素的位置,因此最多需要遍历n-1次,而每次遍历最多需要比较n-1次。
因此比较次数为:(n-1) + (n-2) + ... + 2 + 1 = n(n-1)/2
因此时间复杂度为O(n^2)。
需要注意的是,在最好情况下,也就是所有元素已经按照升序排列,在第一次遍历时就可以确定所有元素的位置,因此只需要进行一次遍历,时间复杂度为O(n);
而在最坏情况下,也就是所有元素已经按照降序排列,在每次遍历时都需要进行比较和交换,时间复杂度为O(n^2)。
二:递归实现快速排序
基础思路
1.选择一个基准值(key),将数组或序列分成两部分。
2.将小于基准值的元素放在基准值的左侧,大于基准值的元素放在右侧,等于基准值的元素可以放在左侧或右侧。
3.递归地对左右两侧进行排序,直到排序完成。
(简单的来说,快速排序的核心思路就是把每一个数据放到属于它的位置)
单趟排序
我们看下面这个数组:
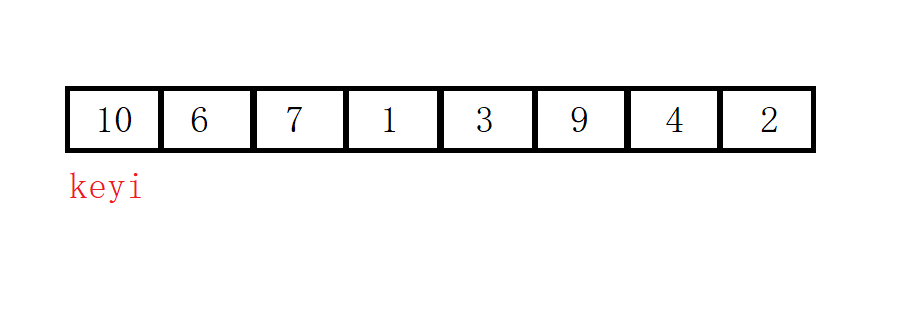
我们选取最左边的数据为基准值key(key的选取没有规定,按个人需求来就行),采用交换而不是覆盖的方法,我们保存key的下标keyi。如果采用覆盖的方法,我们保存值key。
要让小于key的值全都移到左边,大于key的值全都移到右边(相等无所谓),我们一共有三种方法。
单次排序完成后我们要让程序知道是那个数据已经确定好了位置,所以每一组方法最后都要返回确定好的位置下标。
(1)双向扫描法
基础思路:
①选择一个基准值(key),从左到右和从右到左分别进行扫描
②将小于基准值的元素交换到左侧,大于基准值的元素交换到右侧,直到两个扫描相遇
③最后将基准值插入到左右两侧之间
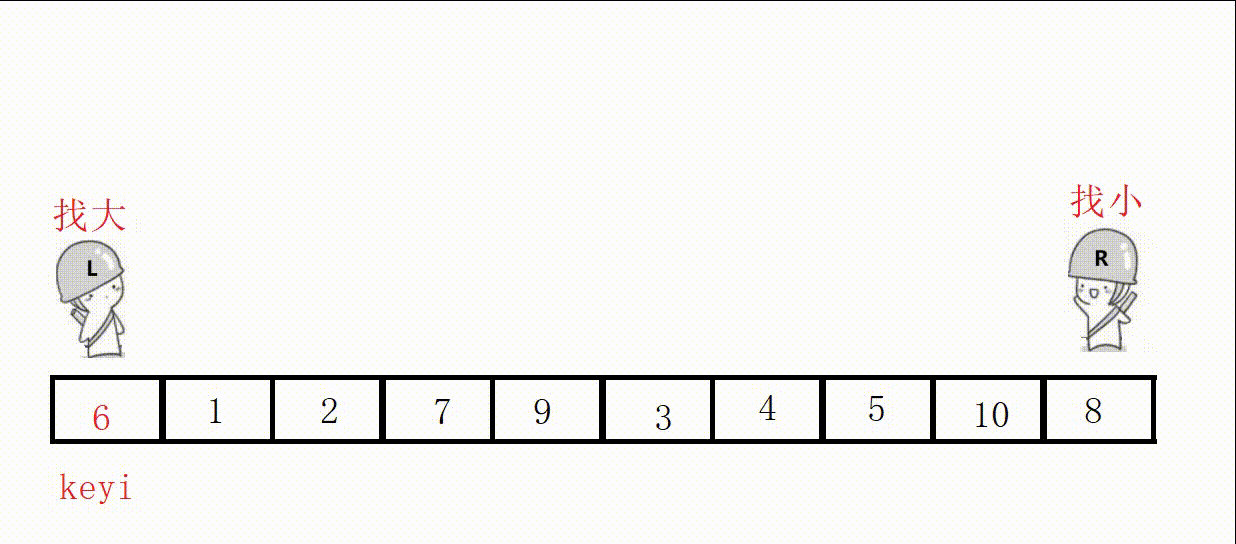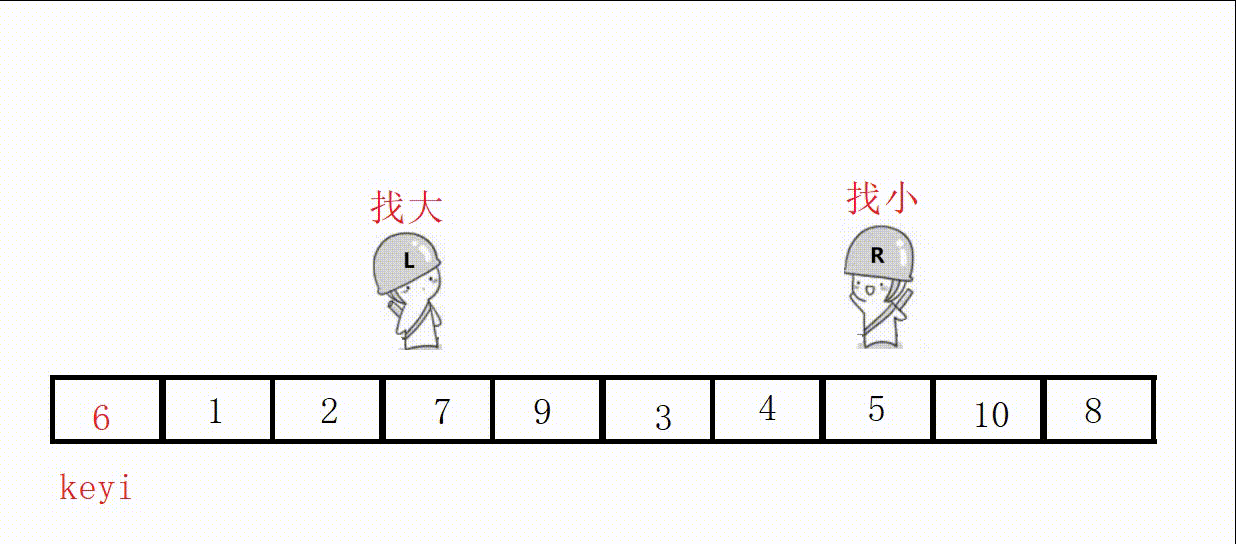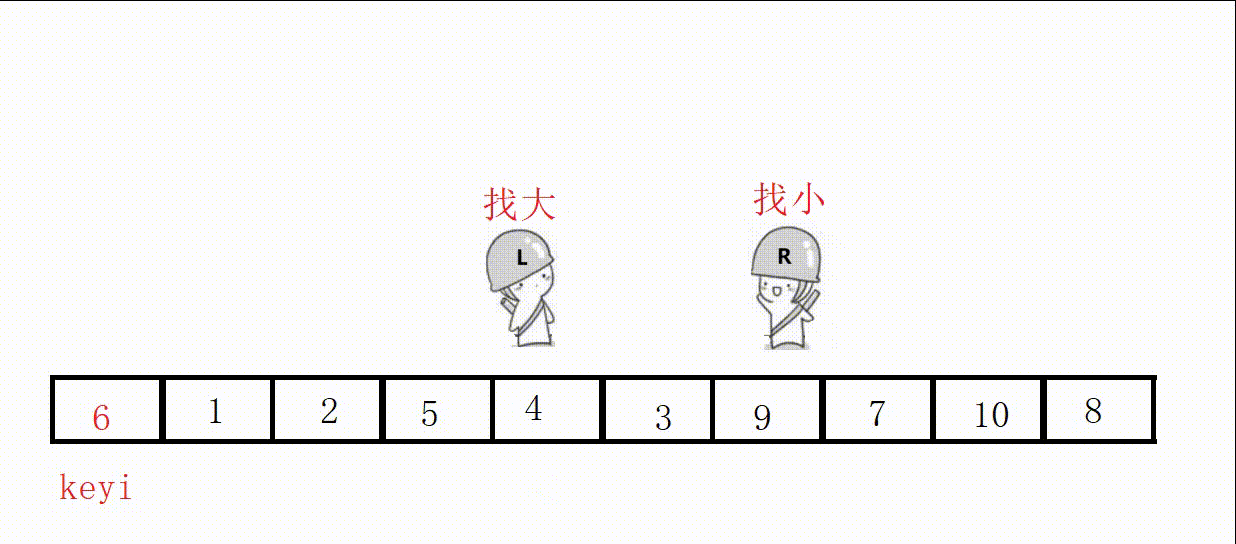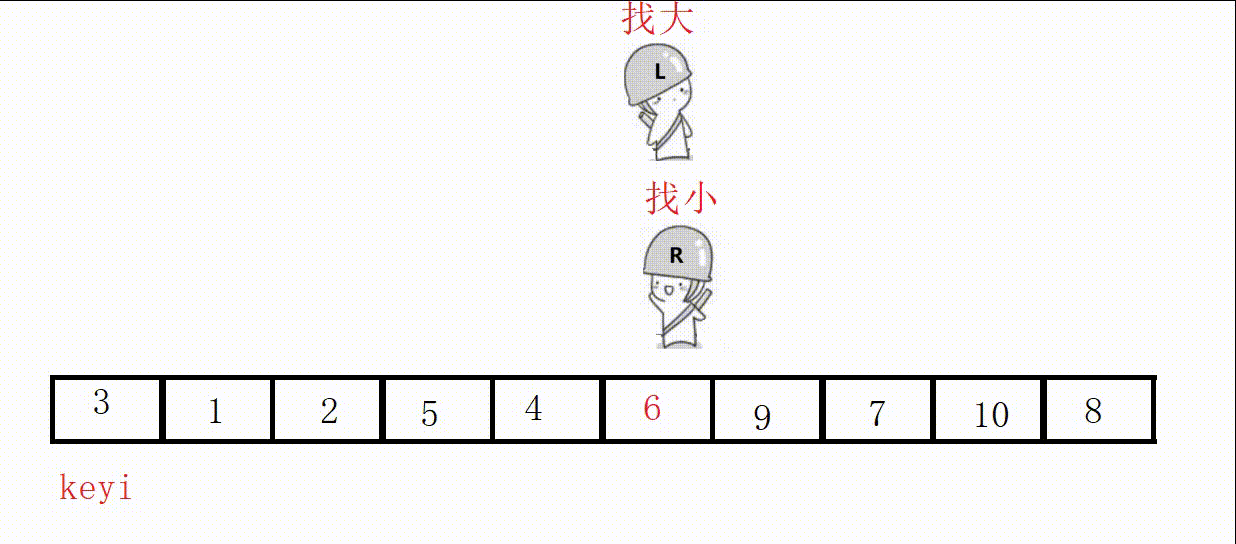
选最左边为key,右边先出发,这样可以保证最后相遇的的位置值小于key。
图解:
相反,选右边为key,左边先出发,可以保证相遇位置大于key
图解:
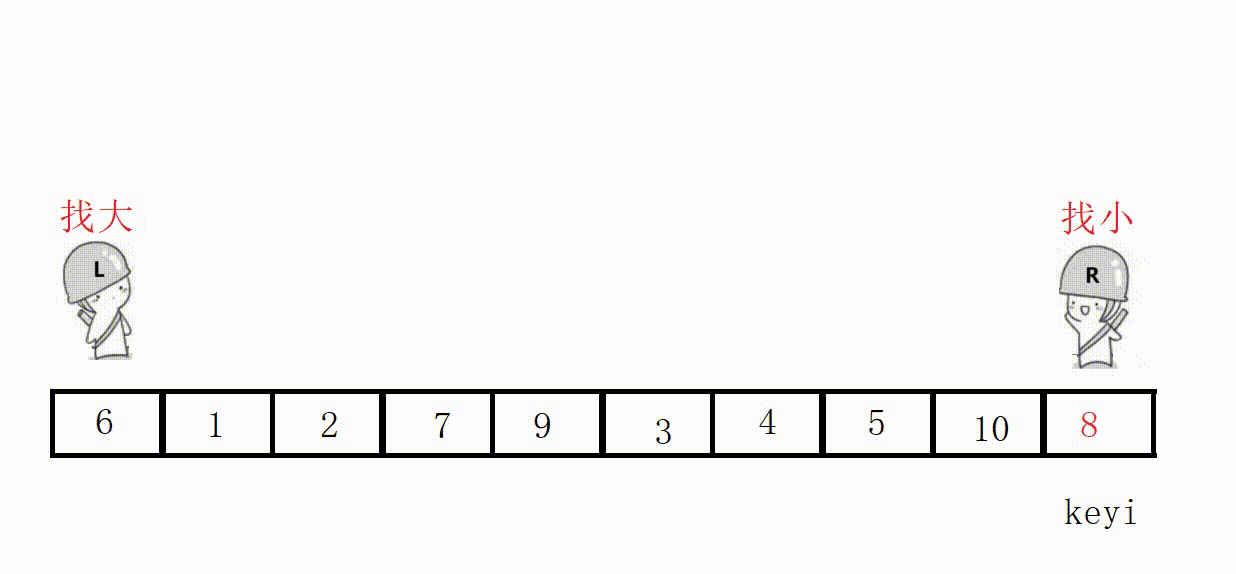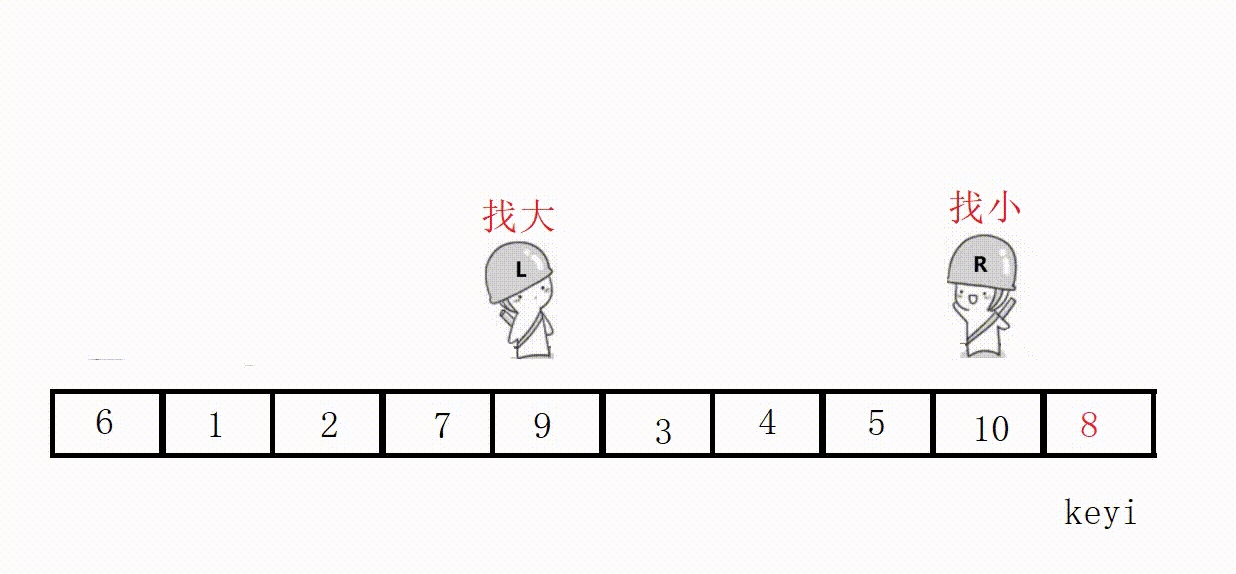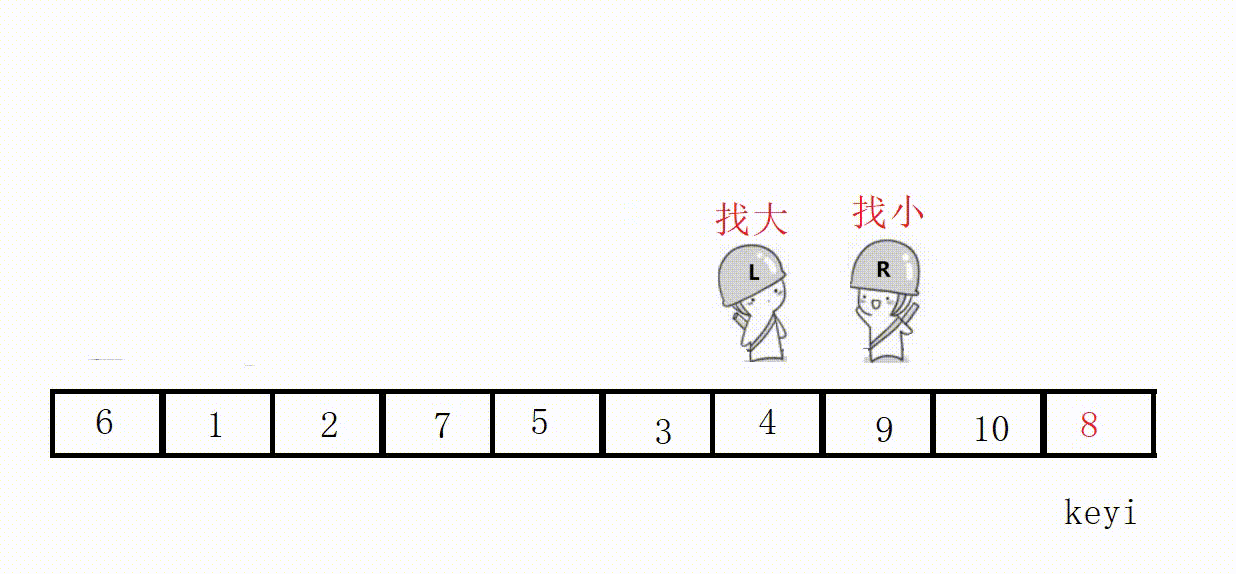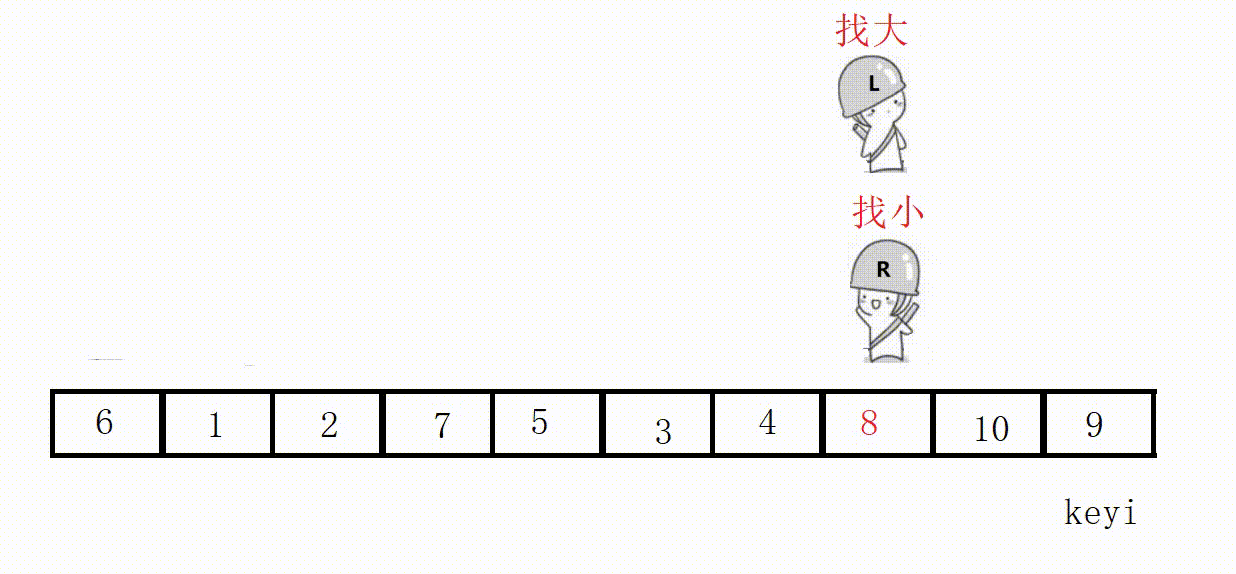
代码(这里选最左为key):
//单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; }
(2)挖坑法
基础思路:
①选择一个基准值(key),设计一个变量pivot来记录坑位,坑位的初始值为key下标一致,从左到右和从右到左分别进行扫描
②将小于基准值的元素交换到左侧坑位,自己形成新的坑位;大于基准值的元素交换到右侧坑位,自己形成新的坑位,直到两个扫描相遇
③最后将基准值插入到左右两侧之间
和前面不同,挖坑法会覆盖数据,我们选择保存值而不是下标。
选最左边为key,右边先出发,这样可以保证最后相遇的的位置值小于key。
图解:
相反,选右边为key,左边先出发,可以保证相遇位置大于key
图解:
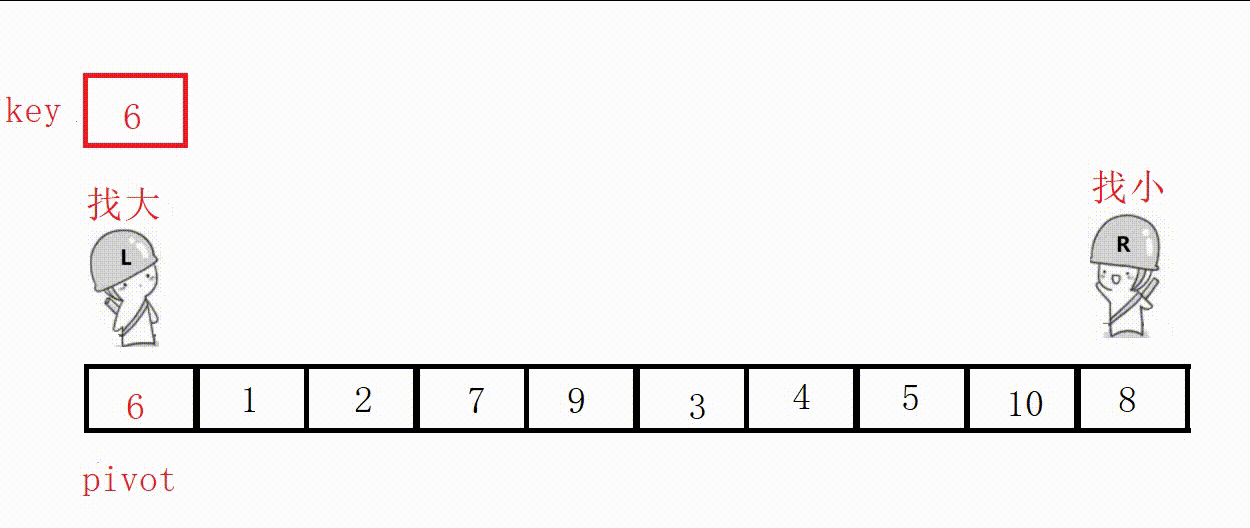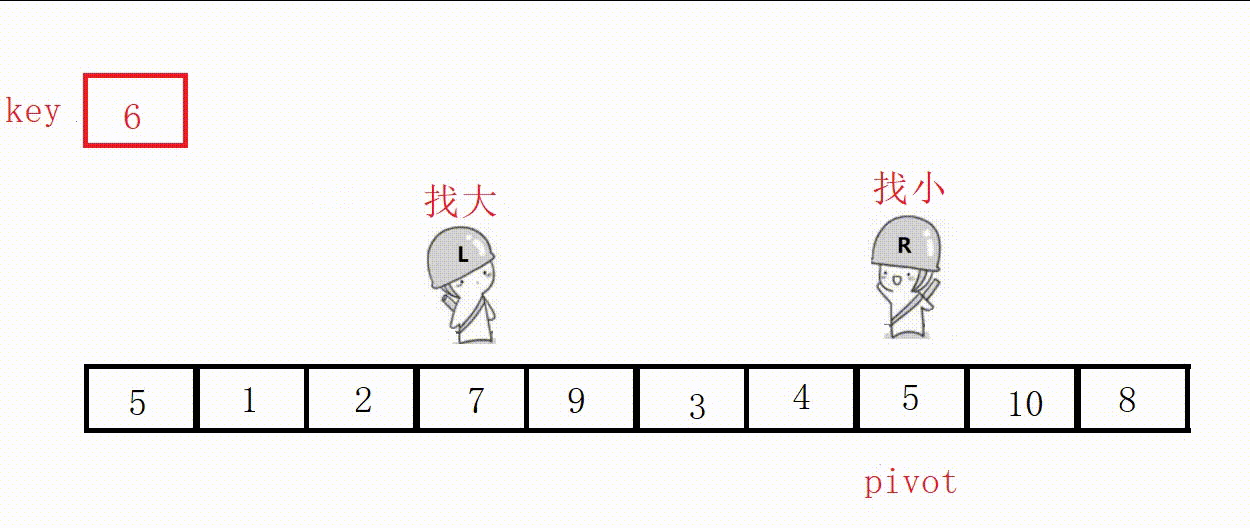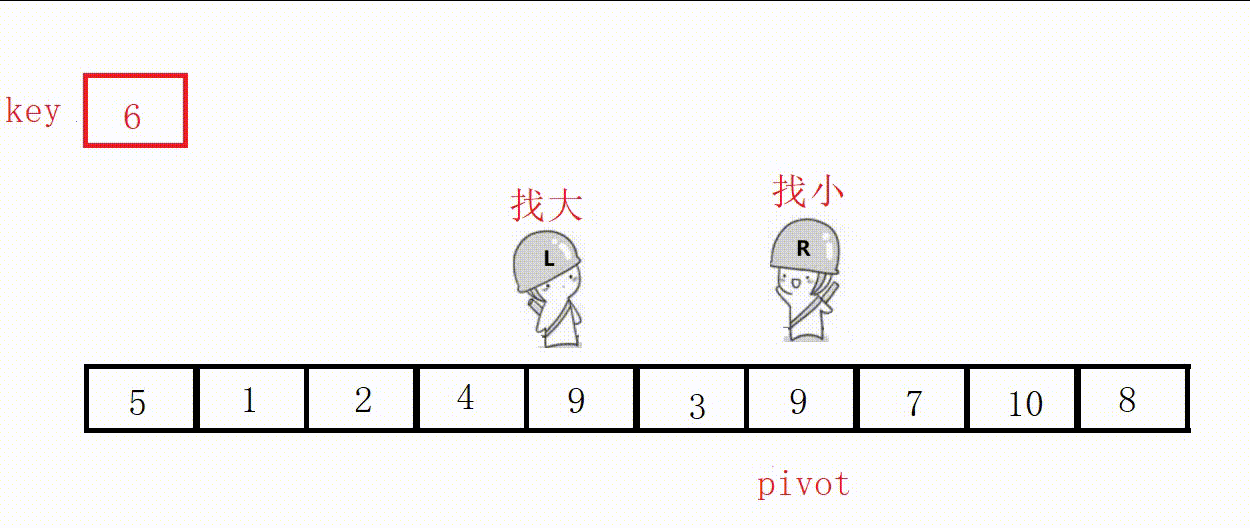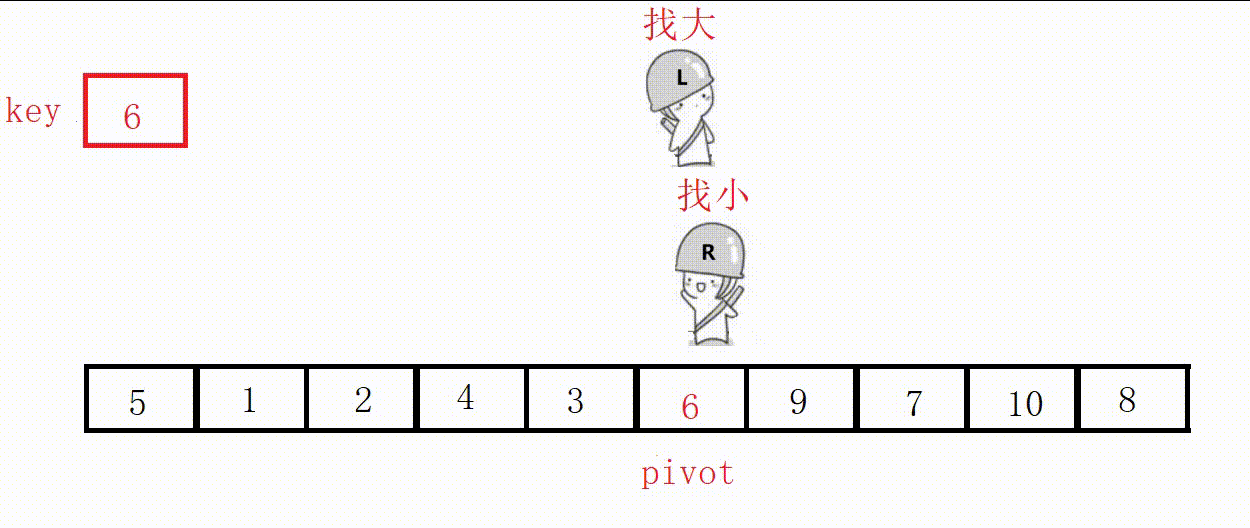
代码:
//挖坑法单趟 int partion2(int* a, int left, int right) { int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; }
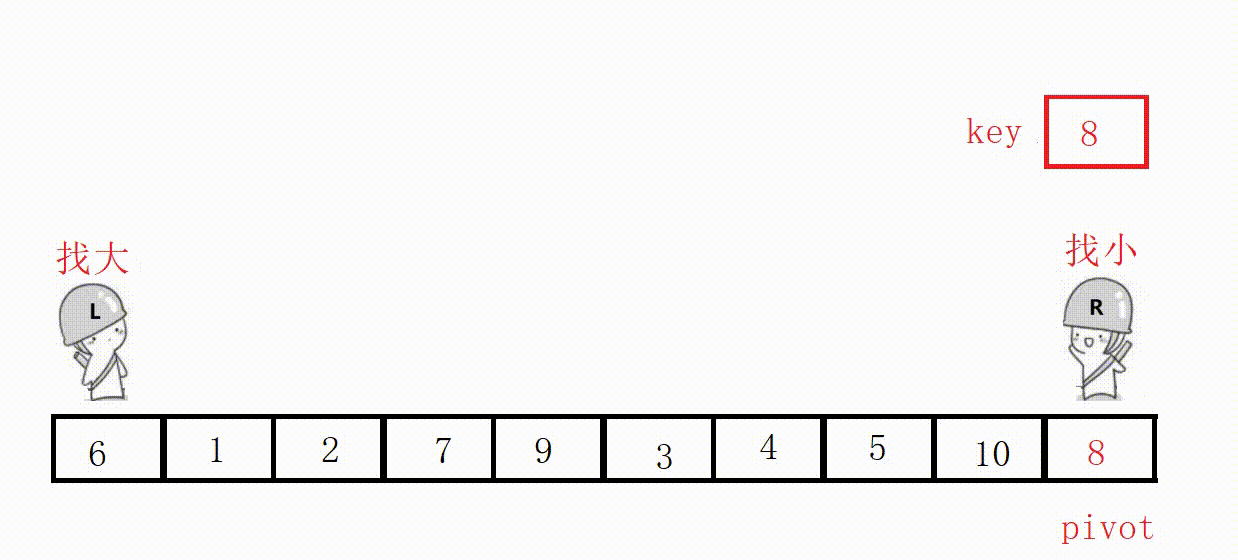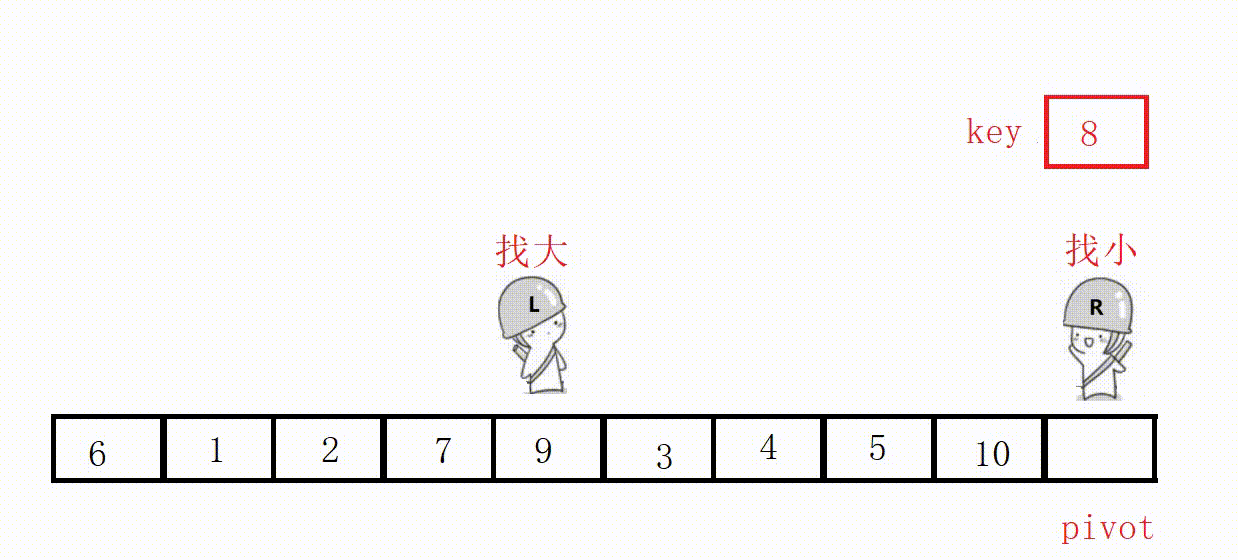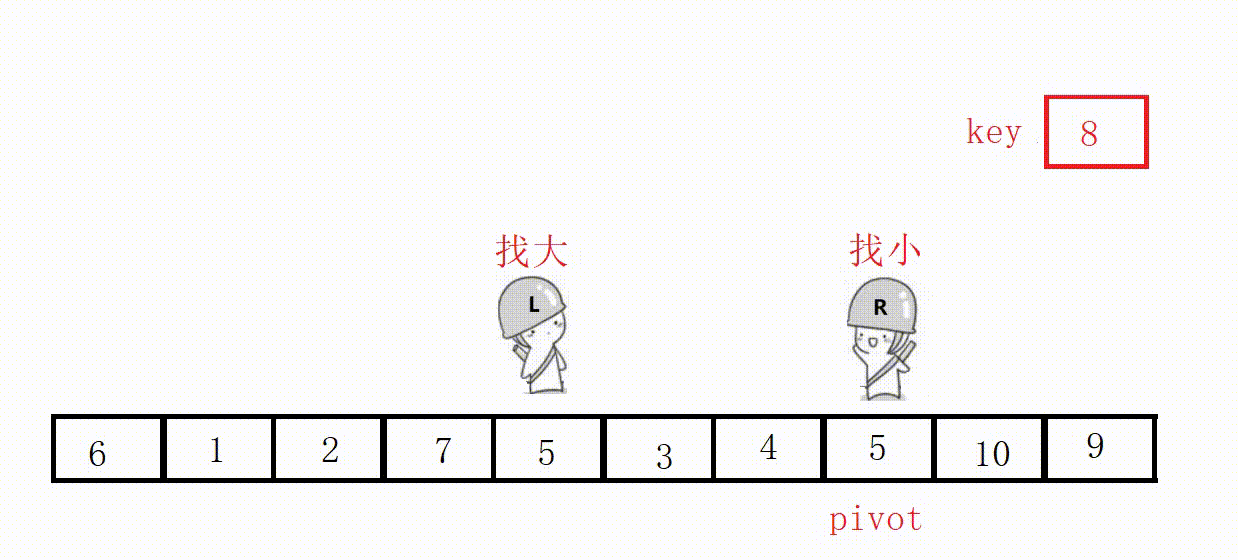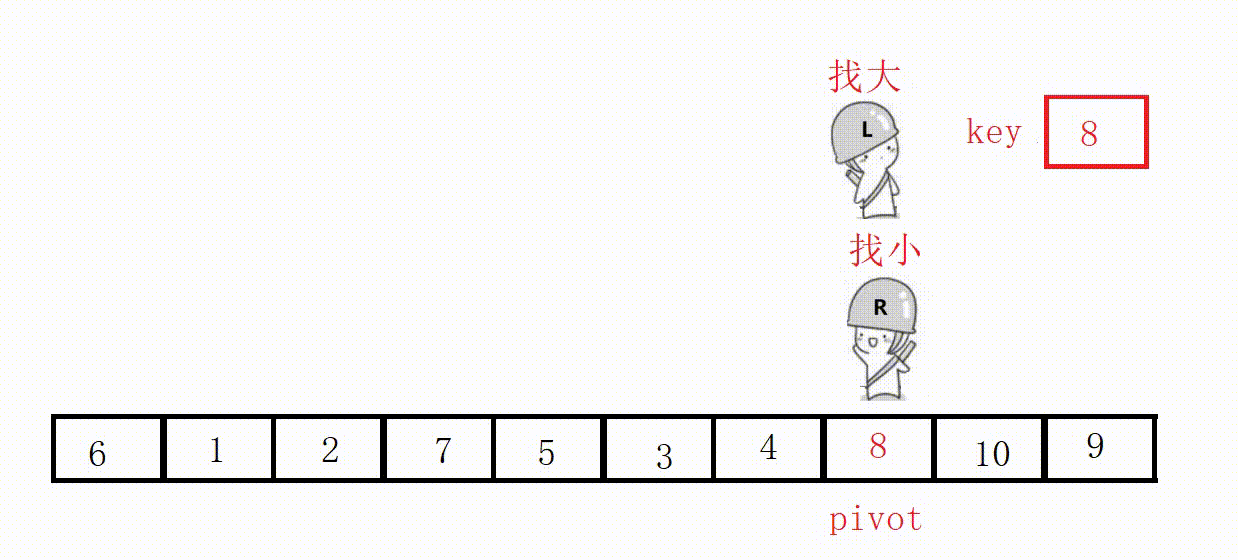
(3)前后指针法(推荐这种)
基础思路:
①定义两个指针prev和cur,prev表示左侧已处理区域的末尾,cur表示右侧未处理区域的起始。
②从cur开始向右扫描,如果扫描到的元素小于基准值,就将其与prev后面的元素交换,prev指针右移一位。
③最后将基准值插入到prev位置。
(这个过程其实相当于把比key小的值全都赶到左边)
选最左边为key,prev位置的值最后一定小于key。
图解:
代码:
//前后指针法 int partion3(int* a, int left, int right) { int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; }
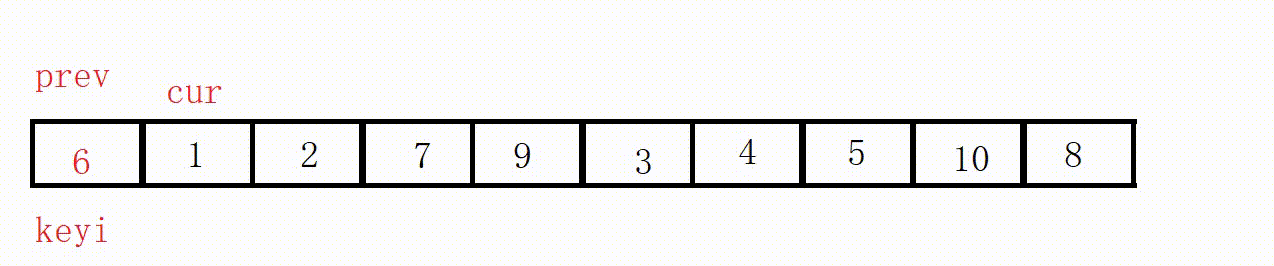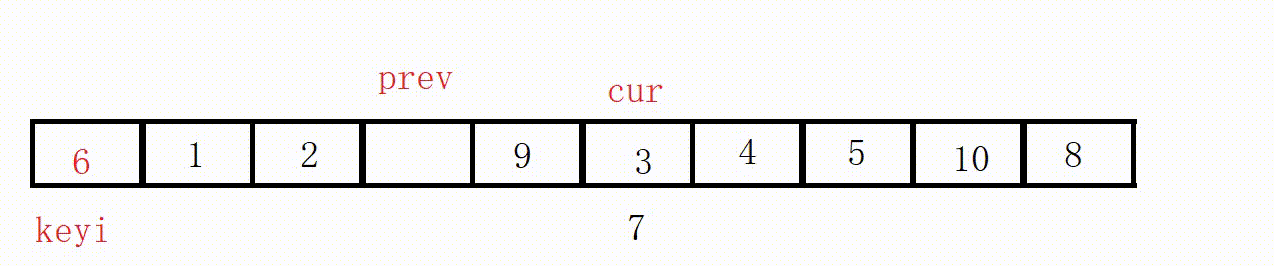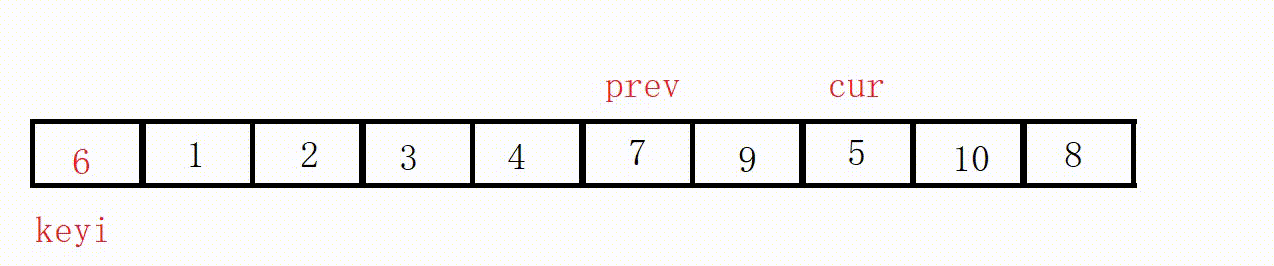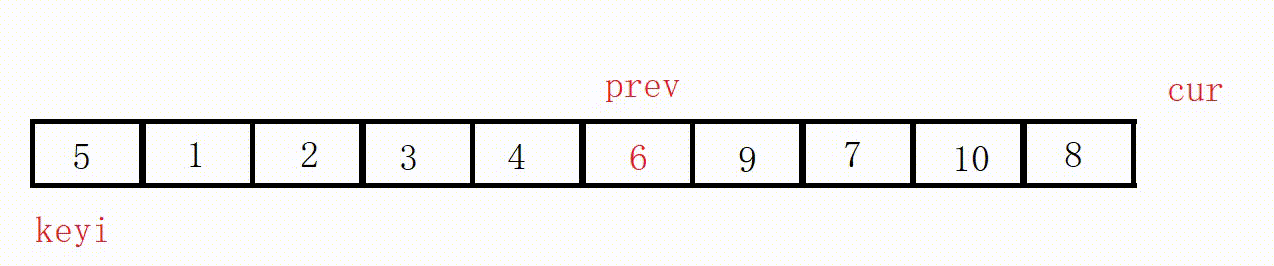
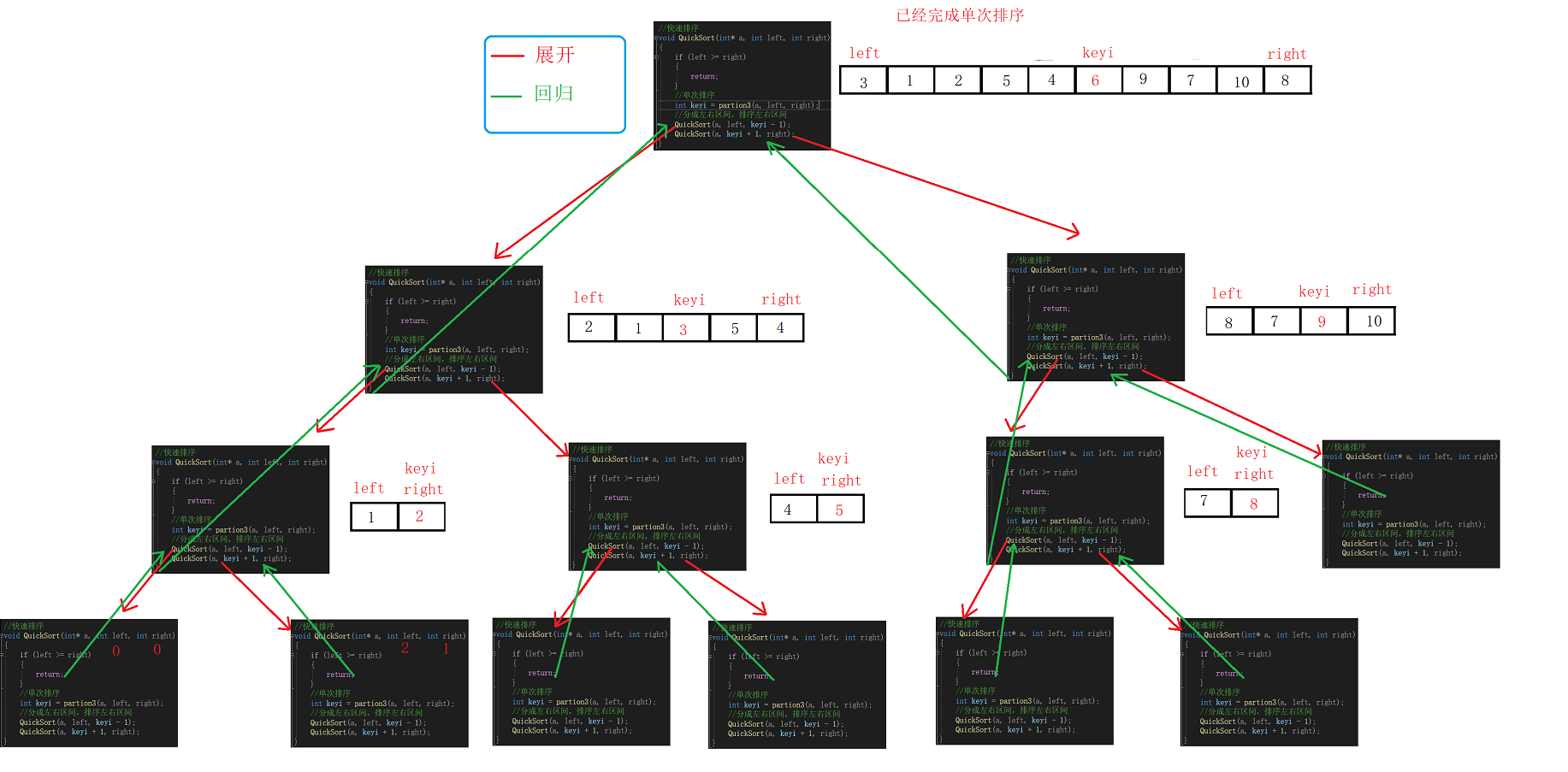
完整排序
完整排序的核心在于分治思想。
要排序整个数组,我们可以先确定key的位置,以这个位置为界分出左右两个区域。
排序左区域,我们先确定key的位置,以这个位置为界分出两个区域。
………………
一直细分到区域不存在(right<left)或者只有一个元素(right==left,相当于有序)。
然后用同样的方法排序右区域。
代码(未优化):
//单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; } //挖坑法单趟 int partion2(int* a, int left, int right) { int key = a[left]; int pivot = left; while (left < right) { //右边先走,找比key小的 while (right > left && a[right] >= key) { right--; } // 小的放到左边的坑里,自己形成新的坑位 a[pivot] = a[right]; pivot = right; //左边走,找比key大的 while (right > left && a[left] <= key) { left++; } // 大的放到右边的坑里,自己形成新的坑位 a[pivot] = a[left]; pivot = left; } a[pivot] = key; return pivot; } //前后指针法 int partion3(int* a, int left, int right) { int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //快速排序 void QuickSort(int* a, int left, int right) { //如果left>right,区间不存在 //left==right,只有一个元素,可以看成是有序的 if (left >= right) { return; } //单次排序 int keyi = partion3(a, left, right); //分成左右区间,排序左右区间 QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); }图解:
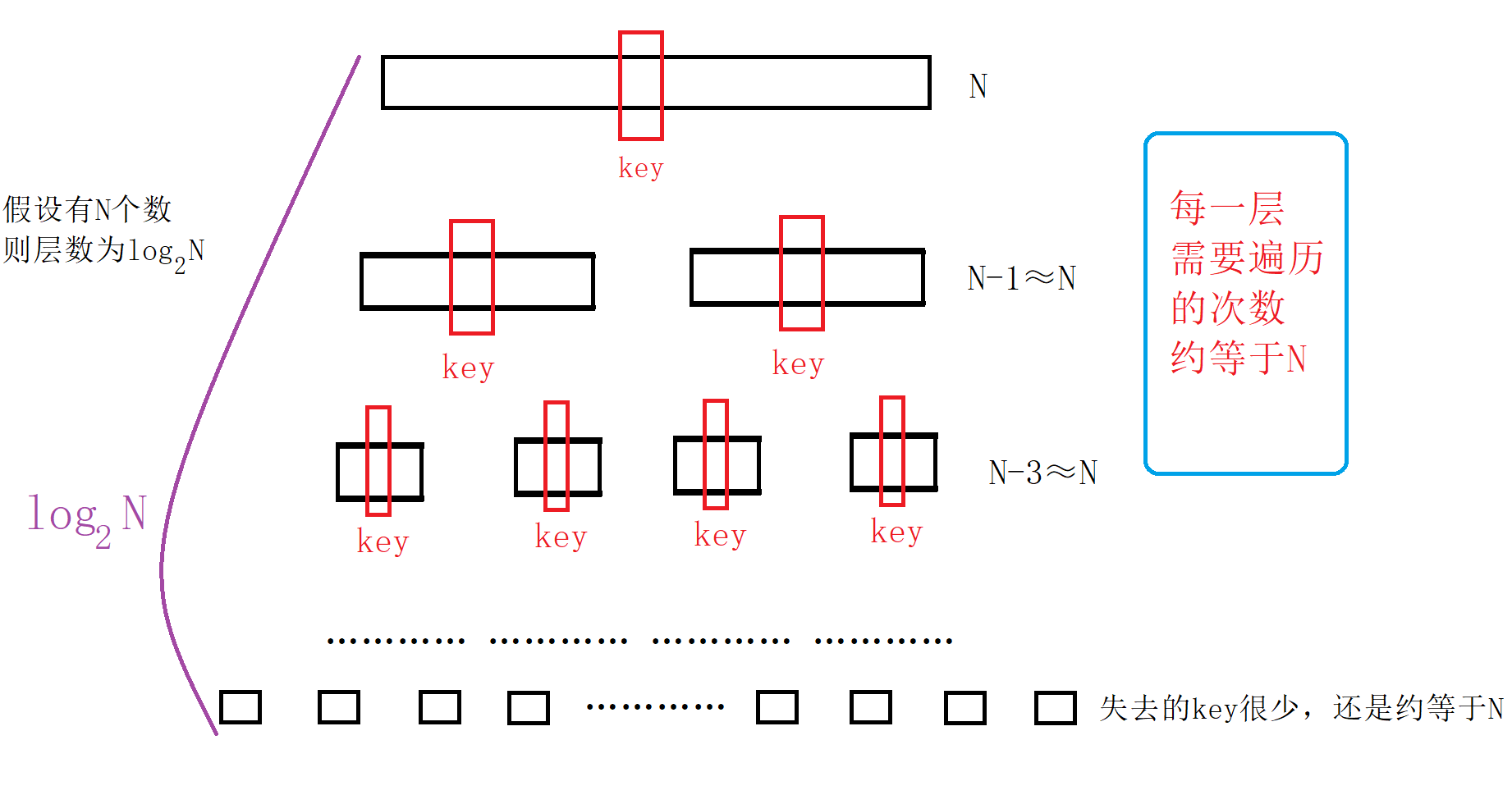
时间复杂度分析
假设有N个数,快速排序的时间复杂度一般在O(N*logN)
图解:
大多数情况都是上面这种情况,但也存在特殊的情况会使快速排序的效率降低,比如原数组有序(后面优化可以应对这种情况)或者数组中存在很多相同的数据,这个时候时间复杂度为O(N^2)。
优化
(1)三数取中
基础思路:
①既然有序会降低快排的排序效率,那我们可以自己打乱数组
②取到该区间的最左边数据和最右数据以及中间数据,取到中间值
③将这个中间值与我们选定的key交换
(这样每次key最后位置都接近中位数)
代码:
// 三数取中 int GetMidIndex(int* a, int left, int right) { int midi = left + (right - left) / 2; if (a[midi] > a[right]) { if (a[midi] < a[left]) return midi; else if (a[right] > a[left]) return right; else return left; } else // a[right] > a[mid] { if (a[midi] > a[left]) return midi; else if (a[left] < a[right]) return left; else return right; } } //单次快速排序,双向扫描法 int partion1(int* a, int left, int right) { //三数取中,打乱顺序 int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); //关键字下标 int keyi = left; while (right > left) { //右边先走,找比key小的 //加上right>left是为了让相遇的两者停下 //a[right]>=a[keyi]的目的是如果相同也跳过 //不然可能导致死循环,这里相遇的位置就是9 // right和left一直不进入循环,死循环 // 9, 3, 5, 2, 7, 8, 6, -1, 9, 4, 0 while (right > left && a[right] >= a[keyi]) { right--; } //左边走,找比key大的 while (right > left && a[left] <= a[keyi]) { left++; } //交换 swap(&a[left], &a[right]); } //最后相遇进行交换 swap(&a[left], &a[keyi]); return left; }
(2)小区间优化
就现在编译器的优化来说,只要控制得当,递归与非递归效率几乎无异
递归最大的缺点在于如果递归深度太深,可能会导致栈溢出。
小区间优化的目的就是将递归的最后几层(最后几层占到递归次数的90%)使用其它排序完成,这样就一定程度减少了栈溢出的可能(依然可能溢出)。
至于排序的选择,因为数据量很少,可以采用比较简单的排序,而且快排的过程区间不断接近有序,用直接插入排序是比较合适的。
代码:
//直接插入排序 void InsertSort(int* a, int n) { //断言,不能传空指针 assert(a); for (int i = 0; i < n - 1; i++) { int end = i; int x = a[end + 1]; //如果end < 0就代表这个数据是最小的 while (end >= 0) { //如果大于就向后覆盖,用x保存 if (a[end] > x) { a[end + 1] = a[end]; end--; } //如果小于就确定了插入位置 else { break; } } a[end + 1] = x; } } //快速排序 void QuickSort(int* a, int left, int right) { //如果left>right,区间不存在 //left==right,只有一个元素,可以看成是有序的 if (left >= right) { return; } //优化,减少递归次数(差不多三层),效率提升几乎没有 //小于10的区间(区间大小自己控制)用直接插入排序 if (right - left + 1 < 10) { InsertSort(a + left, right - left + 1); return; } else { //单次排序 int keyi = partion3(a, left, right); //分成左右区间,排序左右区间 QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); } }
三:非递归实现快速排序
基础思路
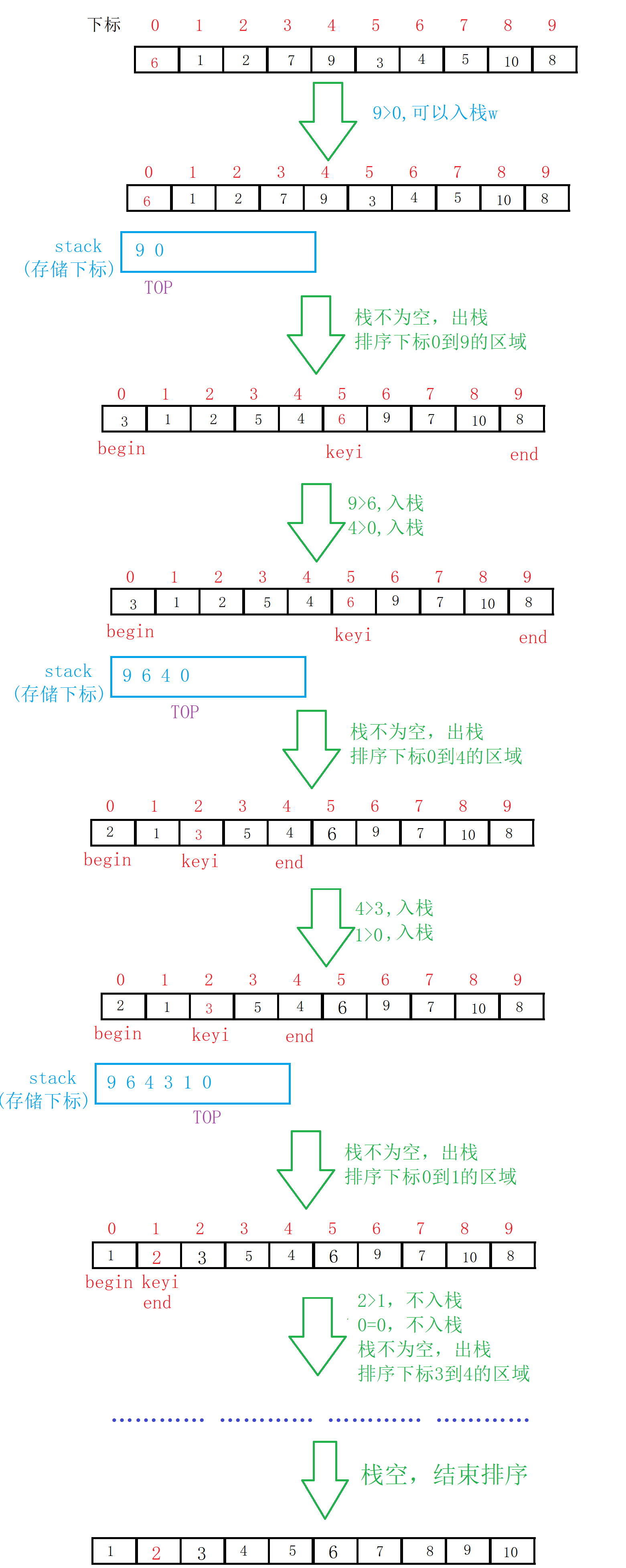
1.非递归实现的思想和递归一致,需要借助栈来模拟函数栈帧的建立销毁,将整个序列视为一个待排序的区间,并使用左右指针指向区间的两端;
2.将区间左右指针指向的范围分别作为待排序序列的左区间和右区间,并将区间信息保存到栈中。这一步相当于对待排序序列进行了压栈操作;
3.当栈不为空时,从栈顶弹出一个区间,并以该区间的左右指针为基准值进行快速排序。具体而言,对该区间进行划分,选出一个基准值,将数组分为两部分,并将左右区间分别压入栈中,以便之后进行排序;
4.重复执行步骤 3,直到栈为空为止。
完整排序
图解:
对栈的实现和性质有疑问的可以点下面的链接,这里直接给出代码
栈的实现:https://blog.csdn.net/2301_76269963/article/details/129823215?spm=1001.2014.3001.5502
代码:
//栈的代码 //重定义数据类型,方便更改 typedef int STDataType; typedef struct stack { //存储数据 STDataType* a; //栈顶(位置) int top; //容量 int capacity; }ST; //初始化 void StackInit(ST* ps) { //断言,不能传空指针进来 assert(ps ); //一开始指向NULL ps->a = NULL; //把栈顶和容量都置为空 ps->top = ps->capacity = 0; } //判断栈是否为空 bool StackEmpty(ST* ps) { //断言,不能传空指针进来 assert(ps); //依据top来判断 /*if (ps->top == 0) return true; return false;*/ //更简洁的写法,一个判断语句的值要么为true,要么false return ps->top == 0; } //销毁 void StackDestroy(ST* ps) { //断言,不能传空指针进来 assert(ps ); //栈顶和容量置为空 ps->top = ps->capacity = 0; //释放空间 free(ps->a); ps->a = NULL; } //入栈 void StackPush(ST* ps, STDataType x) { //断言,不能传空指针进来 assert(ps); //先判断是否扩容 if (ps->top == ps->capacity) { int newcapacity = ps->capacity == 0 ? 4 : (ps->capacity) * 2; //扩容 STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity); //扩容失败 if (tmp == NULL) { printf("realloc error\n"); exit(-1); } //更新 ps->capacity = newcapacity; ps->a = tmp; } //存储数据 ps->a[ps->top] = x; ps->top++; } //出栈(删除) void StackPop(ST* ps) { //断言,不能传空指针进来 assert(ps); //如果栈为空,不能出栈 assert(!StackEmpty(ps)); ps->top--; } //取顶部数据 STDataType StackTop(ST* ps) { //断言,不能传空指针进来 assert(ps); //如果栈为空,不能进行访问 assert(!StackEmpty(ps)); //返回栈顶数据 return ps->a[ps->top-1]; } //前后指针法 int partion3(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //非递归快排 void QuickSortNonR(int* a, int left, int right) { ST s; StackInit(&s); StackPush(&s, right); StackPush(&s, left); //栈不为空,循环继续 while (!StackEmpty(&s)) { int begin = StackTop(&s); StackPop(&s); int end = StackTop(&s); StackPop(&s); int keyi = partion3(a, begin, end); //要先排序左区间,先入右区间,后进先出 //不满足条件代表区间不存在或者区间元素个数为1 if (keyi + 1 < end) { StackPush(&s, end); StackPush(&s, keyi + 1); } if (begin < keyi - 1) { StackPush(&s, keyi-1); StackPush(&s, begin); } } }
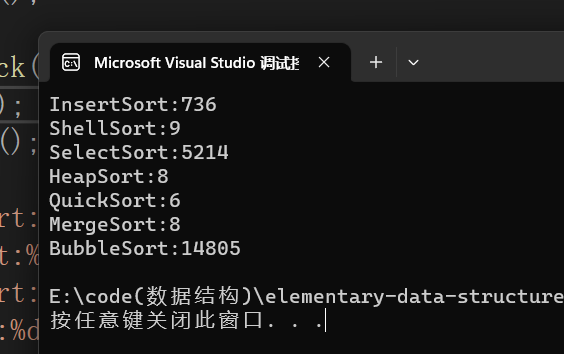
四:效率对比
代码:
// 测试排序的性能对比 void TestOP() { srand(time(0)); //随机生成十万个数 const int N = 100000; int* a1 = (int*)malloc(sizeof(int) * N); int* a2 = (int*)malloc(sizeof(int) * N); int* a3 = (int*)malloc(sizeof(int) * N); int* a4 = (int*)malloc(sizeof(int) * N); //5和6是给快速排序和归并排序的 int* a5 = (int*)malloc(sizeof(int) * N); int* a6 = (int*)malloc(sizeof(int) * N); int* a7 = (int*)malloc(sizeof(int) * N); if (a1==NULL || a2==NULL ) { printf("malloc error\n"); exit(-1); } if (a3 == NULL || a4 == NULL) { printf("malloc error\n"); exit(-1); } if (a5 == NULL || a6 == NULL || a7 == NULL) { printf("malloc error\n"); exit(-1); } for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; a3[i] = a1[i]; a4[i] = a1[i]; a5[i] = a1[i]; a6[i] = a1[i]; a7[i] = a1[i]; } //clock函数可以获取当前程序时间 int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); int begin3 = clock(); SelectSort(a3, N); int end3 = clock(); int begin4 = clock(); HeapSort(a4, N); int end4 = clock(); int begin5 = clock(); QuickSort(a5, 0, N - 1); int end5 = clock(); int begin6 = clock(); MergeSort(a6, N); int end6 = clock(); int begin7 = clock(); BubbleSort(a7, N); int end7 = clock(); printf("InsertSort:%d\n", end1 - begin1); printf("ShellSort:%d\n", end2 - begin2); printf("SelectSort:%d\n", end3 - begin3); printf("HeapSort:%d\n", end4 - begin4); printf("QuickSort:%d\n", end5 - begin5); printf("MergeSort:%d\n", end6 - begin6); printf("BubbleSort:%d\n", end7 - begin7); free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); free(a7); } int main() { //测试效率 TestOP(); }