目录
一、前言
二、管道
1、匿名管道
1.1、基本原理
1.2、代码实现
1.3、管道的特点
1.4、基于管道的简单设计
2、命名管道
2.1、匿名管道与命名管道的区别
2.2、代码实现命名管道通信
一、前言
为了满足各种需求,进程之间是需要通信的。进程间通信的主要目的包括如下几个方面:
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
因为进程具有独立性,这增加了通信的成本。要让两个不同的进程通信,前提条件是先让两个进程看到同一份“资源”,这份“资源”通常是由OS直接或间接提供的。
所以任何进程通信手段,无非都包含如下步骤:
- 想办法先让不同的进程看到同一份资源。
- 让一方写入,另一方读取,完成通信过程。
- 至于通信目的与后续工作,要结合具体场景具体分析。
进程间通信可以分为三类:
- 管道
- System V IPC
- POSIX IPC
这三类方法,都是在解决第一个步骤,即让不同的进程看到同一份“资源”。本篇博客针对于管道进行讲解。
二、管道
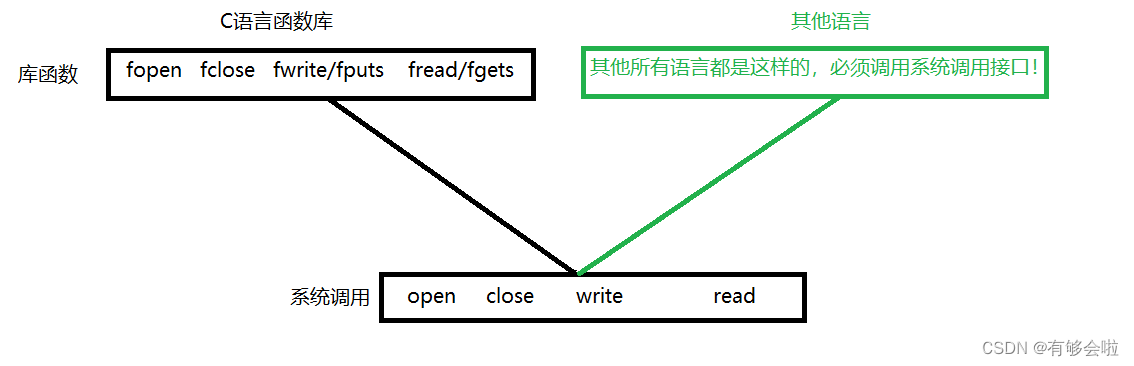
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。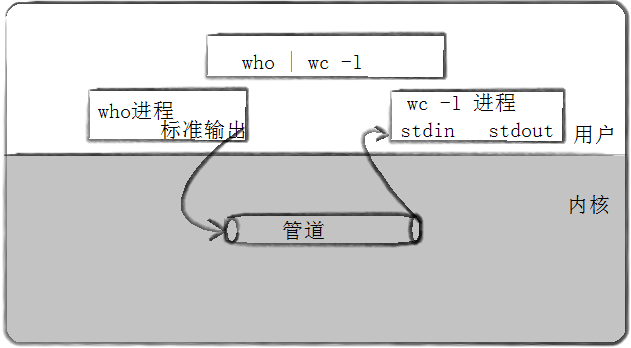
管道也是文件。在使用管道符 "|" 时, "|" 左边的进程以写的方式打开管道文件,将标准输出重定向到管道之中, "|" 右边的进程以读的方式打开管道文件,将标准输入重定向到管道之中。
1、匿名管道
1.1、基本原理
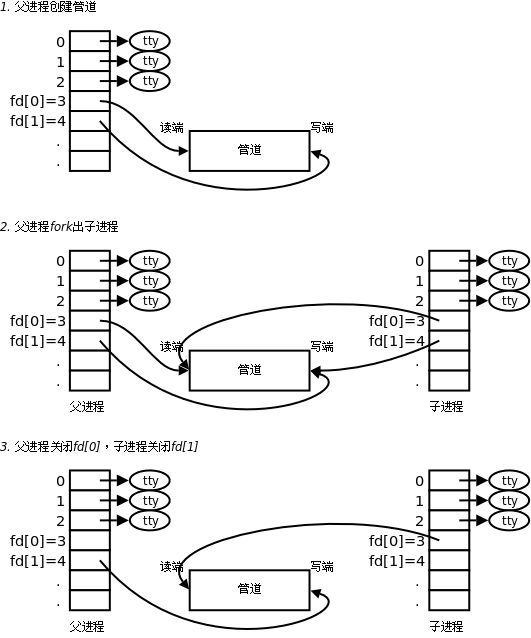
在文章《文件描述符》中,对已经打开的文件与进程的关系进行了较为详细的说明,文件描述符的 0、1、2 默认为标准输入、标准输出、标准错误。这些文件都有对应的缓冲区。
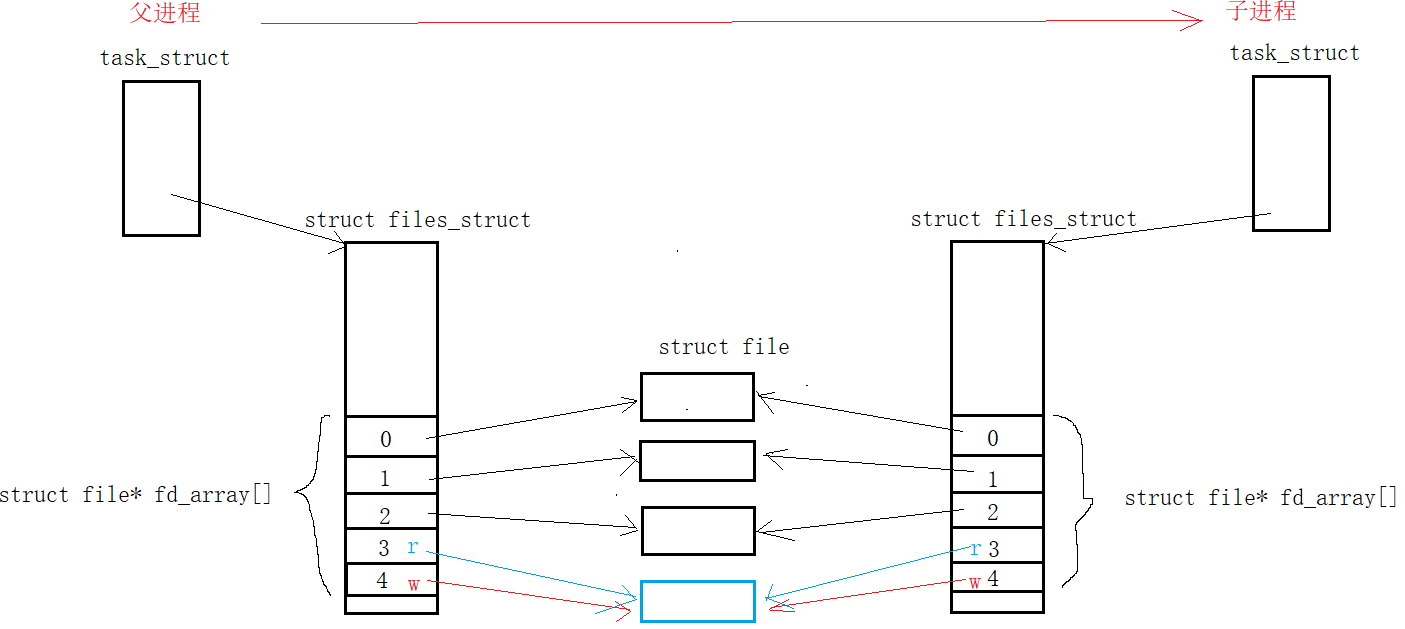
匿名管道文件是OS提供的内存文件,仅存在于内存,而并不需要将该文件的内容刷新到磁盘之中。OS通过某些方式,使用读方式和写方式分别打开这个匿名管道文件。
该进程通过 fork 创建一个子进程,子进程拷贝了父进程的PCB结构,包括 task_struct 与 struct files_struct 。因此子进程的文件描述符表中存储的指针也被拷贝下来了,指向同一批文件对象(创建子进程的时候,fork子进程,只会复制进程相关的数据结构对象,不会复制父进程曾经打开的文件对象)。这时,我们就做到了进程间通信的前提:让不同的进程看到同一份“资源”。
这种管道只支持单向通信,因此在进程通信的时候,需要确定数据的流向,分别关闭和保留父子进程文件描述符表中的读与写端。这是因为文件对象只有一个缓冲区,难以做到同时读写。
进程创建管道的具体过程如下:
1.2、代码实现
创建管道函数:
int pipe(int pipefd[2]);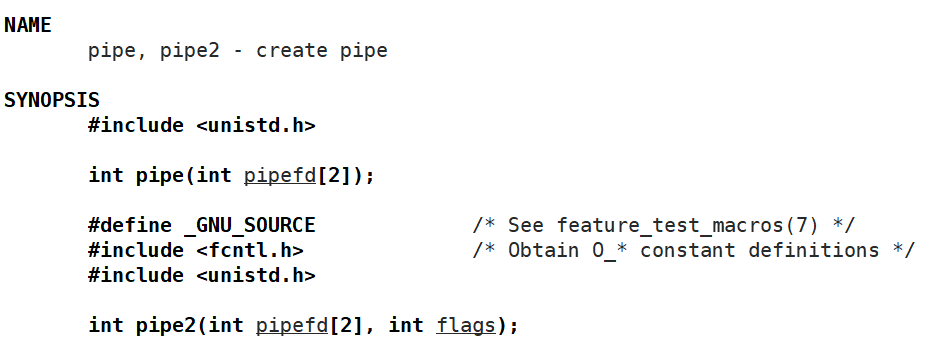
pipe 系统调用函数的参数列表中有一个数组,是一个输出型参数。如果创建成功,函数返回值是 0 ,失败返回值为 -1 。因为系统调用接口的底层是使用C语言编写的,所以错误码 errno 会被设置。具体用法如下:
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <cerrno>
#include <assert.h>
#include <string.h>
using namespace std;
int main()
{
int pipefd[2] = {0};
//1.创建管道
int n = pipe(pipefd);
if(n < 0)
{
cout << "pipe error, " << errno << ": " << strerror(errno) << endl;
return 1;
}
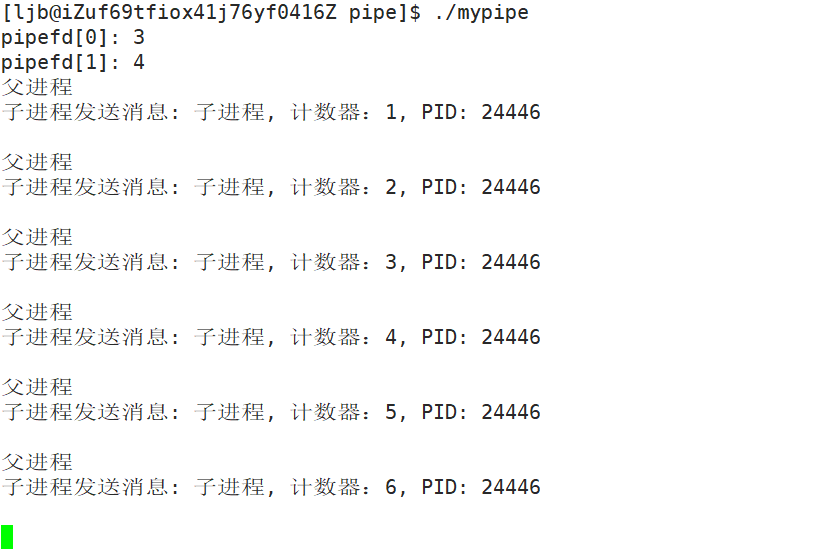
cout << "pipefd[0]: " << pipefd[0] << endl; //读端
cout << "pipefd[1]: " << pipefd[1] << endl; //写端
//2.创建子进程
pid_t id = fork();
assert(id != -1);
if(id == 0)
{
//子进程
//3.关闭不需要的fd
//这里让父进程读,子进程写
close(pipefd[0]);
//4.开始通信
string namestr = "子进程";
int cnt = 1;
char buffer[1024];
while(1)
{
snprintf(buffer, sizeof(buffer), "%s, 计数器:%d, PID: %d\n", namestr.c_str(), cnt++, getpid());
write(pipefd[1], buffer, strlen(buffer));
sleep(1);
}
exit(0);
}
//父进程
close(pipefd[1]);
char buffer[1024];
while(1)
{
int n = read(pipefd[0], buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n] = '\0';
cout << "父进程" << endl;
cout << "子进程发送消息: " << buffer << endl;
}
}
return 0;
}编译并运行:
1.3、管道的特点
- 管道是单向通信的.
- 管道本质是文件。因为文件描述符的生命周期是随进程的,所以管道的生命周期也是随进程的。
- 管道通信,通常用来进行具有“血缘”关系的进程之间的通信。如父子进程间通信。
- pipe系统调用打开的管道,并不清楚它的名字,称之为匿名管道。
- 在管道通信中,写入的次数与读取的次数,不是严格匹配的。
- 管道具有一定的协同能力,让读端与写端按照一定的步骤进行通信:
1)如果读端读取完毕了所有的管道数据,此时如果写端不写,读端就只能等待。
2)如果写端将管道写满了,就无法再继续写入,等读端读取之后才能继续写。
3)如果关闭了写端,读端读取完毕管道数据后,再读,read就会返回 0 ,表明读到了文件结尾。
4)如果写端一直在写,并关闭了读端,那么OS会通过信号终止一直在写入的进程。因为OS不会维护无意义、低效率、浪费资源的事情。 - 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
1.4、基于管道的简单设计
现在我们来实现由一个父进程通过管道向多个子进程写入特定消息,让子进程定向执行某种任务的代码:
//task.hpp
#pragma once
#include <iostream>
#include <vector>
#include <unistd.h>
typedef void (*fun_t)();
void Print()
{
std::cout << "pid: " << getpid() << "打印任务正在执行" << std::endl;
}
void InsertMySQL()
{
std::cout << "pid: " << getpid() << "数据库任务正在执行" << std::endl;
}
void NetRequest()
{
std::cout << "pid: " << getpid() << "网络请求任务正在执行" << std::endl;
}
//约定每一个command都是4个字节
#define COMMAND_PRINT 0
#define COMMAND_MYSQL 1
#define COMMAND_REQEUST 2
class Task
{
public:
Task()
{
funcs.push_back(Print);
funcs.push_back(InsertMySQL);
funcs.push_back(NetRequest);
}
void Execute(int command)
{
if(command >= 0 && command < funcs.size())
{
funcs[command];
}
}
~Task(){}
public:
std::vector<fun_t> funcs;
};
//ctrlProcess.cc
#include <iostream>
#include <string>
#include <vector>
#include <cassert>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include "task.hpp"
using namespace std;
const int gnum = 3;
Task t;
class EndPoint
{
private:
static int number;
public:
pid_t _child_id;
int _write_fd;
string processname;
public:
EndPoint(int id, int fd):_child_id(id),_write_fd(fd)
{
char namebuffer[64];
snprintf(namebuffer, sizeof(namebuffer), "process-%d[%d:%d]", number++, _child_id, _write_fd);
processname = namebuffer;
}
const string& name() const
{
return processname;
}
~EndPoint(){}
};
int EndPoint::number = 0;
//子进程要执行的方法
void WaitCommand()
{
while(1)
{
char command = 0;
int n = read(0, &command, sizeof(int));
if(n == sizeof(int))
{
t.Execute(command);
}
else if(n == 0)
{
cout << "父进程让我退出,我的pid:" << getpid() << endl;
break;
}
else
{
break;
}
}
}
void creatProcesses(vector<EndPoint>* end_points)
{
for(int i = 0; i < gnum; ++i)
{
//创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0);
(void)n;
//创建进程
pid_t id = fork();
assert(id != -1);
if(id == 0)
{
//子进程
close(pipefd[1]);
//我们期望,所有的子进程读取“指令”,都从标准输入读取
//输入重定向,也可以不重定向,只要在WaitCommand函数里传参fd就可以了
dup2(pipefd[0], 0);
//子进程开始等待获取命令
WaitCommand();
exit(0);
}
//父进程
close(pipefd[0]);
//将新的子进程和他的管道写端构造对象
end_points->push_back(EndPoint(id, pipefd[1]));
}
}
int ShowBoard()
{
cout << "########################################" << endl;
cout << "### 0.执行打印任务 1.执行数据库任务###" << endl;
cout << "### 2.执行请求任务 3.退出 ###" << endl;
cout << "########################################" << endl;
cout << "请选择" << endl;
int command = 0;
cin >> command;
return command;
}
void ctrlProcess(const vector<EndPoint>& end_points)
{
int num = 0;
int cnt = 0;
while(1)
{
//选择任务
int command = ShowBoard();
if(command == 3) break;
if(command < 0 || command > 2) continue;
//选择进程
int index = cnt++;
cnt %= end_points.size();
cout << "选择了进程: " << end_points[index].name() << " | 处理任务: " << command << endl;
//下发任务
write(end_points[index]._write_fd, &command, sizeof(command));
}
}
// void WaitProcess(const vector<EndPoint>& end_points)
// {
// //让子进程全部退出,通过关闭写端的方式
// for(const auto& ep : end_points) close(ep._write_fd);
// cout << "父进程让所有子进程退出" << endl;
// sleep(5);
// //父进程回收子进程的僵尸状态
// for(const auto& ep : end_points) waitpid(ep._child_id, nullptr, 0);
// cout << "父进程回收了所有的子进程" << endl;
// sleep(1);
// }
void WaitProcess(const vector<EndPoint>& end_points)
{
for(int end = end_points.size() - 1; end >= 0; --end)
{
cout << "父进程让我退出: " << end_points[end]._child_id << endl;
close(end_points[end]._write_fd);
waitpid(end_points[end]._child_id, nullptr, 0);
cout << "父进程回收了子进程:" << end_points[end]._child_id << endl;
}
sleep(10);
}
int main()
{
//先进行构建控制结构,父进程写入,子进程读取
vector<EndPoint> end_points;
creatProcesses(&end_points);
ctrlProcess(end_points);
//处理退出问题
WaitProcess(end_points);
return 0;
}
其中, WaitProcess 函数内,退出进程的循环要在 vector 中从后向前遍历:
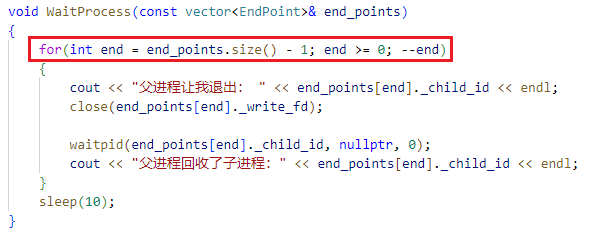
这是因为我们使用的进程退出方式,是通过关闭父进程写端的文件对象,让OS杀死子进程实现的。而在我们创建子进程与管道的 creatProcesses 函数中,是通过循环一个一个创建的:
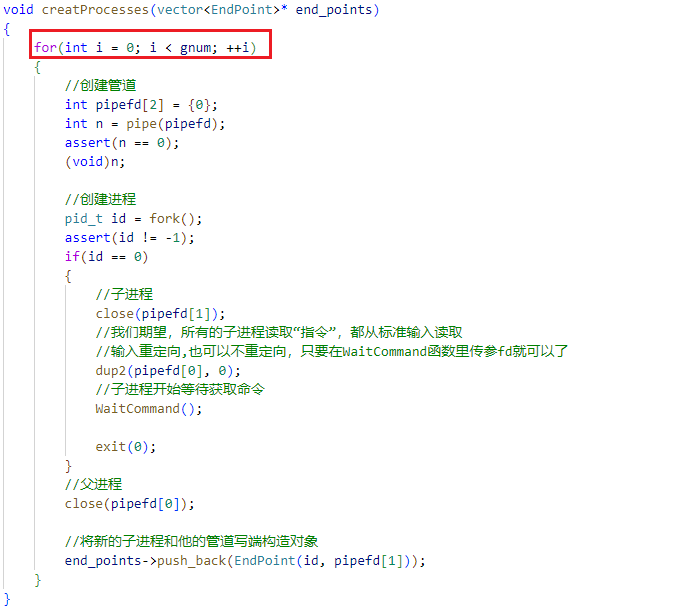
这种创建方式在创建第一组管道与子进程时不会有任何问题。但是在之后创建第二、第三组乃至更多时,由于它们的 task_struct 也是父进程的拷贝,就会导致后面子进程的文件描述符表里保留指向前几个管道的指针:
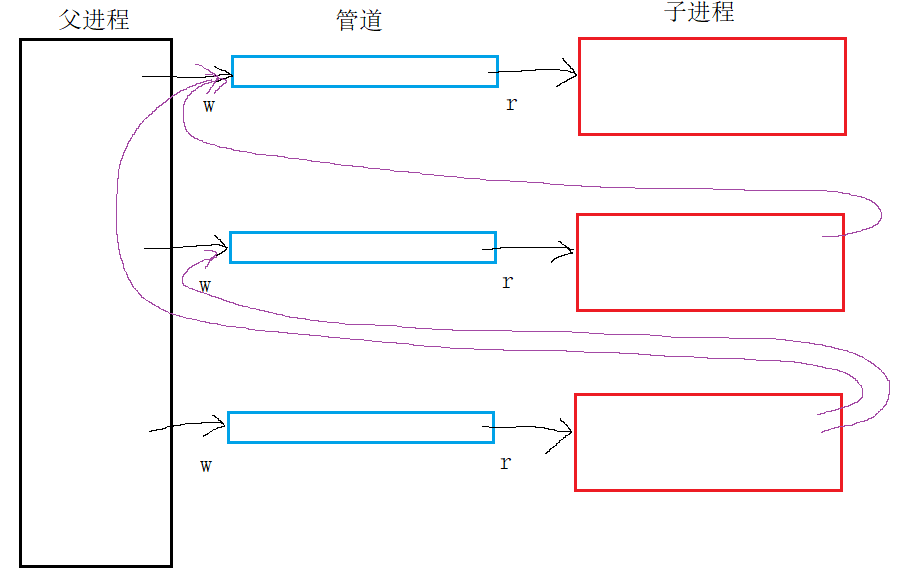
如果是从前向后依次关闭父进程的写端,那么因为第一个子进程对应的管道的写端不只有父进程一个,还有其他两个子进程,因此第一个子进程就不会被OS杀死,从而在下面执行 waitpid 函数时造成堵塞。
为了真正构建每一个管道的写端都只有父进程一个的构造,则可以改写 creatProcesses 函数的代码:
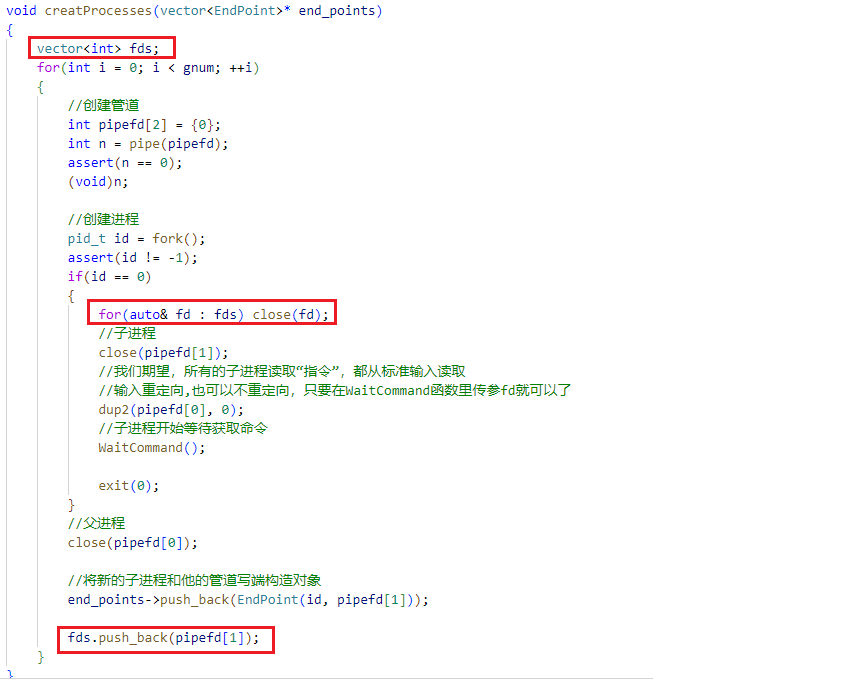
在创建时就直接关闭子进程对应的写端文件。
2、命名管道
- 管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
- 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
- 命名管道是一种特殊类型的文件
命名管道的打开规则:
- 如果当前打开操作是为读而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
O_NONBLOCK enable:立刻返回成功 - 如果当前打开操作是为写而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
O_NONBLOCK enable:立刻返回失败,错误码为ENXIO
创建命名管道指令:
mkfifo [OPTION]... NAME...
具体用法如下:
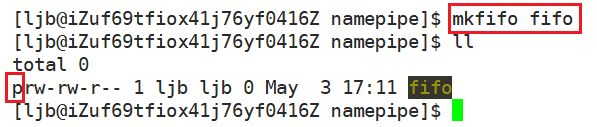
可以看到 fifo 是管道文件。
2.1、匿名管道与命名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,打开用open。
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
命名管道虽然有自己的 inode ,存在于磁盘上,但也仅仅只有 inode ,代表它存在,而没有自己的 datablock 。与匿名管道相同,命名管道也是内存级的文件,不存在刷盘操作。
我们通过创建命名管道,也可以让不同的进程通过文件路径 + 文件名找到同一个文件,并打开它,让不同的进程看到同一份资源,具备了进程间通信的前提。
2.2、代码实现命名管道通信
创建命名管道文件的系统调用:
int mkfifo(const char *pathname, mode_t mode);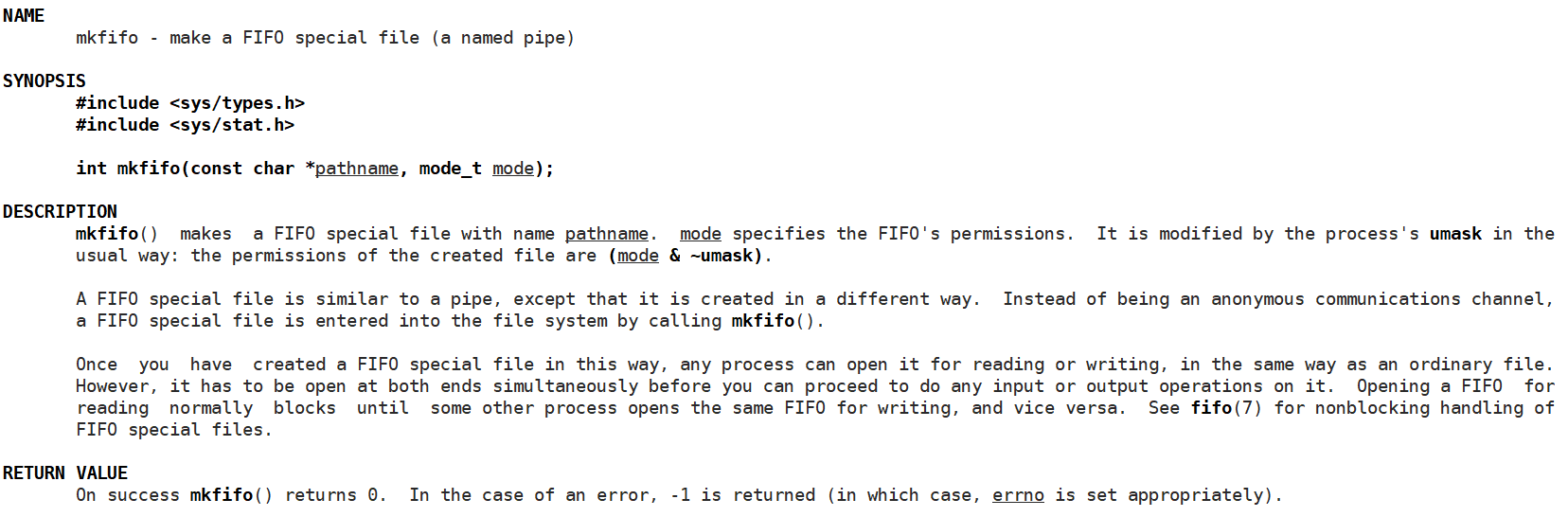
mkfifo 函数的参数列表中, pathname 为创建文件的路径与文件名,如果不指定路径,默认为当前路径。 mode 为创建文件的权限。创建成功就返回 0 。创建失败返回 -1,并且错误码会被设置。
具体代码如下:
//makefile
.PHONY:all
all:server client
server:server.cc
g++ -o $@ $^ -std=c++11
client:client.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f server client
//comm.hpp
#pragma once
#include <iostream>
#include <string>
#define NUM 1024
const std::string fifoname = "./fifo";
uint32_t mode = 0666;
//server.cc
#include <iostream>
#include <cerrno>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include "comm.hpp"
using namespace std;
int main()
{
//创建一个管道文件
umask(0); //这个设置不会影响系统默认设置,只会影响当前进程
int n = mkfifo(fifoname.c_str(), mode);
if(n != 0)
{
cout << errno << " : " << strerror(errno) << endl;
return 1;
}
//让服务器开启管道文件
int rfd = open(fifoname.c_str(), O_RDONLY);
if(rfd <= 0)
{
cout << errno << " : " << strerror(errno) << endl;
return 2;
}
//正常通信
char buffer[NUM];
while(1)
{
buffer[0] = 0;
ssize_t n = read(rfd, buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n] = 0;
cout << "client: " << buffer << endl;
}
else if(n == 0)
{
cout << "client quit, me too" << endl;
break;
}
else
{
cout << errno << " : " << strerror(errno) << endl;
break;
}
}
//关闭文件
close(rfd);
unlink(fifoname.c_str()); //把管道文件删掉
return 0;
}
//client.cc
#include <iostream>
#include <cstdio>
#include <cerrno>
#include <cstring>
#include <assert.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include "comm.hpp"
using namespace std;
int main()
{
//不需要创建管道文件,只需要打开就可以了
int wfd = open(fifoname.c_str(), O_WRONLY);
if(wfd < 0)
{
cerr << errno << " : " << strerror(errno) << endl;
return 1;
}
//正常通信
char buffer[NUM];
while(1)
{
cout << "输入数据:";
char* msg = fgets(buffer, sizeof(buffer), stdin); //不用 -1
assert(msg);
(void)msg;
if(strcasecmp(buffer, "quit") == 0) break;
ssize_t n = write(wfd, buffer, strlen(buffer)); //不用 +1
assert(n > 0);
(void)n;
}
return 0;
}运行观察现象:
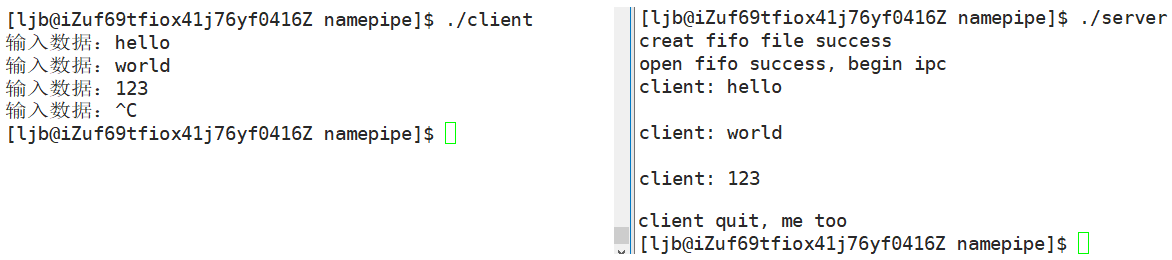
与匿名管道不同,匿名管道在创建时,默认读写端都是打开的。而命名管道在打开文件阶段会被卡住,只有当我们把读端和写端都手动打开后,程序才能继续向下运行。
之所以在 server 端读取的数据中间有一行空行,是因为发送的时候会按下回车键,回车键也会被读取。为了解决这个问题,可以做如下更改:
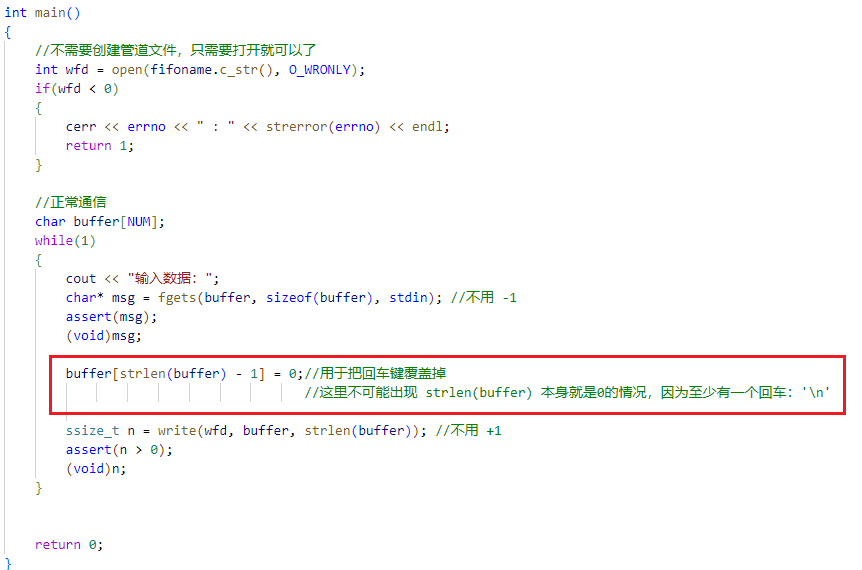
观察结果:
关于管道的内容就讲到这里,希望同学们多多支持,如果有不对的地方欢迎大佬指正,谢谢!