这篇是清华大学发表在IV(IEEE Transactions on Intelligent Vehicles)上的文章: Bridging the view disparity between radar and camera features for multi-modal fusion 3d object detection
文章信息讲得比较细致,非常值得一看;
一、创新点和贡献
1. 提出了一种多视图,2阶段的camera-radar的融合方法;
2. 提出了一个同时考虑时间和空间信息的radar feature encoder;
3. 用radar信息产生高维的热力图, 加强对于空间信息的回归;
4. 在nuScenes上效果很好;
二、精度

三、实现


3.1 radar 分支

多帧叠加到当前时刻的某个参考坐标系(比如前雷达)
置信度过滤
voxel或者pillar based的encoder提取空间特征
convLSTM提取时间特征
3.2 图片分支

和LSS基本上是一致的
3.3 融合分支
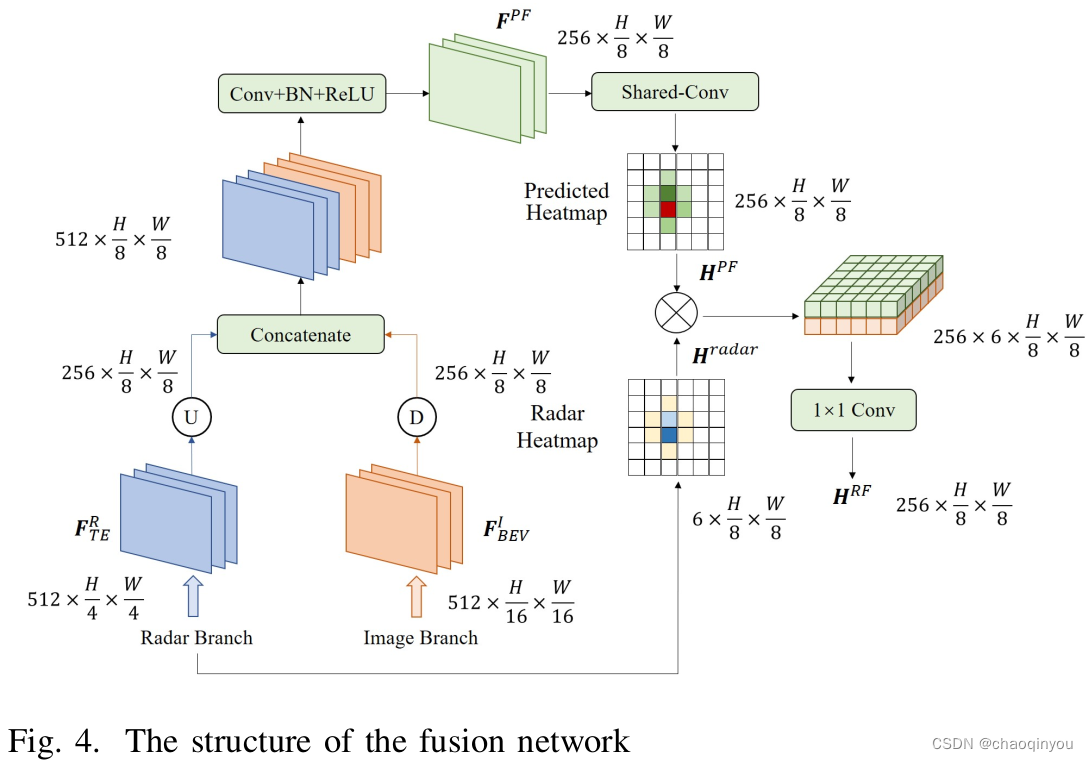
我理解,RoI融合,使用radar分支产生的6个方面的置信度,把point fuse的feature扩散到(1536=256*6) 个维度,也有点像LSS;