基于微服务架构,由于服务拆分粒度比较细,并且服务复用范围增大,不太可能再通过人工登记的方式进行接口调用情况的管理,因此对于每个请求的调用情况追踪将成为不可忽视的问题。追踪请求的调用情况,主要有几个作用:
- 当请求发生失败时,可以快速排查到在哪个微服务出现问题,并获取到失败的信息
- 当请求响应时间超过预期时,可以分析调用链路上的每个服务处理时长,从而找到性能瓶颈并进行优化
- 完整呈现一笔交易的处理过程,便于分析和优化;同时也有利于评估某个微服务升级时的影响范围
调用链定义
在系统完成一次业务调用的过程中,把服务之间的调用信息(时间、接口、层次、结果)打点到日志中,然后将所有的打点数据连接为一个树状链条就产生了一个调用链。跟踪系统把过程中产生的日志信息进行分析处理,将业务端到端的执行完整的调用过程进行还原,根据不同维度进行统计分析;从而标识出有异常的服务调用,能够快速分析定界到出异常的服务;同时可根据数据统计分析系统性能瓶颈。
调用链追踪原理
微服务的调用链追踪原理其实也满简单的,跟人工追踪的思考方向基本一样,就是通过服务所记录的日志信息进行匹配和分析,从而找到一个请求的所有相关调用记录而形成调用链条。不过为了能把不同的调用日志关联起来,需要有一些特殊的信息辅助分析:
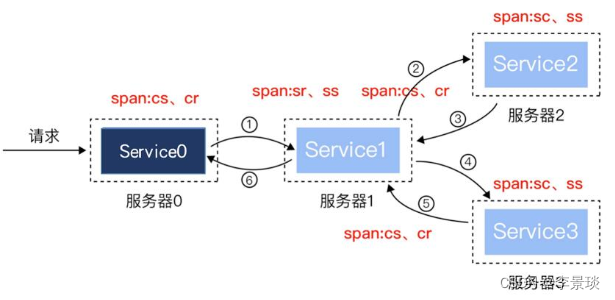
- 调用链的唯一标识:一个请求的所有调用日志信息都要记录一个相同的标识,这样才能把记录关联起来,这个唯一标识可以称为追踪标识(trace_id),由第一个发起的请求生成,并传递到后续的每次调用进行记录
- 每次调用的唯一标识:服务端在接收到请求后,要生成一个唯一标识标记该次调用,一方面通过该标识可以在调用链中区分不同的调用(有可能同一个接口被调用多次的情况),另外一方面该标识也要传递给本次服务过程中需要执行的子调用(下一个服务),并作为子调用信息的父调用标识,从而形成直接相邻调用之间的上下级关联关系。我们可以把每次调用称为一个时间跨度(Span),调用的唯一标识称为时间跨度标识(span_id),由服务端生成,并传递到下一个调用使用
- 时间信息:服务端必须在接收到请求时记录开始时间(start timestamp),并在结束调用时记录结束时间(finish timestamp),这样才能对不同的调用顺序进行排序,同时分析当次服务调用的耗时。
有了上面的几个特殊的信息,我们就可以把一次请求的整个调用链条关联起来:通过trace_id找到所有调用日志,通过span_id和每次调用的父span_id形成调用关系,通过timestamp形成调用的先后顺序,从而形成一个有向无环图(DAG图),这就是我们所需要追踪的调用链。
选型对比
Zipkin是Twitter开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单。
Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
SkyWalking是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
CAT是大众点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
| 对比项 | Zipkin | Pinpoint | SkyWalking | CAT |
|---|---|---|---|---|
| 实现方式 | 拦截请求,发送(HTTP,mq)数据至zipkin服务 | java探针,字节码增强 | java探针,字节码增强 | 代码埋点(拦截器,注解,过滤器等) |
| 接入方式 | 基于linkerd或者sleuth方式,引入配置即可 | javaagent字节码 | javaagent字节码 | 代码侵入 |
| agent到collector的协议 | http,MQ | thrift | gRPC | http/tcp |
| OpenTracing | 支持 | 不支持 | 支持 | 不支持 |
| 颗粒度 | 接口级 | 方法级 | 方法级 | 代码级 |
| 全局调用统计 | 不支持 | 支持 | 支持 | 支持 |
| traceid查询 | 支持 | 不支持 | 支持 | 不支持 |
| 报警 | 不支持 | 支持 | 支持 | 支持 |
| JVM监控 | 不支持 | 不支持 | 支持 | 支持 |
| UI功能 | ** | ***** | **** | ***** |
| 数据存储 | ES/mysql/Cassandra/内存 | Hbase | ES/H2 | mysql/hdfs |
| 社区活跃度star | 8.4k | 5.9k | 3.3k | 4.9k |
PinPoint和skyWalking支持的插件对比
| 类别 | Pinpoint | SkyWalking |
|---|---|---|
| web容器 | Tomcat6/7/8,Resin,Jetty,JBoss,Websphere | Tomcat7/8/9,Resin,Jetty |
| JDBC | Oracle,mysql | Oracle,mysql,Sharding-JDBC |
| 消息中间件 | ActiveMQ, RabbitMQ | RocketMQ 4.x,Kafka |
| 日志 | log4j, Logback | log4j,log4j2, Logback |
| HTTP库 | Apache HTTP Client, GoogleHttpClient, OkHttpClient | Apache HTTP Client, OkHttpClient,Feign |
| Spring体系 | spring,springboot | spring,springboot,eureka,hystrix |
| RPC框架 | Dubbo,Thrift | Dubbo,Motan,gRPC,ServiceComb |
| NOSQL | Memcached, Redis, CASSANDRA | Memcached, Redis |
性能对比
模拟了三种并发用户:500,750,1000。使用jmeter测试,每个线程发送30个请求,设置思考时间为10ms。使用的采样率为1,即100%,这边与生产可能有差别。pinpoint默认的采样率为20,即50%,通过设置agent的配置文件改为100%。zipkin默认也是1。组合起来,一共有12种。下面看下汇总表:
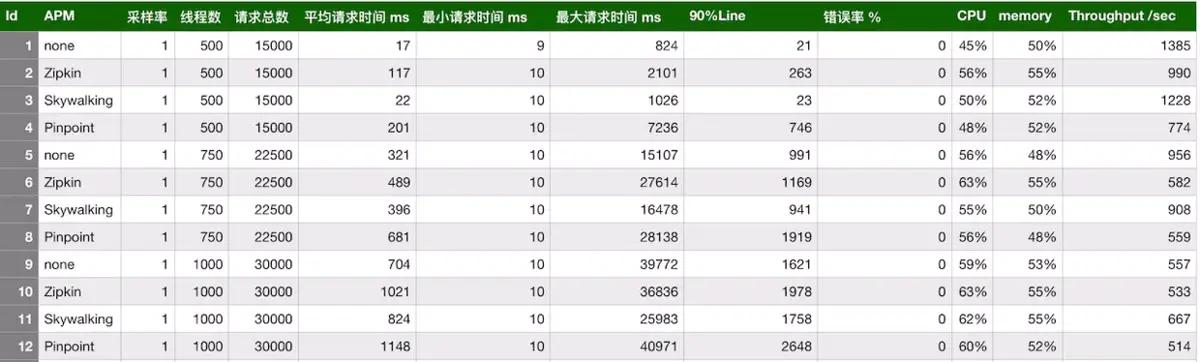
从上表可以看出,在三种链路监控组件中,skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint的探针对吞吐量的影响较为明显,在500并发用户时,测试服务的吞吐量从1385降低到774,影响很大。然后再看下CPU和memory的影响,在内部服务器进行的压测,对CPU和memory的影响都差不多在10%之内。