目录
- 1. 安装bs4模块
- find()
- findall()
- 2. 爬取信息测试
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
1. 安装bs4模块
pip install bs4
pip install-i https://pypi.tuna.tsinghua.edu.cn/simplebs4
如果遇到报错The soupsieve package is not installed. CSS selectors cannot be used
可能还需要安装下面的库
pip install soupsieve
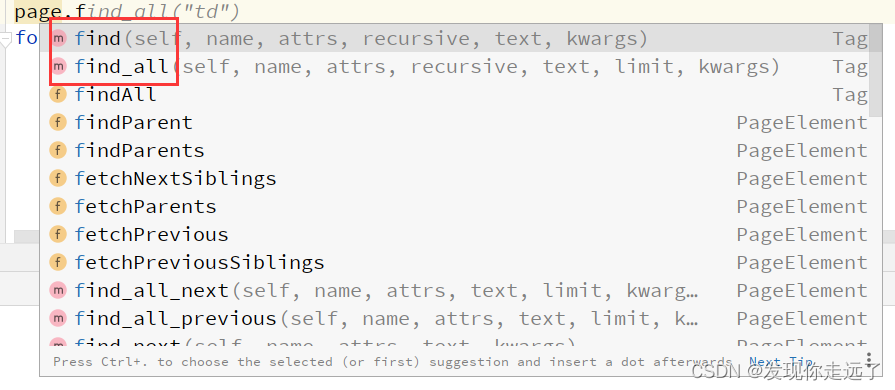
基本上find()和findall()就够用了
find()
找到第一个满足条件的标签就返回。只会返回第一个元素。
find(标签,属性=值)意思是在⻚⾯中查找xxx标签,并且标签的xxx属性必须是xxx值
学过python面向对象的朋友可能会知道python的保留字中有一个class,如果你没有学过你就理解为是和if 一样的东西。但是html标签中也有class属性,这无疑会带来关键字冲突。可以在class后⾯加个下划线。
page.find("div",class_="honor")
推荐使用第⼆种写法来避免这类问题出现
page.find("div",attrs={"class":"qwer"})
findall()
将所有满足条件的标签都返回。以列表的形式返回很多标签
findall(标签,属性=值)意思是在⻚⾯中查找xxx标签,并且标签的xxx属性必须是xxx值
其他类似find()
2. 爬取信息测试
先获取⻚⾯源代码.并且确定数据就在⻚⾯源代码中。
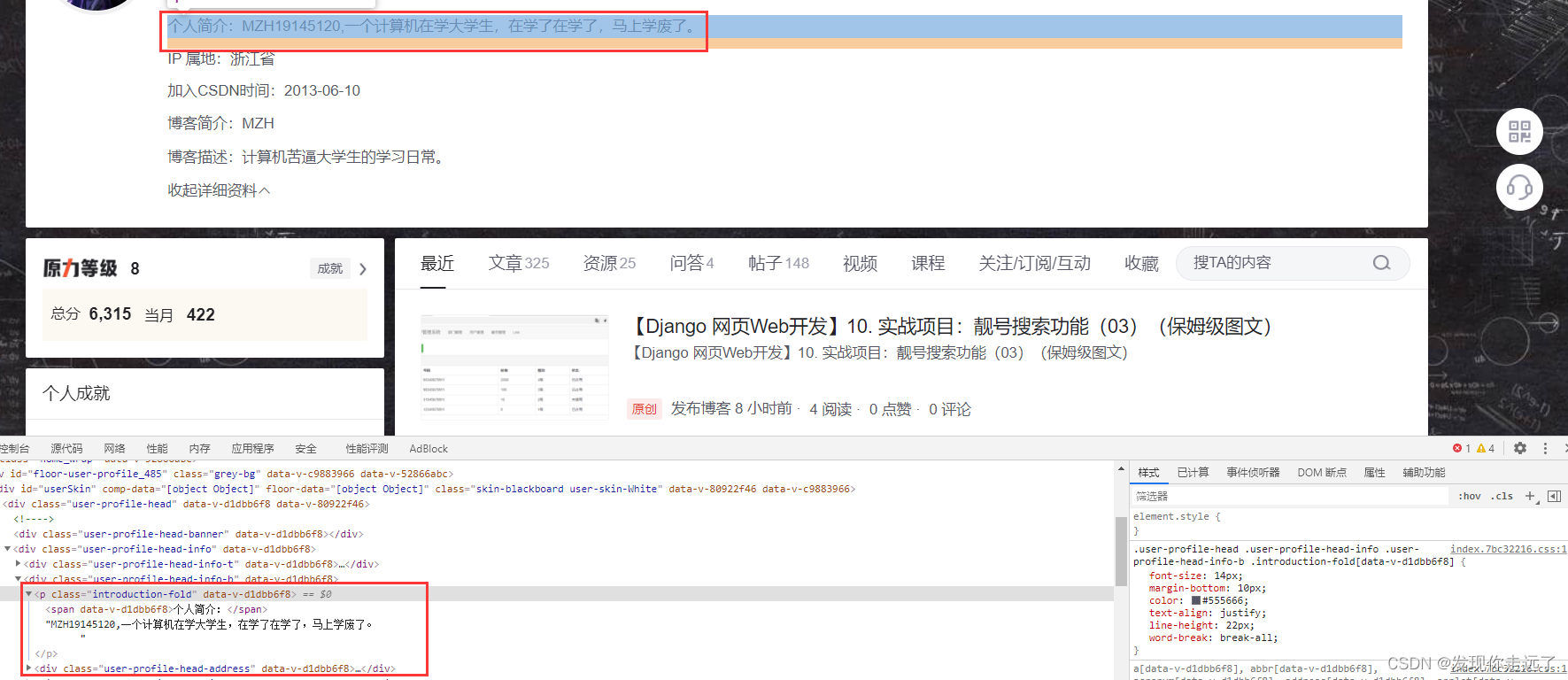
我们这边测试一下我爬我自己,爬取我博客个人主页中的个人简介。
我的主页
https://blog.csdn.net/u011027547
根据p标签的class="introduction-fold"属性查找,并且可以在找到p标签的基础上进行二次查找。
import csv
# 1. 拿到页面源代码
# 2. 使用bs4进行解析. 拿到数据
import requests
from bs4 import BeautifulSoup
url = "https://blog.csdn.net/u011027547"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
resp = requests.get(url,headers=headers)
print(resp)#
f = open("搜索信息.csv", mode="w")
csvwriter = csv.writer(f)
# 解析数据
# 1. 把页面源代码交给BeautifulSoup进行处理, 生成bs对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器
# 2. 从bs对象中查找数据
# find(标签, 属性=值)
# find_all(标签, 属性=值)
# table = page.find("table", class_="hq_table") # class是python的关键字,所以我们用class需要改为class_,类似避讳古代皇帝的名
p = page.find("p", attrs={"class": "introduction-fold"}) # 和上一行是一个意思. 此时可以避免class
print(p)#<p class="introduction-fold default" data-v-d1dbb6f8=""><span data-v-d1dbb6f8="">个人简介:</span>MZH19145120,一个计算机在学大学生,在学了在学了,马上学废了。</p>
print(p.text)#得到p标签中关于个人信息的文本-->个人简介:MZH19145120,一个计算机在学大学生,在学了在学了,马上学废了。
message=p.find("span")#在原本p标签中寻找span标签
print(message)#<p class="introduction-fold default" data>
print(message.text)#个人简介:

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』
![[网络原理] HTTP协议](https://img-blog.csdnimg.cn/0165697193564bd7ae9aefb62d133e0a.png)