近年来,大型语言模型(LLM)技术取得了令人瞩目的进展,为自然语言处理领域带来了巨大的变革,但是大多数LLM都面临着领域适应性的问题,因为它们使用的数据都是公开的数据,在国内,有很多数据是受到部门保密或隐私限制的。因此,针对特定环境的内容生成是LLM应用中的一个重要方向,实现这一目标,主要有以下几种方法:全量微调、lora微调和LLM模型外挂知识库方法。
在研究清华大学开源的ChatGLM-6B1时,我发现了两个基于该模型的有趣的项目:langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答和闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能。我在自己的电脑上部署了这两个项目,发现它们都采用了知识库+脚本的形式为LLM提高生成能力,既考虑了个人和中小企业的资源限制,又保证了知识的安全性和私密性,实现了让小模型获得近似于大模型的生成能力。
在这里介绍一种利用大型语言模型(LLM)实现本地多模态数据的知识获取和推理的方法。本方法基于 wenda 模型,可以读取多模态数据(word、pdf、excel、数据库等),并结合知识库和自动执行脚本为 LLM 提高生成能力。本方法有以下几种模式:
rtst模式,使用 sentence_transformers+faiss 进行索引,支持预先构建索引和运行中构建。
bing模式,使用 cn.bing 搜索,仅国内可用。
bingsite模式,使用 cn.bing 站内搜索,仅国内可用。
fess模式,使用本地部署的 fess 搜索,并进行关键词提取。
mix模式,融合以上四种模式。
简单来说,就是利用 bing 获取网页、fess 搜索等获取新知识,然后交给 LLM 来总结。
项目分为安装版本与懒人版两个版本,为了便捷,我们使用懒人版。
1 部署
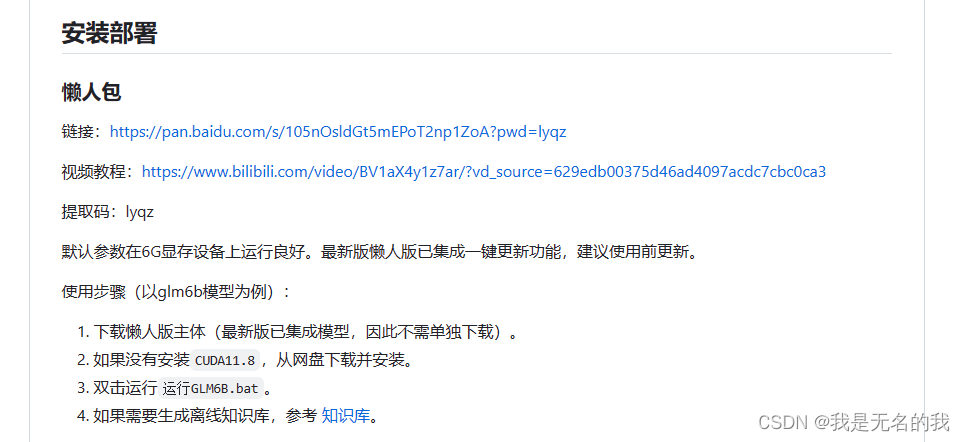
1.1 下载最新懒人包主体
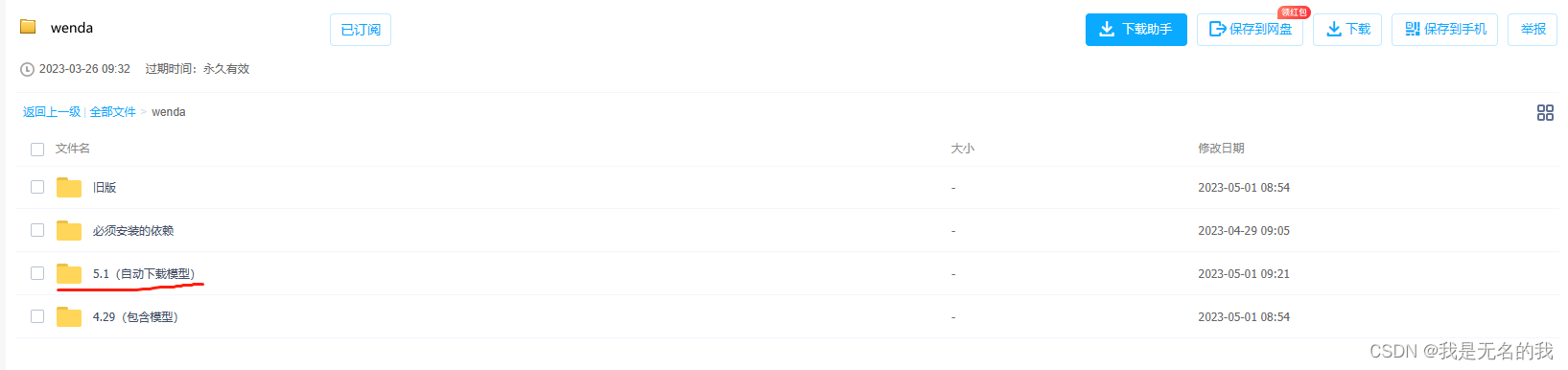
1.2 下载必要的依赖

1.3 模型下载
模型分为LLM模型以及文字编码模型,项目的支持特性如下
LLM模型模型:chatGLM-6B、chatRWKV、chatYuan、llama系列以及openaiapi和chatglm130b api,初步支持moss。
文字编码模型:text2vec-large-chinese。
各类模型可以在百度云盘里面找到下载
(记得下载fess)
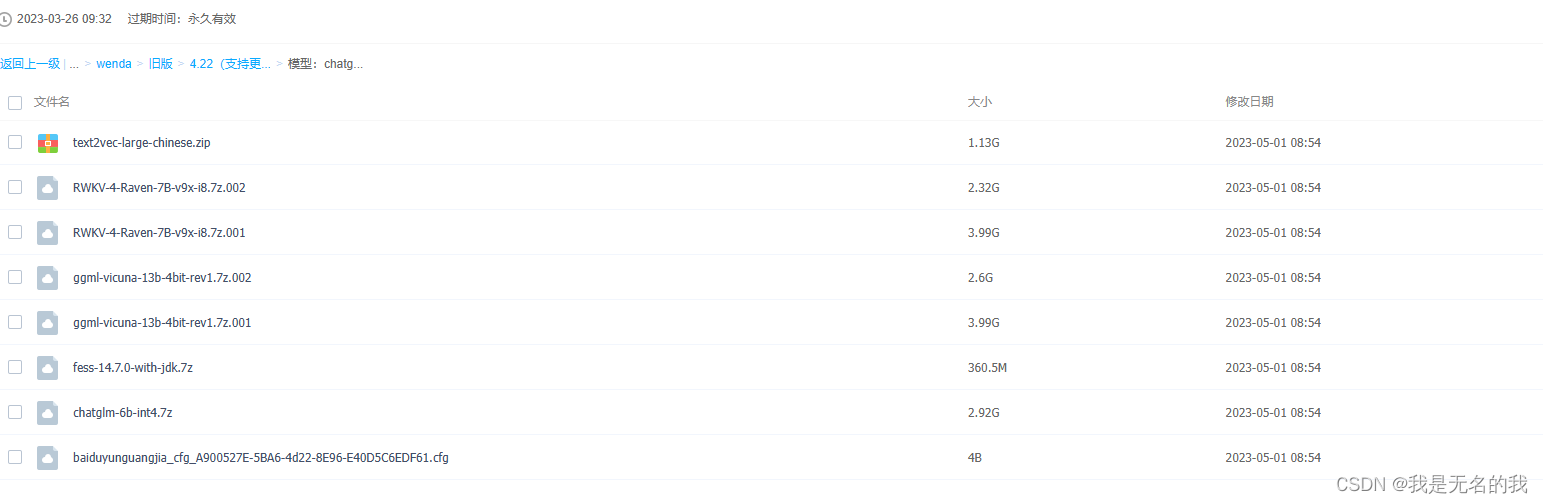
1.4 文件配置
修改配置文件,复制example.config.xml文件,重命名为config.xml,根据自己的实际,修改
1.大模型路径,其他模型路径同理
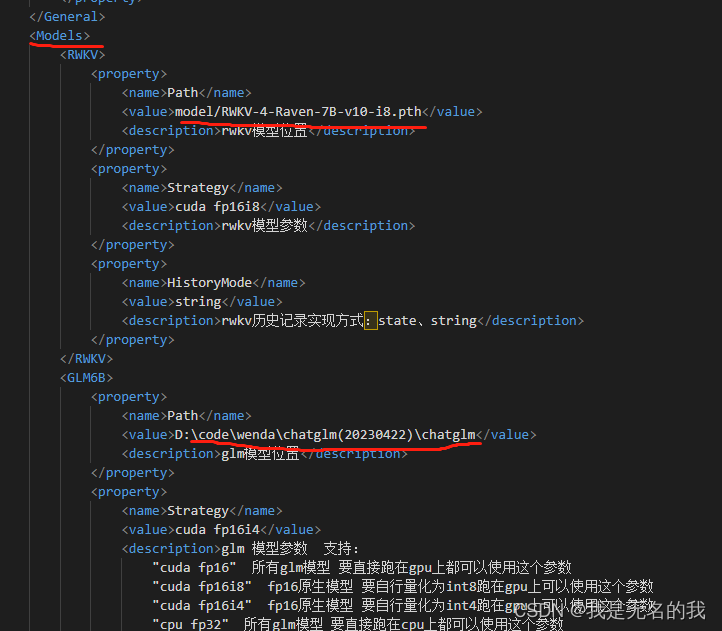
2.文字编码模型路径,在你使用strt模式时使用。
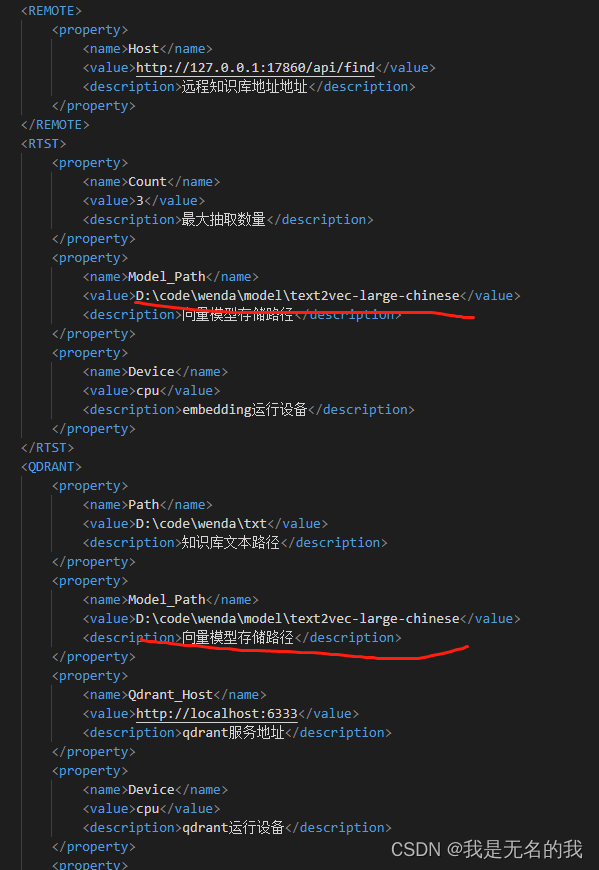
1.5 fess安装
根据教程的方式,安装fess系统,根据fess系统github的介绍,它是一个支持多模态数据的开源的文件搜索系统。记得完成索引后,别关闭这个窗口
初步对这个fess系统进行测试,发现它对多模态数据都能支持良好,在自己电脑部署一个也不错
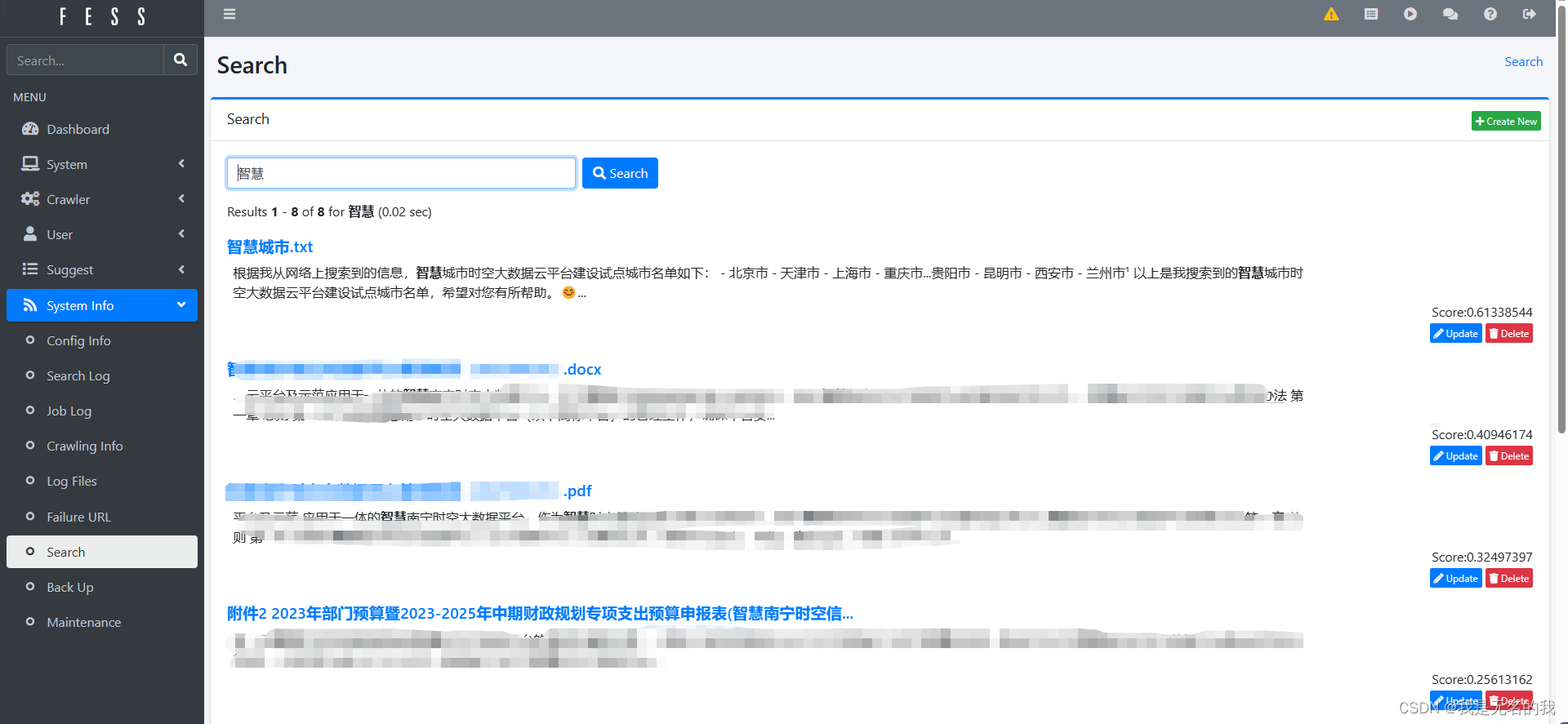
2 测试
根据你想测试的模型,双击批处理代码,经过测试,rwkv模型在1060 6g下支持良好。
在这里可以看到我们的参数
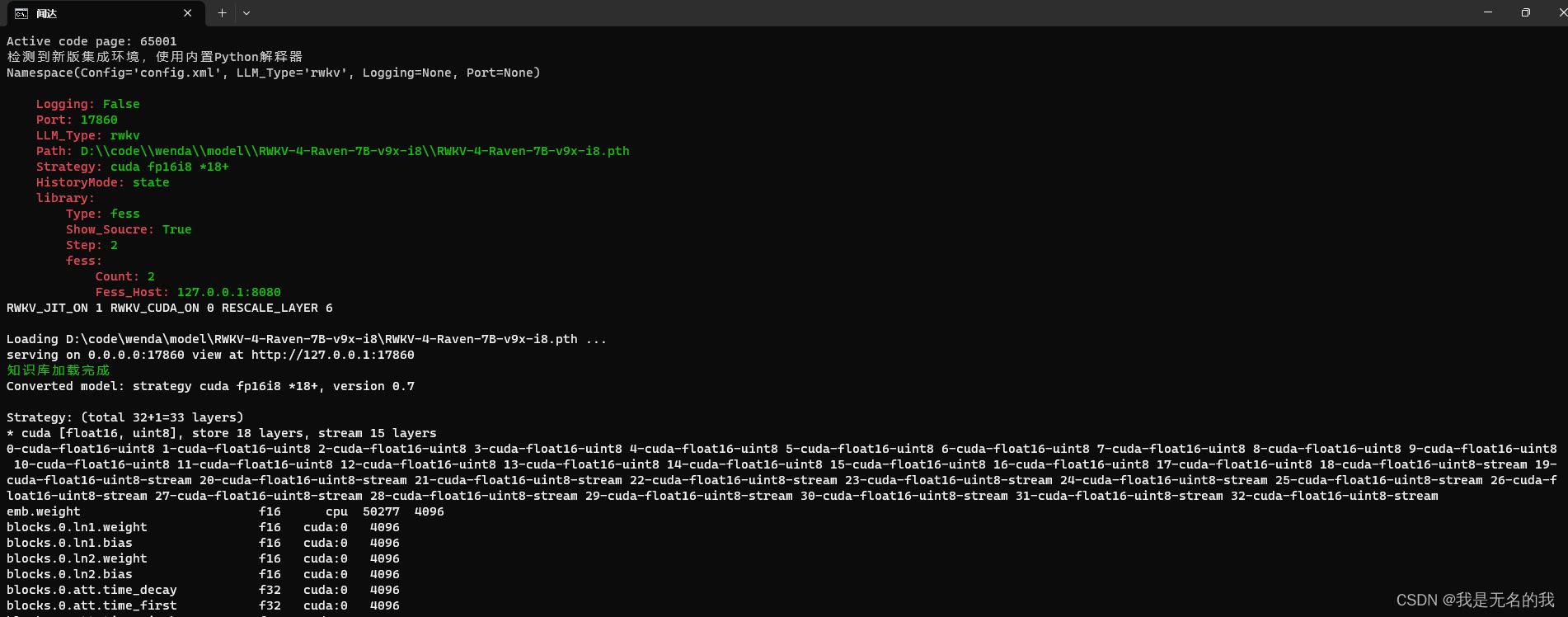
打开这个http://127.0.0.1:17860,就可以使用fess系统+LLM模型了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4XJclcuJ-1683025683879)(null)]](https://img-blog.csdnimg.cn/da1f68c17d1f4a0bb8fc5741f450cbd8.png)