架构现代化-微服务
Hi,我是阿昌,今天学习记录的是关于架构现代化-微服务的内容。
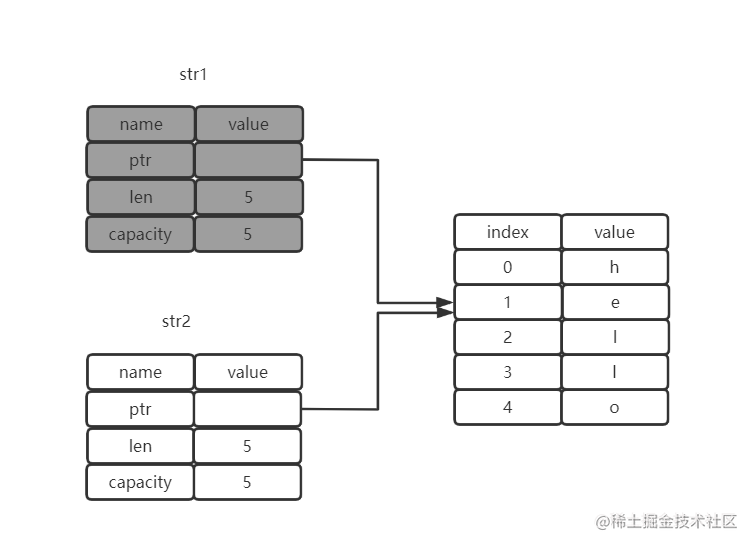
在自治气泡模式的基础上,通过事件拦截来实现数据同步,给气泡和遗留系统之间又加上 API 访问这个通信渠道。
这时的自治气泡就和真正的微服务差不多了。
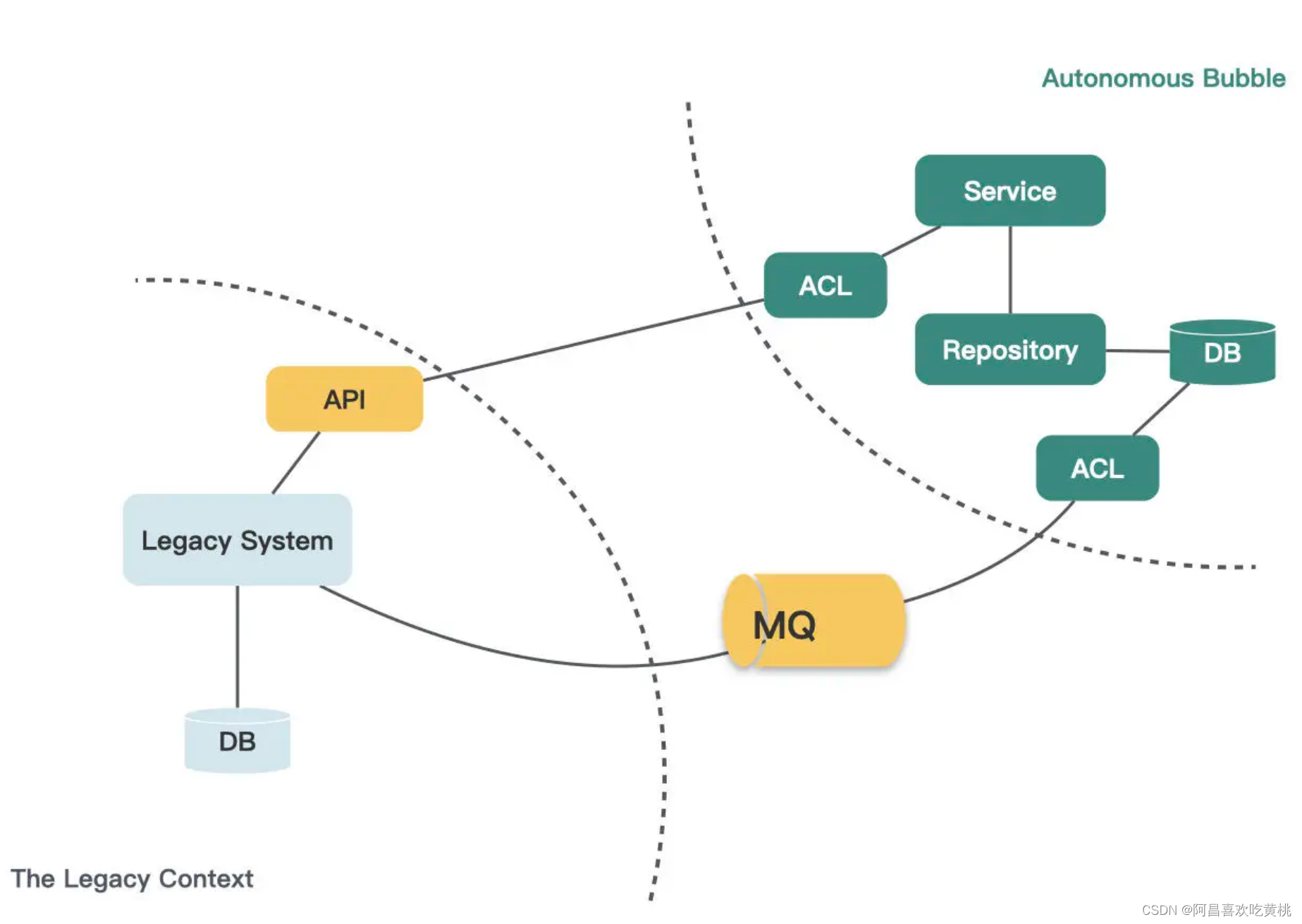
有了这种模式,在开发一个全新的需求时,你就可以将新需求实现在新的服务中,通过防腐层和遗留系统隔离,达到自治的目的。
这样,新服务可以更好地演进,不受遗留系统的影响;
遗留系统也不会因为新需求的增加而带来太多修改。
然而,单体真的不好吗?微服务一定是目标架构吗?
一、单体和微服务应该如何取舍?
这个问题众说纷纭,几个有代表性的咱们看看。
-
在 2015 年,Martin Fowler 就撰文强调,即使知道系统会大到值得去使用微服务,也应该单体先行;
-
Stefan Tilkov 却说如果目标是一个微服务架构,就不要从单体开始;
-
C4 模型的作者 Simon Brown 的观点则是,如果连单体都构建不好,凭什么认为微服务就是想找的答案呢?
-
最“气人”的就是《微服务设计》的作者 Sam Newman,在被问到应该何时使用微服务时,他的回答是:应该在有足够理由的时候。

大牛们的观点要么针锋相对,要么似是而非,那到底应该如何取舍呢?
直到有一天,在网上看到一条视频,是 Matthew Skelton 和 Manuel Pais 在伦敦一个技术大会上的演讲,题目是:Monoliths vs Microservices is Missing the Point—Start with Team Cognitive Load。单体有单体的好处,微服务也有微服务的好处。
同时,选择了任何一种,也都要面对它所带来的问题。所以,单纯从纯技术角度说哪个好,是没有意义的。同样是微服务,有些团队如虎添翼,有些团队却步履蹒跚。这一切的背后并不是技术本身在搞怪,而是人,是团队的认知负载。Martin Fowler 和 Sam Newman 们无法用语言表达出来的模棱两可,被如此轻描淡写地化解。就仿佛一个置身四维空间的神,在低头嘲笑三维空间中渺小的人类。这是一个彻彻底底的降维打击。也就是说,判断依据不应该是技术本身,而应该是团队的认知负载。
哪一种方案对当前团队来说认知负载低,哪一种就更有可能成功。比如一个包含 10 个模块的单体系统,目前共有 10 个开发人员,如果按模块拆分成微服务,平均每个人要维护一个服务,这就超出了人的认知负载。
正确的方案可能要这样演进:先拆出一个不太大的服务,抽出 2 到 3 名开发人员组成新的团队来维护它,然后再慢慢扩张团队,并逐渐拆出新的服务,直到形成一个 5 到 9 人的团队维护一个服务这样的比例为止。
二、单体向微服务的演进
在确定了要拆分之后,应该如何演进。
1、大泥球单体架构
单体架构往往都是“大泥球”(Big Ball of Mud),这也是遗留系统最常见的情况。
大泥球架构可能也分一些层次,如常见的三层或四层结构。
但它的内部就不忍直视了,特别是业务逻辑层内部,各个模块的边界十分模糊,往往是你调用我,我调用它,它又调用你,循环往复,错综复杂;持久层也好不到哪去,本应属于不同模块的表之间 join 来 join 去,形成一张大网。
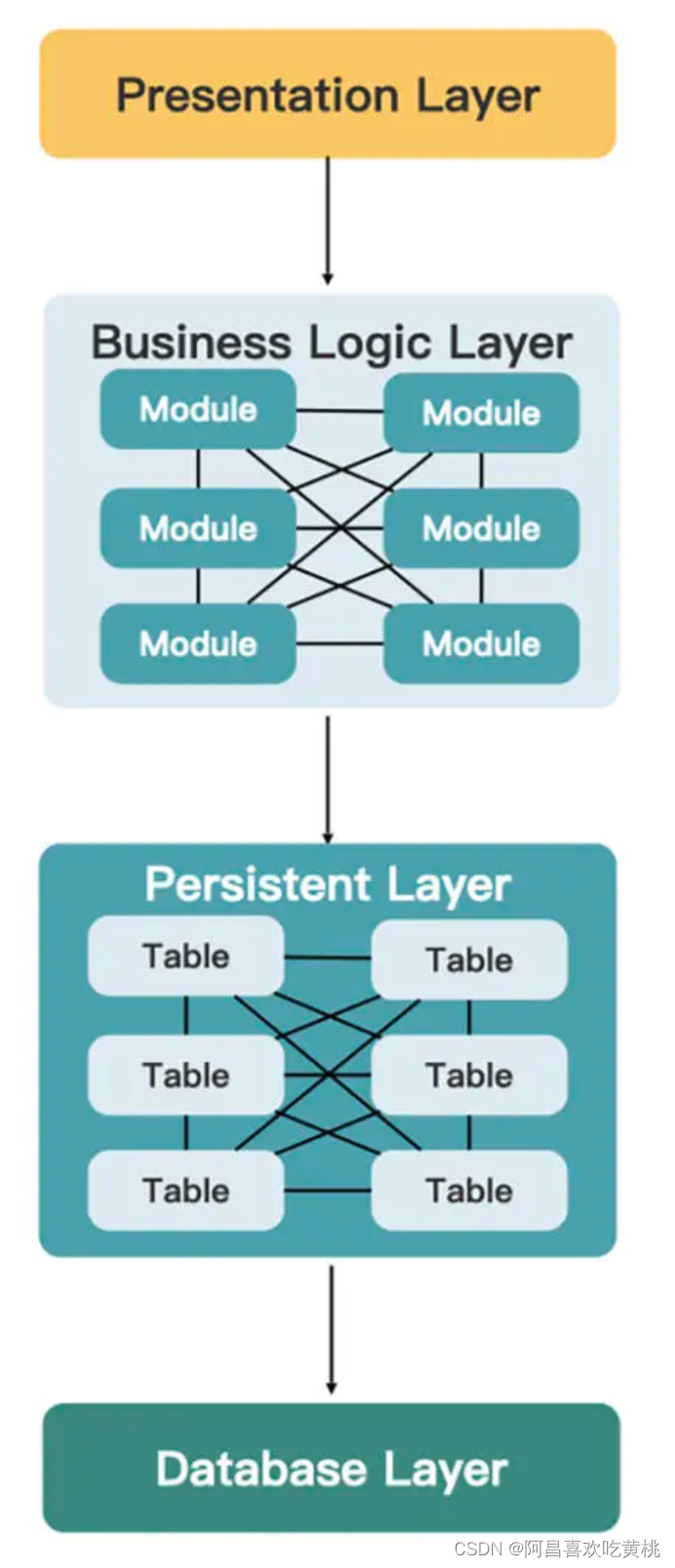
大泥球并不是一种架构风格,也没有人一开始就想构建一个这样的架构,它们只是从简单的分层架构中逐渐腐化而成的。
对于小型的、简单的软件来说,选择分层架构没什么不好。
只是随着业务的演进,架构没有得到很好地守护,才一步步变成了大泥球。
2、基于组件的单体架构
要想改善大泥球架构,最重要的就是把业务模块之间的耦合解开,消除掉模块间的相互依赖关系。
同时,也要将数据的所有权分开,让不同的模块拥有不同的数据。
这种类型的单体架构称之为基于组件的单体架构。
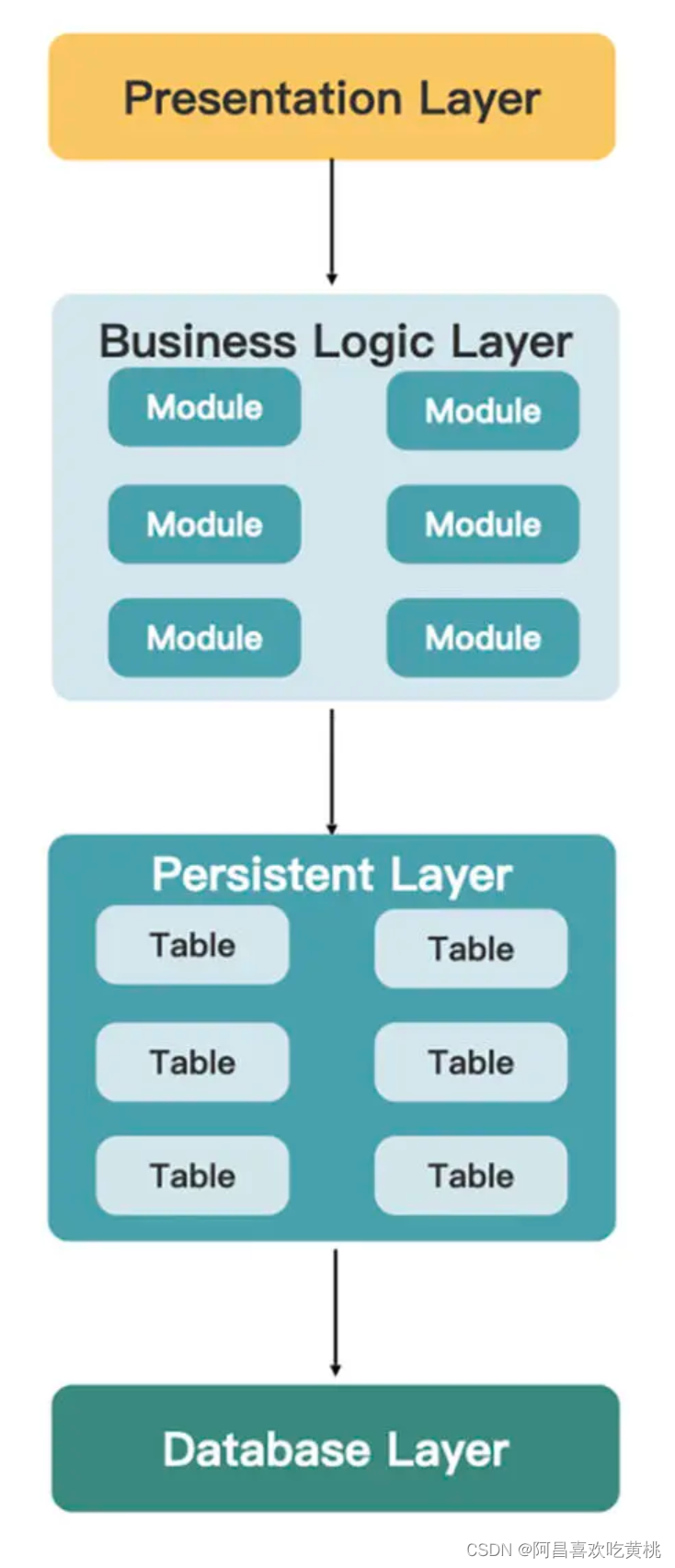
当然,要达到这样的理想情况实际很难。因为一个模块想不依赖另一个模块的数据,这不太可能。
比如销售模块不可能不依赖库存数据。在大泥球中的做法,当然是在销售模块中直接访问库存表,但在基于组件的单体架构中,要让库存模块提供一个外部模块可以访问的接口(非 Web API),销售模块通过防腐层去调用这个接口,转换成销售业务所需要的库存数据。
这样,销售模块就不再直接依赖库存数据表了。这种模块之间虽然也有依赖,但比起销售模块依赖库存模块的库存对象来说,还是要好出不少的。它通过防腐层对不同模块进行了隔离,一个模块中模型的修改,不会影响到另一个模块。
如果大泥球的模块之间比较好解耦,就可以先将其中一个模块解耦出来,再逐步把其他模块也一一照方抓药。
如果没有系统弹性等方面的非功能需求,那么基于组件的单体架构,就是一个比较理想的架构形态了。
常常用“分而不拆”来形容这种架构风格。
3、基于服务的分布式架构
当单体内的模块清晰之后,会发现一些模块描述的是一个大的业务领域,你可以尝试按业务领域给这些模块分组,将它们拆分出来,形成服务。这种架构叫做基于服务的分布式架构。
Mark Richards 和 Neal Ford 在《软件架构:架构模式、特征及实践指南》这本书中详细介绍了这种架构。
相对微服务而言,这时的服务是粗粒度的,Neal 管它叫做领域服务,要注意这里的领域服务概念,它和 DDD 中的领域服务并不一样。
这里的领域服务是指,由描述同一块业务领域的多个模块所组成的服务。比如保险行业的理赔是一个业务领域,它可能由报案、受理、理算、结案等多个模块组成。
这些服务往往都只有一个用户界面层和数据库。当然,如果数据库成为瓶颈的话,也有可能需要对数据库进行拆分
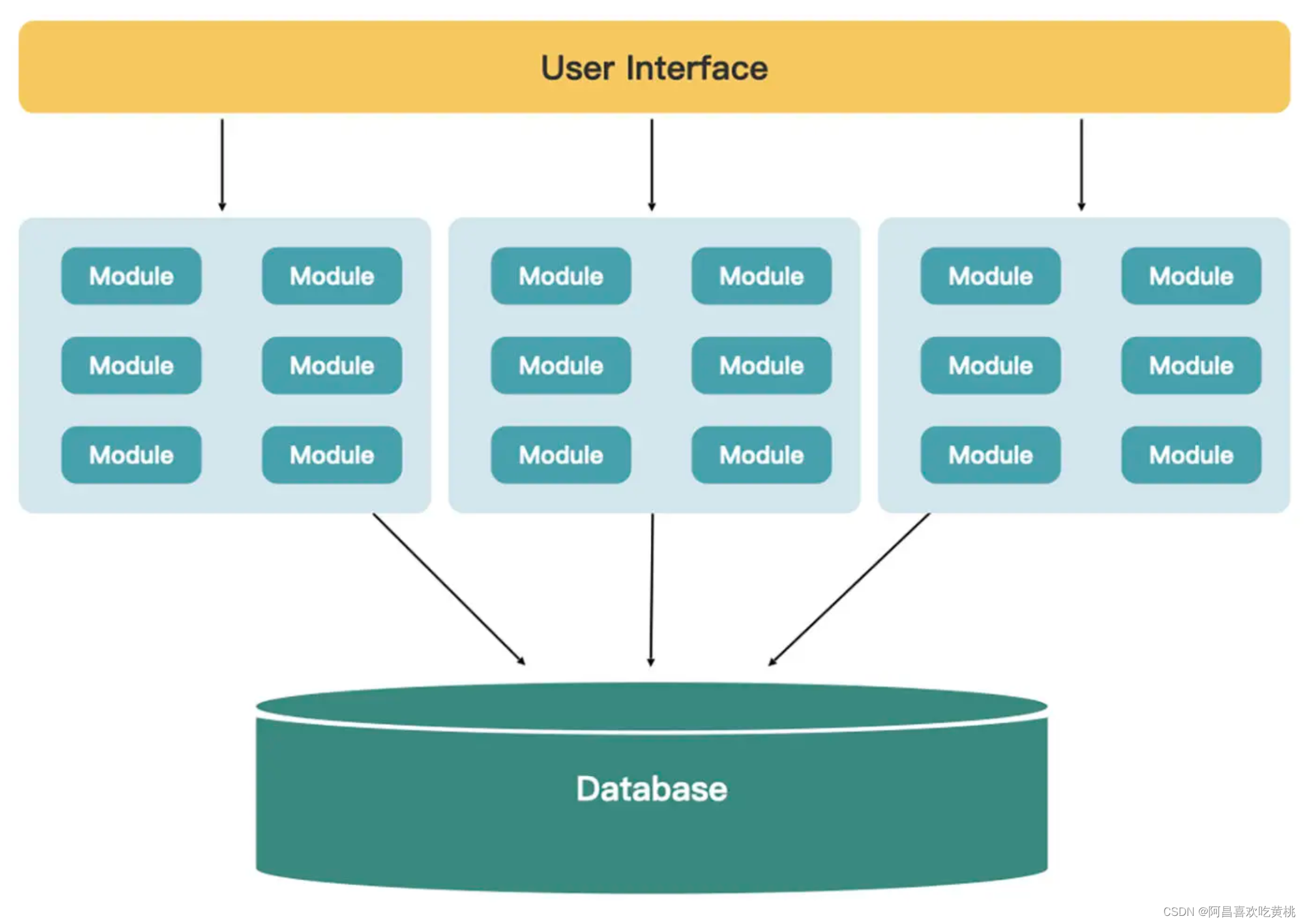
基于服务的分布式架构既可以作为一个过渡架构,也可以作为目标架构。
它是一种粗粒度的微服务架构,每个服务都可以独立部署,并包含一个特定领域的所有业务逻辑。
可以自行决定哪些领域需要进一步细化,哪些保持粗粒度就足够满足需求了。这种过渡架构优势是什么?
一方面,这种架构享受了一部分可扩展性和高可用性,这是分布式架构带来的“增益 buff”。同时,由于服务数量并不会很多,也不会像微服务架构那样,带来太多的系统复杂性和运维负担。
有意思的是,很多项目号称做到了微服务架构,其实质上只是这种基于服务的分布式架构而已。
4、微服务架构
如果基于服务的分布式架构仍然无法满足需求,比如同一服务中,不同模块之间弹性需求的差异越来越大,那就不得不对模块继续拆分。
比如理赔领域中的报案模块,需要 7x24 小时的高可用服务,以支撑客户的自助报案。
但其他模块则没有这种需求。当各个模块及其数据库的弹性边界都不同时,就拆分出了微服务架构。
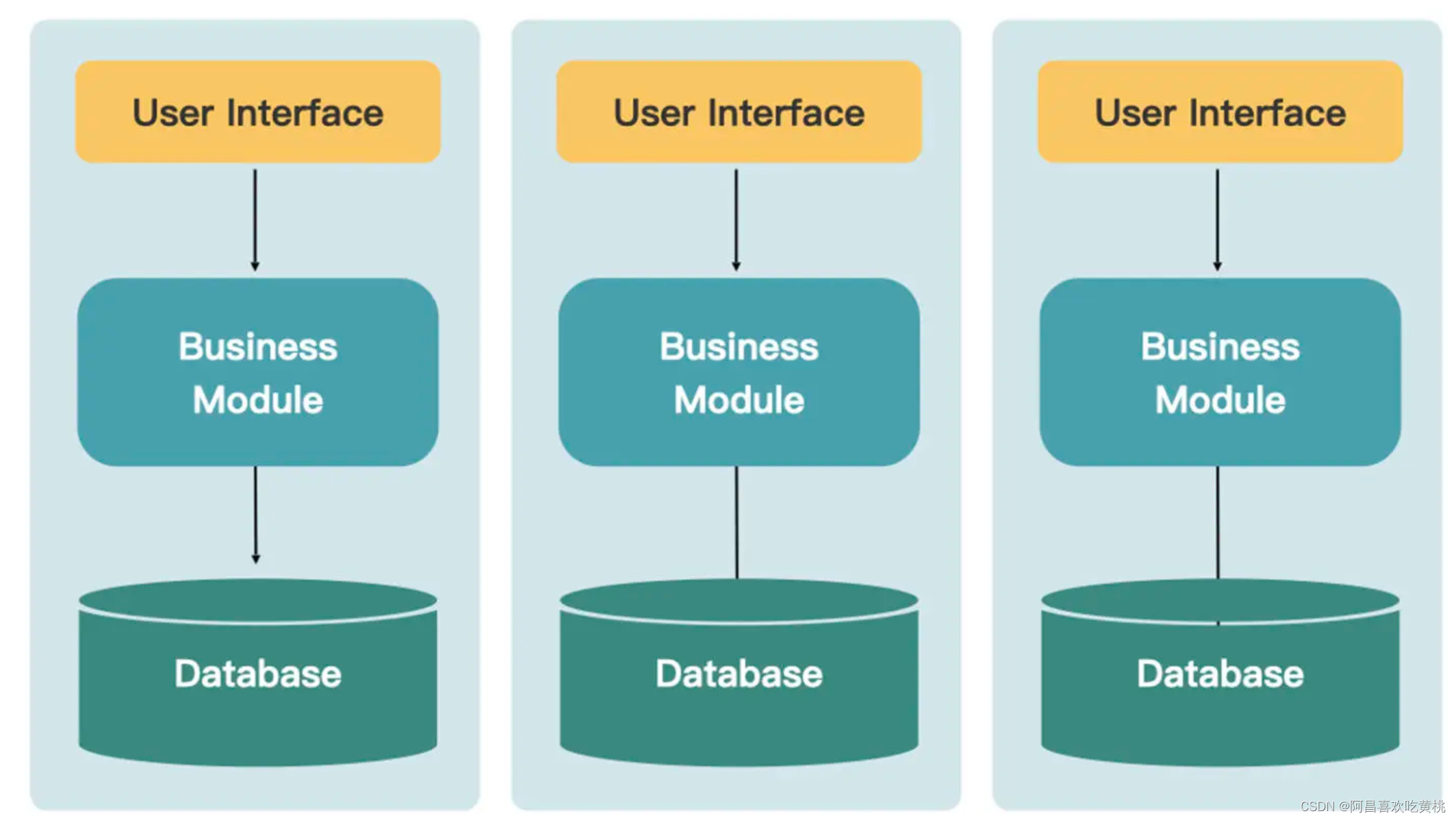
在微服务架构下,业务边界变得十分清晰,每个服务可以独立部署和演进,并且可以选择不同的技术栈。一个团队只负责一个或少量的服务(业务模块),可以更好地守护住这个服务不被外界腐化。同时由于关注点比较聚焦,认知负载也得到了降低。
很多人觉得不同技术栈这一点并没有多吸引人,可能是因为并没有看到适用场景,反而是有些人盲目地引入多语言,用不同编程语言去开发相似的业务,凭空增加了很多认知负载。
多语言开发是指让不同的语言去处理各自擅长的领域,比如用 Python 去处理算法,用 Scala 去处理数据。但如果没有特殊需求,只是凭喜好来混合使用多种技术栈,那简直就是多此一举。
微服务架构虽然降低了开发人员的认知负载,但却提升了运维人员的认知负载。它实际上是用运维复杂度来置换开发复杂度。开发人员所面对的内容少了,更加聚焦了,但运维人员却从以前运维一个单体服务,变为运维几个甚至几十个上百个微服务。这需要强有力的 DevOps 文化作为支撑。
所以,如果团队不具备这样的能力和文化,最好不要引入微服务。
把那种无视团队认知负载,只因为技术先进性而盲目拆分微服务的行为,叫做微服务强迫症(Microservice Envy)。
三、遗留系统的架构应该如何演进?
刚才说了很多种架构风格,那到底什么样的架构适合遗留系统呢?
如果系统目前是一个大泥球单体架构,且已经明确体现出一些问题,比如代码越来越混乱,那就要考虑改进架构了。
Neal Ford 在他的新书《Software Architecture: The Hard Parts》中提出了一个架构解耦的决策树,非常适合辅助来决定采取什么策略应对遗留系统的架构。
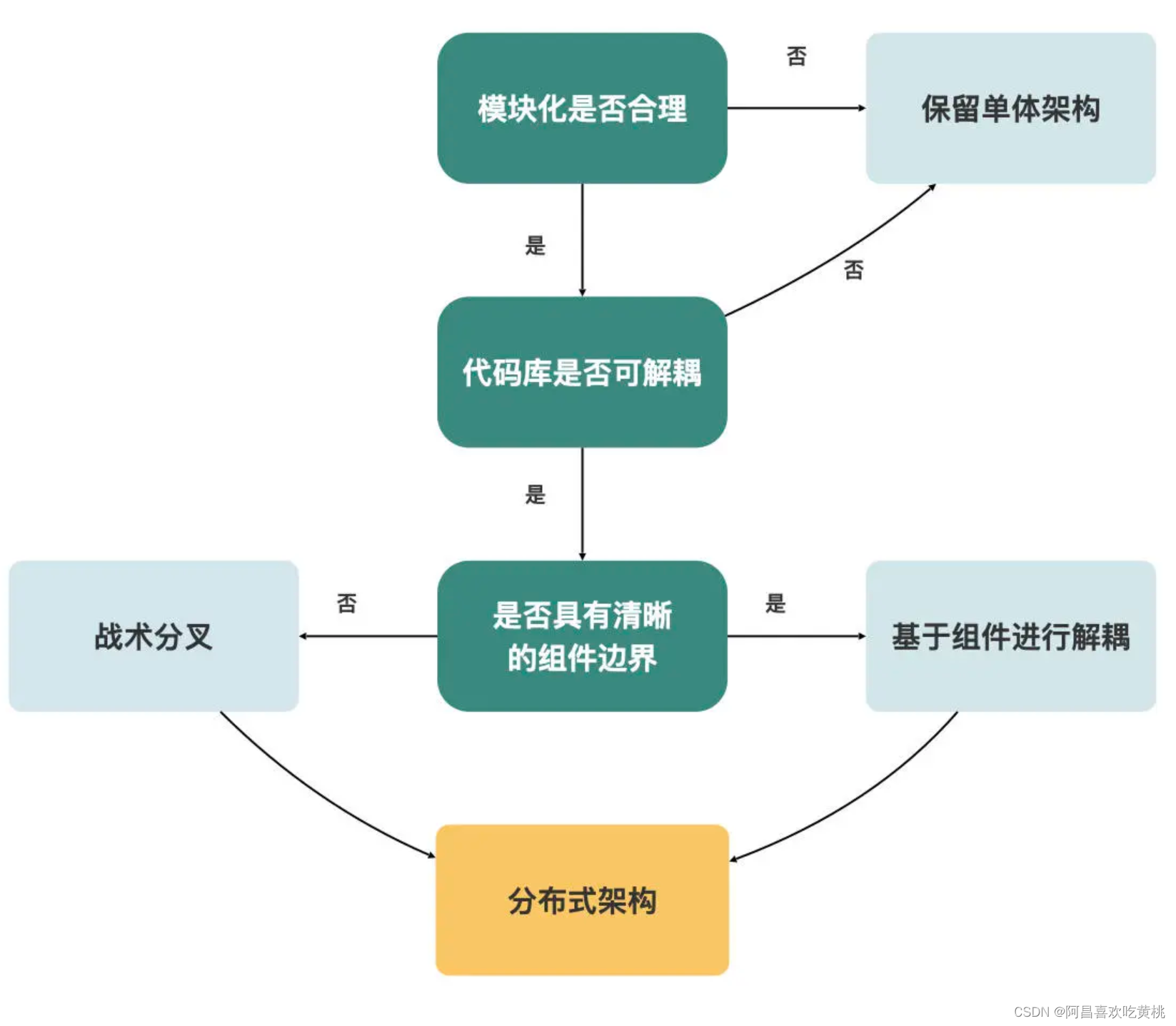
从这个决策树中可以看出,首先需要判断,系统是否适合进行模块化?
如果不适合,就保留单体架构不动。那如何判断是否适合呢?
Neal 给出了一些模块化的驱动因素:
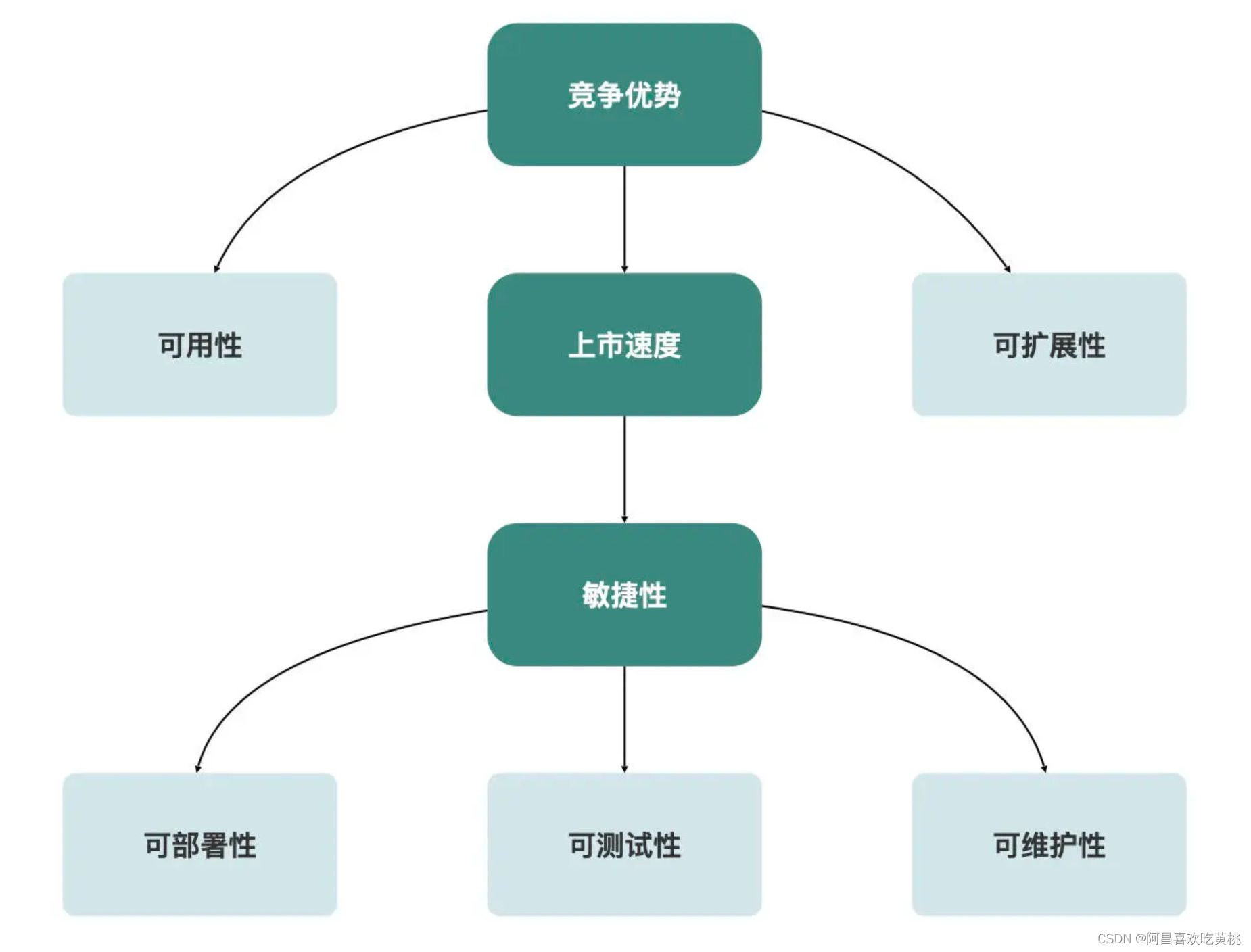
可以从可用性、可扩展性、可部署性、可测试性、可维护性几个方面来判断。
如果系统对这些指标有着比较高的要求,就是适合模块化的;如果并不关心,就可以保留单体结构不变。
不过,恐怕很少有系统会不关心这些指标吧。如果系统适合模块化,下一步还要判断代码库是否可拆分,也就是是否有可能把一个大泥球代码库拆分成多个小的代码库。
Neal 在书中给出了三种代码的特征指标来辅助我们判断,分别是:传入传出耦合(Afferent and Efferent Coupling)、抽象性和不稳定性,以及和主序列的距离。
如果代码库可拆分,下一步就是判断系统的各个模块之间是否具有清晰的组件边界。
如果有,就可以选择基于组件的分解(Compnent-based Decomposition)模式,否则可以使用战术分叉(Tactical Forking)模式。
四、基于组件的分解
基于组件的分解模式适合将单体架构迁移到基于服务的分布式架构上,这往往是我们迈向微服务架构的第一步。
如果目前的系统是基于组件的单体架构,轻而易举就能使用这种模式。但如果系统仍然是大泥球,但是组件边界相对来说还算比较清晰,也可以使用这种模式。
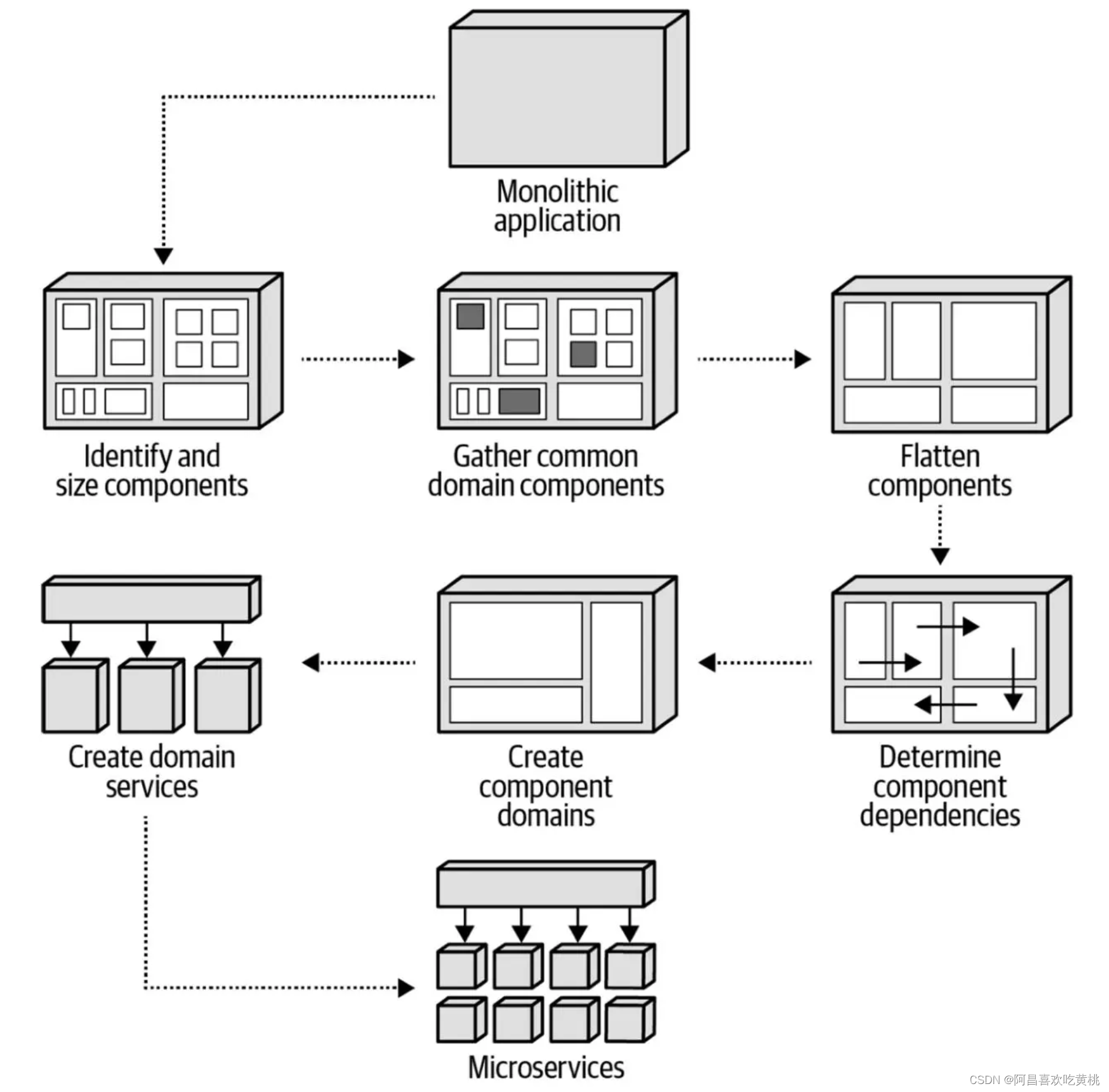
Neal 在《Software Architecture: The Hard Parts》中介绍了 6 种组件分解模式,简单给盘点一下:
- 识别和调整组件大小:统计各个模块的代码语句数,拆分那些过于庞大的组件,使所有组件的语句数趋于一致。
- 收集公共领域组件:在基于组件的单体架构中,很多组件的功能是类似的,比如邮件通知和短信通知,或者订单通知模块和物流通知模块。识别这些模块并进行合并,有助于消除重复。
- 展平组件:让组件中的类都位于叶子节点的包中,不要出现孤儿类(即类和其他包平级)。
- 明确组件依赖:分析组件之间的依赖关系。
- 构建领域组件:在逻辑上将属于同一领域的组件组合在一起。
- 创建领域服务:当组件的大小适中、结构扁平,并且按领域分组后,就可以在此基础上拆分出领域服务,构建基于服务的分布式架构了。
需要引起注意的是,在微服务或基于服务的分布式架构中,它们的服务都是这种按组件或领域组件来划分的,它们描述的是业务而不是数据。
很多架构师在设计服务的时候,不是按业务划分,而是按比较复杂的实体对象来划分。比如员工服务或商品服务,就只包含员工或商品的增删查改。这样的服务称之为实体服务(Entity Service),是一种典型的反模式。
要完成一个简单的业务场景,需要有一个编排服务来编排多个实体服务,这导致业务逻辑位于编排服务中,而不是微服务中;
一个常见的业务需求,都可能会涉及多个实体服务的修改,这就导致服务无法独立部署,只能多个服务或整体一起部署。
这样一来,就跟单体架构没有区别了,甚至更糟,因为它还是分布式的。管这种架构叫做分布式单体(Distributed Monolith)。
遗憾的是,网上很多微服务的示例,包括Spring 和微软的示例,其实都是分布式单体。
当然,它们主要是想描述如何搭建和运维一个服务,但要长个心眼儿,千万不要以为这样的服务就是微服务的样板,并且盲目效仿。
五、战术分叉
如果一个大泥球单体架构中,连相对清晰的组件边界都没有,所有代码混在一起,这种情况拆分起来会十分困难。
通常来说,当我们考虑从一个大的整体中,把一个小的部分挪出去的时候,方法都是“拆”。但当“拆”不动的时候,你可以变换一下思路,用“删”的方式来实现拆分。这种模式,就叫做战术分叉。
怎么删呢?先把系统整体复制一份,然后在复制出来的系统中删掉不需要的代码,保留下来的就是希望拆分出来的部分了。
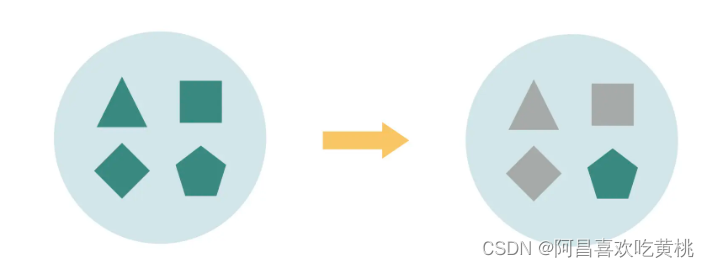
在系统之上,需要构建一个反向代理,根据请求来判断,需要转发给原来的系统,还是复制出来的分叉系统。
在使用战术分叉之前,需要先对大泥球加以梳理。尽管代码可能无法体现出很好的模块化,但业务领域还是有边界的。
可以使用服务蓝图、用户故事地图等工具,来识别企业的业务领域,然后选择一个希望“分叉”出去的业务能力。
在实际操作中,发现这种模式非常有用。因为很少有系统能够做到真正的模块化,更多的遗留系统现状是,有大体的业务模块,但从代码层面上看,模块之间耦合过于严重,很难通过基于组件的分解模式来拆分。
采用战术分叉时,开发团队可以立即开始工作,不需要事先做太多的分析。而且在开发人员看来,删代码总是比提取代码要容易得多。
但这也会导致两边的系统或服务都不可能删得太干净,相当于从一个大泥球中剔出来一个小泥球,等服务可以独立部署之后,还是会有很多善后工作要做。
六、总结
如何选择遗留系统的目标架构,到底是单体合适,还是微服务合适呢?看起来“二选一”的题目,还有更适合自己业务的隐藏选择么?
拆与不拆,要看认知负载。拆成什么样,要按步骤演进。除了微服务,基于组件的单体架构和基于服务的分布式架构也有可能是大泥球单体的最终目标,如何取舍主要还是看业务上是否具有弹性需求。在拆分时,你可以使用基于组件的分解和战术分叉两种模式。
微服务是个非常庞大的话题,很难在一节课中体现所有内容。奉劝你一句,拆分微服务一定要想清楚为什么要拆。
逻辑上分离(分)和在逻辑分离的基础上再做物理上隔离(拆)是两件事,解决的也是两个问题。
前一个解决的是知识边界封装和解耦的问题,后一个是想要物理隔离后的一些优势(如技术异构、弹性边界、可用性隔离、安全分级隔离、服务级别的独立交付等)。
大部分的拆分都承担了后者的成本,但是做的是前者的事儿,没享受到后者的好处。