本文要介绍的是Google于2016年提出的Wide&Deep模型,此模型的提出对业界产生了非常大的影响,不仅其本身成功地应用在多家一线互联网公司,而且其后续的改进工作也一直延续至今。
Wide&Deep模型正如其名,分别包含了Wide部分和Deep部分。其中Wide部分的作用是让模型具有较强的“记忆能力”(memorization);而Deep部分的作用是让模型具有“泛化能力”(generalization)。正是这样的设计,使得模型兼具了逻辑回归和深度神经网络的优点——能够快速处理并记忆大量历史行为特征,并具有强大的表达能力。
原论文在这里。
完整源码&技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
文章中的完整源码、资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自 获取推荐资料
方式②、微信搜索公众号:机器学习社区,后台回复:推荐资料
背景知识
推荐系统可以被认为是一个搜索排名系统,它的输入是一组用户以及上下文信息,输出是物品的排序列表。对于一次查询,推荐任务是从数据库中找到相关的物品,然后根据具体的任务(比如点击率预估或者购买预测)对这些物品进行排名,最后把结果呈现给用户。
与一般的搜索排名问题类似,推荐系统中的一项挑战是同时实现记忆(memorization)和泛化(generalization),Wide&Deep模型正是为了解决这项挑战而提出的。那么我们首先来理解下这两个概念,记忆和泛化。
Memoriization(记忆能力)
下面是原论文中的描述:
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.
“记忆能力”可以被理解成模型直接学习并利用历史数据中物品或者特征的"共现频率"的能力。一般来说,协同过滤、逻辑回归等简单模型具有较强的“记忆能力”。由于这类模型结构简单,原始数据往往可以直接影响推荐结果,产生类似于"如果曾经点击过A,就推荐B"这类规则式的推荐,这相当于模型直接记住了历史数据的分布,并根据这些特点进行推荐。
Generalization(泛化能力)
下面是原论文中的描述:
Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解比协同过滤的泛化能力强,因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。
下面以人为例来总结一下记忆和泛化能力,我们人类可以观察日常事件并且记在脑子中,比如我们观察到了“麻雀会飞”和“鸽子会飞”等自然事件。除此之外,我们还可以根据已有记忆进行总结并制定出相应规则(比如“有翅膀的动物会飞”),并应用到之前未见过的事物。当然也有例外,比如"企鹅不会飞",因此我们也需要记住一些异常情况,来进一步完善之前制定出的规则。
Wide&Deep模型如何工作
假设我们现在要开发一款点餐app,用户只需要输入它想要的某种食物(query),点餐app就可以预测出用户最喜欢的食物(item),并且呈现出来。如果用户下单了app推荐的食物,那么得分为1,否则为0。
我们首先使用Wide模型来处理这个问题,Wide模型希望能够记住对于一次query,究竟哪一个item与之最为匹配。这个模型预测一个消费概率,即对于一个特定的query和推荐的item,它被消费的概率有多大?
举个例子,这个模型学到了组合特征"AND(query=‘fried chicken’, item=‘chicken and waffles’)"成功率很高,即如果用户搜索炸鸡,app推荐炸鸡和华夫饼,那么用户消费的概率就很大。
组合特征"AND(query=‘fried chicken’, item=‘chicken fried rice’)"却并没有得到用户的青睐,尽管从名字上看,炸鸡和鸡肉炒饭相似度很高,但实际上这两者完全是不同的口味。因此Wide模型是要记住用户之前喜欢什么样的item。下图展示了Wide模型的“记忆过程”。

Wide模型
对于组合特征"AND(query=‘fried chicken’, item=‘chicken fried rice’)",Wide模型会降低此组合特征的权重,而增大组合特征"AND(query=‘fried chicken’, item=‘chicken and waffles’)"的权重。
过了一段时间,用户对app的推荐内容感到疲倦,他们希望app能够推荐一些符合他们口味,但同时又能带来新鲜感的食物。因此我们选择Deep模型来解决这个问题,Deep模型会对每个query和item都生成低维的稠密embedding向量,并且在embedding空间中来查找彼此比较接近的ietm。
举个例子,你会发现搜索炸鸡的用户一般也不会介意再吃个汉堡。下图展示了Deep模型示意图,可以看到在Embedding空间中,炸鸡和汉堡彼此距离比较近。

Deep模型
但是Deep模型也有它自身的问题,就是泛化过度,即给用户推荐了不太相关的物品。通过查询历史数据,我们发现实际上存在两种不同的query-item关系。
第一种是精准查询,用户输入了非常精准的食物描述,比如“冰脱脂牛奶拿铁咖啡”,我们不能因为它与“热全脂拉铁咖啡”在Embedding空间中比较相近就推荐给用户。
第二种是宽泛查询,比如用户输入了类似"海鲜"或者“意大利食物”这样的关键字,根据这种具有宽泛意义的关键词可以找到非常多相关的item。
了解到了这些问题之后,一个很自然的想法就是将Wide和Deep模型结合起来使用,如下图:

Wide&Deep模型
如上图所示,对于两个稀疏特征query=“fried chicken” 以及 item=“chicken fried rice”,我们同时丢入Wide模型(左边)和Deep模型(右边)进行训练。这样模型就兼具了记忆和泛化的能力,从而可以达到更好的推荐效果。
Wide&Deep模型
因此在这里引入本文的主角,Wide&Deep模型,如下图:

Wide&Deep模型
上图左边是Wide模型,右边是Deep模型,中间便是Wide&Deep模型了,下面分别来介绍一下:
Wide部分
Wide模型其实就是一个简单的广义线性模型,公式定义如下:

这里需要介绍一下叉乘特征,叉乘特征是通过特定的变换函数对特征进行组合得来的,其中论文使用的是交叉积变换函数,其定义如下:

Deep部分
Deep模型其实就是一个前馈神经网络,网络会对一些稀疏特征(如ID类特征)学习一个低维的稠密Embedding向量,维度通常在O(10)~O(100)之间,然后与一些原始稠密特征一起作为网络的输入,依次通过若干隐层进行前向传播,每一个隐层都执行以下计算:

Wide&Deep联合训练
论文特意强调了Wide模型和Deep模型是联合(Joint)训练的,与集成(Ensemble)是不同的,集成训练是每个模型单独训练,再将模型结果汇总。因此每个模型都会学的足够好的时候才会进行汇总,故每个模型相对较大。而对于Wide&Deep的联合训练而言,Wide部分只是为了补偿Deep部分缺失的记忆能力,它只需要使用一小部分的叉乘特征,故相对较小。
Wide&Deep模型采用的Logistic Loss函数,模型的预测值定义如下:

关于模型训练,论文对Wide部分使用了FTRL算法并且加上了L1正则化,对于Deep部分使用了AdaGrad算法。
实验
作者将Wide&Deep模型运用到了Google Play商店中,当一个用户访问Google Play,会生成一个包含用户和上下文信息的query,推荐系统的精排模型会对于候选池中召回的一系列apps(即item)进行打分,按打分生成app的排序列表返回给用户。
app推荐系统的pipeline包含3个部分,分别是数据生成、模型训练、模型服务。Google Play的app推荐系统管道示意图如下:

论文使用的Wide&Deep模型结构如下:
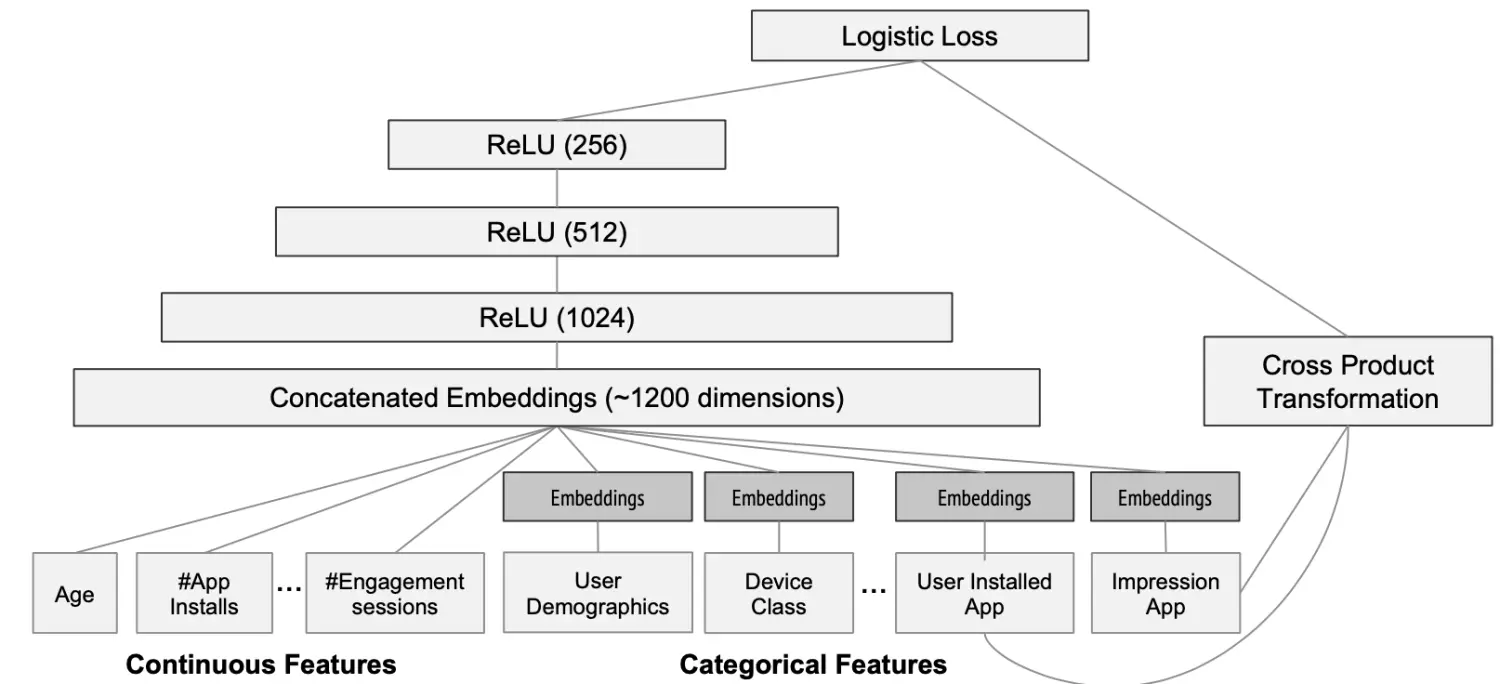
Wide&Deep模型应用于推荐系统中
实验细节如下:
- 训练样本约5000亿
- Categorical 特征(sparse)会有一个过滤阈值,即至少在训练集中出现m次才会被加入
- Continuous 特征(dense)通过CDF被归一化到 [0,1] 之间
- Categorical 特征映射到32维embeddings,和原始Continuous特征共1200维作为神经网络的输入
- Wide部分只用了一组特征叉乘,即已安装的应用和曝光应用
- 线上模型更新时,通过“热启动”重训练,即使用上次的embeddings和模型参数初始化
Wide部分的输入仅仅是已安装应用和曝光应用两类特征,其中已安装应用代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥Wide部分“记忆能力”强的优势。
通过3周的线上A/B实验,实验结果如下,其中Acquisition表示下载。

实验结果
可以看到,经过3周的实验之后,Wide&Deep模型使Google Play应用商店主页上的app下载量提升了3.9%。
代码实践
网络模型部分分别实现了Wide和Deep模型,然后拼接起来实现了Wide&Deep模型,模型部分代码如下:
import torch
import torch.nn as nn
class Wide(nn.Module):
def __init__(self, input_dim):
super(Wide, self).__init__()
# hand-crafted cross-product features
self.linear = nn.Linear(in_features=input_dim, out_features=1)
def forward(self, x):
return self.linear(x)
class Deep(nn.Module):
def __init__(self, config, hidden_layers):
super(Deep, self).__init__()
self.dnn = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_layers[:-1], hidden_layers[1:]))])
self.dropout = nn.Dropout(p=config['deep_dropout'])
def forward(self, x):
for layer in self.dnn:
x = layer(x)
# 如果输出层大小是1的话,这里再使用了个ReLU激活函数,可能导致输出全变成0,即造成了梯度消失,导致Loss不收敛
x = torch.relu(x)
x = self.dropout(x)
return x
class WideDeep(nn.Module):
def __init__(self, config, dense_features_cols, sparse_features_cols):
super(WideDeep, self).__init__()
self._config = config
# 稠密特征的数量
self._num_of_dense_feature = dense_features_cols.__len__()
# 稠密特征
self.sparse_features_cols = sparse_features_cols
self.embedding_layers = nn.ModuleList([
# 根据稀疏特征的个数创建对应个数的Embedding层,Embedding输入大小是稀疏特征的类别总数,输出稠密向量的维度由config文件配置
nn.Embedding(num_embeddings = num_feat, embedding_dim=config['embed_dim'])
for num_feat in self.sparse_features_cols
])
# Deep hidden layers
self._deep_hidden_layers = config['hidden_layers']
self._deep_hidden_layers.insert(0, self._num_of_dense_feature + config['embed_dim'] * len(self.sparse_features_cols))
self._wide = Wide(self._num_of_dense_feature)
self._deep = Deep(config, self._deep_hidden_layers)
# 之前直接将这个final_layer加入到了Deep模块里面,想着反正输出都是1,结果没注意到Deep没经过一个Linear层都会经过Relu激活函数,如果
# 最后输出层大小是1的话,再经过ReLU之后,很可能变为了0,造成梯度消失问题,导致Loss怎么样都降不下来。
self._final_linear = nn.Linear(self._deep_hidden_layers[-1], 1)
def forward(self, x):
# 先区分出稀疏特征和稠密特征,这里是按照列来划分的,即所有的行都要进行筛选
dense_input, sparse_inputs = x[:, :self._num_of_dense_feature], x[:, self._num_of_dense_feature:]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embedding_layers[i](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
# Deep模块的输入是稠密特征和稀疏特征经过Embedding产生的稠密特征的
deep_input = torch.cat([sparse_embeds, dense_input], axis=-1)
wide_out = self._wide(dense_input)
deep_out = self._deep(deep_input)
deep_out = self._final_linear(deep_out)
assert (wide_out.shape == deep_out.shape)
outputs = torch.sigmoid(0.5 * (wide_out + deep_out))
return outputs
def saveModel(self):
torch.save(self.state_dict(), self._config['model_name'])
def loadModel(self, map_location):
state_dict = torch.load(self._config['model_name'], map_location=map_location)
self.load_state_dict(state_dict, strict=False)
数据集方面采用的是criteo数据集的一个很小的子集,仅仅是为了测试模型功能。测试数据并没有标签,因此模型训练好了之后,直接对测试集进行点击率预估,输出的结果是由0,1组成的向量,代表点击与否,部分结果如下:
后记
自己在调试的时候,遇到一个很棘手的问题,就是模型代码设计好了之后,在训练时,无论怎样调整学习率等超参数,损失就是降不下来。自己也搜了很多相关的资料,有很多说的是数据集本身有问题,学习率过小,损失函数不对等等。
结果折腾了半天依然没找到原因。最后通过一步一步对比自己的代码,发现WideDeep模型最后是会将Wide和Deep模型各自的两个输出Tensor相加的,这两个Tensor大小都是1。
而自己当时觉得为了方便,将输出为1的Linear层直接放到了Deep层里面,其实这样做并没有什么问题,但是由于Deep模型进行前向计算时,每次都会经过ReLU激活函数,当Deep模型最后的输出大小为1的时候,再经过ReLU,很可能导致输出直接变为0,即造成了梯度消失的问题。
因此这样无论怎么训练,梯度都无法传递到网络的浅层部分,导致模型参数无法更新,Loss无法降低。通过这次代码调试,自己也算是学到一些技巧了,以后在编写代码的时候要尽可能注意不要犯这样的错误。