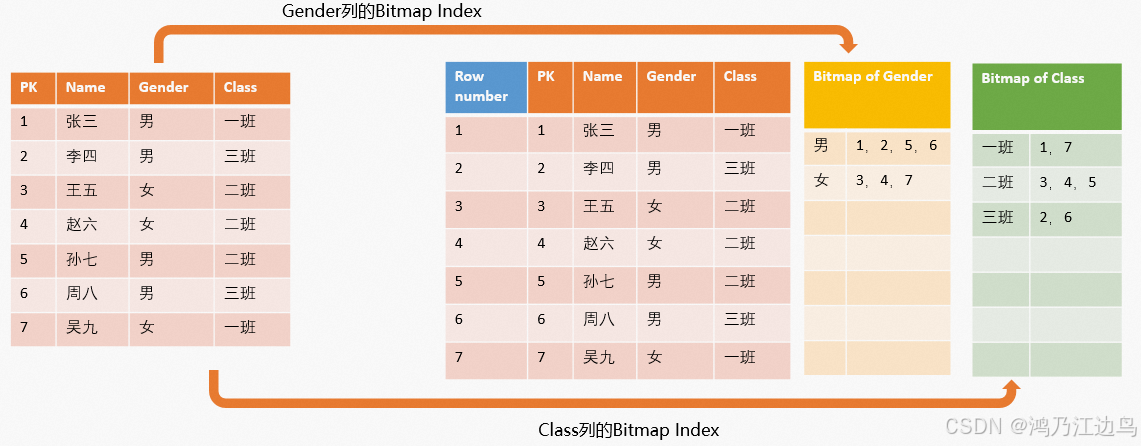
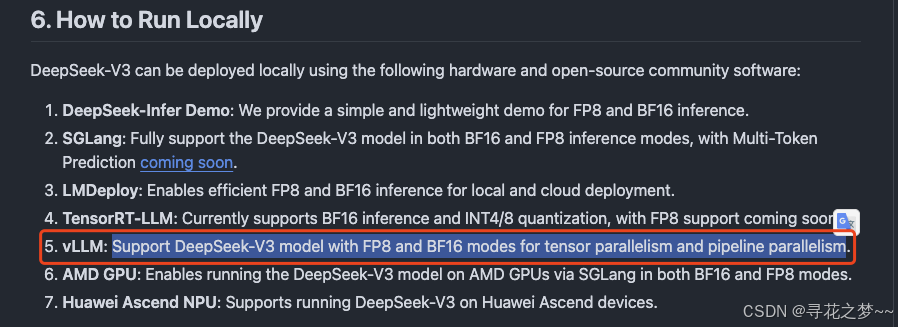
过去十年,Web 和 App 的开发范式基本稳定:前端负责交互体验,后端负责业务逻辑和数据管理。即使是“无服务架构”也只是将后端“拆散”而非“消失”。
但随着 AI 原生应用的兴起,特别是 大模型本地化、小模型部署、WebAssembly、LoRA微调 等技术的成熟,一个全新的架构范式正在悄然出现:
AI App 的下一代形态:前端生成,后端消失。
一、什么是“前端生成,后端消失”?
这是一个由 模型驱动、端侧运行、无服务器依赖 的全新App架构。它具备以下特征:
- AI模型部署在前端(手机、浏览器、边缘设备)
- 核心功能通过前端调用本地模型直接生成结果
- 无后端API依赖,或仅依赖边缘缓存 / 静态资源托管
- 数据本地处理,符合隐私与合规要求
- 代码/功能通过AI“即时生成”而非传统开发
简单说,就是:
| 传统架构 | 下一代AI架构 |
|---|---|
| 前端 + 后端 + API | 纯前端 + 本地AI模型 |
| 开发 -> 部署 -> 运行 | 生成 -> 使用 -> 自演化 |
| 数据传输到云处理 | 数据本地即处理即反馈 |
| 用户依赖服务端更新 | 用户端自学习、自适应更新 |
二、为什么现在是时候了?
这个架构并非幻想,它背后的“燃料”已齐备:
1. 模型本地部署已现实
- Apple 的 CoreML、Google 的 TFLite、Meta 的 Llama.cpp、Mistral、Gemma 等模型,均可运行在手机、浏览器、甚至 ESP32。
- WASM + WebGPU 使得 Transformer 模型在浏览器本地推理成为可能。
2. 边缘算力提升
- iPhone、Android 旗舰机、Apple M 系芯片、Jetson Nano 甚至平板,都可以高效跑小模型。
- RTX 40 系显卡支持本地训练和微调。
3. 生成式AI+Prompt编程范式
- 用户不需要复杂交互逻辑,通过 Prompt 或自然语言就能驱动App。
- 前端本身也可以由AI生成——UI自动适配、功能自动组合。
4. 数据隐私需求倒逼本地处理
- 隐私法规(如GDPR)推动敏感数据不出设备。
- 医疗、教育、金融等场景必须“端上智能”。
三、典型场景举例
-
AI记事本
- 输入一句话,浏览器内的模型解析并生成结构化笔记
- 无需后端存储,数据存入本地IndexedDB或文件系统
-
AI对话助理(嵌入App或手机桌面)
- 小模型Llama3-8B在本地运行,对话实时生成
- 无需调用OpenAI API,无需用户登录
-
手势识别 + 指令执行(AR/投影设备)
- 摄像头采集图像,前端模型识别手势
- 触发预设动作,无需云端控制器
-
个人AI Copilot(浏览器插件、桌面端)
- 本地向量数据库 + 本地模型(如Ollama)组合
- 用户文件全程不上传,无需云端“中控”
四、前端即模型、即应用
在这个新架构中,“前端” 不再是UI层,而是“模型宿主 + 交互接口 + 推理引擎”:
- 前端代码中直接嵌入模型(或通过懒加载机制加载)
- 应用功能通过提示词(Prompt)组合,无需传统编程逻辑
- 用户行为驱动模型生成结果,即时呈现,无需网络请求
它的开发范式也将变化:
| 传统前端开发 | AI原生前端开发 |
|---|---|
| 写JS/React逻辑 | 写Prompt/微指令 |
| 调API接口 | 调本地模型/向量搜索 |
| 构造UI组件 | 用自然语言生成界面 |
| 构建 -> 发布 | 用户端“即生成即用” |
五、这是否意味着后端真的“消失”了?
并不是所有“后端”都会消失,但以下部分将不再必要:
- 用户注册/登录系统:本地模型可做身份验证或根本不需要登录
- 业务逻辑API:用AI生成逻辑,不需要硬编码
- 数据库访问层:数据本地持久化
- 权限校验中间件:模型判断上下文直接决定动作执行
- 模型托管平台:模型直接集成进App中,脱离服务器推理
真正留下来的“后端”,可能是:
- 模型权重/资源的CDN式分发
- 用户行为匿名收集的分析通道
- 协同类App的轻量同步机制
六、未来展望:App将成为“自生、自演化”的智能体
下一代AI App 不再是“我们开发出来交付给用户”的传统模式,而是:
App像一个生物体一样,自我生成、自我适应、自我进化。
用户和App之间的边界会模糊:
- 用户说出需求 → App结构自适应生成
- 用户使用过程 → 模型自动学习优化
- 用户添加知识 → App自动扩展功能
这才是真正的“AI原生App”,它不是“加了AI的传统App”,而是从一开始就以AI为操作系统思考的产物。
七、总结
“前端生成,后端消失” 不是一句口号,而是正在发生的架构革命。
它意味着:
- 更低的开发门槛
- 更强的隐私保障
- 更快的AI落地速度
- 更接近人类自然交互的体验
开发者、创业者和产品设计者都需要重新思考我们所说的“App”,甚至“操作系统”到底是什么。
未来,或许真正强大的App,不再托管在服务器,也不再用传统语言开发——而是,你用一句话就能“长”出来。
八、落地挑战:通向“前端即智能体”的现实阻力
尽管“前端生成,后端消失”愿景令人振奋,但在当前阶段,它依然面临一些实际挑战:
1. 模型大小 vs. 设备算力
- 即便是优化后的 LLaMA 3-8B、Gemma 2B,在嵌入端侧时仍对内存和算力提出较高要求。
- 部分模型在浏览器中仍存在启动缓慢、加载耗时的问题。
✅ 趋势对策:
- 微调小模型(Mistral 7B、Phi-2、TinyLLaMA)并做量化(INT4/INT8)。
- 通过 LoRA + QLoRA 方式本地化用户个性。
- 浏览器端配合 WebGPU + SIMD + WASM 多线程加速。
2. 前端存储与隐私隔离
- 浏览器原生的 IndexedDB、LocalStorage 容量有限、权限脆弱。
- 移动设备上如何安全、高效地持久化数据仍需权衡(尤其是合规性场景如医疗/政务)。
✅ 趋势对策:
- 使用 WebAssembly 模拟文件系统(如 WebR/WASI + SQLite + DuckDB)。
- 移动端采用 Secure Storage + 本地向量数据库(如 Chroma 本地部署、Qdrant edge 模式)。
3. 如何维护“智能体”的一致性与演进性
- 当前 LLM 仍缺乏稳定的行为一致性,Prompt 一变,结果可能截然不同。
- 如果 App 的逻辑依赖 Prompt,本身就缺少“代码确定性”。
✅ 趋势对策:
- 使用 Prompt 模板 + Function Calling 构造结构化思维链(Chain of Thought)。
- 建立小型 RAG 系统,在本地做自我检索+生成。
- 用 DSL(领域特定语言)描述功能,由模型翻译执行。
九、工具链与生态:下一代开发者的“全新 IDE”
构建 AI 原生 App,不再是 VSCode + Node.js 的旧世界,而是围绕以下核心工具链:
| 方向 | 工具/框架 | 说明 |
|---|---|---|
| 本地模型运行 | Ollama、Mistral.cpp、llm.c | 一行命令跑起轻量模型 |
| Web 推理 | Transformer.js、WebLLM、Llama.cpp + WebAssembly | 模型直接运行在浏览器 |
| 模型微调 | LoRA、QLoRA、BentoML、Axolotl | 个性化调教,不依赖服务器 |
| 向量检索 | LanceDB、Chroma、DuckDB(本地模式) | 小型知识库自组织 |
| 前端 AI 接口 | LangChain.js、OpenAgents、AutoGen UI | 将模型变成“前端 API” |
| UI生成器 | Gradio、WebUI、Replicate + Vercel | 用Prompt构建界面交互 |
未来 IDE 的核心不再是代码,而是:
- Prompt 模块化管理
- 模型调试与可视化
- 意图流追踪与行为一致性测试
十、开发者:从“写代码”到“设计智能体”的迁移
这种范式转变下,开发者的核心能力也发生了本质变化:
| 旧技能 | 新技能 |
|---|---|
| 编写 API | 构建 Prompt 和意图流 |
| 写业务逻辑 | 设计“思维路径”与“反应机制” |
| 前后端联调 | 前端内集成模型与向量检索 |
| 数据建模 | 知识图谱构建 + 上下文检索链 |
| UI开发 | UI由模型生成,开发者定义“交互意图” |
甚至于,非程序员也将成为 App 的“创造者” —— 用一句话或一个例子就能生成功能,微调模型行为。
十一、结语:拥抱一个后端终将隐退的时代
“前端生成,后端消失” 并不是一个极端,而是一个必然。
未来的应用将越来越像是用户的“共生智能体”——在本地理解、生成、记忆与进化。后端将变得越来越轻,最终隐入技术栈之下,直至被用户彻底感知不到。
开发者的身份,也正在从“功能制造者”转变为“智能体设计师”。
这将是一个全新的时代。
而我们正处在它的清晨。