遇到的问题:当时用并行流的时候期望结果7,但是偶尔会有结果不对的情况。。。
如下代码:
public static void main(String[] args) {
long start=System.currentTimeMillis();
List<String> alist = new ArrayList<String>(Arrays.asList("1","2","3","4","5","6","7"));
for(int i=0;i<100000;i++) {
Map<String, String> result = new HashMap<>();
alist.parallelStream().forEach(item->{
result.put(item, item);
});
System.out.println("i="+i+",map大小:"+result.size());
}
System.out.println("执行耗时:"+(System.currentTimeMillis()-start)/1000);
}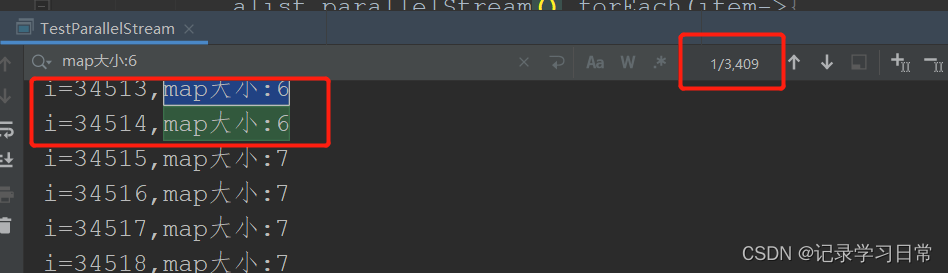 从结果来看:10万条数据,有三千多数据是错误的,这影响很大
从结果来看:10万条数据,有三千多数据是错误的,这影响很大
解决的方式:
- 保证并行流中的变量线程安全
for(int i=0;i<100000;i++) {
Map<String, String> result = new ConcurrentHashMap<>();
//Map<String, String> result = new HashMap<>();
alist.parallelStream().forEach(item->{
result.put(item, item);
});
System.out.println("i="+i+",map大小:"+result.size());
}
- 使用jdk8中的collect收集结果
for(int i=0;i<100000;i++) {
Map<String, String> result = new HashMap<>();
result=alist.parallelStream().collect(Collectors.toMap(e->e,e->e));
System.out.println("i="+i+",map大小:"+result.size());
}
但是这种方式是保证了线程安全,没保证效率,收集还是单线程执行的,alist数量大时会稍微快点
综上考虑还是采用第一种方式会更好。
测试代码:
public static void main(String[] args) { long start=System.currentTimeMillis(); List<String> alist = new ArrayList<String>(Arrays.asList("1","2","3","4","5","6","7")); //测试时没效果的,保证安全是要并行流中的变量线程安全 //List<String> list = Collections.synchronizedList(alist); for(int i=0;i<100000;i++) { //Map<String, String> result = new ConcurrentHashMap<>(); Map<String, String> result = new HashMap<>(); //.parallelStream().collect(Collectors.toList())相当于没用并行,时间没有缩短 result=alist.parallelStream().collect(Collectors.toMap(e->e,e->e)); System.out.println("i="+i+",map大小:"+result.size()); } System.out.println("执行耗时:"+(System.currentTimeMillis()-start)/1000); }
如果被抢占,还可以这么写
由于默认并行流使用的是全局的线程池,线程数量是根据cpu核数设置的,所以如果某个操作占用了线程,将影响全局其他使用并行流的操作
所以折中的方案是自定义线程池来执行某个并行流操作
| 1 2 3 4 5 6 |
|