文章目录
- ChatGPT是什么
- GTP中的 生成式 是什么意思
- GTP中的 预训练 是什么意思
- GTP中的 变换模型 是什么意思
- 什么是Transformer
- 什么是注意力机制
- 监督学Xi、无监督学Xi、强化学Xi

ChatGPT是什么
GPT: Generative Pre-trained Transformer
生成式预训练变换模型
ChatGPT是由OpenAI开发的一个自然语言处理(NLP)模型,是一个基于人工智能技术的语言模型,它能够根据输入的文本生成自然语言回复。
"GPT"是"Generative Pre-trained Transformer"的缩写,是OpenAI开发的一种基于Transformer架构的深度学Xi模型,它能够根据输入的文本生成类似于人类语言的自然语言回复。
ChatGPT中的"G"(Generative)代表生成式,“P”(Pre-trained)代表预训练,“T”(Transformer)代表Transformer架构。
GTP中的 生成式 是什么意思
在GPT (Generative Pre-trained Transformer)中,生成式(generative)意味着这个模型能够生成新的文本序列。这与其他类型的自然语言处理模型不同,其他模型主要是用来对文本进行分类或者预测文本的标签。
通过预训练,GPT 模型能够学Xi大量的自然语言文本,从而能够捕捉到自然语言的语法、结构和语义等方面的规律。一旦GPT模型完成训练,就可以用来生成新的文本,这些文本是基于已经学Xi到的文本规律和结构进行生成的。
通过生成新文本,GPT模型可以应用于多种自然语言处理任务,例如:文本摘要、机器翻译、对话系统、问题回答、自动写作等等。GPT 的生成式能力使其成为自然语言生成任务中的一种有力工具,能够为自然语言处理领域带来新的创新和进步。
👉 简单来说 生成式就它能自发的生成内容
生成式AI的应用非常广泛,从自动摘要到文本生成、从语音合成到自然语言理解、从图像生成到计算机视觉,生成式AI正在改变许多行业。
GTP中的 预训练 是什么意思
预训练(Pre-training) 是指在大规模数据集上进行无监督学Xi,学Xi到一些通用的特征或知识,井将这些特征或知识迁移到其他任务上,用于增强模型的泛化能力和表现。预训练技术在自然语言处理。计算机视觉等领域中得到了广泛应用,并且在很多任务上取得了非常好的效果。
在自然语言处理领域,预训练通常指在大规模的语料库上进行无监督学Xi,学Xi到一些通用的语言知识,例如单词的词向量表示。句子的语义表示等等。这些预训练模型通常基于深度神经网络,例如递归神经网络(RNN) 。长短时记忆网络(LSTM) 。卷积神经网络(CNN)等,通过对大规模数据集进行预训练,可以得到一个通用的特征表示,然后可以将这些特征迁移到其他任务上,例如文本分类、命名实体识别、机暴翻译等任务。
在计算机视觉领域,预训练通常指在大规模的图像数据集上进行无监督学Xi,学Xi到一些通用的特征表示,例如图像的纹理、边缘、颜色等等。这些预训练模型通常基于卷积神经网络(CNN),例如AlexNet. VGG. ResNet等,通过对大规模数据集进行预训练,可以得到一个通用的特征表示,然后可以将这些特征迁移到其他任务上,例如图像分类、目标检测、图像分割等任务。
总之,预训练是一种在大规横数据集上进行无监督学Xi的技术,通过学Xi通用的特征或知识,可以增强模型的泛化能力和表现,并在自然语言处理、计算机视觉等领域中取得了广泛应用。
👉 简单来说 预训练不需要你拿到它在训练,它是个通用的语言模型,直接拿来用就可以了
预训练模型(Pre-trained Model)是指在大规模语料库的基础上,通过算法学Xi得到的一种预训练模型。这些模型通常是通过使用Transformer、LSTM等深度学Xi架构,以及针对不同任务和领域的数据进行训练得到的。
在语言模型领域,预训练模型主要用于自然语言处理(NLP)任务,例如文本分类、情感分析、问答系统等。预训练模型的优势在于,它们已经被大量的语料库训练,可以针对各种任务和领域进行优化,从而在性能上比传统的全手动训练模型更加优越。
GTP中的 变换模型 是什么意思
变换模型(Transtformer) 是一种基于自注意力机制的神经网络结构,最初是由Vaswani等人在论文"Attention is All You Need"中提出的。该结构主要用于自然语言处理任务,特别是机器翻译任务,由于在这些任务中序列的长度通常很长,因此传统的循环神经网络(RNN) 和卷积神经网络(CNN) 的效果不理想,而Transformer通过引入自注意力机制,实现了对序列的并行处理,井取得了较好的效果。
在Transformer中,自注意力机制可以在不同位置之间计算注意力权重,从而获得一个综合的表示。具体来说,输入序列首先经过一个叫做嵌入层(Embedding) 的模块,将每个单词嵌入到一个d维的向量空间中。然后,经过多个层次的自注意力和前馈神经网络(Feed-Forward Network)的计算,得到最终的输出。自注意力机制可以在序列中的每个位置计算权重,从而计算每个位置与序列中其他位置的关系。这样的注意力机制可以捕获序列中的长期依赖关系,而不像传统的RNN和LSTM一样,只能处理有限长度的序列。
变换模型在自然语言处理领域中应用广泛,特别是在机器翻译、文本分类、语言模型等任务中取得了非常好的效果。同时,变换模型的结构也被广泛应用到其他领域,例如图像处理、语音识别等任务中,成为了种重要的神经网络结构。
👉 简单来说 变换模型(Transtformer) 就是Google 提出来的一个模型它可以帮助更好的处理NLP相关的问题,是一种很强的神经网络结构。
变换模型(Transformer)是一种自然语言处理(NLP)模型,最初由Google在2017年提出,用于处理序列到序列的任务,例如机器翻译、文本生成、语言模型等。
传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理序列数据时,容易出现梯度消失或梯度爆炸的问题,导致模型难以训练和效果不佳。而变换模型则引入了新的变换方式,如位置编码、注意力机制等,使得模型能够更好地捕捉序列数据中的长期依赖关系。
变换模型主要包括两个基本变换:位置编码和注意力机制。
位置编码:位置编码是指将输入序列中的每个位置进行编码,得到一个向量,该向量表示该位置在输入序列中的相对位置。这样,模型可以更好地捕捉输入序列中的长期依赖关系,例如语言的上下文信息。
注意力机制:注意力机制是指将输入序列中不同位置的信息进行加权平均,以更好地捕捉不同位置之间的依赖关系。例如,在处理自然语言时,模型可能会根据上下文信息对不同单词进行加权,以更好地区分相关单词。
总的来说,变换模型的引入使得序列到序列的任务处理变得更加容易,同时也提高了模型的表达能力和效果。
什么是Transformer
引用:http://jalammar.github.io/illustrated-transformer/
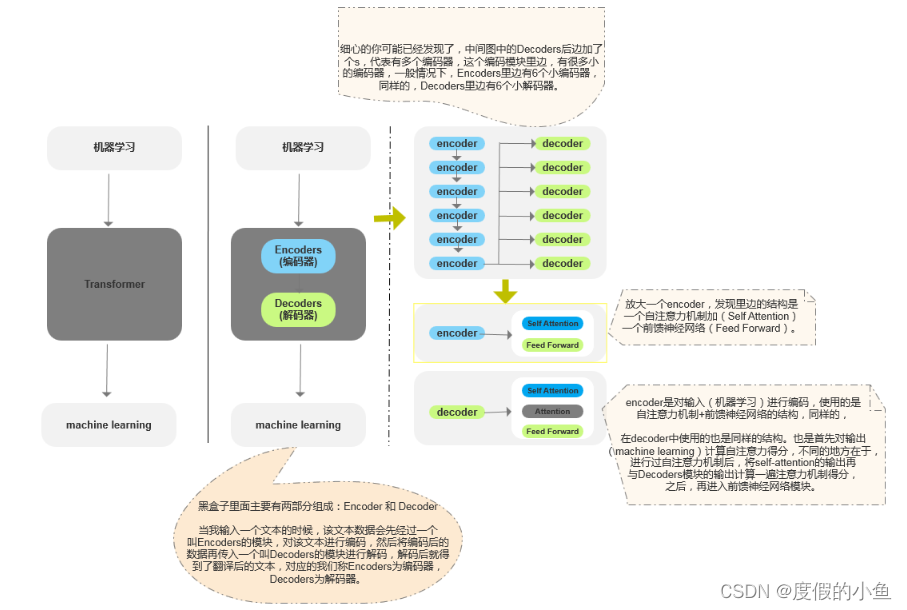
Transformer 可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。
Transformer不等于预训练模型,它不能完全摆脱人工标注数据。模型在质量上更优,更易于并行化,所需训练的时间明显变少。
什么是注意力机制
注意力机制(Attention Mechanism)是种神经网络结构,用于计算输入序列中不同部分之间的重要性,并将其应用于不同的自然语言处理任务中。注意力机制最初是在机器翻译任务中引入的,但现在已经广泛应用于各种自然语言处理任务中。
在自然语言处理中,注意力机制可以用于计算每个单词在上下文中的重要性,并将这些重要性应用于模型的输出中。例如,在机器翻译任务中,输入是源语言的一一句话,输出是目标语喜的一句话。注意力机制可以帮助模型关注源语言中与目标语言相美的部分,并将其翻译为目标语言。
注意力机制的计算过程通常由三个步骤组成:查询、键值对,计算权重。首先,将输入序列经过线性变换得到查询向量,将上下文序列经过线性变换得到健值对。然后,通过计算查询向量与每个键的相似度,得到注意力权重。最后根据注意力权重和键值对计算加权平均值,得到输出向量。
总之,注意力机制是一种神经网络结构,用于计算输入序列中不同部分之间的重要性,并将其应用于各种自然语言处理任务中。注意力机制可以帮助模型关注与任务相关的部分,并取得了在很多自然语言处理任务中非常好的效果。
用小学生可以理解的例子,形象的解释一下什么是Transformer中的注意力机制
假设你是一个小学生,你正在看一本厚厚的科普书,里面有许多重要的知识点,但你只有一定时间来阅读它。这时候,如果你能够集中注意力在最重要的知识点上,忽略那些不重要的内容,你就能更好地理解书中的内容。
在机器翻译中,Transformer模型也需要类似的能力,即需要从输入的源语言句子中挑选出最重要的部分来翻译成目标语言句子。注意力机制就是帮助Transformer模型集中注意力在输入序列中最重要的部分上的一种技术。让我们用一个例子来解释下Transformer模型中的注意力机制。 比如你正在学Xi一个英文句子:"The cat sat on the mat"想要将其翻译成中文。当Transformer模型对这个句子进行编码时,它会将句子中每个单词表示成一个向量,然后将这些向量输入到一个注意力机制中。
注意力机制会计算每个单词与其他单词的相关性,并给它们分配一个注意力权重。在这个例子中,注意力机制可能会将“cat"和"mat"之间的关系分配更高的权重,因为它们之间有一个"on the"短语,而这个短语对于理解整个句子的意思非常重要要。然后,这些注意力权重会被用来对单词向量进行加权产生一个加权向量,表示整个输入序列的含义。
在翻译过程中,这个加权向量会被传递到解码器中,解码器会根据这个加权向量生成对应的中文句子。这样,注意力机制就可以帮助Transformer模型集中注意力在输入序列中最重要的部分上,从而更好地理解输入序列和生成输出序列。
总之,注意力机制就像是在输入序列中找出最重要的信息,帮助模型更好地理解输入和输出。这个过程类似于小学生在学Xi中筛选出重要知识点,集中精力理解它们的过程。
这就好像你看到一个小学生,还是一个博士生,你肯定会用不同的方法来解释一件事情。但是ChatGPT没有眼睛,它看不到你是小学生还是博士生,所以你要给它一个印象,让他知道怎么回答你更好,这种感觉的。
监督学Xi、无监督学Xi、强化学Xi
生成式AI可以这样定义:通过各种机器学Xi(ML)方法从数据中学Xi工件的组件(要素),进而生成全新的、完全原创的、真实的工件(一个产品或物品或任务),这些工件与训练数据保持相似,而不是复制。 其本质是一种深度学Xi模型,是近年来复杂分布上无监督学Xi最具前景的方法之一。
生成式AI有三个主要的特点:
- 监督学Xi:监督学Xi主要是指在预训练过程中使用一组监督信号来训练模型。这些监督信号可以是真实的文本数据,也可以是一些标注数据,用来指示模型应该生成怎样的输出。通过在训练过程中使用这些监督信号,可以帮助模型更好地学习语言模式和知识,并生成更加自然和准确的输出。
- 无监督学Xi:生成式模型不需要标签来指定输入数据的类别,而是利用输入数据本身的特征进行训练。
- 强化学Xi:生成式模型可以通过尝试不同的行动来学Xi,就像在现实世界中一样,它可以通过尝试不同的行动来学Xi最佳策略。
生成式AI的应用非常广泛,从自动摘要到文本生成、从语音合成到自然语言理解、从图像生成到计算机视觉,生成式AI正在改变许多行业。
尝试不同的行动来学Xi,就像在现实世界中一样,它可以通过尝试不同的行动来学Xi最佳策略。
生成式AI的应用非常广泛,从自动摘要到文本生成、从语音合成到自然语言理解、从图像生成到计算机视觉,生成式AI正在改变许多行业。