| 概念 | 概念理解和解释 | 备注 |
| 窄依赖 | 窄依赖指1个父RDD分区数据只被1个子RDD的分区使用,即一对一或多对一的关系。 分为两种映射情况:一个父RDD的分区对应于一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区。 1个子RDD的分区对应于1个父RDD的分区,比如map,filter,union等算子 1个子RDD的分区对应于N个父RDD的分区,比如co-partioned join | 两个或者固定几个part合到一个part,起到减少分区的作用,这个也是窄依赖,比如coalese。(coalese有参数可是设置shuffle使其从窄依赖变成宽依赖)
|
| 宽依赖 | 宽依赖是指1个父RDD分区数据被多个子RDD分区使用,即一对多或多对多的关系。 宽依赖有分为两种情况 1个父RDD对应非全部多个子RDD分区,比如groupByKey,reduceByKey,sortByKey 1个父RDD对应所有子RDD分区,比如未经协同划分的join | RDD之间的依赖关系分为宽依赖、窄依赖。 Repartition 是宽依赖。 |
| 为什么要理解spark的宽依赖、窄依赖这个概念? | 1 窄依赖(narrow dependency) 可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败回复也更有效,因为它只需要重新计算丢失的parent partition即可 2 宽依赖(shuffle dependency) 则需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,shuffle dependency牵涉RDD各级的多个parent partition。 | 窄依赖,如果一个part失败了,只需要固定几个父part重跑,宽的就需要所有的都重跑了 |
| 有向无环图 | RDD之间的依赖关系形成DAG。 在Spark作业调度系统中,调度的前提是判断多个作业任务的依赖关系,这些作业任务之间可能存在因果的依赖关系,也就是说有些任务必须先获得执行,然后相关的依赖任务才能执行,但是任务之间显然不应出现任何直接或间接的循环依赖关系,所以本质上这种关系适合用DAG表示 | |
| stage划分 | 由于shuffle依赖必须等RDD的父RDD分区数据全部可读之后才能开始计算,因此Spark的设计是让父RDD将结果写在本地,完全写完之后,通知后面的RDD。后面的RDD则首先去读之前RDD的本地数据作为输入,然后进行运算。 由于上述特性,讲shuffle依赖就必须分为两个阶段(stage)去做: (1)第1个阶段(stage)需要把结果shuffle到本地,例如reduceByKey,首先要聚合某个key的所有记录,才能进行下一步的reduce计算,这个汇聚的过程就是shuffle。 (2) 第二个阶段(stage)则读入数据进行处理。 为什么要写在本地? 后面的RDD多个分区都要去读这个信息,如果放到内存,假如出现数据丢失,后面所有的步骤全部不能进行,违背了之前所说的需要父RDD分区数据全部ready的原则。 同一个stage里面的task是可以并发执行的,下一个stage要等前一个stage ready(和map reduce的reduce需要等map过程ready一脉相承)。 |
|
spark底层原理理解--高级进阶
news2026/3/25 7:29:27


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/4790.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

深入理解JS作用域链与执行上下文
变量提升:
变量提升( hoisting )。
我可恨的 var 关键字:
你读完下面内容就会明白标题的含义,先来一段超级简单的代码:
<script type"text/javascript">var str Hello JavaScript hoi…
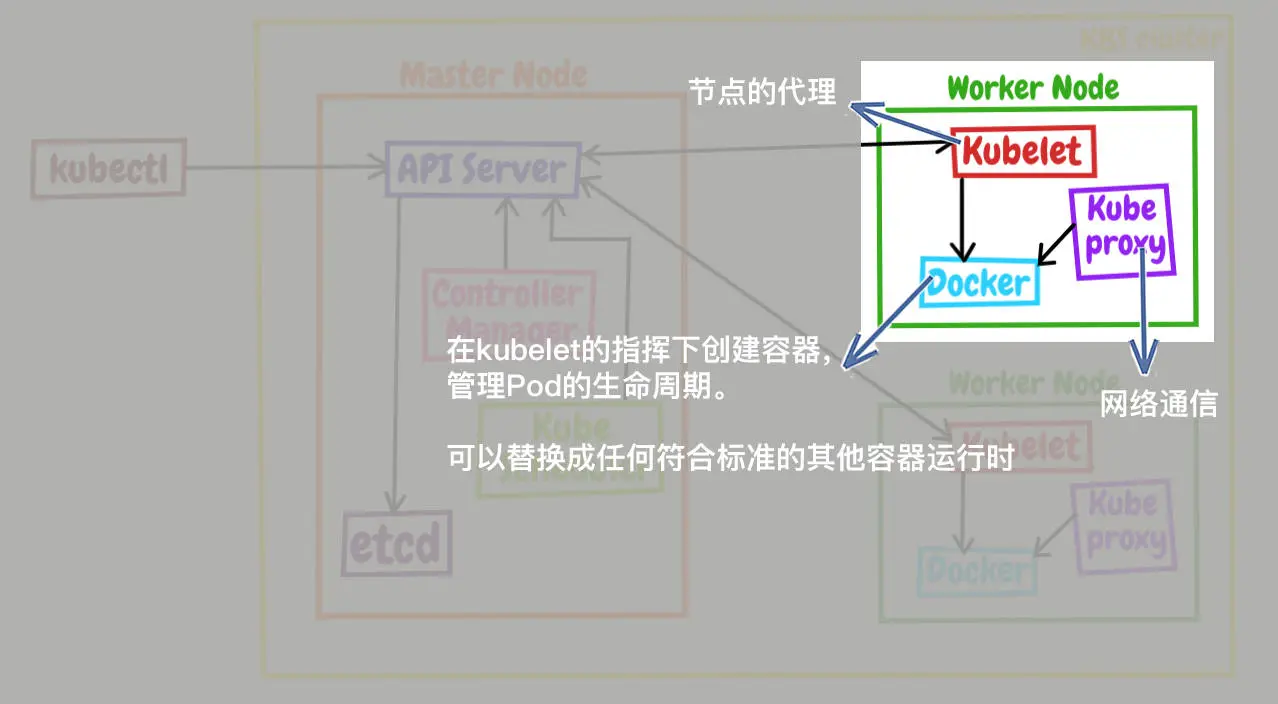
【K8S】初探Kubernetes
文章目录什么是容器编排什么是KubernetesK8s 和 Docker 之间的关系Kubernetes的整体架构Master 里的组件构成Work Node 里的组件构成总结K8s 组件工作流程结束语什么是容器编排
在《Docker 进阶指南(下)- 使用Docker Compose编排多个容器》文章当中&…


【数据结构】带头双向链表的简单实现
目录前言链表的实现List.hList.c**ListCreate()****LTInit()****ListPushBack()****ListPopBack()****ListPrint()****ListPushFront()****ListPopFront()****ListFind()****ListInsert()****ListErase()**ListErase()test.c前言 该篇博客主要讲解了带头双向链表的实现和一些细…
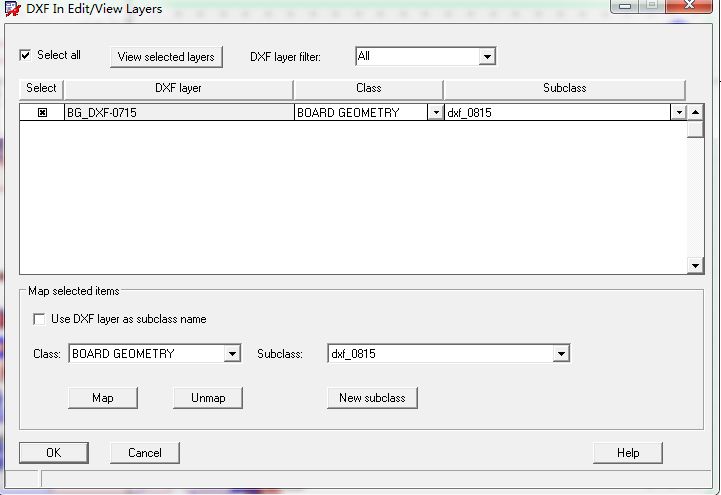
Cadence Allegro DXF结构图的导入详细教程
很多消费类板卡的结构都是异形的,由专业的CAD结构工程师对其进行精准的设计,PCB布线工程师可以根据结构工程师提供的2D图(DWG或DXF格式)进行精准的导入操作,在PCB中定义板型结构。
同时,对于一些工控板或者…
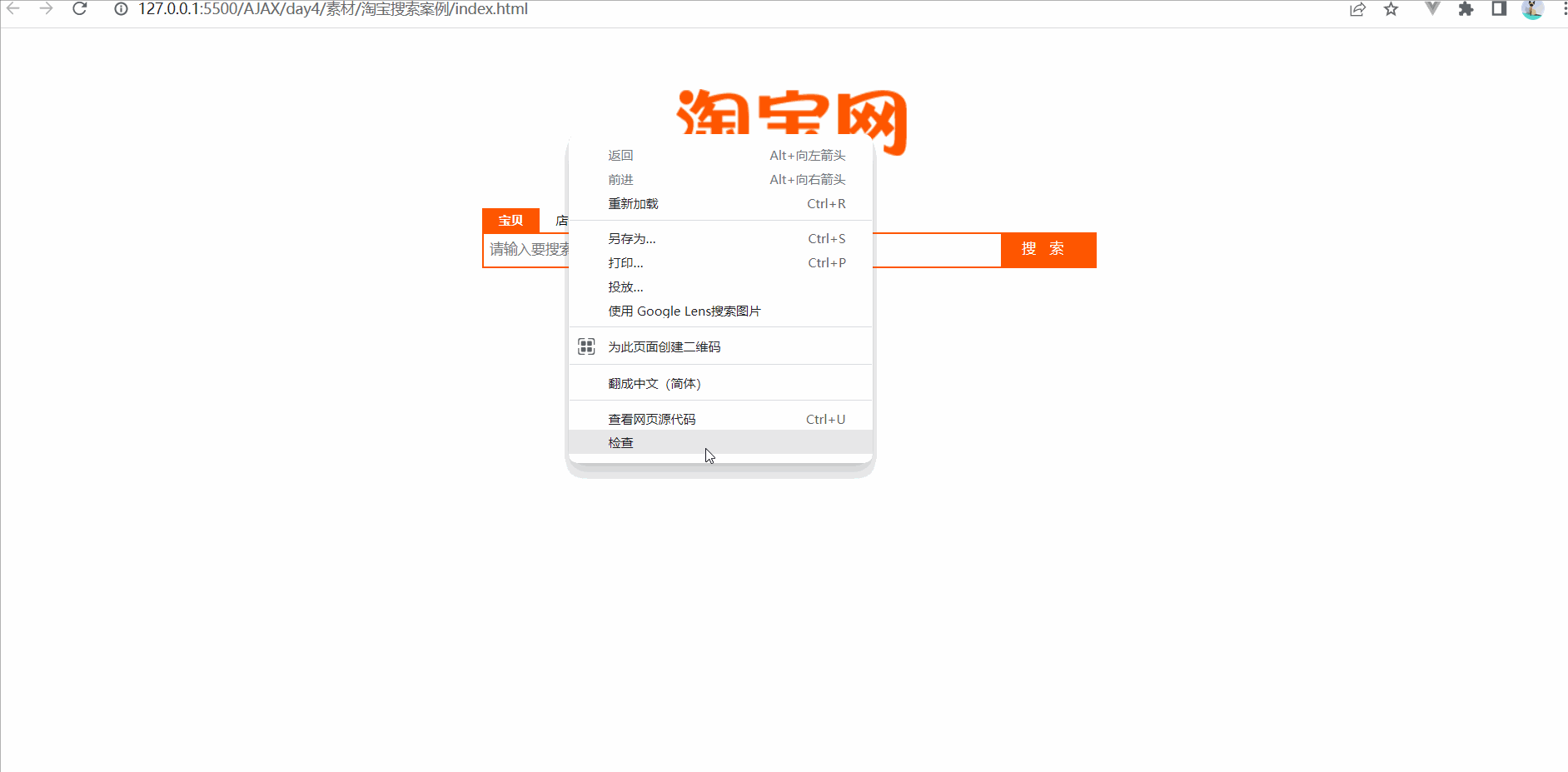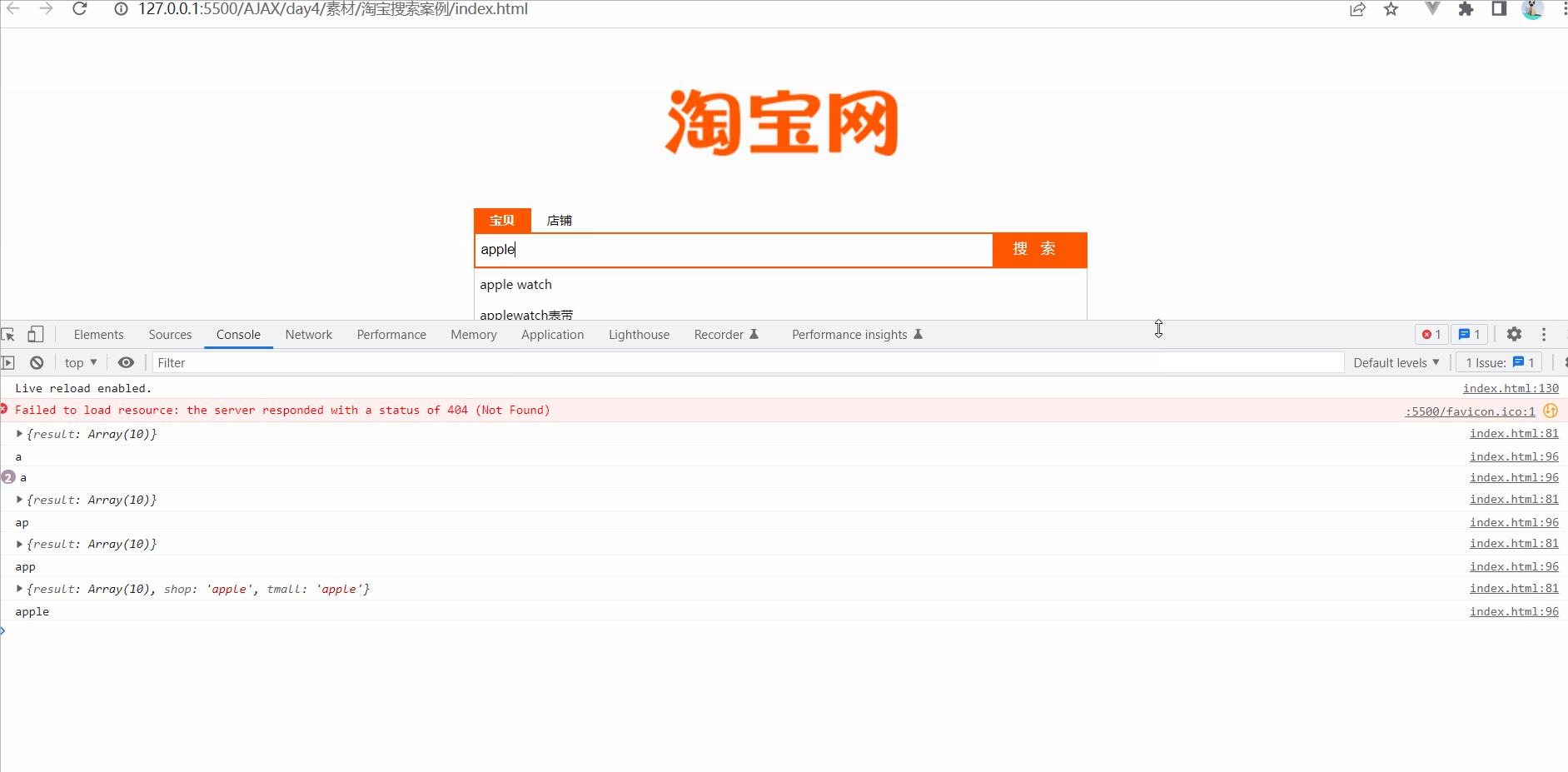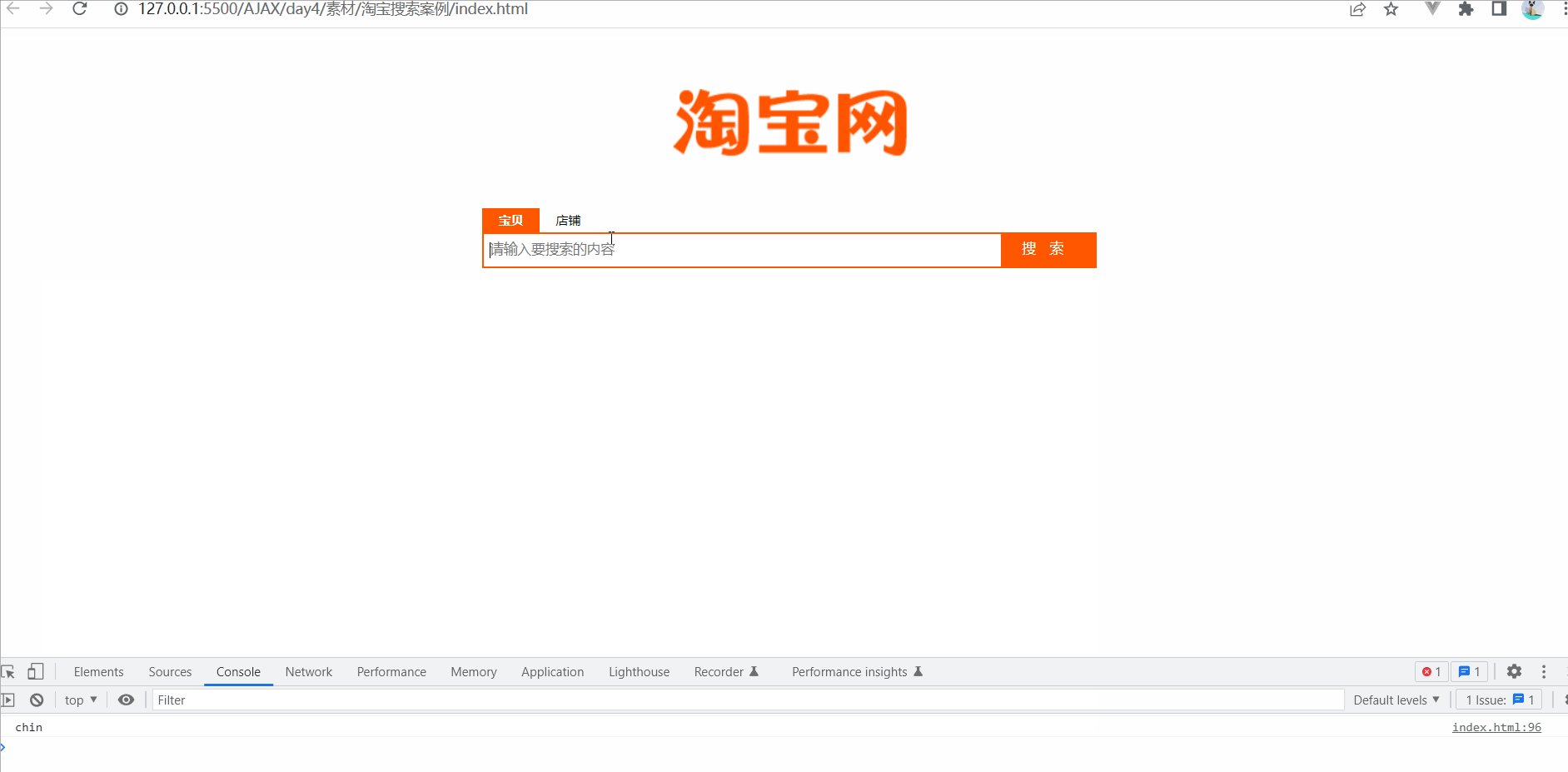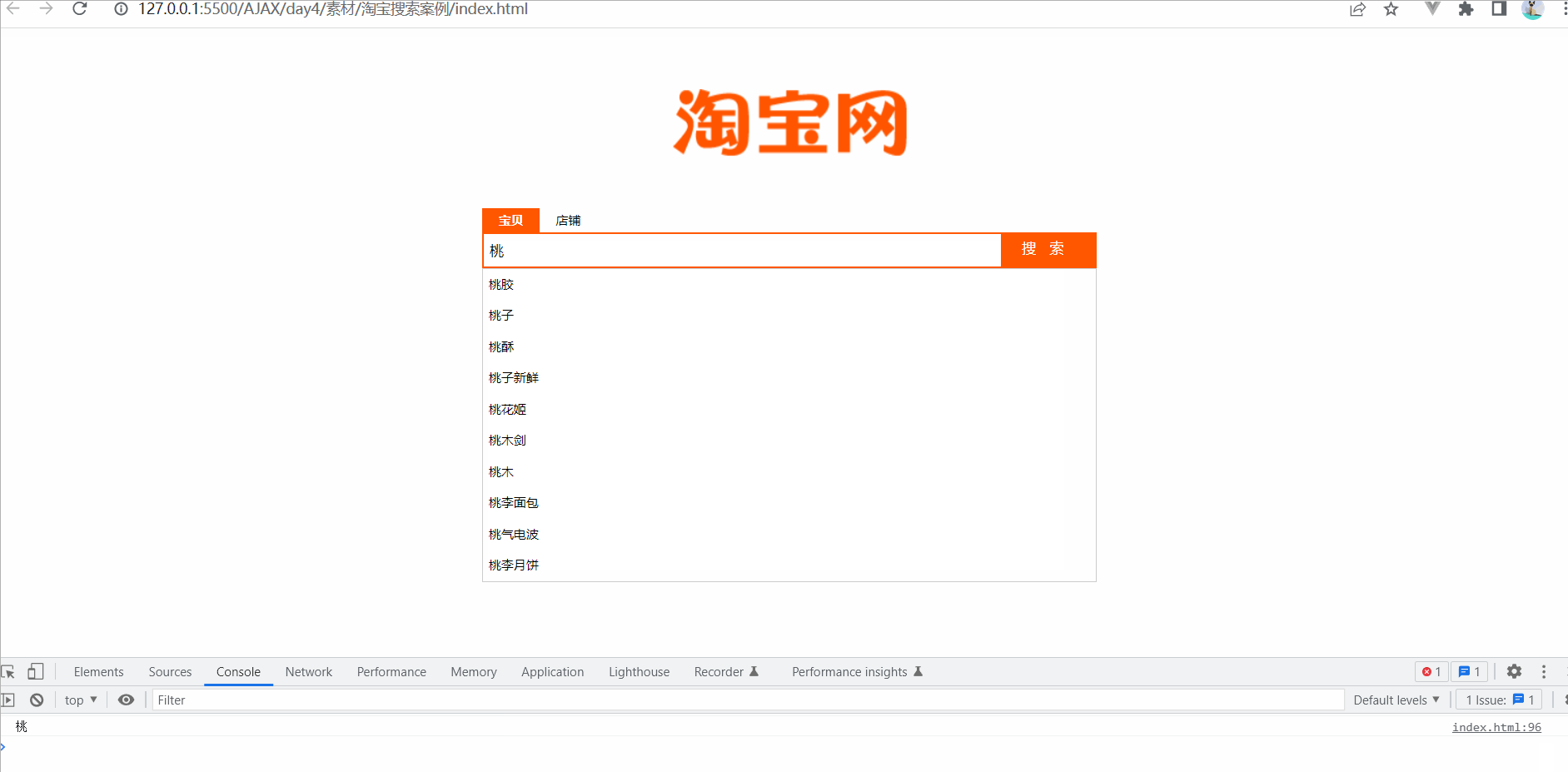
Ajax--跨域与JSONP--案例-淘宝搜索
要实现的UI效果 获取用户输入的搜索关键词
为了获取到用户每次按下键盘输入的内容,需要监听输入框的 keyup 事件,示例代码如下:
// 监听文本框的 keyup 事件$(#ipt).on(keyup, function() {// 获取用户输入的内容var keywords $(this).val…


HTML期末作业:基于html+css+javascript+jquery实现古诗词网页 学生网页设计作品 web前端开发技术 web课程设计 网页规划与设计
🎉精彩专栏推荐 💭文末获取联系 ✍️ 作者简介: 一个热爱把逻辑思维转变为代码的技术博主 💂 作者主页: 【主页——🚀获取更多优质源码】 🎓 web前端期末大作业: 【📚毕设项目精品实战案例 (10…

初学C语言有什么建议?
什么?开玩笑,新手学C语言?
确实新手不学C语言学什么呢?为什么这么推荐新手学C语言呢具体看看下面的解释吧?
C的重要性
我总结了网上很多人的说法如下:
C语言是计算机界公认的有史以来最重要的语言。C语…
R语言偏相关和典型相关
本文首发于公众号:医学和生信笔记,完美观看体验请至公众号查看本文。 文章目录偏相关(partial correlation)偏相关散点图典型相关(Canonical Correlation)使用R语言实现偏相关分析和典型相关分析࿰…

一个对C#程序混淆加密,小巧但够用的小工具
对于我们程序员来说,平常开发的桌面应用程序,如果不进行一定程度的加密、混淆,是很容易通过反编译手段进行破解的,特别是一些商业用途的C#软件,更是容易被破解。
所以今天给大家推荐一个对C#程序加密混淆项目…

脱离CRUD苦海 !性能优化全栈小册来了!
性能优化
随着互联网的高速发展,互联网行业已经从IT时代慢慢步入到DT时代。对于Java程序员的要求越来越高,只是单纯的掌握CRUD以不足以胜任互联网公司的相关职位,大量招聘岗位显示:如果是面试中高级的Java岗,基本上都…
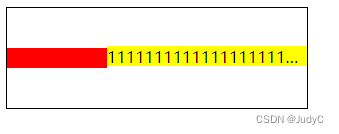
flex1时内容溢出
目标效果:右边黄色部分填充减去红色部分的剩余部分
原理: flex: 1 代码:
<div class"box"><div class"inner-left"></div><div class"inner-right"><span class"inner-right-content&…

RK3568平台开发系列讲解(NPU篇)让 NPU 跑起来
🚀返回专栏总目录 文章目录 一、在 Android 系统中使用 NPU1.1、下载编译所需工具1.2、修改编译工具路径1.3、更新 RKNN 模型1.4、编译 demo沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将介绍如何让NPU跑起来。
一、在 Android 系统中使用 NPU 下载 rknpu2 …
Hadoop的eclipse搭建(客观莫划走,留下来看一眼(适用人群学生初学,其他人看看就行))
前言:Hadoop的eclipse搭建是建立在Hadoop的安装之后进行的,因为Linux上的Hadoop和Windows上的Hadoop版本要求一致,不一致可能会出现某些问题
准备工作:Java的安装包、eclipse的安装包、Hadoop的包(Windows的Hadoop安装…
基于Socket编程下 实现Linux-Linux、Linux-Windows udp通信
文章目录一、通信实现二、Linux-Linux1. 服务器 Server2. 客户端 Client三、Linux-Windows1. 服务器 Linux_Server2. 客户端 Windows_Client程序源码一、通信实现
1. Linux-Linux 在虚拟机下开启俩个终端,分别运行服务器和客户端程序(服务器运行在前,客…
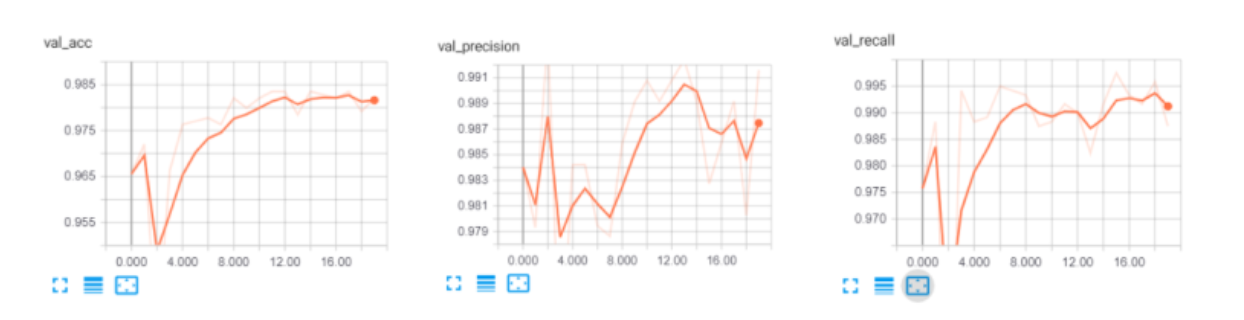
【毕业设计】垃圾邮件(短信)分类算法研究与实现 - 机器学习
文章目录1 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后1 前言
🔥 Hi,大家好,这里是丹成学长的毕设系列文章!
&#…

Vue面试题-答案、例子
1、Vue的生命周期 每一个vue实例从创建到销毁的过程,就是这个vue实例的生命周期。在这个过程中,他经历了从开始创建、初始化数据、编译模板、挂载Dom、渲染→更新→渲染、卸载等一系列过程。
将要创建 >调用beforeCreate函数 创建完毕 >调用creat…
振弦采集模块复位( 重启)及恢复出厂设置
振弦采集模块复位( 重启)及恢复出厂设置 以下几种情况(或操作)可使模块产生复位动作,重新启动。 ( 1) 在模块正常工作期间,向寄存器 SYS_FUN 发送软复位指令 0x01; &…