文章目录
- 前言
- 一、ChatGPT训练原理
- 二、采样和微调阶段
- 三、采样和训练奖励模型阶段
- 三、采样和训练奖励模型阶段
- 总结
前言
ChatGPT发展到目前,其实网上已经有大量资料了,博主做个收口,会出一个ChatGPT探索系列的文章,帮助大家深入了解ChatGPT的。整个系列文章会按照一下目标来完成:
- 理解ChatGPT的背景和应用领域;
- 学习GPT模型系列的发展历程和原理;
- 探究ChatGPT的训练、优化和应用方法;
- 分析ChatGPT在各领域的实际案例;
- 讨论人工智能伦理问题及ChatGPT的责任;
- 思考ChatGPT的未来发展趋势和挑战。
本次ChatGPT探索系列之一的主题是探究ChatGPT的训练、优化和应用方法。在本篇文章中,我们将探讨ChatGPT的训练、优化和应用方法,了解其背后的技术原理,帮助您更好地利用ChatGPT进行各种场景的自然语言处理任务。
如果对ChatGPT相关资料感兴趣的同学,可以直接访问开源资料库:ChatGPT_Project
一、ChatGPT训练原理
注:本文内容基于GPT-3.5进行构建。
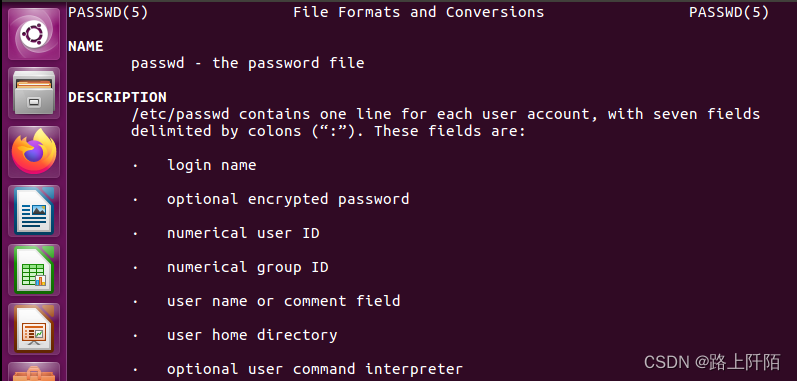
ChatGPT是由OpenAI开发的一种最先进的语言模型,采用深度神经网络架构生成类似人类的文本。ChatGPT的主要组成部分是演员模型和评论家模型,通过使用强化学习与人类反馈(RLHF)进行训练。
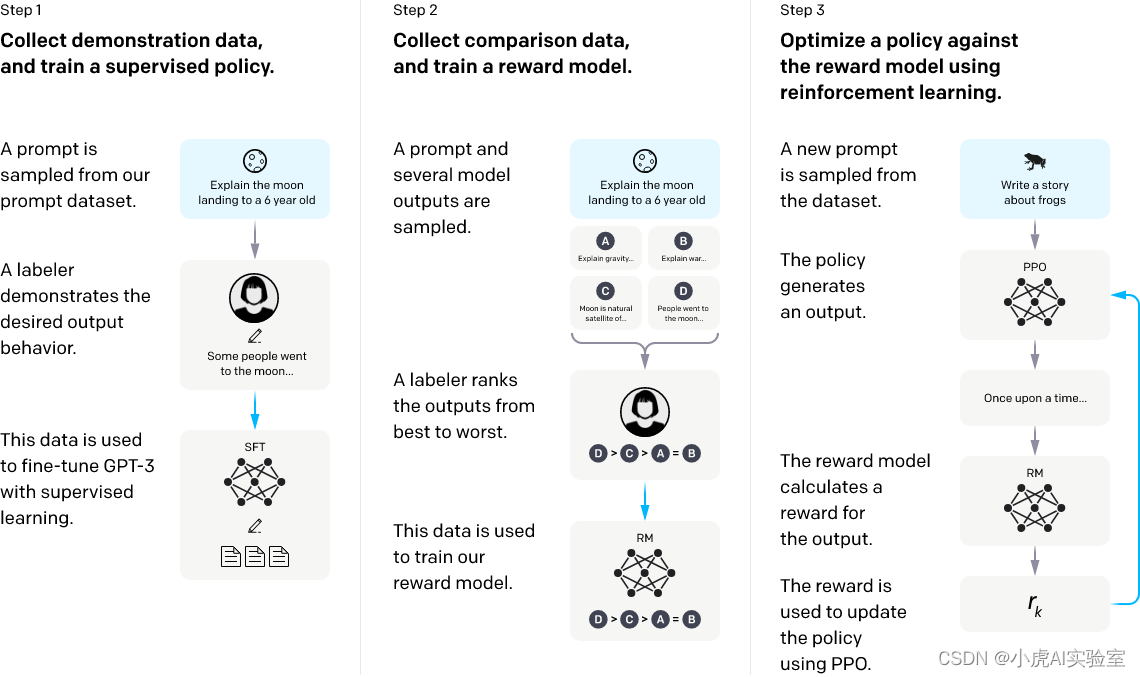
如上图所示,ChatGPT训练过程的三个阶段可以概括如下:
-
采样和微调阶段:训练过程的第一阶段涉及从提示库中采样和收集人类响应。然后,使用InstructGPT工具将这些数据用于微调预训练的大型语言模型,以更好地捕捉人类偏好。
-
采样和训练奖励模型阶段:在第二阶段,使用语言模型生成多个响应,然后根据人类偏好进行手动排名。然后使用这些数据训练适合人类偏好的奖励模型(RM)。
-
强化学习与人类反馈阶段:进一步使用强化学习算法训练大型语言模型,基于第一阶段的监督微调模型和第二阶段的奖励模型。这个阶段是RLHF训练的核心部分,使用强化学习中的Proximal Policy Optimization(PPO)算法引入奖励信号,并生成更符合人类偏好的内容。
接下来我们来详细分析下每个阶段的详细内容。
二、采样和微调阶段
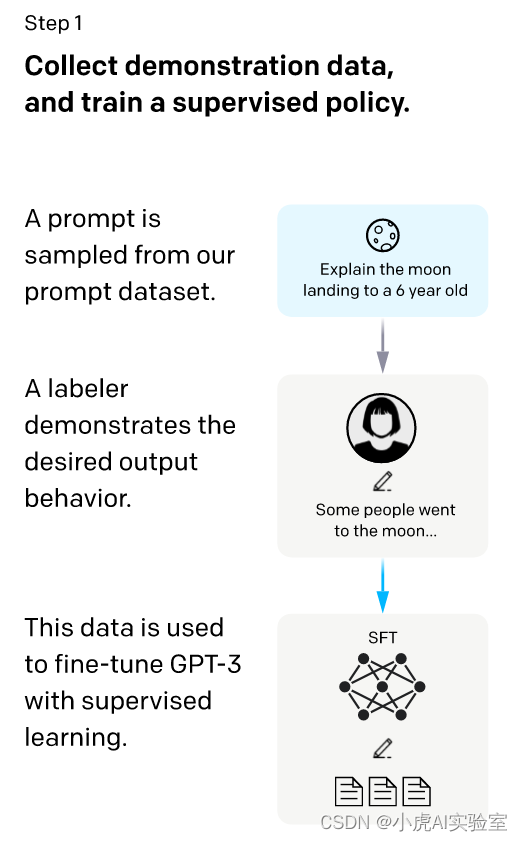
如上图所示,ChatGPT的采样和微调阶段是训练过程的第一阶段,其目的是使用人类响应微调预训练的大型语言模型,以更好地捕捉人类偏好。下面是该阶段的详细过程:
-
提示采样:ChatGPT首先从提示库中随机采样一些与特定主题或任务相关的提示或问题。这些提示可能来自于各种来源,例如问题回答网站、社交媒体平台、新闻文章等等。
-
响应收集:针对每个采样的提示,ChatGPT生成多个响应,并将其存储在一个响应库中。这些响应是由ChatGPT使用预训练的语言模型生成的,因此它们可能与人类的语言和偏好存在差异。
-
人类评估:接下来,ChatGPT需要通过人类评估员对每个响应进行评估,以确定哪些响应更符合人类偏好。这些评估员可能是专业人士、志愿者或从众包平台招募的人群。
-
数据筛选:评估员的评估结果通常会被用作筛选数据的标准。通常会筛选掉低质量或不符合人类偏好的响应,以减少噪声数据对模型的影响。
-
微调模型:ChatGPT使用筛选后的数据对预训练模型进行微调,以更好地适应人类偏好和语言习惯。微调通常采用监督学习算法,例如随机梯度下降(SGD)或自适应动量估计(Adam),以调整模型的参数。微调模型的目的是使模型更加适应任务或提示,并使其生成的响应更加符合人类偏好。
-
重复该过程:ChatGPT将重复这个过程,直到获得足够多的微调数据,并且模型的性能达到预期的水平。采样和微调阶段的输出是一个微调的预训练模型,可以用于下一个阶段的训练。
采样和微调阶段是ChatGPT训练过程中非常重要的一步,它为ChatGPT提供了一个能够更好地适应人类偏好的基础模型。这个阶段需要耗费大量的人力成本和计算资源,但它对于训练一个高质量的语言模型至关重要。通过微调预训练模型,ChatGPT能够更好地捕捉人类偏好和语言习惯,从而生成更符合人类偏好的响应。
三、采样和训练奖励模型阶段
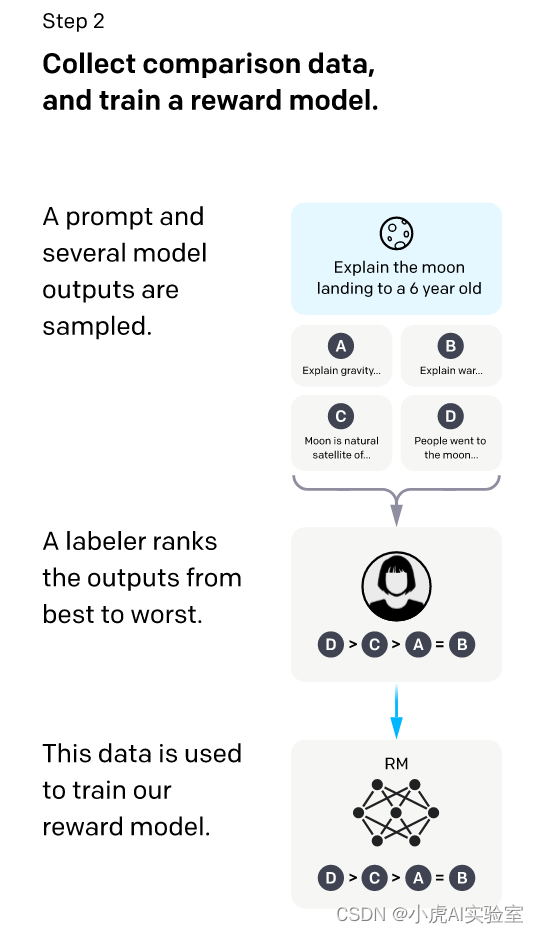
如上图所示,采样和训练奖励模型阶段是ChatGPT训练过程中的第二阶段,其目的是通过奖励模型训练ChatGPT更好地生成符合人类偏好的响应。下面是该阶段的详细过程:
-
提示采样:ChatGPT从一个提示库中随机采样一些与特定主题或任务相关的提示或问题。
-
响应生成:针对每个采样的提示,ChatGPT使用预训练的语言模型生成多个响应,并将其存储在一个响应库中。这些响应可能与人类偏好存在差异。
-
人类评估:接下来,ChatGPT需要通过人类评估员对每个响应进行评估,以确定哪些响应更符合人类偏好。评估员的评估结果通常会被用作奖励信号来训练奖励模型。评估员的数量越多,得出的奖励信号就越准确。
-
数据筛选:根据评估员的排名结果,ChatGPT会筛选掉低质量或不符合人类偏好的响应,以减少噪声数据对模型的影响。
-
奖励模型训练:ChatGPT使用筛选后的响应数据训练一个奖励模型,该模型能够基于人类偏好为每个响应分配一个奖励分数。奖励模型通常使用监督学习算法,例如线性回归或神经网络。训练奖励模型的目的是帮助ChatGPT更好地理解人类偏好,并在生成响应时更好地符合这些偏好。
采样和训练奖励模型阶段是ChatGPT训练过程中的第二步。在这个阶段中,ChatGPT使用人类评估员对生成的响应进行评估,以确定符合人类偏好的响应。这些评估结果用于训练奖励模型,该模型能够帮助ChatGPT更好地了解人类偏好,并在生成响应时更好地符合这些偏好。通过采样和训练奖励模型,ChatGPT能够生成更符合人类偏好的响应。
三、采样和训练奖励模型阶段
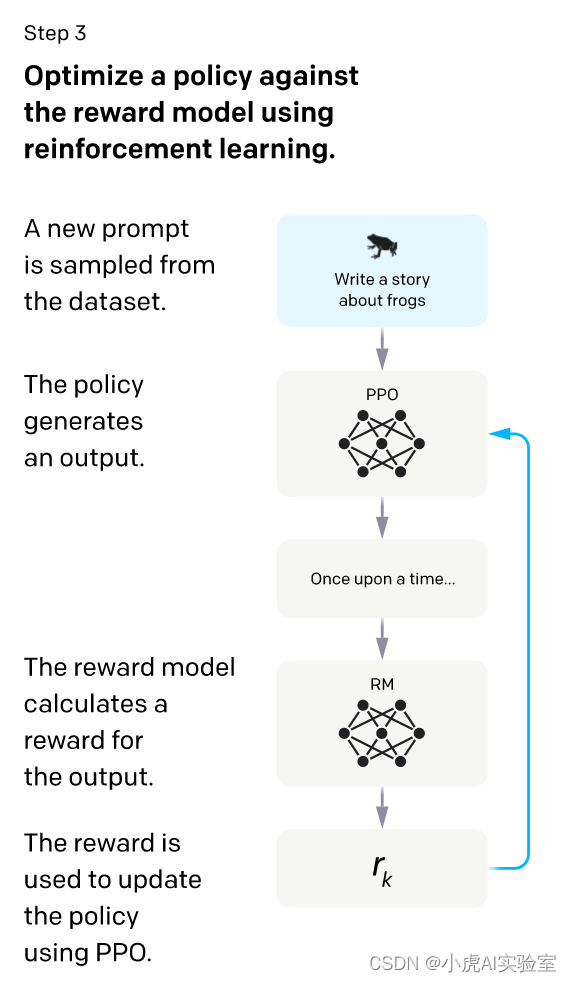
如上图所示,强化学习与人类反馈阶段是ChatGPT训练过程中的核心阶段,其目的是使用强化学习算法和人类反馈训练大型语言模型,使其生成更加符合人类期望的响应。下面是该阶段的详细过程:
-
预训练模型加载:ChatGPT首先加载在前两个阶段中微调的预训练模型,该模型已经可以生成符合人类偏好的响应。
-
生成响应:ChatGPT使用加载的预训练模型生成多个响应,并将这些响应发送给人类评估员进行评估。
-
人类评估:评估员对响应进行评估,并根据评估结果为每个响应分配一个奖励信号。评估员的数量越多,得出的奖励信号就越准确。
-
数据筛选:ChatGPT使用人类评估员的奖励信号对生成的响应进行筛选,以减少噪声数据对模型的影响。
-
强化学习:ChatGPT使用筛选后的响应数据来训练一个强化学习模型,该模型使用Proximal Policy Optimization(PPO)算法来引入奖励信号,并生成更符合人类偏好的内容。
强化学习与人类反馈阶段是ChatGPT训练过程的核心部分。在这个阶段中,ChatGPT使用强化学习算法引入奖励信号,以便更好地生成符合人类偏好的响应。通过使用人类反馈来指导强化学习,ChatGPT能够不断提高生成响应的质量,并且可以根据人类偏好自动调整响应生成的策略。这个阶段的输出是一个训练有素、可以生成更加符合人类期望的响应的ChatGPT模型。这个阶段需要大量的计算资源和人力成本,但它可以让ChatGPT模型更好地适应不同的语言环境,并生成更加符合人类期望的响应。通过强化学习和人类反馈的相互作用,ChatGPT可以不断提高其生成响应的质量和准确性,从而在实现更好的人机交互方面发挥重要作用。
总结
ChatGPT、通过采样、微调、奖励模型训练和强化学习与人类反馈等阶段进行训练,使其能够生成更加符合人类期望的响应。整个训练过程需要大量的计算资源和人力成本,但它能够让ChatGPT生成高质量、符合人类期望的响应,从而在实现更好的人机交互方面发挥重要作用。
由于ChatGPT不再开源,因此在工业界和学术界有大量研究机构及专家学者专注于ChatGPT的开源平替,他们也取得了不少亮眼的进展。
我们的知识星球中,也对此有相关研究,欢迎大家加入!