淘金时代很像
如果你那个时候去加州淘金,一大堆人会死掉,但是卖勺子的人、卖铲子的人永远可以赚钱。所谓的shove and pick business。
大模型是平台型机会。按照我们几天的判断,以模型为先的平台,将比以信息为先的平台体量更大。平台有以下几个特征:
- ① 它是开箱即用;
- ② 要有一个足够简单和好的商业模式,平台是开发者可以活在上面,可以赚足够的钱、养活自己,不然不叫平台;
- ③ 他有自己杀手级应用。ChatGPT本身是个杀手应用,今天平台公司就是你在苹果生态上,你做得再好,只要做大苹果就把你没收了,因为它要用你底层的东西,所以你是平台。平台一般都有它的锚点,有很强的支撑点,长期OpenAI设备机会有很多——有可能这是历史上第一个10万亿美元的公司。
这是一场激烈的竞争平台之战,未来一个体量很大的公司。在这个领域竞争是无比激烈。The price is too big(代价实在太大),错过太可惜。再怎么也得试一试。
拐点 获取信息的边际成本开始变成固定成本。
一定要记住,任何改变社会、改变产业的,永远是结构性改变。这个结构性改变往往是一类大型成本,从边际成本变成固定成本。
举个例子,陆奇在CMU念书开车离开匹茨堡出去,一张地图3美元,获取信息很贵。今天我要地图,还是有价钱,但都变成固定价格。Google平均一年付10亿美元做一张地图,但每个用户要获得地图的信息,基本上代价是0。也就是说,获取信息成本变0的时候,它一定改变了所有产业。这就是过去20年发生的,今天基本是free information everywhere(免费的信息无处不在)。
今天2022-2023年的拐点是 大模型
今天2022-2023年的拐点是什么?它不可阻挡、势不可挡,原因是什么?一模一样。模型的成本从边际走向固定,因为有件事叫大模型。
模型的成本开始从边际走向固定,大模型是技术核心、产业化基础。OpenAI搭好了,发展速度爬升会很快。为什么模型这么重要、这个拐点这么重要,因为模型和人有内在关系。我们每个人都是模型的组合。人有三种模型:
-
认知模型,我们能看、能听、能思考、能规划;
-
任务模型,我们能爬楼梯、搬椅子剥鸡蛋;
-
领域模型,我们有些人是医生,有些人是律师,有些人是码农。
That’s all。我们对社会所有贡献都是这三种模型的组合。每个人不是靠手和腿的力量赚钱,而是靠脑袋活。
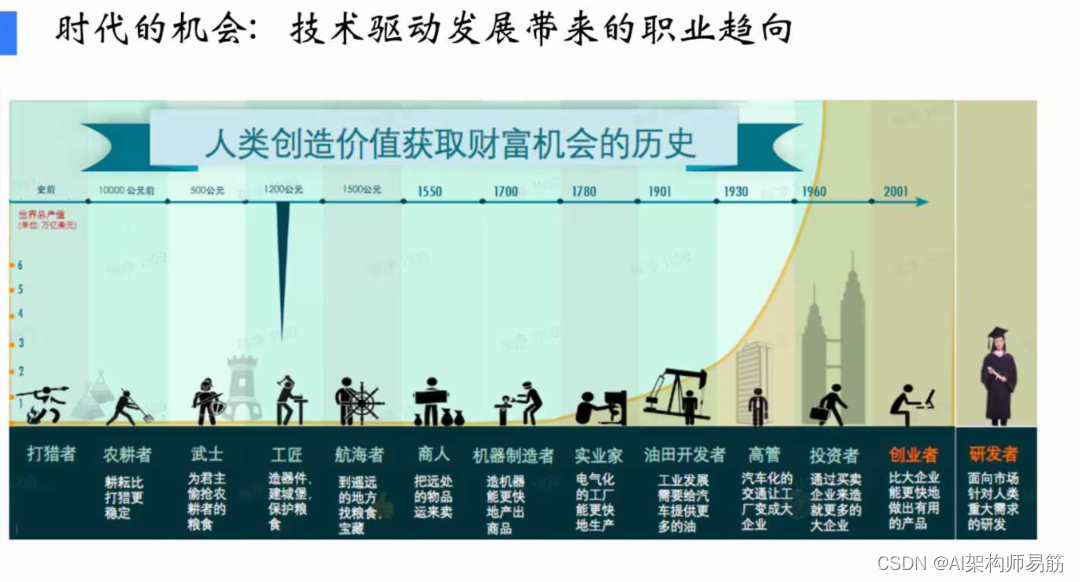
未来,唯一有价值的是你有多大见解
人类社会是技术驱动。从农业时代,人用工具做简单劳动,最大问题是人和土地绑定,人缺少流通性,没有自由。工业发展对人最大变化是人可以动了,可以到城市和工厂。早期工业体系以体力劳动为主、脑力劳动为辅,但随着机械化、电气化、电子化,人的体力劳动下降。信息化时代以后,人以脑力劳动为主,经济从商品经济转向服务经济——码农、设计师、分析师成为我们时代的典型职业。
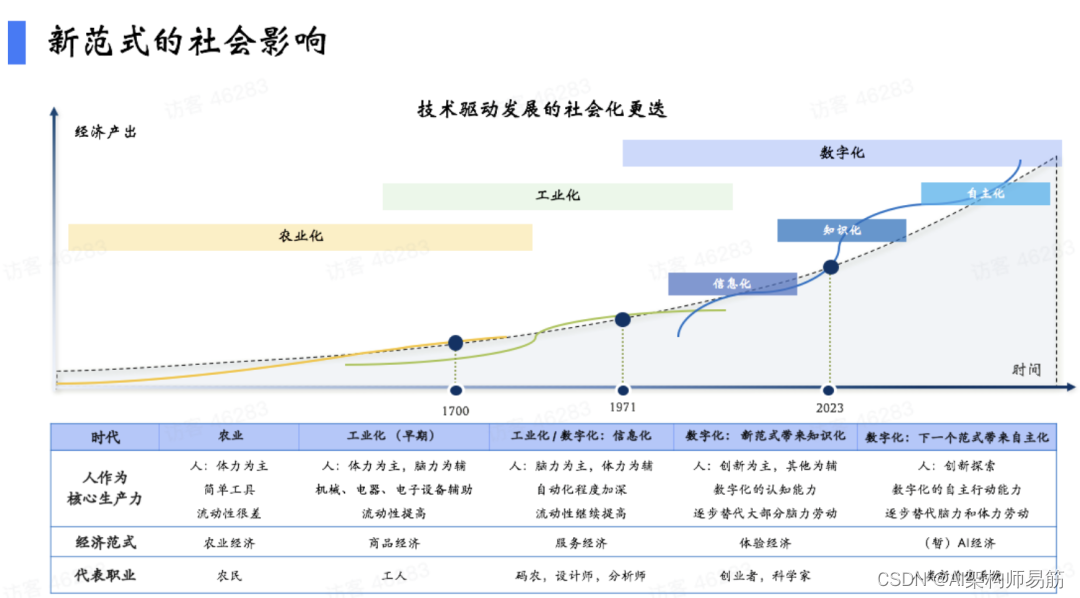
这一次大模型拐点会让所有服务经济中的人、蓝领基本都受影响,因为他们是模型,除非有独到见解,否则你今天所从事的服务大模型都有。下一时代典型的职业,我们认为是创业者和科学家。
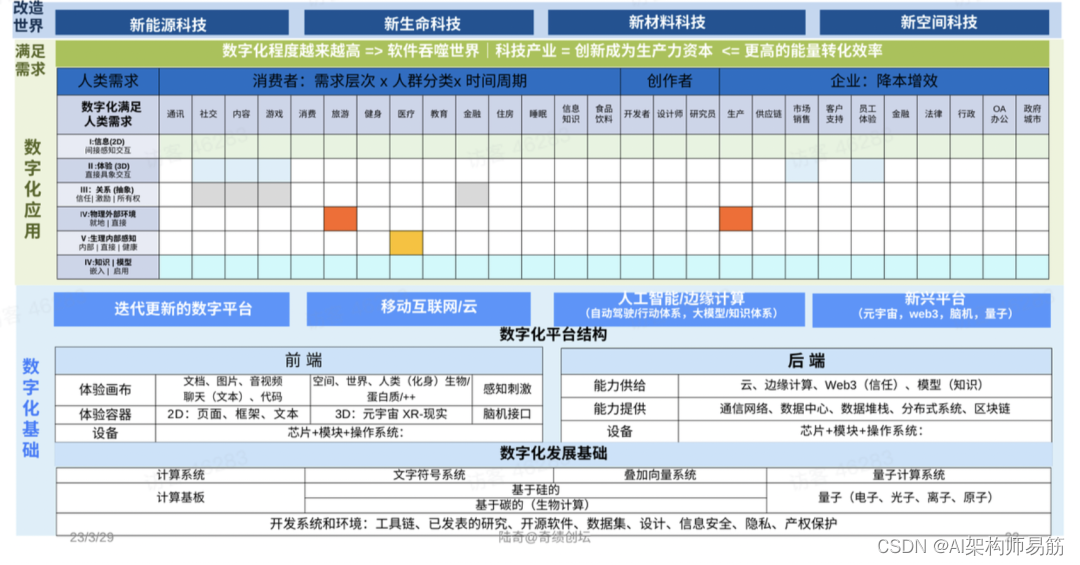
三位一体结构演化模式
本质是讲任何复杂体系,包括一个人、一家公司、一个社会,甚至数字化本身的数字化体系,都是复杂体系。“三位一体”包括:
-
“信息”系统(subsystem of information),从环境当中获得信息;
-
“模型”系统(subsystem of model),对信息做一种表达,进行推理和规划;
-
“行动”系统(subsystem of action),我们最终和环境做交互,达到人类想达到的目的。
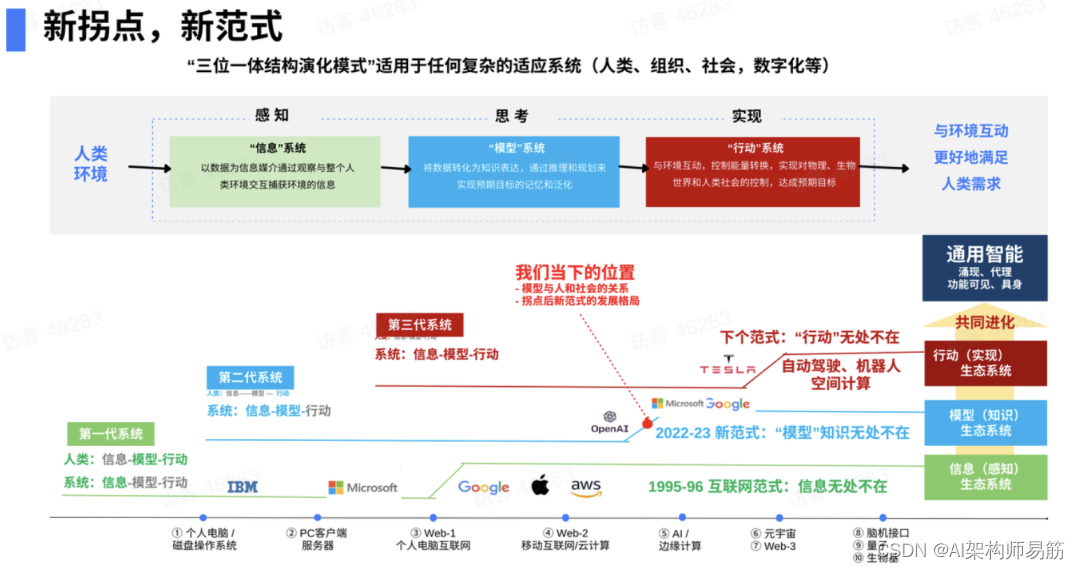
下个拐点是什么?
下个拐点将是组合:“行动”无处不在(自动驾驶、机器人、空间计算)。也就是人需要在物理空间里行动,它的代价也从边际走向固定。20年后,这个房子里所有一切都有机械臂,都有自动化的东西。我需要的任何东西,按个按钮,软件可以动,今天还需要找人。
那么,哪些公司能走到下个拐点、站住下个拐点?我认为特斯拉有很高概率,它的自动驾驶、机器人现在很厉害。微软今天跟着OpenAI爬坡,但怎么站住下个拐点?
三个拐点:
-
① 今天信息已经无处不在了,接下来15-20年,模型就是知识,将无处不在。以后手机上打开,任何联网,模型就过来了。它教你怎么去解答法律问题,怎么去做医学检验。不管什么样的模型都可以无处不在。
-
② 在未来,自动化、自主化的动作可以无处不在。
-
③ 人和数字化的技术共同进化。Sam最近经常讲,它必须要共同进化,才能达到通用智能(AGI)。通用智能四大要素是:涌现(emergence)+代理(agency)+功能可见性(affordence)+具象(embodiment)。
总结来说,我们从根本性的三位一体结构分析未来,从过去的历史拐点能清晰看到今天所面临的拐点,本质是模型成本从边际走向固定,将有一家甚至多家伟大公司诞生。毫无疑问,OpenAI处于领先。
虽然讲得有点早,但我个人认为,OpenAI未来肯定比Google大。只不过是大1倍、5倍还是10倍。
OpenAI
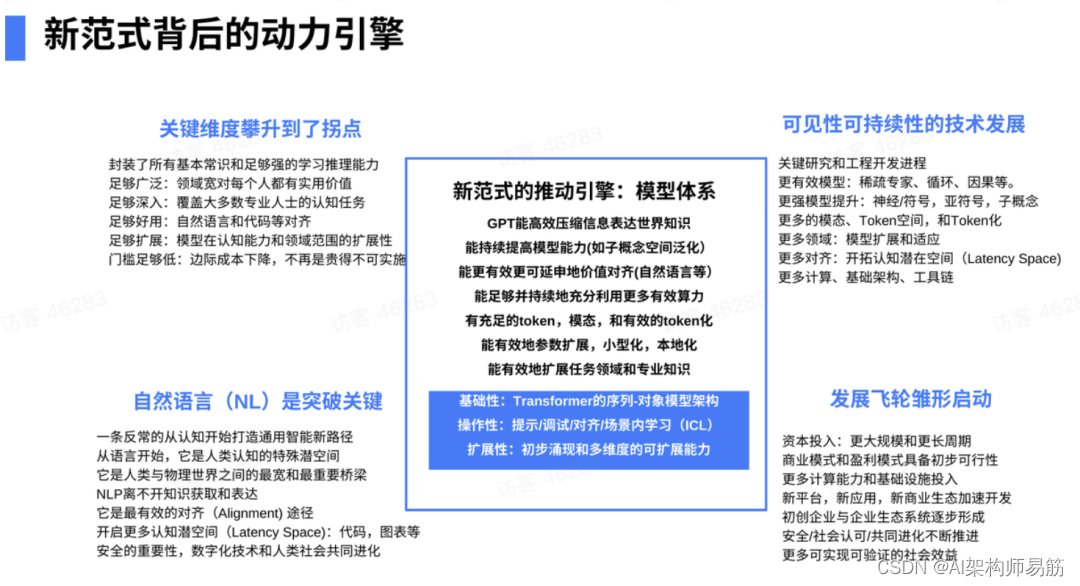
这个引擎基本是一个模型体系(model system),它的核心是模型架构Transformer,就是sequence model(序列模型):sequence in、sequence out、encode、decode后者decode only。但最终的核心是GPT,也就是预训练之后的Transformer,它可以把信息高度压缩。Ilya有个信念:如果你能高效压缩信息,你一定已经得到知识,不然你没法压缩信息。所以,你把信息高效压缩的话,you got to have some knowledge(你得有一些知识)。
Ilya坚信GPT3、3. 5,当然GPT-4更是,它已经有一个世界模型在里面。虽然你做的事是predict next word(预测下一个关键词),这只不过是优化手段,它已经表达了世界的信息,而且它能持续地提高模型能力,尤其是目前研究比较多的在子概念空间当中做泛化。知识图谱真的不行。如果哪个同学做知识图谱,我认真跟你讲,你不要用知识图谱。我自己也做知识图谱20多年,just don’t do that。Just pretty bad。It does not work at all。You should use Transformer。(不要那样做。很糟糕。它根本不起作用。你应该使用Transformer。)
更重要的是用增强学习,加上人的反馈,与人的价值对齐。因为GPT已经做了4年多,知识已经封装在里面了,过去真的是用不起来,也很难用。
最大的是对齐(alignment engineering),尤其是instruction following和自然语言对齐。当然也可以跟代码、表格、图表对齐。
做大模型是很难的,很大难度是infra(基础设施)。我在微软的时候,我们每个服务器都不用网卡,都放了FPGA。网络的IO的带宽速度都是无限带宽技术(Infiniband),服务器和服务器之间是直接访问内存。为什么?因为Transformer是密度模型,它不光是算力问题,对带宽要求极高,你就想GPT-4需要24000张到25000张卡训练,试想世界上多少人能做这种系统。所有数据、data center网络架构都不一样。它不是一个三层的架构,必须是东西向的网络架构。所以这里要做大量的工作。
Token很重要。全世界可能有40-50个确定的token,就是语言的token和模态,现在有更多的token化。当然现在更多的模型的参数小型化、本地化,任务领域的专业知识可以融入这些大模型当中。它的可操纵性主要是靠提示和调试,尤其是根据指令来调,或者对齐来调试,或者in-context learning(上下文学习),这个已经贯彻比较清晰了。它的可操作性是越来越强。可拓展性基本上也足够。
GPT能在历史上第一次两个月1亿活跃用户,挡都挡不住,为什么?
① 它封装了世界上所有知识。
② 它有足够强的学习和推理能力,GPT-3能力在高中生和大学生之间,GPT-4不光是进斯坦福,而且是斯坦福排名很靠前的人。
③ 它的领域足够宽,知识足够深,又足够好用。自然语言最大的突破是好用。扩展性也足够好。当然还是很贵,像2万多张卡,训练几个月这么大的工程。不过也没贵到那么离谱——Google可以做,微软可以做,中国几个大公司能做,创业公司融钱也能做。
加在一起,范式的临界点到了。拐点已经到来。
稍微啰嗦几句。我做自然语言20多年,原来的自然语言处理有14种任务,我能够把动词找出来、名词找出来、句子分析清楚。即使分析清楚,你知道这是形容词,这是动词,这是名词——那这个名词是包香烟?还是你的舅舅?还是一个坟墓?还是个电影?No idea(不知道)。你需要的是知识。自然语言处理没有知识永远没用。
The only way to make natural language work is you have knowledge(让自然语言处理有效的唯一路径是你有知识)。正好Transformer把这么多知识压缩在一起了,这是它的最大突破。
未来是一个模型无处不在的时代
OpenAI未来2-3年要做的——模型更稀疏一点,现在它对带宽要求实在太高,要把attention window拉长一点,或者是recursion causality推理的功能,包括brainstorming等一些工作要做。当然有一些grounding的东西,包括亚符号、子概念的都可以做。更多的模态,更多的token空间,更多的模型稳定性,更多的潜在空间(例如Latent Space对齐),更多的计算,更多的基础架构工具。2-3年基本排满。也就是说,我们大概知道需要什么去把这个引擎继续做大。
对创业者有几点建议
创业公司的内在结构是人和事的组合。人,一开始是创始人/创始团队;他有初心,内在驱动力、外在驱动力;他能独立思考,判断未来;他能行动导向,解决问题;他能需求导向,找到价值;最终通过沟通获得资源。接下来是产品市场匹配,这部分就是研发技术、研发产品、交付产品。商业模式是收到钱、更多增长、触达更多客户、融更多钱、一直触达到未来的价值。组织上,通过系统建设,开拓面向未来的人才、组织结构和文化价值观等等。这一切就是一家公司的总和。

我们对每位同学的建议是,不要轻举妄动,首先要思考。
-
① 不要浮夸,不能蹭热。我个人最反对蹭热,你要做大模型,想好到底做什么,大模型真正是怎么回事,跟你的创业方向在哪个或哪几个维度有本质关系。蹭热是最不好的行为,会浪费机会。
-
② 在这个阶段要勤于学习。新范式有多个维度,有蛮大复杂性,该看到的论文要看,尤其现在发展实在太快,非确定性很大。我的判断都有一定灰度,不能说看得很清楚,但大致是看到是这样的结果。学习花时间,我强烈推荐。
-
③ 想清楚之后要行动导向,要果断、有规划地采取行动。如果这一次变革对你所在的产业带来结构性影响,不进则退。你不往前走没退路的,今天的位置守不住。如果你所在的产业被直接影响到,你只能采取行动。
每个公司是一组能力的组合。
① 产品开发能力方面,如果你的公司以软件为主,毫无疑问一定对你有影响,长期影响大得不得了。尤其是如果你是做C端,用户体验的设计一定有影响,你今天就要认真考虑未来怎么办。
② 如果你的公司是自己研发技术,短期有局部和间接影响,它可以帮助你思考技术的设计。长期核心技术的研发也会受影响。今天芯片的设计是大量的工具,以后大模型一定会影响芯片研发。类似的,蛋白质是蛋白质结构设计。不管你做什么,未来的技术它都影响。短期不直接影响,长期可能有重大影响。
③ 满足需求能力,满足需求基本就要触达用户,供应链或运维一定受影响。软件的运维可以用GPT帮你做,硬件的供应链未必。长期来看有变革机会,因为上下游结构会变。你要判断你在这个产业的结构会不会变。
④ 商业价值的探索、触达用户、融资,这一切它可以帮你思考、迭代。
关于人才和组织。
① 首先讲创始人。今天创始人技术能力强,好像很牛、很重要,未来真的不重要。技术ChatGPT以后都能帮你做。你作为创始人,越来越重要、越来越值钱的是愿力和心力。愿力是对于未来的独到的判断和信念,坚持、有强的韧劲。这是未来的创始人越来越重要的核心素养。
② 对初创团队,工具能帮助探索方向,加速想法的迭代、产品的迭代,甚至资源获取。
③ 对未来人才的培养,一方面学习工具,思考和探索机会,长期适当时候培养自己的prompt engineer(提示工程师)。
④ 最后讲到组织文化建设,要更深入思考,及早做准备,把握时代的机会。尤其是考虑有很多职能已经有副驾驶员,写代码也好,做设计也好,这之间怎么协同?
我们面临这样一个时代的机会。它既是机会,也是挑战。我们建议你就这个机会做全方位思考。
启示:不要做失落的一代
回顾历史,工业革命早期受益者只有瓦特、富尔顿这些2%的人,其他98%只是晚期受益者,而这中间大概有50-70年的过渡期,这一代人在工业革命中是被淘汰的,是没有机会的。
同理,为什么美国会爆发“占领华尔街”事件?因为第三次工业革命之后,失落的一代认为自己是被淘汰的那98%的人,而财富被2%的人拿走了。
但在这背后的另一个事实是,美国1%的人交了国家50%的税。富人的钱不是放到保险柜,而是拿来投资,作为一种社会资源再生产。
差别只在于:谁掌控这些资源、负责这些角色。
大家要深刻理解成为2%的人的必要性,没有一个中间地带!要么成为占领华尔街的人,要么就只能是那98%的人。
工业革命是世界上最大的事件
工业革命之前,无论是东方还是西方,人均GDP都没有本质的变化。但工业革命发生后,人均GDP突飞猛进,纵观整个欧洲,200年间增加了50倍;而在中国,短短40年就增加了50多倍。(1978年大概人均GDP200美金,差点被开除球籍,如今1万多美金。) 因此,古今中外任何王侯将相的功绩和工业革命相比都不值一提。而工业革命的发生,就是科学推动技术,再转化为生产力的结果,这是科技在经济和社会生活中的重要体现。
不仅如此,人的寿命也是一样。
在解放前中国人均寿命39岁,现在我们的生命预期是80岁,在建国70年之内涨了两倍,这是很不得了的一件事。
人类的寿命再往前涨大概一倍是什么时候?基本上要倒退到农耕开始之前,大约几万年前。
几万年人均寿命翻了一番,在短短的70年又翻了一番,这就要感谢工业革命,没有工业革命就没有这一切。
世界文明有各种力量,艺术也是一种力量,那为什么科学和技术这么重要?因为它可以带来一个可叠加式的进步。
什么叫可叠加式进步?今天是1,明天是2,后天是4,再后天是8,这叫可叠加式的进步。
参考
- https://mp.weixin.qq.com/s/_ZvyxRpgIA4L4pqfcQtPTQ
- https://www.sohu.com/a/466624040_121118995
- https://www.sohu.com/a/326413586_124422f
- https://www.sohu.com/a/326413586_124422