Map
map 是一种特殊的数据结构:一种元素对(pair)的无序集合,pair 的一个元素是 key,对应的另一个元素是 value,所以这个结构也称为关联数组或字典。这是一种快速寻找值的理想结构:给定 key,对应的 value 可以迅速定位。
map 这种数据结构在其他编程语言中也称为字典(Python)、hash 和 HashTable 等。
哈希表
哈希,也就是 Map 的实现原理;哈希表是除了数组之外,最常见的数据结构,几乎所有的语言都会有数组和哈希表这两种集合元素,有的语言将数组实现成列表, 有的语言将哈希表称作结构体或者字典,但是它们是两种设计集合元素的思路,数组用于表示元素的序列,而哈希表示的是键值对之间映射关系,只是不同语言的叫法和实现稍微有些不同。
设计原理
哈希表是计算机科学中的最重要数据结构之一,这不仅因为它 O(1) 的读写性能非常优秀,还因为它提供了键值之间的映射。想要实现一个性能优异的哈希表,需要注意两个关键点 —— 哈希函数和冲突解决方法。
哈希函数
实现哈希表的关键点在于如何选择哈希函数,哈希函数的选择在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键能够地映射到不同的索引上,这要求哈希函数输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的结果是不可能实现的。
完美哈希函数如图:

比较实际的方式是让哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题,但是哈希的结果一定要尽可能均匀,结果不均匀的哈希函数会造成更多的冲突并导致更差的读写性能。
不均匀哈希函数如图:

在一个使用结果较为均匀的哈希函数中,哈希的增删改查都需要 O(1) 的时间复杂度,但是非常不均匀的哈希函数会导致所有的操作都会占用最差 O(n) 的复杂度,所以在哈希表中使用好的哈希函数是至关重要的。
冲突解决
哈希函数往往都是不完美的,输出的范围是有限的,所以一定会发生哈希碰撞,这时就需要一些方法来解决哈希碰撞的问题,常见方法的就是开放寻址法和拉链法。
开放寻址法
开放寻址法是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是对数组中的元素依次探测和比较以判断目标键值对是否存在于哈希表中,如果使用开放寻址法来实现哈希表,那么在支撑哈希表的数据结构就是数组,不过因为数组的长度有限,存储 (author, draven) 这个键值对时会从索引开始遍历
当我们向当前哈希表写入新的数据时发生了冲突,就会将键值对写入到下一个不为空的位置
开放地址法写入数据如图:

如上图所示,当 Key3 与已经存入哈希表中的两个键值对 Key1 和 Key2 发生冲突时,Key3 会被写入 Key2 后面的空闲内存中;当我们再去读取 Key3 对应的值时就会先对键进行哈希并取模,这会帮助我们找到 Key1,因为 Key1 与我们期望的键 Key3 不匹配,所以会继续查找后面的元素,直到内存为空或者找到目标元素。
开放地址法读取数据如图:

当需要查找某个键对应的值时,就会从索引的位置开始对数组进行线性探测,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的读写性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找任意元素都需要遍历数组中全部的元素,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过有一些语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成一个可以扩展的『二维数组』:
拉链法写入数据如图:

如上图所示,当我们需要将一个键值对 (Key6, Value6) 写入哈希表时,键值对中的键 Key6 都会先经过一个哈希函数,哈希函数返回的哈希会帮助我们选择一个桶,和开放地址法一样,选择桶的方式就是直接对哈希返回的结果取模
选择了 2 号桶之后就可以遍历当前桶中的链表了,在遍历链表的过程中会遇到以下两种情况:
找到键相同的键值对 —— 更新键对应的值;
没有找到键相同的键值对 —— 在链表的末尾追加新键值对;将键值对写入哈希之后,要通过某个键在其中获取映射的值,就会经历如下的过程:

Key11 展示了一个键在哈希表中不存在的例子,当哈希表发现它命中 4 号桶时,它会依次遍历桶中的链表,然而遍历到链表的末尾也没有找到期望的键,所以哈希表中没有该键对应的值。
在一个性能比较好的哈希表中,每一个桶中都应该有 0-1 个元素,有时会有 2-3 个,很少会超过这个数量,计算哈希、定位桶和遍历链表三个过程是哈希表读写操作的主要开销,使用拉链法实现的哈希也有装载因子这一概念:
装载因子 := 元素数量 / 桶数量
与开放地址法一样,拉链法的装载因子越大,哈希的读写性能就越差,在一般情况下使用拉链法的哈希表装载因子都不会超过 1,当哈希表的装载因子较大时就会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。如果有 1000 个桶的哈希表存储了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比在链表中直接读写好 1000 倍。
Map 底层数据结构
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中使用 hmap 结构体来表示哈希 其实是 hashmap 的缩写,我们先来看一下这个结构体内部的字段:
type hmap struct {
// map中存入元素的个数, golang 中调用 len(map) 的时候直接返回该字段
count int
// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态
flags uint8
// 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组
B uint8
// overflow bucket 的数量的近似数
noverflow uint16
// hash seed (hash 种子) 一般是一个素数
hash0 uint32
// 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nil
buckets unsafe.Pointer
// 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大
oldbuckets unsafe.Pointer
// 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成
nevacuate uintptr
// optional fields
extra *mapextra
}
count 表示当前哈希表中的元素数量;
B 表示当前哈希表持有的 buckets 数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是 len(buckets) == 2^B;
hash0 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;
oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
哈希表的数据结构如图:
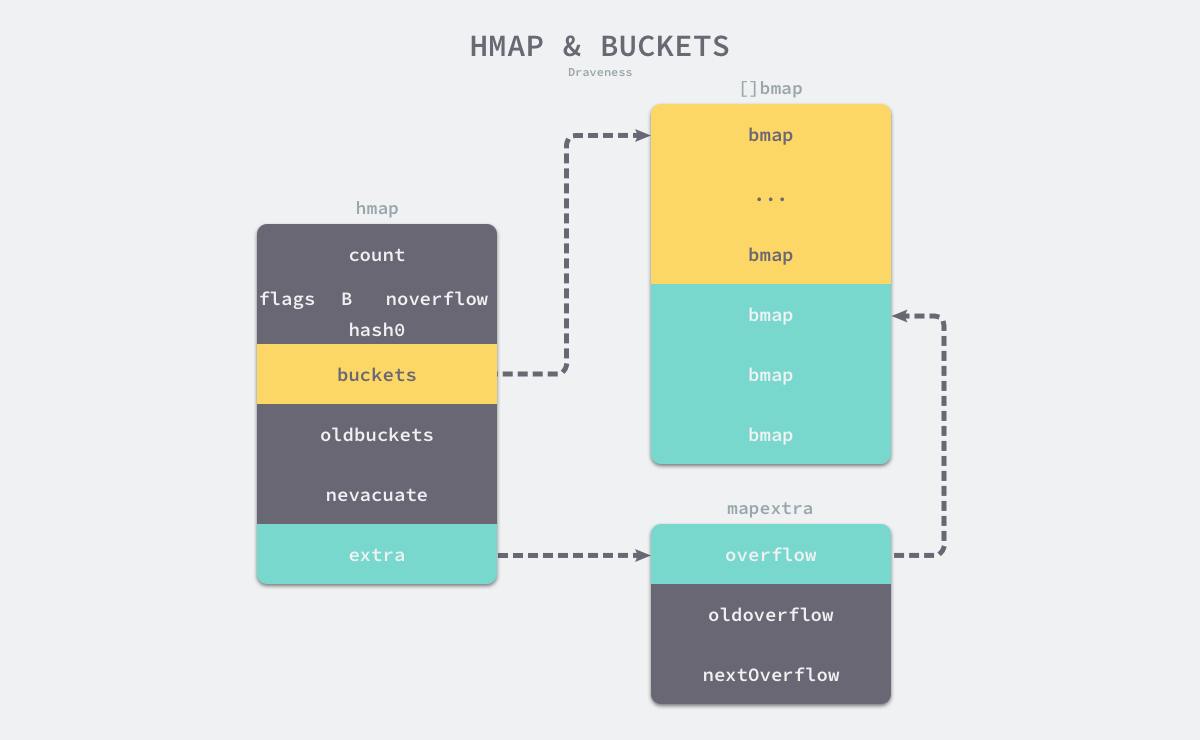
如上图所示哈希表 hmap 的桶就是 bmap,也就是我们常说的"桶"的底层数据结构, 每一个 bmap 都能存储 8 个键值对(key/value),map 使用 hash 函数得到 hash 值决定分配到哪个桶, 然后又根据hash 值的高 8 位来寻找放在桶的那个位置。当哈希表中存储的数据过多,单个桶无法装满时就会使用 extra.overflow 中桶存储溢出的数据。上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为正常桶和溢出桶,上图中黄色的 bmap 就是正常桶,绿色的 bmap 是溢出桶,溢出桶是在 Go 语言还使用 C 语言实现时就使用的设计3,由于它能够减少扩容的频率所以一直使用至今。
这个桶的结构体 bmap 在 Go 语言源代码中的定义只包含一个简单的 tophash 字段,tophash 存储了键的哈希的高 8 位,通过比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能:
type bmap struct {
tophash [bucketCnt]uint8
}
bmap 结构体其实不止包含 tophash 字段,由于哈希表中可能存储不同类型的键值对并且 Go 语言也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导,这些字段在运行时也都是通过计算内存地址的方式直接访问的,所以它的定义中就没有包含这些字段,但是我们能根据编译期间的 cmd/compile/internal/gc.bmap 函数对它的结构重建:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
如果哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
Map 存与取
在 map 中存与取本质上都是在进行一个工作, 那就是:
- 查询当前 k/v 应该存储的位置。
- 赋值/取值, 所以我们理解了 map 中 key 的定位我们就理解了存取。
底层代码
package hexo_blog
import "unsafe"
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// map 为空,或者元素数为0,直接返回未找到
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
// 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 根据hash 函数算出hash值,注意key的类型不同可能使用的hash函数也不同
hash := t.hasher(key, uintptr(h.hash0))
// 如果 B = 5,那么结果用二进制表示就是 11111 ,返回的是B位全1的值
m := bucketMask(h.B)
// 根据hash的后B位,定位在bucket数组中的位置
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 当 h.oldbuckets 非空时,说明 map 发生了扩容
// 这时候,新的 buckets 里可能还没有老的内容
// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 说明之前只有一半的 bucket,需要除 2
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// tophash 取其 8bit 的值
top := tophash(hash)
// 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上
// 遍历当前bucket的所有链式bucket
for ; b != nil; b = b.overflow(t) {
// 在bucket的8个位置上查询
for i := uintptr(0); i < bucketCnt; i++ {
// 如果找到了相等的 tophash,那说明就是这个 bucket 了
if b.tophash[i] != top {
continue
}
// 根据内存结构定位key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
// 校验找到的key是否匹配
if t.key.equal(key, k) {
// 定位v的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v, true
}
}
}
// 所有 bucket 都没有找到,返回零值和 false
return unsafe.Pointer(&zeroVal[0]), false
}
Map 扩容
在 golang 中 map 和 slice 一样都是在初始化时首先申请较小的内存空间, 随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
...
}
runtime.mapassign 函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5(触发增量扩容);
- 哈希使用了太多溢出桶, 桶数量过多(触发等量扩容);不过由于 Go 语言哈希的扩容不是一个原子的过程,所以
runtime.mapassign函数还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
根据触发的条件不同扩容的方式分成两种,增量扩容与等量扩容(重新排列并分配内存)。如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容 sameSizeGrow,sameSizeGrow 是一种特殊情况下发生的扩容,当我们持续向哈希中插入数据并将它们全部删除时,如果哈希表中的数据量没有超过阈值,就会不断积累溢出桶造成缓慢的内存泄漏。runtime: limit the number of map overflow buckets 引入了 sameSizeGrow 通过重用已有的哈希扩容机制,一旦哈希中出现了过多的溢出桶,它就会创建新桶保存数据,垃圾回收会清理老的溢出桶并释放内存5。
参考
Go 语言设计与实现-哈希表
Golang 中 map 探究