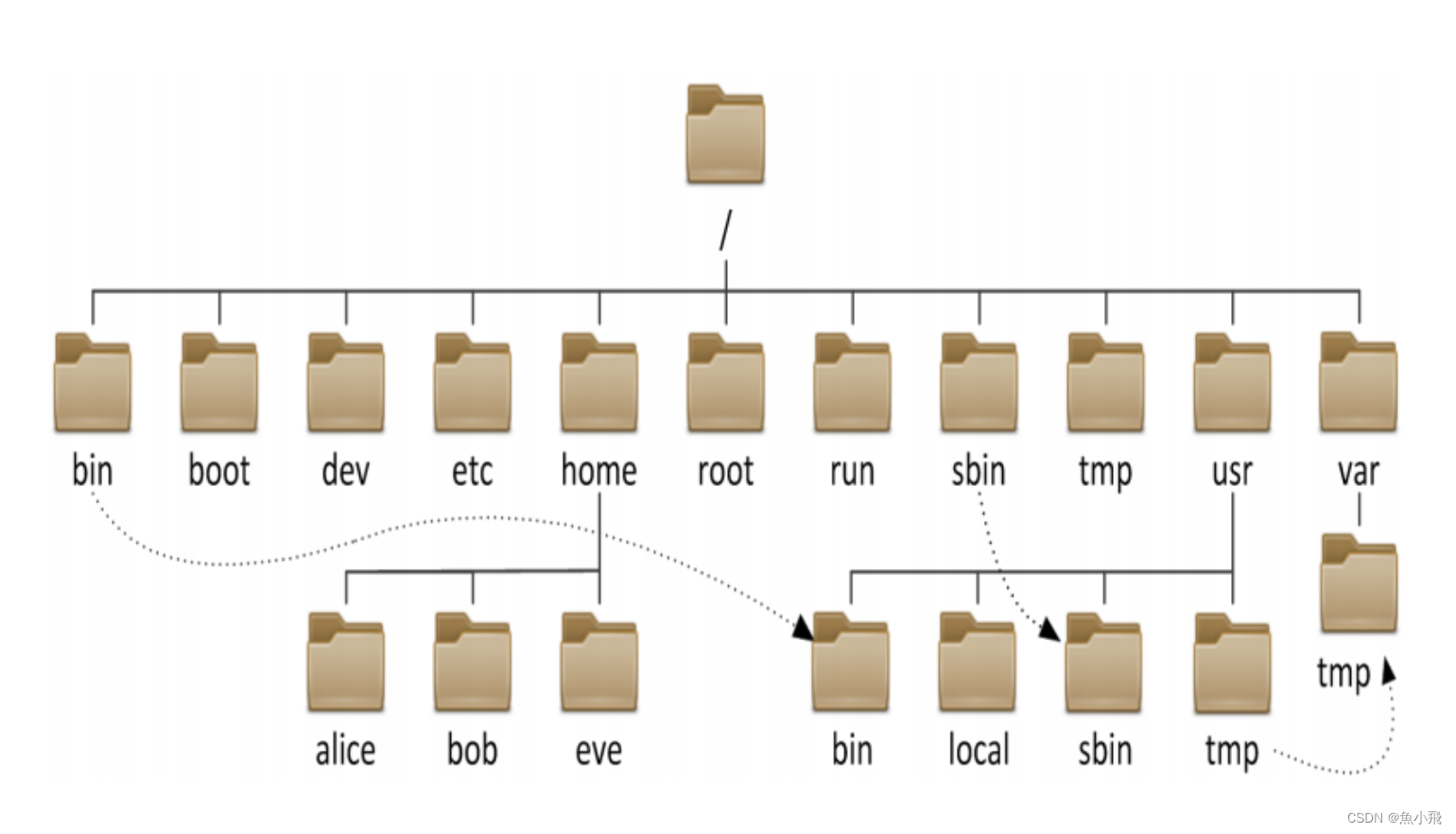
Background
一个raft集群的性能很明显和raft的数量有关系,更重要的是如果我们多个key放在一个raft集群里,这样的并行性不太好。所以我们可以考虑分片,利用操作潜在的并行性来提升性能。每一个副本组只管理几个分片的put和get,并且组之间并行操作;因此总的系统吞吐量(单位时间的put和get)与组的数量成比例增加。这个实验就是对raft group和分片的所在的group做一个协调控制的。
挑战
该lab的一个主要挑战是处理重新配置——在分配分片到组的变化。在单个副本组中,所有的组成员必须在当重新配置关系到客户端的Put/Append/Get请求的时候达成一致。例如,一个Put请求可能与导致副本组停止对保存的Put键的分片负责的重新配置通知到达。组内的所有副本必须就Put是在重新配置之前还是之后发生达成一致。如果是在之前,Put应该生效,分片的新所有者应该看到其效果;如果之后,Put请求不应该生效以及客户端必须在新的所有者处进行重试。建议的方法是去让每个副本组使用Raft去记录Put/Append/Get的顺序以及重新配置的顺序。你将需要确保在任何时候最多只有一个副本组为每一个分片服务。
shard 只对应于一个 raft group。一个raft group可以在备份多个shard
实现
为了保障每个副本看到的配置都一样,我们采用了raft command日志来保障线性一致性,也就是1)对所以副本看到的配置都是一样的,2)而且读能看到最新的写。实际上完全可以仿造lab3来实现
主要map的访问是不确定顺序的,我们可以把这个他按key排序,这样每个副本对map的操作就是都是一样的了。Go中的map是引用的。如果您将一个一个map类型的变量分配给了另一个变量,那么两个变量将引用同一个map。因此,如果希望基于以前的配置创建一个新的Config,你需要创建一个新的map对象(使用make())以及分别复制键值
主要说一下leave和join方法
join:就是加入几个raft组,为了有比较好的扩展性,在join的时候,我们根据shards反向计算出group ----》shards这个map,然后不断的取最大的和最小的组,如果他们之间的差大于1的话,就从最大的组给最小的组一个shard控制权。可以将 shard 分配地十分均匀且产生了几乎最少的迁移任务。
leave:就是移除几个raft组,同样我们要动态挑战shards与group的关系,把一些没有组,也就是被移除raft组的shards,一个一个分配给最小的shards num的raft group来挑战。
func (sm *StateMachine) Join(gid_servers map[int][]string) {
DPrintf("join {%v}", gid_servers)
latest_config := sm.Configs[len(sm.Configs)-1]
new_config := Config{len(sm.Configs), latest_config.Shards, deep_copy(latest_config.Groups)}
for gid, servers := range gid_servers {
if _, ok := new_config.Groups[gid]; !ok {
new_servers := make([]string, len(servers))
copy(new_servers, servers)
new_config.Groups[gid] = new_servers
}
}
g2s := Group2Shards(&new_config)
for {
min_gid, max_gid := GetGIDWithMinNumShards(g2s), GetGIDWithMaxNumShards(g2s)
DPrintf("min_gid{%v} max_gid{%v}", min_gid, max_gid)
if len(g2s[max_gid])-len(g2s[min_gid]) <= 1 {
break
}
g2s[min_gid] = append(g2s[min_gid], g2s[max_gid][0])
g2s[max_gid] = g2s[max_gid][1:]
}
var Shards [NShards]int
for gid, shards := range g2s {
for _, shard := range shards {
DPrintf("shared{%v} -----> gid{%v}", shard, gid)
Shards[shard] = gid
}
}
new_config.Shards = Shards
DPrintf("join group len{%v}", len(new_config.Groups))
sm.Configs = append(sm.Configs, new_config)
}
func (sm *StateMachine) Leave(gids []int) {
DPrintf("leave %v", gids)
config_last_copy := sm.Configs[len(sm.Configs)-1]
newConfig := Config{len(sm.Configs), config_last_copy.Shards, deep_copy(config_last_copy.Groups)}
g2s := Group2Shards(&newConfig)
orphanShards := make([]int, 0)
for _, gid := range gids {
delete(newConfig.Groups, gid)
if shards, ok := g2s[gid]; ok {
orphanShards = append(orphanShards, shards...)
delete(g2s, gid)
}
}
var newShards [NShards]int
if len(newConfig.Groups) != 0 {
for _, shard := range orphanShards {
target := GetGIDWithMinNumShards(g2s)
g2s[target] = append(g2s[target], shard)
}
for gid, shards := range g2s {
for _, shard := range shards {
newShards[shard] = gid
}
}
}
newConfig.Shards = newShards
sm.Configs = append(sm.Configs, newConfig)
}论文关于一个raft集群配置更改部分的讨论(不是实验部分,实验是多个raft集群与shard调节的实现)
一般情况下,可能导致两个leader,因为集群的大多数的定义发生了变化。
可以采用两阶段的方法

同时一个新加入的raft节点要比较长时间才能追赶上leader,为了减低提交的延时,在没有追赶上leader之前没有表决权
删除集群时,被删节点超时,变了candidte, 发出高term的requestvote,将leader变了follower将导致集群频繁不可用

raft bug
map不可比,!=也不行。对于日志条目是否相等的判断,我们不应该加上command,直接根据log的term和index就行了!