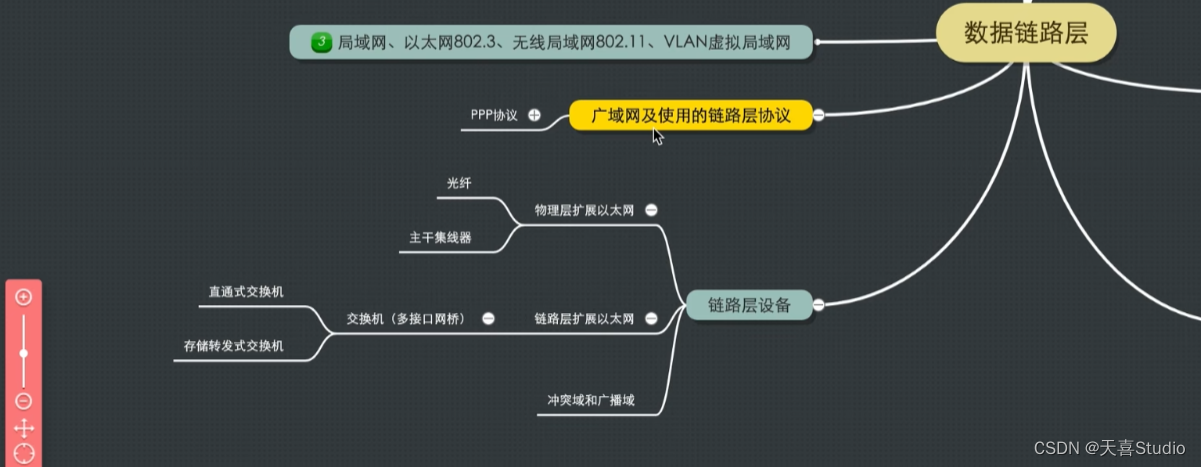
任务4:孪生网络
孪生网络是一种由两个相同结构的神经网络组成的模型,其目的是将两个输入数据映射到一个共同的向量空间中,并计算它们之间的相似度或距离。它通常用于图像匹配、人脸识别、语义匹配等任务中。
步骤1:构建三元组数据集,分别为<图片A,图片A’>和<图片B,图片B’>的组合,此时图片A和A’分别进行不同的数据增强;
步骤2:加载CNN模型,定义二分类损失函数
步骤3:训练孪生网络,记录损失曲线
步骤4:计算query与dataset最相似的图片,提交到实践比赛地址:https://competition.coggle.club/
参考代码:
https://github.com/owruby/siamese_pytorch/blob/master/train.py
思路分析,孪生网络的输入为(A,B),输出为is_different,A、B代表两张图片,is_different是一个布尔变量,如果是1,表示两张图片是不同,如果是0,表示两张图片是相同的,即A、B分别经过不同的线性变换得来。因此是一个二分类问题,用二分类损失。
推理时候,输入dataset中一张图片,query一张图片,输出一个0-1之间的数,就可以认为是孪生网络判断二者的相似性,通过相似性得分输出最后结果。
代码实践细节,如果一张一张图片推理,并行化很慢,可以参考下代码细节如何使用Dataloader提高推理速度
代码细节:
nn.BCELoss()和nn.BCEWithLogitsLoss()都是用来计算二分类问题的损失函数。它们的主要区别在于输入格式不同。
nn.BCELoss()期望模型的输出是经过 Sigmoid 函数后的类别概率,因此它会将这些预测概率作为输入,并与目标标签进行比较,计算二元交叉熵损失。可以使用它来训练快速收敛的二元分类器。
而nn.BCEWithLogitsLoss()则不需要对模型输出进行 Sigmoid 变换,它要求模型直接输出未经过 Sigmoid 的 logits 值。因为这个损失函数内部会自动对 logits 进行 Sigmoid 变换,并相应地计算二元交叉熵损失。nn.BCEWithLogitsLoss()通常在训练神经网络时更加稳定,特别是当输出值非常大或非常小的时候,因为它避免了数值不稳定性和梯度消失等问题。
因此,如果你的模型最后一层已经包含了 Sigmoid 激活函数,那么就应该使用nn.BCELoss();如果没有,则应该使用nn.BCEWithLogitsLoss()。
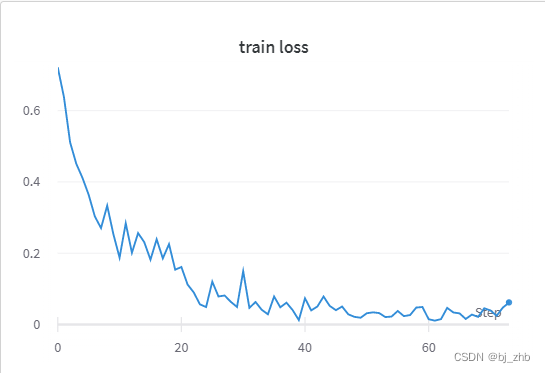
同时,训练代码还启用了分布式训练,也可以作为一个很好的练习,供读者参考
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
import torch.backends.cudnn as cudnn
import torchvision.models as models
from torch.utils.data import Dataset
import glob
import random
import numpy as np
from PIL import Image
import torchvision
import matplotlib.pyplot as plt
import wandb
import torch.distributed as dist
class PairDataset(Dataset):
def __init__(self, path: list, transform) -> None:
super().__init__()
self.data = []
if len(path) == 2:
path1, path2 = path
for p in glob.glob(path1):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
for p in glob.glob(path2):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
else:
for p in glob.glob(path[0]):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
self.transform = transform
def __getitem__(self, index):
x1 = self.data[index]
is_diff = random.randint(0, 1)
if is_diff == 1:
# different
while True:
idx2 = random.randint(0, len(self) - 1)
x2 = self.data[idx2]
if index != idx2:
break
else:
# same
idx2 = index
x2 = self.data[idx2]
x1, x2 = Image.fromarray(x1), Image.fromarray(x2)
# 把x1转换成tensor
base_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((224, 224)),
])
if is_diff == 0:
# same
x1 = base_transform(x1)
x2 = self.transform(x2)
else:
# different
x1 = self.transform(x1)
x2 = self.transform(x2)
return x1, x2, int(is_diff)
def __len__(self):
return len(self.data)
def get_loaders(batch_size, transform, path):
pair_dataset = PairDataset(path=path, transform=transform)
train_data, val_data = torch.utils.data.random_split(pair_dataset,
[int(len(pair_dataset) * 0.8),
len(pair_dataset) - int(
len(pair_dataset) * 0.8)])
#(3)使用 DistributedSampler 对数据集进行划分:
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_data)
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=batch_size,
sampler=train_sampler,
num_workers=4,
drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data,
batch_size=batch_size,
shuffle=False,
num_workers=4,
drop_last=True)
# do not need test loader
return train_sampler, train_loader, val_loader
class Siamese(nn.Module):
def __init__(self):
super(Siamese, self).__init__()
self.model = models.resnet18(pretrained=False)
# remove the last fc layer
self.model = nn.Sequential(*list(self.model.children())[:-1])
self.outfc1 = nn.Linear(512, 16) # convert to 2 classes for classification
self.outfc2 = nn.Linear(16, 1) # convert to 2 classes for classification
self.activation = nn.Sigmoid()
def forward_once(self, x):
return self.model(x)
def forward(self, x1, x2):
o1, o2 = self.forward_once(x1), self.forward_once(x2)
o1, o2 = o1.view(o1.size(0), -1), o2.view(o2.size(0), -1)
out = torch.abs(o1 - o2) # 对称性,两张图片不管谁减去谁都是一样的
out = self.outfc1(out)
out = self.outfc2(out)
out = self.activation(out)
return out
# def contrastive_loss(o1, o2, y):
# # Contrastive Loss
# g, margin = F.pairwise_distance(o1, o2), 5.0
# loss = (1 - y) * (g**2) + y * (torch.clamp(margin - g, min=0)**2)
# return torch.mean(loss)
def main(args):
trans = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
# resize成224*224
torchvision.transforms.Resize((224, 224)),
# torchvision.transforms.RandAugment(),
torchvision.transforms.RandomInvert(0.2),
torchvision.transforms.RandomGrayscale(0.2),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.RandomVerticalFlip(p=0.5),
torchvision.transforms.RandomAutocontrast(),
torchvision.transforms.RandomRotation(10),
torchvision.transforms.RandomAdjustSharpness(0.2),
])
train_sampler, train_loader, val_loader = get_loaders(args.batch_size, trans, args.path)
#(4)使用 DistributedDataParallel 包装模型
model = Siamese().cuda()
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank])
# opt = optim.Adam(model.parameters(), lr=args.lr)
# define SGD optim
opt = optim.Adam(model.parameters(), lr=args.lr, weight_decay=5e-4)
scheduler = optim.lr_scheduler.MultiStepLR(opt,
milestones=[40, 60],
gamma=0.1)
criterion = nn.BCELoss()
cudnn.benckmark = True
if args.local_rank == 0:
print("start training")
print("\t".join(["Epoch", "TrainLoss"]))
best_loss = float('inf')
patience = 10
counter = 0
for epoch in range(args.epochs):
train_sampler.set_epoch(epoch)
model.train()
train_loss, train_num = 0, 0
# record train loss and draw curve
total_loss = []
for n, (x1, x2, y) in enumerate(train_loader):
x1, x2 = x1.cuda(non_blocking=True), x2.cuda(non_blocking=True)
y = y.float().cuda(non_blocking=True).view(y.size(0), 1)
opt.zero_grad()
out = model(x1, x2)
loss = criterion(out, y)
loss.backward()
opt.step()
train_loss = loss.item()
# record train loss
total_loss.append(train_loss)
train_num += y.size(0)
if args.local_rank == 0 and n % 10 == 0:
# print loss for each epoch
print('[%d]\t%.10f' % (epoch + 1, train_loss))
wandb.log({'train loss': train_loss})
scheduler.step()
# 在测试集上验证模型效果
model.eval()
with torch.no_grad():
test_loss = 0.0
for x1,x2,y in val_loader:
x1, x2 = x1.cuda(non_blocking=True), x2.cuda(non_blocking=True)
y = y.float().cuda(non_blocking=True).view(y.size(0), 1)
outputs = model(x1, x2)
loss = criterion(outputs, y)
test_loss += loss.item()
test_loss /= len(val_loader) # 除不除都行
# 判断是否进行 early stop
if test_loss < best_loss:
best_loss = test_loss
counter = 0
else:
counter += 1
if counter >= patience:
print(f'Early stop at epoch {epoch}.')
break
# draw train loss curve
plt.plot(total_loss)
plt.savefig("train_loss-early.png")
# save model
torch.save(model.module.state_dict(), "model-dataset82-ac-nopre.pth")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--batch_size", type=int, default=256)
parser.add_argument("--epochs", type=int, default=80)
parser.add_argument("--lr", type=float, default=0.01)
parser.add_argument("--path", type=list, default=['./dataset/*.jpg'])
#(1)要使用`torch.distributed`,你需要在你的`main.py(也就是你的主py脚本)`
# 中的主函数中加入一个**参数接口:`--local_rank`**
parser.add_argument('--local_rank',
default=-1,
type=int,
help='node rank for distributed training')
args = parser.parse_args()
#(2)使用 init_process_group 设置GPU 之间通信使用的后端和端口:
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
if args.local_rank == 0:
wandb.login(key='808d6ef02f3a9c448c5641c132830eb0c3c83c2a')
wandb.init(project="siamese")
wandb.config.update(args)
main(args)
if args.local_rank == 0:
wandb.run.name = "siamese+resnet18-dataset-ac-sgd0.001"
wandb.finish()
eval.py
import torch
import glob
from PIL import Image
import torchvision
from siamese import Siamese
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
class ImageDataset(Dataset):
def __init__(self, path, transform=None):
super(ImageDataset, self).__init__()
self.path = []
for p in glob.glob(path):
self.path.append(p)
self.transform = transform
def __getitem__(self, index):
img = Image.open(self.path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
def __len__(self):
return len(self.path)
trans = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
# resize成224*224
torchvision.transforms.Resize((224, 224)),
torchvision.transforms.RandomInvert(0.2),
torchvision.transforms.RandomGrayscale(0.2),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.RandomVerticalFlip(p=0.5),
torchvision.transforms.RandomAutocontrast(),
torchvision.transforms.RandomRotation(10),
torchvision.transforms.RandomAdjustSharpness(0.2),
])
query_dataset = ImageDataset(path='./query/*.jpg', transform=trans)
query_dataloader = DataLoader(query_dataset,
batch_size=500,
shuffle=False,
num_workers=8)
match_dataset = ImageDataset(path='./dataset/*.jpg', transform=trans)
match_dataloader = DataLoader(match_dataset,
batch_size=1,
shuffle=False,
num_workers=8)
with torch.no_grad():
# 导入当前文件夹下model.pth文件,多卡训练单卡评估
loaded_dict = torch.load('model-dataset-ac-nopre.pth', map_location='cuda:0')
print('load model successfully')
model = Siamese()
loaded_model = nn.DataParallel(model).cuda()
loaded_model.state_dict = loaded_dict
loaded_model.eval()
query_list = []
match_list = []
for i, query_img in enumerate(query_dataloader):
similarity_list = []
query_img = query_img.cuda()
for match_img in match_dataloader:
# put query_img and dataset_img to GPU
# copy dataset_img to match the shape of query_img
match_img = match_img.repeat(query_img.shape[0], 1, 1, 1)
match_img = match_img.cuda()
# get similarity between query and dataset images
similarity = model(query_img, match_img)
similarity_list.append(similarity)
# print(similarity_list)
# change similarity_list to tensor
similarity_list = torch.stack(similarity_list, dim=1) # torch.Size([query_bs, dataset_len])
# get top 1 index of each query_img
top1_index = torch.argmax(similarity_list, dim=1)
top1_index = top1_index.squeeze().tolist()
# print(top1_index.shape) # torch.Size([query_bs])
# get most similar image name
# print(top1_index)
match_name = [match_dataset.path[k] for k in top1_index]
# get all query_img name of current batch
query_step = query_img.shape[0] * i
query_name = [query_dataset.path[k] for k in range(query_step, query_step + query_img.shape[0])]
# save current query_img name and most similar image name, only keep file name
query_name = [q.split('/')[-1] for q in query_name]
match_name = [m.split('/')[-1] for m in match_name]
query_list.extend(query_name)
match_list.extend(match_name)
# print('query_list:', query_list)
# print('match_list:', match_list)
print('Writing results to csv file...')
# 保存结果到csv文件,第一行source,query,后面每行对应match_list中的图片名,query_list中的图片名
with open('./submit/siamese-dataset-noval.csv', 'w') as f:
f.write('source,query\n')
for i in range(len(query_list)):
f.write(match_list[i] + ',' + query_list[i] + '\n')
debug.py(单卡验证)
import torchvision
import torch
import matplotlib.pyplot as plt
import numpy as np
import glob
import random
from PIL import Image
from torch.utils.data.dataset import Dataset
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
class PairDataset(Dataset):
def __init__(self, path: list, transform) -> None:
super().__init__()
self.data = []
if len(path) == 2:
path1, path2 = path
for p in glob.glob(path1):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
for p in glob.glob(path2):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
else:
for p in glob.glob(path[0]):
raw_img = Image.open(p).convert('RGB')
img = np.array(raw_img)
self.data.append(img)
self.transform = transform
def __getitem__(self, index):
x1 = self.data[index]
is_diff = random.randint(0, 1)
if is_diff == 1:
# different
while True:
idx2 = random.randint(0, len(self) - 1)
x2 = self.data[idx2]
if index != idx2:
break
else:
# same
idx2 = index
x2 = self.data[idx2]
x1, x2 = Image.fromarray(x1), Image.fromarray(x2)
# 把x1转换成tensor
base_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((224, 224)),
])
if is_diff == 0:
# same
x1 = base_transform(x1)
x2 = self.transform(x2)
else:
# different
x1 = self.transform(x1)
x2 = self.transform(x2)
return x1, x2, int(is_diff)
def __len__(self):
return len(self.data)
def get_loaders(batch_size, transform, path):
pair_dataset = PairDataset(path=path, transform=transform)
train_loader = torch.utils.data.DataLoader(pair_dataset,
batch_size=batch_size,
num_workers=4,
drop_last=True)
# do not need test loader
return train_loader
# Showing images
def imshow(img, text=None):
npimg = img.numpy()
plt.axis("off")
if text:
plt.text(75, 8, text, style='italic',fontweight='bold',
bbox={'facecolor':'white', 'alpha':0.8, 'pad':10})
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
plt.savefig('test.png')
trans = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
# resize成224*224
torchvision.transforms.Resize((224, 224)),
# torchvision.transforms.RandAugment(),
torchvision.transforms.RandomInvert(0.2),
torchvision.transforms.RandomGrayscale(0.2),
torchvision.transforms.RandomHorizontalFlip(p=0.2),
torchvision.transforms.RandomVerticalFlip(p=0.2),
torchvision.transforms.RandomAutocontrast(),
torchvision.transforms.RandomRotation(10),
torchvision.transforms.RandomAdjustSharpness(0.2),
])
train_loader = get_loaders(2, trans, ['./dataset/*.jpg'])
example_batch = next(iter(train_loader))
concatenated = torch.cat((example_batch[0], example_batch[1]),0)
imshow(torchvision.utils.make_grid(concatenated))
print(example_batch[2].numpy().reshape(-1))
# 查看train_loader的长度
print(len(train_loader))
class Siamese(nn.Module):
def __init__(self):
super(Siamese, self).__init__()
self.model = models.resnet18(pretrained=True)
# remove the last fc layer
self.model = nn.Sequential(*list(self.model.children())[:-1])
self.outfc1 = nn.Linear(512, 16) # convert to 2 classes for classification
self.outfc2 = nn.Linear(16, 1) # convert to 2 classes for classification
self.activation = nn.Sigmoid()
def forward_once(self, x):
return self.model(x)
def forward(self, x1, x2):
o1, o2 = self.forward_once(x1), self.forward_once(x2)
o1, o2 = o1.view(o1.size(0), -1), o2.view(o2.size(0), -1)
out = torch.abs(o1 - o2) # 对称性,两张图片不管谁减去谁都是一样的
out = self.outfc1(out)
out = self.outfc2(out)
out = self.activation(out)
return out