人脸检测与识别综述
人脸检测与识别是计算机视觉和生物识别领域中最受关注的研究内容。
如何从包含人脸内容的图像、视频等多媒体数据中,找到人脸,并对其身份进行判定,是人脸检测与识别中的主要问题。
应用场景
- 安全监控
- 访问控制
- 数据挖掘
如何将人脸识别与检测技术应用于新的场景,是具有应用创新的工作。
基本流程
总体上,人脸检测与识别包含如下几个关键技术步骤:
1. 人脸检测
利用目标检测算法,从视频或者图像中检测出所有人脸区域。
2. 人脸对齐
将检测到的人脸区域进行对齐,使他们具有相同的尺度、姿态和位置

3. 特征提取
从检测得到的特征中提取出特征向量,作为人脸的唯一特征
4. 特征检索
将特征与数据库中的特征进行比较,找到最佳匹配
主要挑战
人脸检测与识别在实际应用中,不同的场景具有不同的挑战。
例如,监控场景下的大规模人群中检测出人脸小目标,是目前学术界主要关心的核心问题之一。

在人脸识别中,一些长期存在的、经典的挑战包括
- 头部姿态
- 年龄、妆容的变换
- 光影的变化
- 表情的变换
- 遮挡

人脸检测与识别的主要数据集
人脸检测

[链接1](http://host.robots.ox.ac.uk/pascal/VOC/databases.html) |
[链接2](http://shuoyang1213.me/WIDERFACE/) |
[链接3](http://vis-www.cs.umass.edu/fddb/) |
人脸识别

[链接1](https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) |
[链接2](http://vis-www.cs.umass.edu/lfw/) |
目标
1. 了解人脸检测与识别的基本目标,常规流程,以及数学定义
2. 掌握人脸检测的基本算法和处理方法,理解每个步骤的意义所在
3. 了解较新的人脸检测与识别算法的基本思路
人脸检测--传统方法1
非深度学习方法
基本思路
从一张图像中找到人脸目标,需要找寻人脸的特点。
方法1:模板匹配
一种浅显且直白的方式,就是利用模板匹配算法来实现,如下图所示

显然,这种方法不够好。无法通用的检索出“人脸”这个概念。
由于人脸缺少一些模式化的特征,不具备特殊的纹理、形状等规律,因此很难利用初等图像处理的方法来得到普世的结果。
**肤色检测** 而通过肤色划分出人脸区域,通常是较为常见的一种做法。
除此之外,将图像分成小块,并对每个小块进行特征提取,通过机器学习的方式,也可以实现人脸检测。
需要注意的是,传统方法由于缺少特征的鲁棒性,无法获取高维特征表述,因此鲁棒性不够
可以考虑不同方法的叠加进行实现。
方法二:肤色检测
import numpy as np
import cv2
import matplotlib.pyplot as plt
img1 = cv2.imread("../../dataset/d1.png")
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
plt.imshow(img2)
img_HSV = cv2.cvtColor(img1, cv2.COLOR_BGR2HSV)
HSV_mask = cv2.inRange(img_HSV, (0, 60, 60), (20,255,255))
HSV_mask = cv2.morphologyEx(HSV_mask, cv2.MORPH_OPEN, np.ones((3,3), np.uint8))
plt.imshow(HSV_mask) 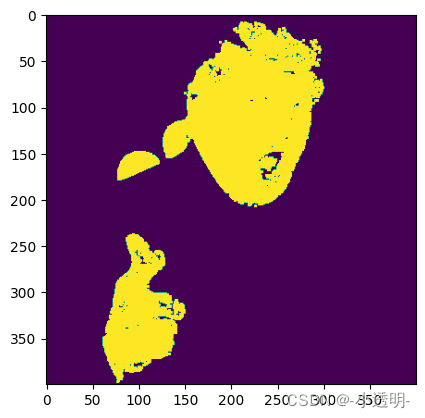
img_YCrCb = cv2.cvtColor(img1, cv2.COLOR_BGR2YCrCb)
YCrCb_mask = cv2.inRange(img_YCrCb, (80, 135, 85), (255,255,255))
YCrCb_mask[np.abs(img_YCrCb[:, :, 1] - img_YCrCb[:, :, 2])<15] = 0
YCrCb_mask = cv2.morphologyEx(YCrCb_mask, cv2.MORPH_OPEN, np.ones((3,3), np.uint8))
plt.imshow(YCrCb_mask) 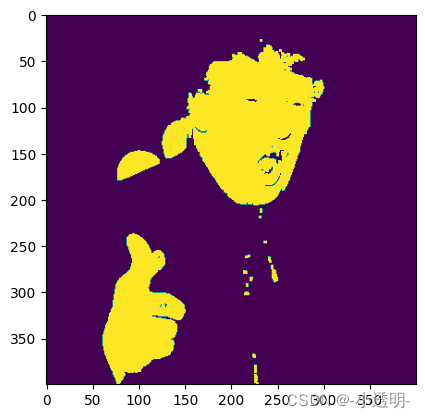
final_mask=cv2.bitwise_and(YCrCb_mask,HSV_mask)
final_mask=cv2.medianBlur(final_mask,3)
final_mask = cv2.morphologyEx(final_mask, cv2.MORPH_OPEN, np.ones((4,4), np.uint8))
plt.imshow(final_mask)
img2[final_mask == 0] = 0
plt.imshow(img2)
同hsv一样,ycrcb格式也是一种颜色空间。
其中,Y表示亮度,Cr和Cb表示色度信息。
常用于肤色检测。(因为肤色载这一空间更加集中)
通常,肤色检测中,采用的阈值为
Y>80, Cr>135, Cb>85, 且|Cr-Cb|>15

需要注意的是,颜色分割只能作为识别的辅助进行。因为其非常容易收到光照和肤色的影响。
方法3:手工特征+分类器
img_a = cv2.imread("../../dataset/d1.png")
img_b = cv2.imread("../../dataset/d2.jpg")
sift = cv2.SIFT_create()
plt.subplot(1,2,1)
plt.imshow(cv2.cvtColor(img_a, cv2.COLOR_BGR2RGB))
plt.subplot(1,2,2)
plt.imshow(cv2.cvtColor(img_b, cv2.COLOR_BGR2RGB))
人脸的另一个规律在于,五官之间存在一定的模式
这种模式很难拿自然语言完整的描述出来,大致上,人脸图像应当符合这样的内容
如 :
- 眼睛区域暗于脸颊区域
- 嘴部区域暗于周围区域等
那么本质上,我们只需要**总结出脸部区域的明暗变化**,那么在待检测区域中发现了类似的模式,则可以认为是一个人脸。
那么如何总结出人脸模式呢?
机器学习
这里涉及两个部分:
1. 特征提取
2. 分类器训练
特征提取:HOG特征
hog, higtogram of oriented gradient, 是抓取图像轮廓的算法。
具体上,将一张图像切成很多个区域,并从每个区域中提取出方向梯度,作为特征。
其基本步骤包括:
1. 图像预处理: 灰度化、归一化、平滑等
2. 计算梯度: 用sobel计算梯度的赋值和方向
3. 分割图像:将图像切割成大小相同的cell。并构建直方图
4. 块归一化:将每个patch中的图直方图进行归一化,消除光影影响
5. 将所有直方图组合成一个特征向量
# 块大小
patch_size = 8
# 直方图数量
nbins = 9
img = cv2.imread('../../dataset/d2.jpg', 0)
plt.imshow(img, cmap='gray')
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=1)
mag, ang = cv2.cartToPolar(gx, gy)
plt.imshow(mag, cmap='gray')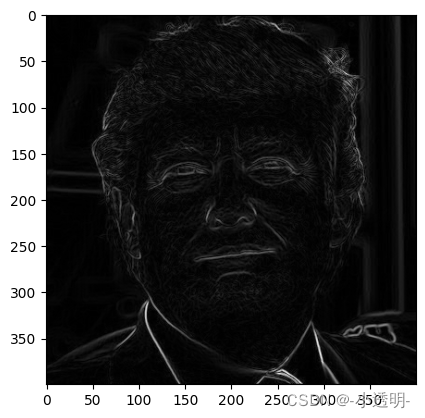
ph = patch_size
pw = patch_size
h, w = img.shape
n_h = h // ph
n_w = w // pw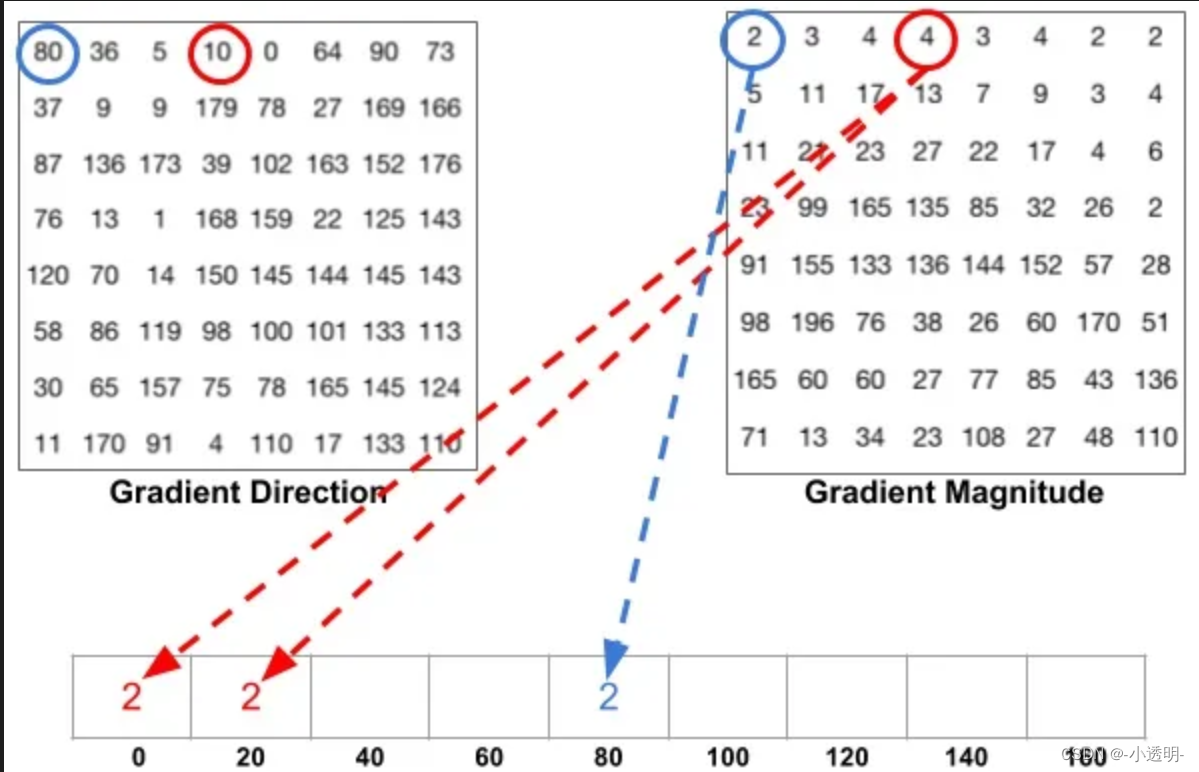
bin_width = 360 // nbins
bins = np.zeros((mag.shape[0], mag.shape[1], nbins))
for i in range(nbins):
angle_bin = ang < (i + 1) * bin_width
angle_bin = angle_bin.astype(np.float32)
bins[:, :, i] = mag * angle_bin
feature_vectors = np.zeros([img.shape[0] // patch_size, img.shape[1] // patch_size, nbins])
for iidx, i in enumerate(range(0, img.shape[0] - patch_size + 1, patch_size)):
for jidx, j in enumerate(range(0, img.shape[1] - patch_size + 1, patch_size)):
cell_bins = bins[i:i+patch_size, j:j+patch_size, :]
cell_hist = np.sum(cell_bins, axis=(0, 1))
feature_vectors[iidx, jidx, :] = cell_hist
归一化,就是将临近四个patch放到一起进行归一化
归一化的目的在于去除阴影和光照的影响,尽可能地令光照统一。
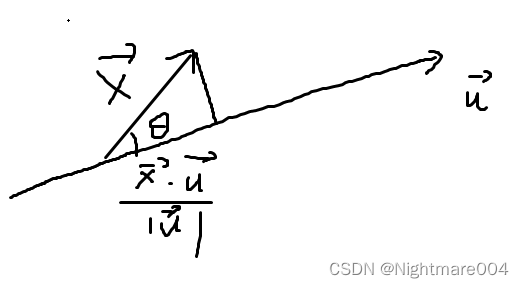
归一化的方法包括采用l2,l1等,如以下公式所示
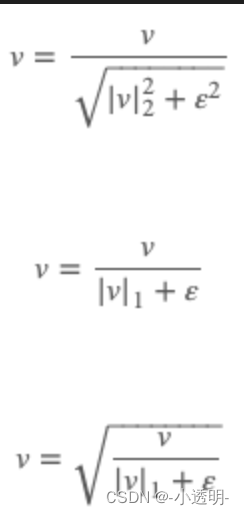
block_size = 2
block_size_cells = (block_size, block_size)
feature_vectors = np.array(feature_vectors)
eps = 1e-7
for i in range(0, feature_vectors.shape[0] - block_size + 1, block_size):
for j in range(0, feature_vectors.shape[1] - block_size + 1, block_size):
block = feature_vectors[i:i+block_size, j:j+block_size, :]
block_sum = np.sum(block)
block_norm = block / (block_sum + eps)
feature_vectors[i:i+block_size, j:j+block_size, :] = block_norm
features = feature_vectors.reshape(-1)
print(features.shape)以上,就是hog特征的底层提取方法。
opencv也为提取hog特征提供了接口,具体实现如下所示
hog = cv2.HOGDescriptor()
features = hog.compute(img)
print(features.shape)需要注意的是,实际上我们采用滑动窗口的方式来检测人脸。
固定窗口尺寸为50\*50,然后为每个patch提取特征
然后,对提取的特征进行分类器分类。
分类器
支持向量机SVM,在特征空间上找到一个超平面将不同类别分开。
sklearn库中提供了相关的接口实现
hog = cv2.HOGDescriptor()
features = hog.compute(img)
print(features.shape)
# 训练过程
```
grad = GridSearchCV(LinearSVC(dual=False), {'C': [1.0, 2.0, 4.0, 8.0]}, cv=3)
grad.fit(X_train, y_train)
print(grad.best_score_)
print(grad.best_params_)
model = grad.best_estimator_
model.fit(X_train, y_train)
```
# 测试过程
```
labels = model.predict(patches_hog)
```人脸检测的传统方法2
传统方法对比深度学习的一个主要弱势在于特征不够泛化,不能描述抽象的概念。
对于这样的特征,就需要更好的分类器,或者更加复杂的分类器。
在前深度学习时代,提高分类器性能的一个主要手段在于**集成**。(深度学习时代也是,kaggle中有大量的高分项目都采用了集成策略。)
集成学习
集成算法,是指将一组不同的分类器整合起来,相互配合地对目标进行预测。
其中所涉及的一个主要内容就是
结合策略
1. 平均法
把若干个学习器的输出进行加权平均,得到最终结果的输出。
其中,权重设置为可学习,就能得到更加鲁棒的学习器。
2. 投票法
少数服从多数的策略。
包括:多数投票法,或者加权投票法等。
同理,也可以设置可学习的分类器权重。
3. stacking
将一部分的分类器的输出,作为另一部分学习器的输入,构建次级模型来提高模型性能。
例如,将一组20个svm的分类器的十分类预测结果组合到一起,输入一个可以接受200维输入的分类器中,进一步预测10分类结果。
Boosting算法
强学习:分类精度比较高的分类器
弱学习:分类精度比随机分类高一点的分类器
通过集成了多个弱学习分类器,通过非随机的组合,得到一个强分类器。
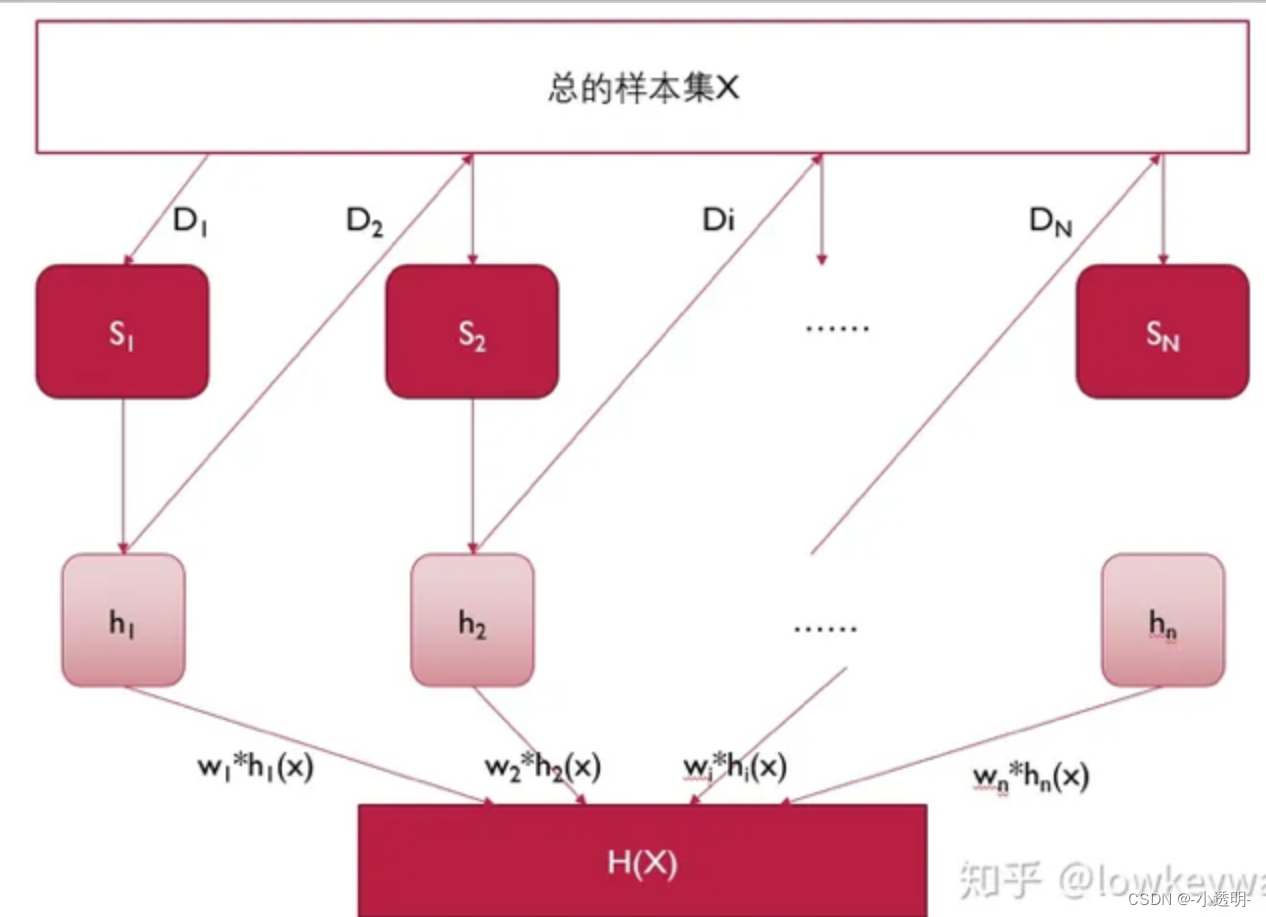 adaboost模型
adaboost模型
adaboost模型是一种boosting算法

更新权重

最终,采用加权平均法,得到最终的分类器如下

总结:adaboost采用了较低的成本,得到了一个性能与SVM差不多的分类器。
其特点在于,对于难分样本,具有很好的效果。且不容易过拟合。
但是对于噪声和扰动较为敏感。
Haar特征
Haar是一种用模板来描述图像变化的工具,所得到的结果可以作为图像特征。
根据目标不同,设计了多种不同的模板。

这些特征,实际上就是卷积神经网络的灵感源泉之一。
在实际运算中,haar特征的精度并不高。但结合积分图,可以快速计算图像特征。
具体计算方法是,白色区域的和 减去 黑色区域的和.
本质上,白色区域的值为1,黑色区域的值为0。
如何利用haar特征进行较好的目标检测?
adaboost的级联算法
首先,用提取的haar特征,训练一个adaboost分类器。
分类器会给出一个决策值,如果这个值大于设定的阈值,则认为是人脸,如果小于,则认为不是人脸。
然而,阈值的设定非常难,且不鲁棒。
那么之所以可能会分错,可能是因为特征不够泛化。
所以,我们重新设置haar的参数,来获得不同的特征表达。
并且用这种特征,训练一个新的分类器。
两种分类器之间,采用级联方式链接
如果A分类器能够确定他是一个目标,则认为是一个目标
如果不能确定是一个目标,则会把他交给B分类器继续判断。
依次类推,直到最后的分类器也不能确定他是一个目标,则不是目标。
同理,上述过程可以反过来,如果有一级分类器判断他不是,则他就不是目标;直到最后一级分类器也认定是一个人脸,则才是一个人脸。
以上过程就是经典的机器学习理论之一:决策树
决策树集成
一个决策树可能并不鲁棒。
我们将数据集划分成若干个重叠的部分,分别训练若干个决策树,并用加权集成的方式,来得到最终的结果。
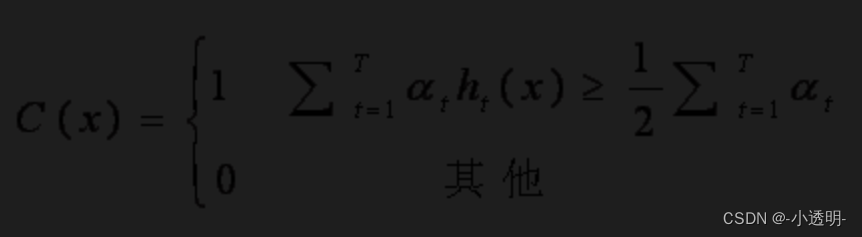
训练与推理
级联分类器的训练过程,可采用opencv提供的工具来实现。
具体可见该链接
[级联分类器的训练-英](https://docs.opencv.org/4.2.0/dc/d88/tutorial_traincascade.html)
[级联分类器的训练-中](https://zhuanlan.zhihu.com/p/407571417)
具体上,要使用到`opencv_traincascade.exe`训练准备好的数据。
不过,也可以使用opencv提供的事先训练好的模型直接进行推理。具体链接为[训练好的各种级联模型](https://github.com/opencv/opencv/tree/master/data/haarcascades)以训练好的模型为例,一个haar级联分类器的人脸检测代码实现如下
import cv2
import matplotlib.pyplot as plt
face_detector = cv2.CascadeClassifier('../../dataset/haarcascade_frontalface_default.xml')
img = cv2.imread('../../dataset/lena.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray,1.1, 4 )
for (x,y, w, h) in faces:
cv2.rectangle(img, pt1 = (x,y),pt2 = (x+w, y+h), color = (255,0,0),thickness = 3)
roi_gray = gray[y:y+h,x:x+w]
roi_color = img[y:y+h, x:x+w]
plt.imshow(img)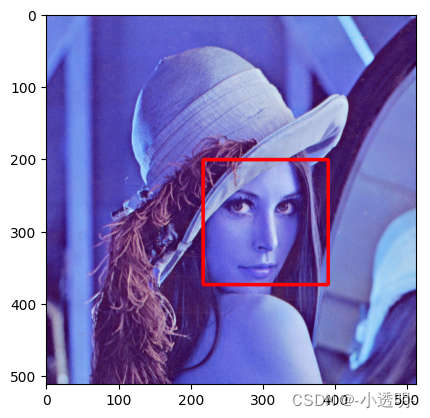
其他的方法与思路
前深度学习时代,思路和方法百花齐放,人们采用不同的方式来实现目标检测。
主要来说,研究的重点涉及两个方面:特征和分类器。
特征层面
特征,本质上的研究问题在于,如何泛化地描述图像的像素变化
无论是sift、surf、orb这种基于关键点的特征
还是hog、Haar这种滑动窗口式的特征,都在一定程度上描述了图像的变化
**除此之外,LBP也是作为检测人脸特征的重要工具。**
LBP特征简而言之,就是一个描述像素周围灰度变化的特征。
对任意像素,其近邻有8个像素。
这八个像素和中心像素进行比较,如果大于目标像素则记为1,否则记为0
那么每个像素都可以得到一个8位的二进制数字。
将二进制数字转化为十进制,来表示当前像素特征。
**随着研究进步,LBP特征也不局限于周围八像素的场景**
比如圆形区域取n个像素比较,这就和orb很类似了。
**同时,LBP也可以做金字塔,从而获得更好的尺度不变性**
模型层面
除了决策树、adaboost之外,
**随机森林也是一个重要的分类器**
随机森林本质上就是多个决策树的集成
但与adaboost不同的是,随机森林每个决策树的训练数据,采用的维度是不一样的
比如第一棵树用的是第一第二维特征,第二课树用的是第2第3维特征等等。
其本质思想,与dropout非常传神,可以说是理论的不谋而合。
小结
关于特征、分类器,在前深度学习时代有非常多的研究,每种研究路线各不相同。
学习这些内容,对于理解深度学习时代的各类研究,揣摩其本质思想,有着非常大的帮助。






![[架构之路-178]-《软考-系统分析师》- 分区操作系统(Partition Operating System)概述](https://img-blog.csdnimg.cn/img_convert/f6127803753a2c50d6fbf3c886530e08.png)