目录
- 前言
- 一、编程时常用的Java类库
- 1. 异常捕获模块(try-catch-finally, Error, Exception)
- 2. boolean / short / int / long / float / double / char / byte及其对应的引用类型
- 二、面试时常考的Java类库
- 1. 一切类型的父类Object及其equals / hashCode / toString方法
- 2. 常用数据结构List、Set、Map
- 三、笔试时做题可以走捷径的类库
- 1. Collection、Collections和Comparator
- 2. BigDecimal和BigInteger
- 后记
前言
“基础知识”是本专栏的第一个部分,本篇博文是第一篇博文,主要介绍Java中的常用类库。我将Java中常用的类库分为3种:
1. 编程时常用的
2. 面试时常考的
3. 笔试时做题可以走捷径的
一、编程时常用的Java类库
1. 异常捕获模块(try-catch-finally, Error, Exception)
准确得说,try/catch/finally只是保留字,它们捕获处理的各种Error和Exception才是类库。
1) 异常处理机制主要回答了3个问题
- What: 异常类型回答了什么被抛出
- Where: 异常堆栈跟踪回答了在哪抛出
- Why: 异常信息回答了为什么被抛出
2) Error和Exception的区别
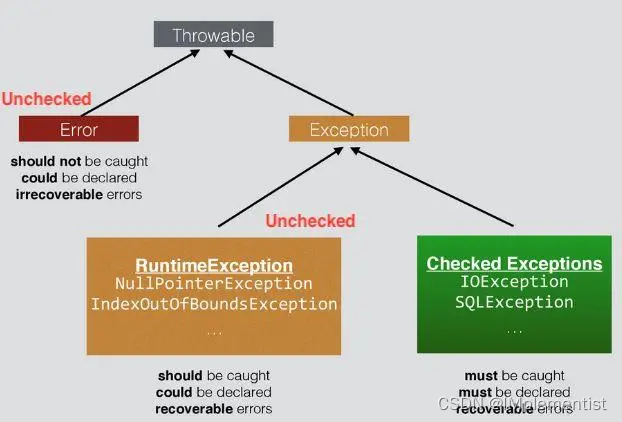
- Error:
程序无法处理的系统错误,编译器不做检查 - Exception:
程序可以处理的异常,捕获后可能恢复
3) 常见的Error和Exception
- RuntimeException
- NullPointerException:空指针异常
- ClassCastException:强制类型转换异常
- IllegalArgumentException:传递非法参数异常
- IndexOutOfBoundsException:下标越界异常
- NumberFormatException:数字格式异常
- CheckedException
- ClassNotFoundException:找不到指定class的异常
- IOException:IO操作异常
- Error
- NoClassDefFoundError:找不到class定义的异常
- StackOverflowError:栈溢出异常
- OutOfMemoryError:内存溢出异常
4) Java的异常处理机制
- 抛出异常:创建异常对象,交由运行时系统处理;
- 捕获异常:寻找合适的异常处理器处理异常,否则终止运行。
5) Java异常的处理原则
- 具体明确:抛出的异常应能通过异常类名和message准确说明异常的类型和产生异常的原因;
- 提早抛出:应尽可能早的发现并抛出异常,便于精确定位问题;
- 延迟捕获:异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理;
2. boolean / short / int / long / float / double / char / byte及其对应的引用类型
上述这8个称为Java的8种基础数值类型,切记虽然String字符串类型非常常用,但基础数值类型中不包含String字符串类型,避免面试时答错。这8个可分为4大类,其中:
- 整型4种:
short、int、long、byte - 浮点型2种:
float、double - 字符型1种:
char - 布尔型1种:
boolean
1) 类型强制转换
值域大的类型转换成值域小的类型会有损失,如:
int intNumber = 2147483647;
// 以下转换会损失数值大小
short shortNumber = (short)intNumber;
double doubleNumber = 1.21474836472147483647;
// 以下转换会损失浮点数精度
float floatNumber = (float)doubleNumber;
2) 基础数值类型及其对应的引用类型
每一个基础数值类型都有一个对应的引用类型:
short——Shortint——Integerlong——Longbyte——Bytefloat——Floatdouble——Doublechar——Characterboolean——Boolean
区别1: 基础数值类型是直接存储数值的数据类型,而引用类型是存储对象引用的数据类型。
区别2: 基础数值类型适用于简单的数值计算,如整数运算、浮点数运算等,而引用类型适用于需要创建和操作对象的情况,如创建对象、调用对象方法等。
区别3: 引用类型可以访问对象的属性和方法,从而实现更复杂的操作,而基础数值类型则只能进行简单的数值计算。同时,基础数值类型在内存中的存储方式和处理效率都比引用类型更高。
区别4: 引用类型有一个特殊的赋值null,表示引用指向空,数值类型不可以赋值为null。
区别5: 支持泛型的一些类、接口或数据结构只能传入引用类型,如List<Integer> arrayList = new ArrayList<Integer>();
二、面试时常考的Java类库
1. 一切类型的父类Object及其equals / hashCode / toString方法
Java是面向对象的语言,可谓一切皆对象。包括上述基础数值类型对应的8种引用类型,所有的引用类型都是Object类的子类,包括我们自定义的类。虽然没有显式得继承Object类,编译器会帮我们隐式继承:
// 隐式继承Object
class DIYClass {}
// 显式继承Object
class DIYClass extends Object {}
Object类中最重要的就是3个方法equals、hashCode和toString
1) equals
public boolean equals(Object obj) {
return (this == obj);
}
这个方法用于判断两个对象是否相等,Object里的equals方法比较简单,逻辑上两个对象的引用相同就返回true,不同就返回false。
我们再来看一下String字符串类中对equals方法的重写:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
String中的equals逻辑就会更复杂一些,以下简单解析一下:
- 判断两个对象的引用是否相同,相同就直接返回
true- 判断传入的对象是否为
String类型,是就进入分支详细判断,不是就默认返回false- 判断两个字符串的长度是否相同,不相同就默认返回
false- 最后对这两个
引用不同、长度相同的字符串进行逐位的字符对比,有一位不同就返回false,否则在while循环结束,没有发现不相同的字符,就返回true
2) hashCode
public native int hashCode();
这个方法专为HashMap这类的数据结构引入的,作用是计算一个对象的哈希散列值。Object类的hashCode方法是原生的C++代码,没有示出。我们来看看String类的:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
我们简单解析一下算法逻辑:
- 首先引用该对象的私有属性
hash,它是int型,初值为0,如果hash不为0或字符串长度<=0,就直接返回hash的值,避免重复计算- 通过公式
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]计算字符串的哈希值并赋值给私有属性hash,代码中的h = 31 * h + val[i];不同,是公式的变形。
3) toString
toString也是一个常用的方法,常用于将一个对象序列化,转化成一个字符串,如:
Integer number = 123456;
// "123456"
String stringifiedNumber = number.toString();
再比如我们有一个自定义类型User,我们可以重写toString方法:
class User {
String name;
String gender;
int age;
public User (String name, String gender, int age) {
this.name = name;
this.gender = gender;
this.age = age;
}
@Override
public String toString() {
return String.format("{\"name\":\"%s\",\"gender\":\"%s\",\"age\":\"%s\"}", name, gender, age);
}
public static void main(String[] args) {
User user = new User("张三", "男", "24");
// "{\"name\":\"张三\",\"gender\":\"gender\",\"age\":\"24\"}"
String stringifiedUser = user.toString();
}
}
利用toSting把User对象序列化,就可以帮助我们实现数据持久化、前后端数据传输等功能。
相关联的知识点和考点:
字符串是一个非常常用,笔面试中最常考的类型,没有之一,以下有几个和相关联的重要知识点:
1. hashCode的溢出问题:最核心的一行代码是h = 31 * h + val[i];,当字符串足够长的时候,h的值一定会超过int类型的最大值,造成溢出,产生一个负数,比如"12345678".hashCode() = -1861353340,但这并不要紧,因为hashCode的作用是将键值分到不同的哈希桶中,负数也可以接受。
2. hashCode计算式为什么选择31作为乘数:31是一个质数,是在众多质数中优选出来的,使这个计算公式具有一定的均匀性,可以尽可能地避免哈希冲突。
3. HashMap:这个数据结构的键(key)最常用的就是String类型,它自身具备的去重功能就完全依赖与equals、hashCode这两个方法,如果用非String的其他引用类型做键(比如整型Integer),也是通过其toString方法把对象的关键信息转换成String类型之后再使用equals和hashCode来做计算和判断的!
4. String / Integer与JVM:这里会有一个常考的题,通过不同方式定义几个String或Integer,让你判断他们equals方法的返回,这里暂不举例,后面写到相关的题我再链接过来。
2. 常用数据结构List、Set、Map
这三个分别对应列表、集合和表(也称为字典或图)
1) List
列表,实际上是一个接口,不能直接实例化,需要实例化他的实现类。实现了List的类中常用的有两个:
ArrayList:直译为数组列表,即线性列表,按照下标index存取数据,使用是要通过泛型指定要存放的数据类型,如:
import java.util.List;
import java.util.ArrayList;
List<Integer> list = new ArrayList<>();
LinkedList:链表,链式存储的列表,使用方式类似于ArrayList
ArrayList和LinkedList的区别:
1. 插入和删除操作的效率:ArrayList在中间插入或删除元素时需要移动后续元素,效率较低;而LinkedList在插入或删除元素时只需要改变前后元素的指针指向,效率较高。
2. 随机访问的效率:ArrayList可以通过索引快速访问元素,时间复杂度为O(1);而LinkedList需要从头开始遍历链表找到指定位置的元素,时间复杂度为O(n)。
3. 内存占用:ArrayList需要预分配内存空间,当存储的元素数量超过预分配的空间时就需要进行扩容,会产生额外的内存开销;而LinkedList不需要预分配内存,只需要为每个元素分配节点空间,不会产生额外的内存开销。
综上所述,如果需要频繁进行插入或删除操作,或者需要按照顺序遍历元素,那么LinkedList更适合;而如果需要随机访问元素,或者需要预先知道元素数量,那么ArrayList更适合。
2) Set
集合,一般用于数据去重,如
import java.util.Set;
import java.util.HashSet;
Set<String> set = new HashSet<>();
set.add("重复的字符串");
set.add("重复的字符串");
// 只输出一行"重复的字符串"
for (String key: set) {
System.out.println(key);
}
3) Map
表,也称为字典,一般用于存储键值对,对一些数据进行统计或分类。比如一个题目:有一堆球,每个球上会写一句话,有的写的一样,有的写的不一样,让我们统计写了各句话的球的个数:
import java.util.Map;
import java.util.HashMap;
Map<String, Integer> map = new HashMap<>();
String[] balls = new String[]{"今天放假啦!", "劳动节快乐!", "今天放假啦!"};
for (String ball: balls) {
if (map.containsKey(ball)) {
map.put(ball, map.get(ball) + 1);
} else {
map.put(ball, 1);
}
}
/**
* 输出:
* 句子:今天放假啦!, 总数:2
* 句子:劳动节快乐!, 总数:1
*/
for (Map.Entry<String, Integer> pair: map.entrySet()) {
System.out.printf("句子:%s, 总数:%d\n", pair.getKey(), pair.getValue());
}
值得注意的是,HashSet是通过HashMap实现的,其维护一个类型为HashMap的私有属性,并在构造方法中实例化它:
public class HashSet<E> {
......
private transient HashMap<E,Object> map;
......
public HashSet() {
map = new HashMap<>();
}
}
HashMap是最频繁的考点之一,在后面的其他博文中我们会展开来讲。
三、笔试时做题可以走捷径的类库
1. Collection、Collections和Comparator
1) Collection和Collections
字面上这两个的名称只有s的区别,但Collection是个接口,Collections是个类。
- 前面说到的
List、Set、Map等接口,其都属于一大堆数据的集合,简称数据集,即Collection,所以它们的实现类,同时也实现了Collection接口,如ArrayList、LinkedList、HashSet、HashMap等。 Collections是一个工具类,它里面定义了很多静态的,数据集通用的工具方法,只要实现了Collection接口的类的实例都可以调用这些方法。其中最长用到的就是Collections.sort(),它用来对List接口实现类的实例进行排序,有两个重载:- public static <T extends Comparable<? super T>> void sort(List list)
这个方法只需传入需要排序的List接口实现类的实例,他的排序逻辑即ascii字典序(数字0 < 9,字符’a’ < ‘z’),举两个例子- 列表[1, 9, 3, 7],排序后得到[1, 3, 7, 9]
- 列表[“d”, “b”, “c”, “a”],排序后得到[“a”, “b”, “c”, “d”]
- public static void sort(List list, Comparator<? super T> c)
这个方法除了待排序的list外,还需要传入一个Comparator比较器的实例,在上述默认的字典序排序方法不能满足我们的需要时,就可以通过Comparator自定义一个排序规则,然后传入排序算法中。
- public static <T extends Comparable<? super T>> void sort(List list)
2) Comparator
比较器是一个接口,自定义一个比较器类,实现其中的compare方法即可。举个例子,我们要对一个Integer型的列表进行排序,排序规则是<=5的数字从小到大排列,>5的数字从大到小排列:
import java.util.Comparator;
class MyComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
if (o1 <= 5 && o2 <= 5) {
return o1 - o2;
} else if (o1 > 5 && o2 > 5) {
return o2 - o1;
} else if (o1 <= 5) {
return -1;
} else {
return 1;
}
}
}
假设输入的list为[1, 9, 3, 7, 4, 6, 8, 2, 5],调用Collections.sort(list, new MyComparator()),得到[1, 2, 3, 4, 5, 9, 8, 7, 6]
需要注意的是:返回负数表示左侧的比较数应该放前边,返回正数表示右边的数应该放前边,返回0表示两数相等,谁放前边都无所谓
再举一个很实用的例子,笔者在笔试实战中也遇到过这种题型,即在Comparator中对一个类的多个属性进行复式规则的排序。这里我们再用一下上面的User类,假设我们拿到一个用户列表,每个用户都有姓名、性别和年龄三个属性,现在要求女性排在男性前面,女性按年龄增序排列,男性按年龄降序排列,请给出比较器:
class MyComparator implements Comparator<User> {
@Override
public int compare(User o1, User o2) {
if (o1.gender.equals("男") && o2.gender.equals("男")) {
return o2.age - o1.age;
} else if (o1.gender.equals("女") && o2.gender.equals("女")) {
return o1.age - o2.age;
} else if (o1.gender.equals("男") && o2.gender.equals("女")) {
return 1;
} else {
return -1;
}
}
}
// 构造测试数据
List<User> list = new ArrayList<>();
list.add(new User("", "男", 24));
list.add(new User("", "女", 19));
list.add(new User("", "女", 43));
list.add(new User("", "女", 8));
list.add(new User("", "男", 63));
list.add(new User("", "男", 13));
// 按照自定义规则排序
Objects.sort(list, new MyComparator());
// 输出排序结果
for (User user: list) {
System.out.println(user.toString());
}
/**
* 输出:
* {"name":"","gender":"女","age":"8"}
* {"name":"","gender":"女","age":"19"}
* {"name":"","gender":"女","age":"43"}
* {"name":"","gender":"男","age":"63"}
* {"name":"","gender":"男","age":"24"}
* {"name":"","gender":"男","age":"13"}
*/
2. BigDecimal和BigInteger
这两个类用于表示和计算比较长的小数和整数,常见于超大数求乘积、银行金额计算需要很高精度等类型的题目。他们内部用字符串来表示和维护整形和浮点型的数值,因为int和double这种类型的数值,其十进制上看最多也就10几位数字、几十位数字,计算大数动辄溢出,而且浮点型数值常常会在计算中损失精度。而JVM中对字符串的长度限制是4GB,可以表示天文数字了。
下面使用BigInteger举例,BigDecimal用法类似:
BigInteger integer = new BigInteger("19374682509876543211234567890");
BigInteger result = integer.add(new BigInteger("1"));
System.out.printf("加法-add:%s\n", result);
result = result.subtract(new BigInteger("3"));
System.out.printf("减法-subtract:%s\n", result);
result = result.multiply(new BigInteger("9"));
System.out.printf("乘法-multiply:%s\n", result);
result = result.divide(new BigInteger("2"));
System.out.printf("除法-divide:%s\n", result);
result = result.pow(4);
System.out.printf("n次方-pow:%s\n", result);
result = result.mod(new BigInteger("482357"));
System.out.printf("取模-mod:%s\n", result);
/**
* 输出:
* 加法-add:19374682509876543211234567891
* 减法-subtract:19374682509876543211234567888
* 乘法-multiply:174372142588888888901111110992
* 除法-divide:87186071294444444450555555496
* n次方-pow:57781449612950572744510682125238074808216304022716317028892540333080618509043126779553236510931372163713161981792256
* 取模-mod:247734
*/
需要注意的是:这里的各种运算不能再使用运算符号±*/等,必须使用该类提供的成员方法。
使用这种类型可以轻松AC大值运算或者有数值精度要求的笔试题,但一个难点是:你需要记住各种运算的方法名,也就是上述的这些单词:add、subtract、multiply、divide、mod、pow等。
后记
这里越写越文思泉涌,越写知识点月多,不觉间写了1万字,一口气看完可能有些吃力。先放出来让大家看看吧,如果嫌长,我得闲拆成两篇。
另外后面如果再想起了什么常用类库需要介绍的,我再补充进来,那时拆成两篇博文也势在必行了。






![[架构之路-178]-《软考-系统分析师》- 分区操作系统(Partition Operating System)概述](https://img-blog.csdnimg.cn/img_convert/f6127803753a2c50d6fbf3c886530e08.png)