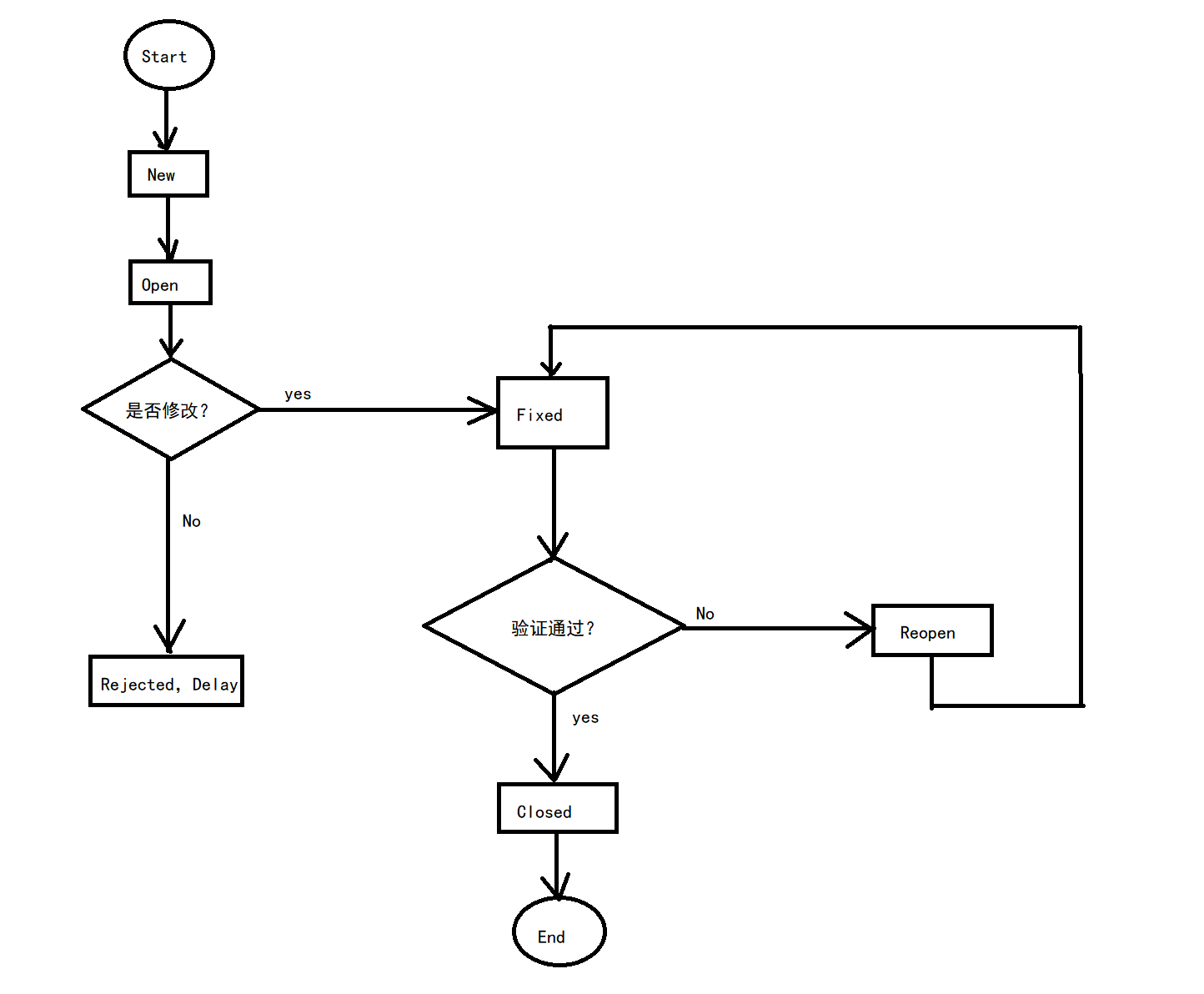
前置知识
统计
假设数据集 X ∈ R n × m \mathbf{X}\in\mathbb{R}^{n\times m} X∈Rn×m,其中 n n n表示样本数量, m m m表示特征个数
均值
X
ˉ
=
1
n
e
T
X
=
1
n
∑
i
=
1
n
X
i
\bar{\mathbf{X}} =\frac{1}{n}\mathbf{e}^T\mathbf{X} =\frac{1}{n} \sum_{i=1}^{n}\mathbf{X}_i
Xˉ=n1eTX=n1∑i=1nXi(其中
e
\mathbf{e}
e为全
1
1
1向量,
X
i
\mathbf{X}_i
Xi是行向量)
协方差
c
o
v
(
X
)
=
1
n
−
1
(
X
−
X
ˉ
)
T
(
X
−
X
ˉ
)
cov(\mathbf{X}) = \frac{1}{n-1}\left(\mathbf{X}-\bar{\mathbf{X}}\right)^T\left(\mathbf{X}-\bar{\mathbf{X}}\right)
cov(X)=n−11(X−Xˉ)T(X−Xˉ)
补充说明:
1.这里用
n
−
1
n-1
n−1和
n
n
n都行,因为最后只要特征向量,而不需要特征值,
A
x
=
λ
x
⇒
(
k
A
)
x
=
(
k
λ
)
x
\mathbf{A}x=\lambda x\Rightarrow (k\mathbf{A})x=\left(k\lambda\right)\mathbf{x}
Ax=λx⇒(kA)x=(kλ)x
2.其实不能直接
X
−
X
ˉ
\mathbf{X}-\bar{\mathbf{X}}
X−Xˉ,因为维度对不上,这里就当作能广播
投影
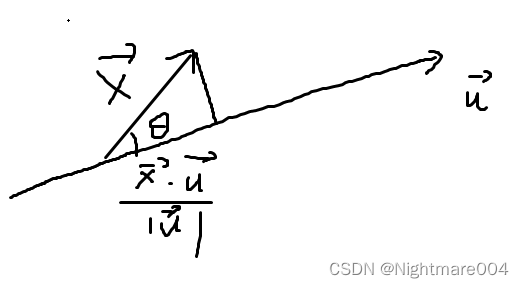
将
x
\mathbf{x}
x投影到
u
\mathbf{u}
u
∥
x
∥
cos
θ
=
∥
x
∥
x
⋅
u
∥
x
∥
∥
u
∥
=
x
⋅
u
∥
u
∥
\|\mathbf{x}\|\cos \theta = \|\mathbf{x}\| \frac{\mathbf{x}\cdot \mathbf{u}}{\|\mathbf{x}\|\|\mathbf{u}\|}=\frac{\mathbf{x}\cdot \mathbf{u}}{\|\mathbf{u}\|}
∥x∥cosθ=∥x∥∥x∥∥u∥x⋅u=∥u∥x⋅u
如果
u
\mathbf{u}
u是单位向量,则投影简化为
x
⋅
u
\mathbf{x}\cdot \mathbf{u}
x⋅u
PCA
步骤
1.减均值
X
^
=
X
−
X
ˉ
=
X
−
1
n
e
e
T
X
=
(
I
−
1
n
e
e
T
)
X
\hat{\mathbf{X}}=\mathbf{X}-\bar{\mathbf{X}}=\mathbf{X}-\frac{1}{n}\mathbf{e}\mathbf{e}^T\mathbf{X}=\left(\mathbf{I}- \frac{1}{n}\mathbf{e}\mathbf{e}^T\right)\mathbf{X}
X^=X−Xˉ=X−n1eeTX=(I−n1eeT)X
(其实不能直接
X
−
X
ˉ
\mathbf{X}-\bar{\mathbf{X}}
X−Xˉ,因为维度对不上,这里就当作能广播,后面两个等号维度是对的上的)
减均值之后,均值为
0
0
0
这里也可以继续除以标准差
2.计算协方差矩阵
c
o
v
(
X
^
)
=
1
n
−
1
X
^
T
X
^
∈
R
m
×
m
cov\left(\hat{\mathbf{X}}\right)=\frac{1}{n-1}\hat{\mathbf{X}}^T\hat{\mathbf{X}}\in\mathbb{R}^{m\times m}
cov(X^)=n−11X^TX^∈Rm×m
这里因为均值为
0
0
0,所以不用再减去
X
ˉ
\bar{\mathbf{X}}
Xˉ
3.计算协方差矩阵特征值与特征向量
不妨假设计算之后的特征值
λ
1
≥
λ
2
≥
⋯
≥
λ
m
\lambda_1 \ge \lambda_2\ge \cdots \ge \lambda_m
λ1≥λ2≥⋯≥λm
对应的单位特征向量
v
1
,
v
2
,
⋯
,
v
m
\mathbf{v}_1,\mathbf{v}_2,\cdots, \mathbf{v}_m
v1,v2,⋯,vm
4.选择前
k
k
k大的特征值对应的特征向量
设
V
=
(
v
1
,
v
2
,
⋯
,
v
k
)
∈
R
m
×
k
\mathbf{V} = \left(\mathbf{v}_1,\mathbf{v}_2,\cdots, \mathbf{v}_k\right)\in\mathbb{R}^{m\times k}
V=(v1,v2,⋯,vk)∈Rm×k
5.投影
Y
=
X
^
V
∈
R
n
×
k
\mathbf{Y} = \hat{\mathbf{X}}\mathbf{V}\in\mathbb{R}^{n\times k}
Y=X^V∈Rn×k
原理
最大方差理论
信号处理中认为信号具有较大的方差,噪声有较小的方差
因此我们认为,最好的
k
k
k维特征是将样本转换为
k
k
k维后,每一维上的样本方差都很大
设
X
^
\hat{\mathbf{X}}
X^为减去均值后的数据集
先从
k
=
1
k=1
k=1开始,不妨假设投影到
u
\mathbf{u}
u,投影后为
X
^
u
\hat{\mathbf{X}}\mathbf{u}
X^u
投影之后的均值依然为
0
0
0,(
e
T
X
^
=
0
⇒
e
T
(
X
^
u
)
=
0
\mathbf{e}^T\hat{\mathbf{X}}=0\Rightarrow \mathbf{e}^T\left(\hat{\mathbf{X}}\mathbf{u}\right)=0
eTX^=0⇒eT(X^u)=0)
则方差
arg
max
∥
u
∥
=
1
S
2
=
1
n
−
1
arg
max
∥
u
∥
=
1
u
T
X
^
T
X
^
u
=
arg
max
∥
u
∥
=
1
u
T
c
o
v
(
X
^
)
u
\begin{aligned} \arg\max_{\|\mathbf{u}\|=1} S^2 &= \frac{1}{n-1}\arg\max_{\|\mathbf{u}\|=1}\mathbf{u}^T\hat{\mathbf{X}}^T\hat{\mathbf{X}}\mathbf{u}\\ &=\arg\max_{\|\mathbf{u}\|=1}\mathbf{u}^Tcov\left(\hat{\mathbf{X}}\right)\mathbf{u}\\ \end{aligned}
arg∥u∥=1maxS2=n−11arg∥u∥=1maxuTX^TX^u=arg∥u∥=1maxuTcov(X^)u
熟悉的话就知道这个是瑞利商,不熟悉可以用拉格朗日乘数法,或者特征值分解
最后得到
u
\mathbf{u}
u为
X
^
T
X
^
\hat{\mathbf{X}}^T\hat{\mathbf{X}}
X^TX^的最大特征值对应的特征向量
为了方便,设刚刚得到的
u
\mathbf{u}
u为
u
1
\mathbf{u}_1
u1
现在需要找
u
2
\mathbf{u}_2
u2,使得投影后方差最大,并且
u
2
\mathbf{u}_2
u2与
u
1
\mathbf{u}_1
u1正交
arg
max
∥
u
2
∥
=
1
u
1
T
u
2
=
1
u
2
T
c
o
v
(
X
^
)
u
2
\arg\max_{\|\mathbf{u}_2\|=1 \atop \mathbf{u}_1^T\mathbf{u}_2=1}\mathbf{u}_2^Tcov\left(\hat{\mathbf{X}}\right)\mathbf{u}_2
argu1Tu2=1∥u2∥=1maxu2Tcov(X^)u2
构造拉格朗日函数
L
(
u
2
,
λ
,
μ
)
=
u
2
T
c
o
v
(
X
^
)
u
2
−
λ
(
u
2
T
u
2
−
1
)
−
μ
u
1
T
u
2
L\left(\mathbf{u}_2, \lambda, \mu\right)=\mathbf{u}_2^Tcov\left(\hat{\mathbf{X}}\right)\mathbf{u}_2-\lambda\left(\mathbf{u}_2^T\mathbf{u}_2-1\right)-\mu\mathbf{u}_1^T\mathbf{u}_2
L(u2,λ,μ)=u2Tcov(X^)u2−λ(u2Tu2−1)−μu1Tu2
求偏导
∂
L
∂
u
2
=
2
c
o
v
(
X
^
)
u
2
−
2
λ
u
2
−
μ
u
1
=
0
\frac{\partial L}{\partial\mathbf{u}_2}=2cov\left(\hat{\mathbf{X}}\right)\mathbf{u}_2-2\lambda\mathbf{u}_2-\mu\mathbf{u}_1=0
∂u2∂L=2cov(X^)u2−2λu2−μu1=0
注意到
c
o
v
(
X
^
)
u
1
=
λ
1
u
1
cov\left(\hat{\mathbf{X}}\right)\mathbf{u}_1=\lambda_1 \mathbf{u}_1
cov(X^)u1=λ1u1,并且协方差矩阵是个对称矩阵,有
2
u
1
T
c
o
v
(
X
^
)
u
2
−
2
u
1
T
u
2
−
μ
u
1
T
u
1
=
2
λ
1
u
1
T
u
2
−
0
−
μ
=
μ
=
0
\begin{aligned} &2\mathbf{u}_1^Tcov\left(\hat{\mathbf{X}}\right)\mathbf{u}_2-2\mathbf{u}_1^T\mathbf{u}_2-\mu\mathbf{u}_1^T\mathbf{u}_1\\ =& 2\lambda_1\mathbf{u}_1^T\mathbf{u}_2-0-\mu\\ =&\mu\\ =&0 \end{aligned}
===2u1Tcov(X^)u2−2u1Tu2−μu1Tu12λ1u1Tu2−0−μμ0
于是
c
o
v
(
X
^
)
u
2
=
λ
u
2
cov\left(\hat{\mathbf{X}}\right)\mathbf{u}_2=\lambda\mathbf{u}_2
cov(X^)u2=λu2
可以得到
u
2
\mathbf{u}_2
u2为
c
o
v
(
X
^
)
cov\left(\hat{\mathbf{X}}\right)
cov(X^)第二大特征值对应的特征向量
后面以此类推
https://towardsdatascience.com/principal-component-analysis-part-1-the-different-formulations-6508f63a5553
https://www.askpython.com/python/examples/principal-component-analysis
https://bagheri365.github.io/blog/Principal-Component-Analysis-from-Scratch/
https://www.python-engineer.com/courses/mlfromscratch/11_pca/
http://blog.codinglabs.org/articles/pca-tutorial.html
![[架构之路-178]-《软考-系统分析师》- 分区操作系统(Partition Operating System)概述](https://img-blog.csdnimg.cn/img_convert/f6127803753a2c50d6fbf3c886530e08.png)