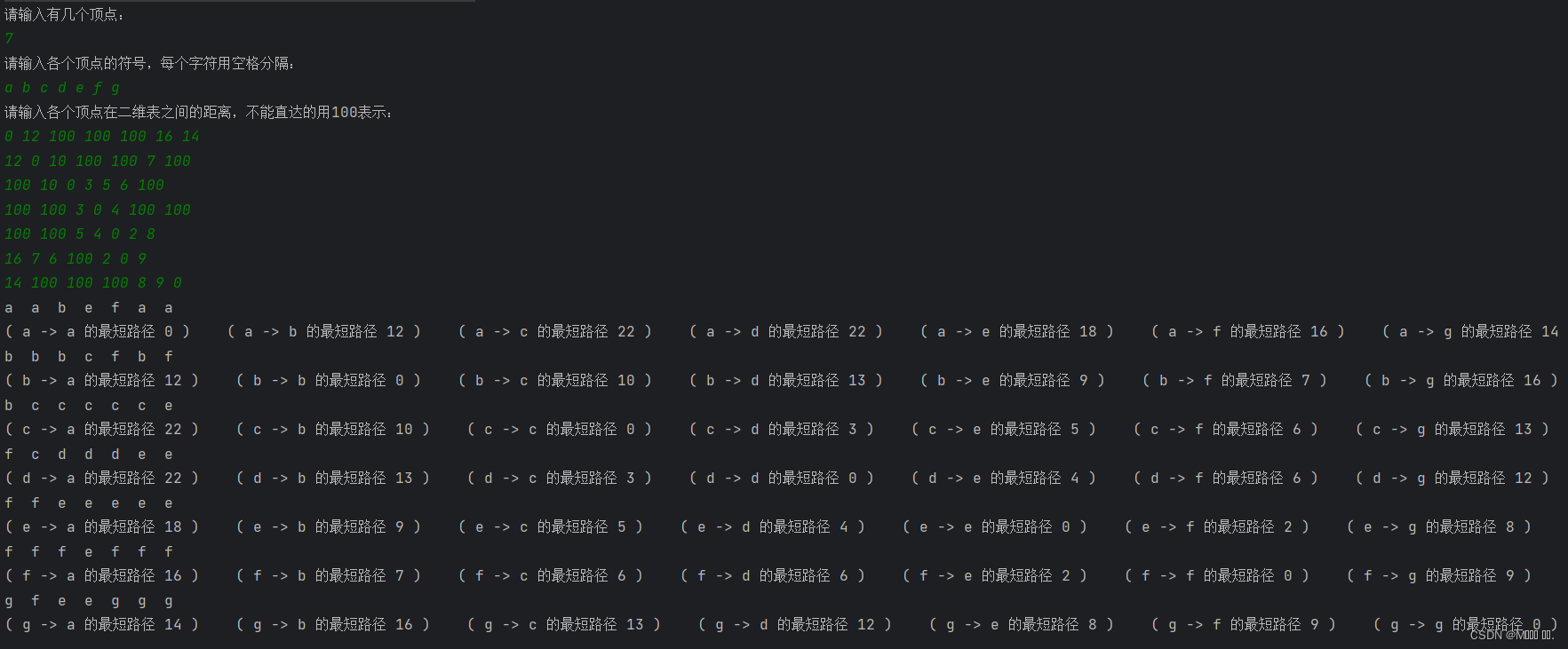
文章目录
- (一)过拟合
- (二)暂退法
(一)过拟合
1.过拟合产生的原因
(1)根本原因:
我们都知道模型参数的优化方式:反向传播更新梯度,然后随机梯度下降。
也非常清楚模型参数优化的方向:使得损失尽可能的小。
但这里有一点值得注意,我们想要尽可能减小的损失是训练损失,而我们想要尽可能达成的目标是模型在未知数据上也能有良好表现。
这里就是过拟合会产生的根本原因——训练数据不能囊括未知数据。
(2)直接原因:
模型的预测能力源于对训练数据中特征之间关系的挖掘。但是由于训练数据是有限的、并且存在噪声,模型会挖掘出一些虚假的关联。
举个例子,我们正在训练一个模型去预测一个人是否患病,样本中所有患病的人如果恰巧穿的都是运动鞋,那么模型很可能挖掘出这样一种关联——穿运动鞋的人患病。这显然不是正确的关联。
2.泛化性-灵活性
(1)泛化性:泛化性就是指模型在未知数据上预测的能力。
也可以理解为在训练数据上与测试数据上的损失差距。这里举几个例子来理解:
过拟合的泛化性之所以差,是因为训练损失很小,但是测试损失很大,二者差距很大;
简单模型的泛化性之所以好,可能是因为训练损失和测试损失都很小(我们希望这样),也可能是因为训练损失和测试损失都很大,对于后者,虽然有很好的泛化性,但是显然没什么意义。
(2)灵活性:能够表示的函数范围。
(3)泛化性-灵活性权衡:
也称为偏差-方差权衡(bias-variance tradeoff),之所以需要权衡,是因为泛化性和灵活性是相冲突的:
模型越复杂,能够表示的函数范围自然越广,灵活性自然越强;
但与此同时,模型越复杂,也就越容易过拟合,泛化性自然越差。
我们既希望模型能够挖掘样本特征间尽可能多的关联,以便模型可以具有广泛的适用性;但又不希望模型挖掘太深以至于挖掘出虚假的关联,造成过拟合,缺少泛化性。
(二)暂退法
1.使用暂退法的原因
暂退法用来使模型具有更强的泛化性,所以我们先来定义什么才是更强的泛化性:
(1)模型复杂度:
模型越简单,泛化性越强。这里的泛化性体现为简单性,以较小维度的形式呈现。
(2)扰动的稳健性(重点):
简单性的另一种角度是平滑性,即函数不应该对输入的微小变化敏感(发生过拟合之后,损失随着输入不同剧烈波动,简单性很差)。
为了添加微小的扰动,除了噪声之外,我们还可以使用暂退法。
2.暂退法原理
直观理解,暂退法就是在训练的每次迭代中,随机丢弃中间的神经元:
h
=
{
0
h
1
−
p
h=\begin{cases} 0\\ \frac{h}{1-p} \end{cases}
h={01−ph
其中
p
p
p为暂退层超参数,意义为抛弃输入的概率。
如下图所示是一个含有一个隐藏层的多层感知机,暂退法丢弃了来自 h 2 h_2 h2和 h 5 h_5 h5的输入:
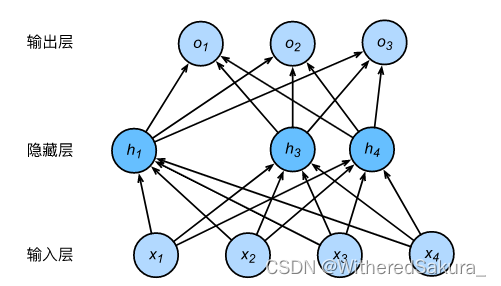
这样模型就不能过于依赖 h 1 h_1 h1到 h 5 h_5 h5中的任何一个元素。
3.应用
一般情况下我们在测试时不使用暂退法,只在训练时应用。
(1)减少过拟合
(2)测试稳定性:在测试时应用不同暂退法,如果模型的预测结果相似,我们可以认为模型具有稳定性。
4.实现
import torch
from torch import nn
def dropout_layer(X, p):
assert 0 <= p <= 1
if p == 1: # 丢弃全部输入
return torch.zeros_like(X)
else if p == 0 # 不丢弃任何输入
return X
mask = torch.rand(X.shape) > p
return mask * X / (1.0 - p)
简洁实现:
dropout_layer = nn.Dropout(p=0.5)
参考资料:《动手学深度学习》(Pytorch版)