ElasticSearch 内置了分词器,如标准分词器、简单分词器、空白词器等。但这些分词器对我们最常使用的中文并不友好,不能按我们的语言习惯进行分词。
ik分词器就是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,我们还可以定制化分词。
ik分词器是一个插件包,我们可以用插件的方式将它接入到ES。
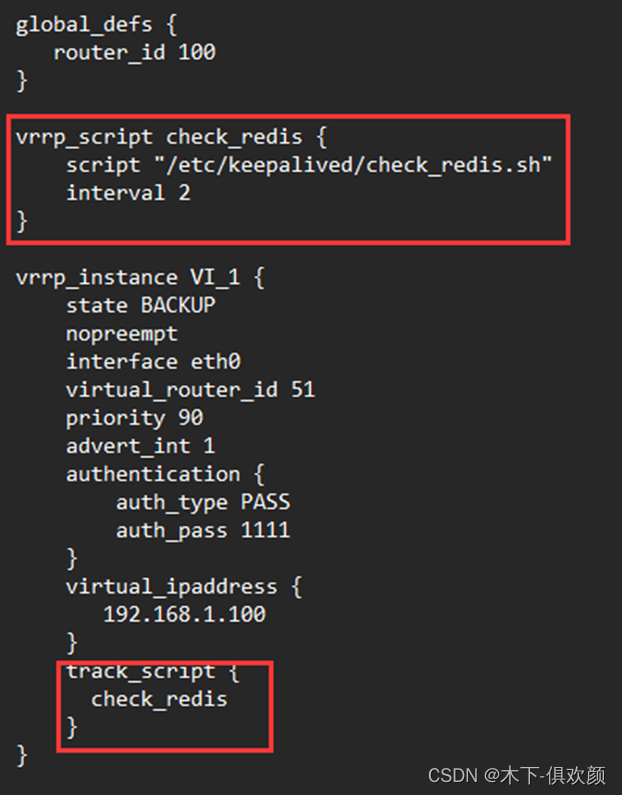
一、安装
1.1 下载
下载地址:ik分词器地址
注意要选择跟自己es保持一致的版本下载。
1.2解压
将下载的安装包在es安装目录下的plugins下新建一个ik文件夹、将文件解压。
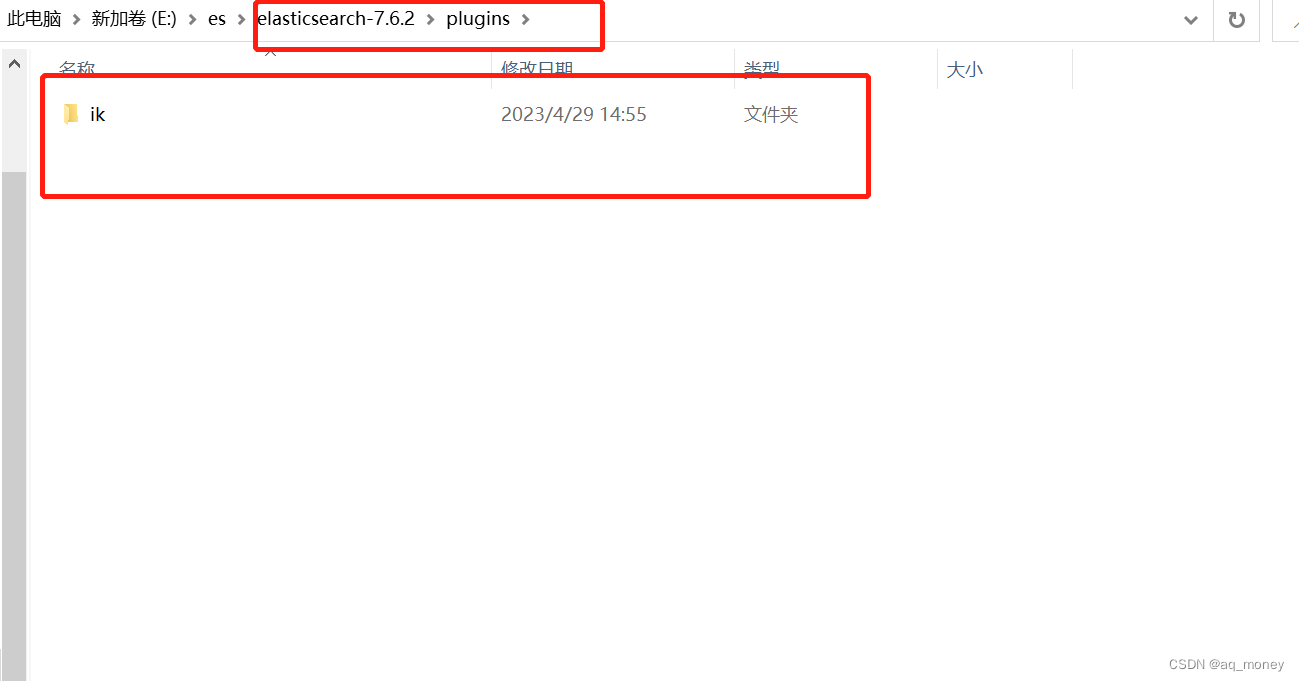
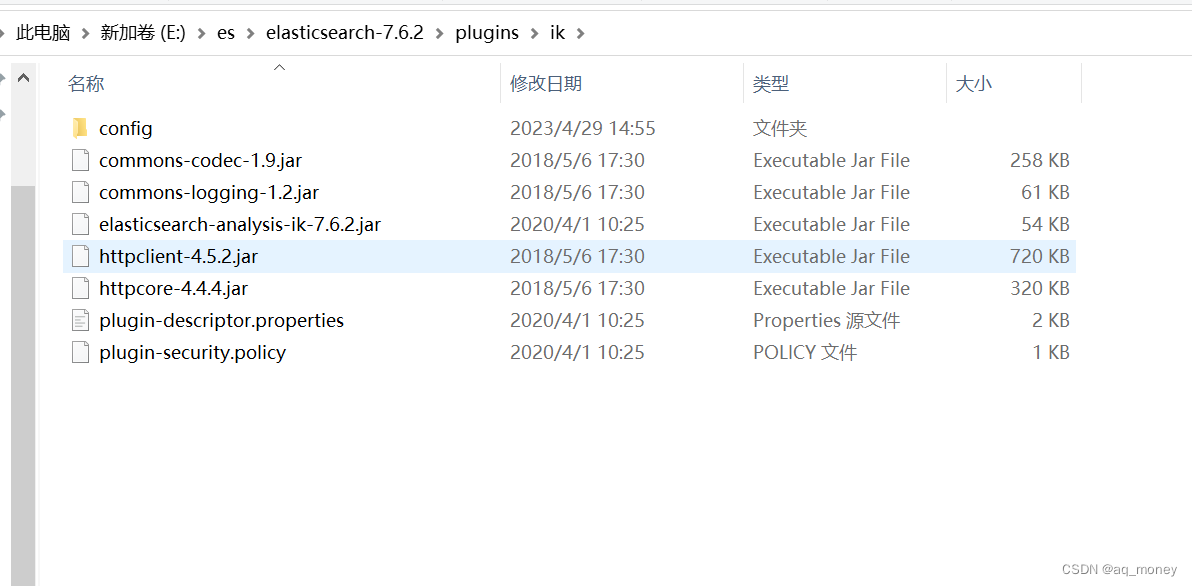
1.3启动
启动成功之后可以看见ik插件已经运行
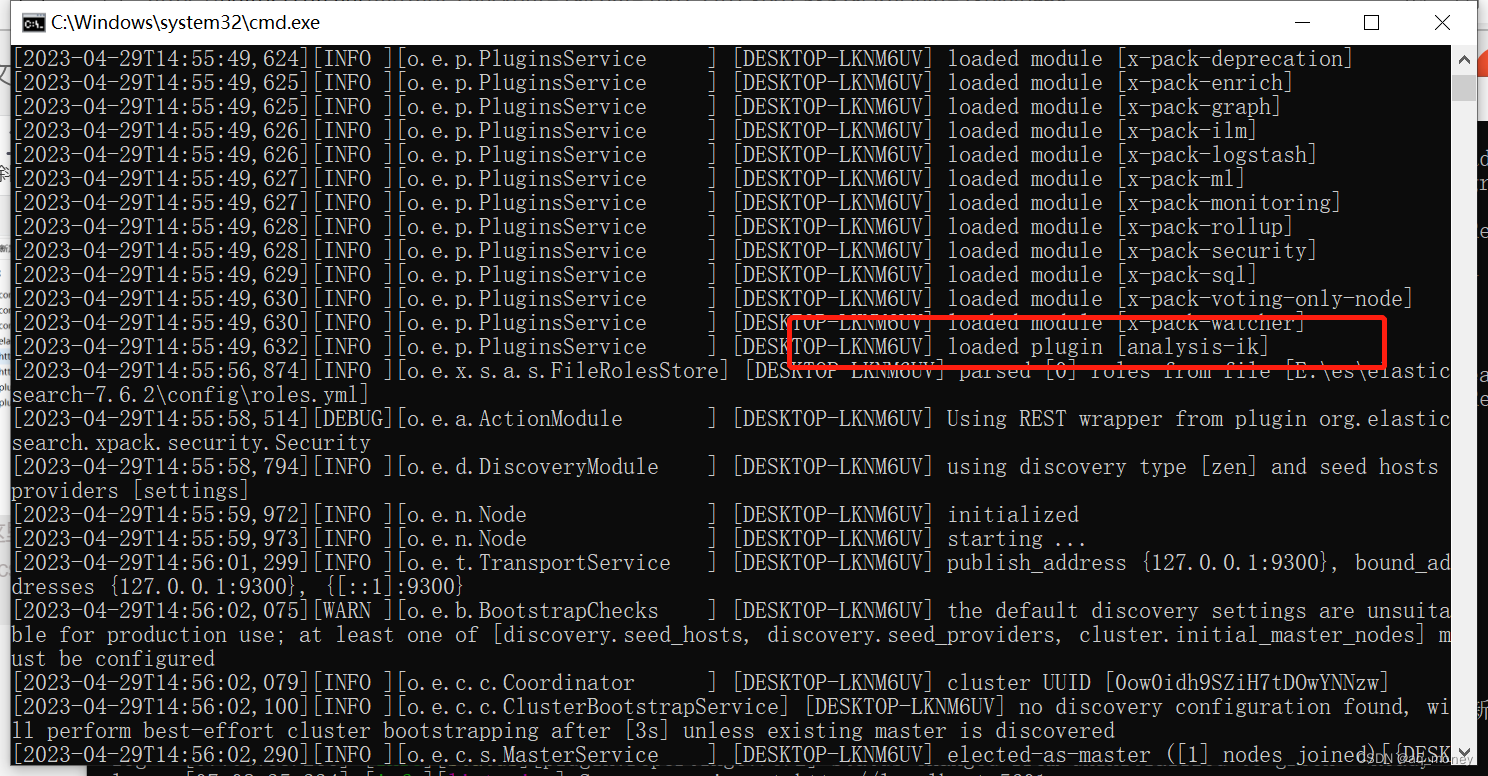
也可以通过当前命令查看插件是否安装。

插箱即用,到此ik分词器的安装就完成了。
二、使用IK分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
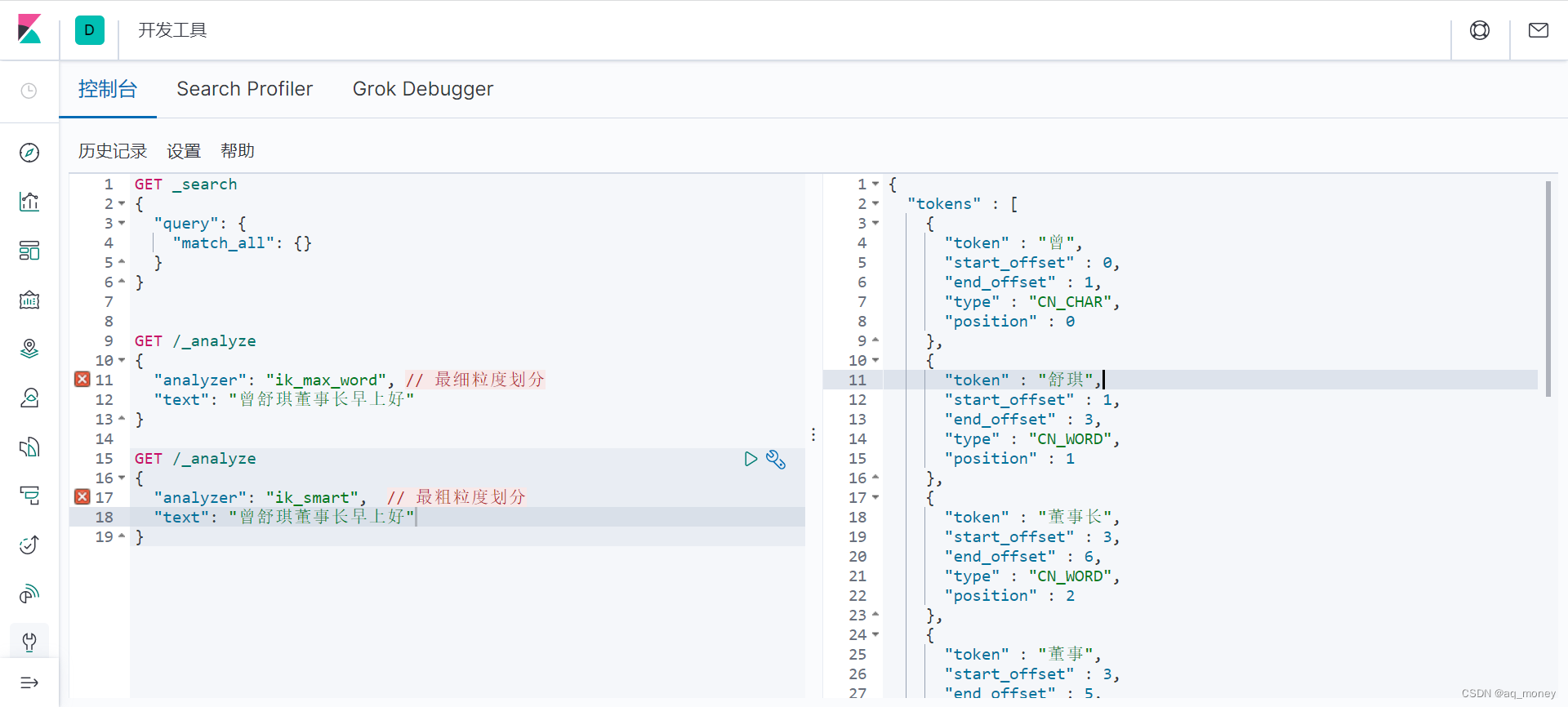
会将文本做最细粒度的拆分,比如会将"曾舒琪董事长早上好"拆分为"曾、舒琪、董事长、董事、长、早上好、早上、上好"
GET /_analyze
{
"analyzer": "ik_max_word", // 最细粒度划分
"text": "曾舒琪董事长早上好"
}
执行结果如下:
{
"tokens" : [
{
"token" : "曾",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "舒琪",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "董事长",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "董事",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "长",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "早上好",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "早上",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "上好",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 7
}
]
}
2、ik_smart
会做最粗粒度的拆分,比如会将"曾舒琪董事长早上好"拆分成"曾、舒琪、董事长、早上好"
GET /_analyze
{
"analyzer": "ik_smart", // 最粗粒度划分
"text": "曾舒琪董事长早上好"
}
执行结果如下:
{
"tokens" : [
{
"token" : "曾",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "舒琪",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "董事长",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "早上好",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}
这就是ik分词器两种简单的使用模式
问题
我们使用这两种模式,想让ik分词器把名词进行一个拆开划分,但是有一个问题,曾舒琪这明显就是一个人名,两种模式都并没有把这个词汇拆开到一起
解决方法
其实ik分词器给我们提供了一系列的词典,我们只需要添加一个自己的词典。
1、找到config目录下的xml配置文件
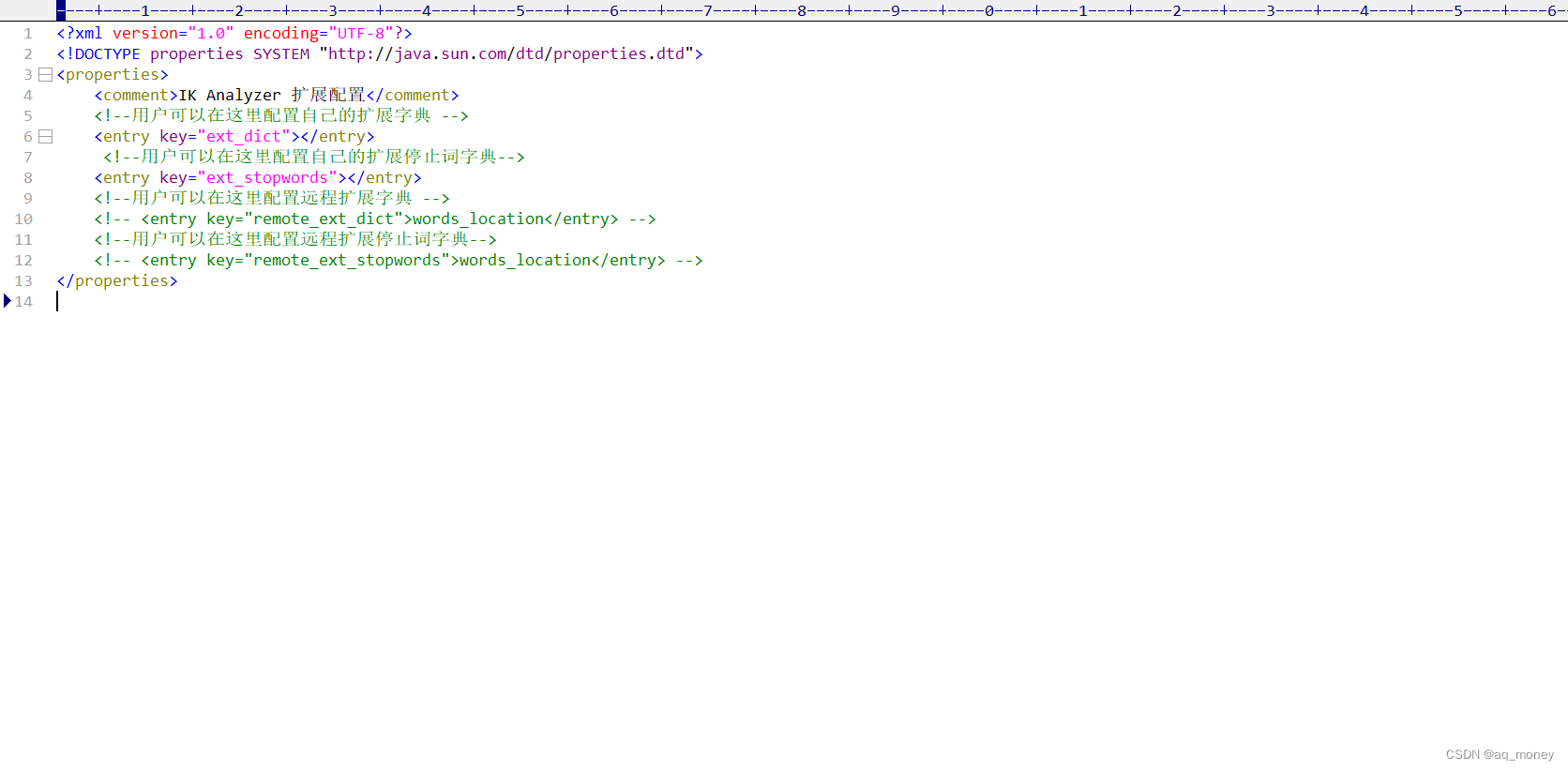
2、这里我们需要添加我们自己的词典。其实所谓词典就是创建一个名称后缀以dict结尾的文件。
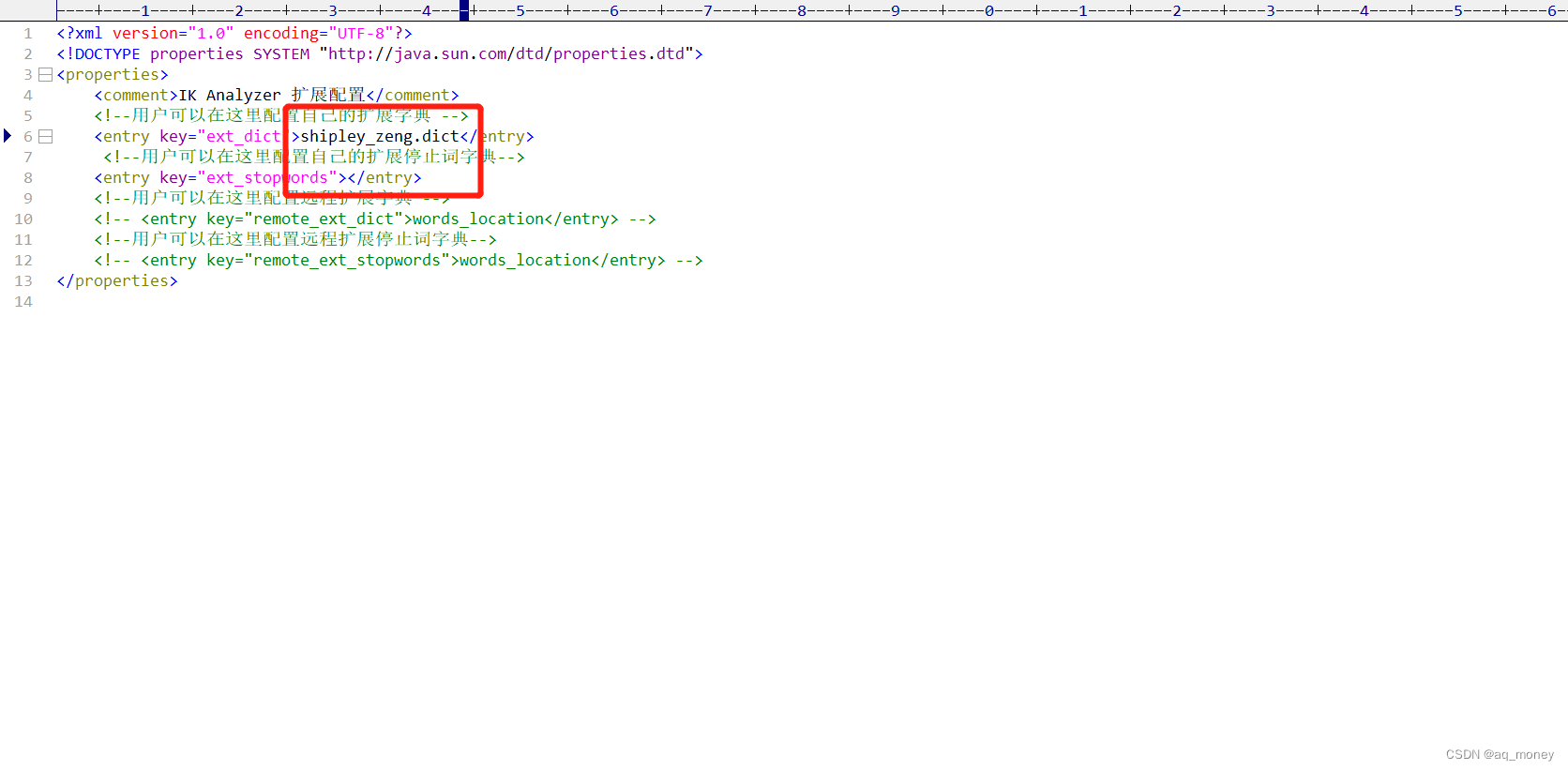
3、这里我添加了一个shipley_zeng.dict的词典
4、那这个词典哪里来的呢?凭空出现吗?我们返回上一级目录。可以看见有很多词典、我们随便打开一个看看。
看看这个main.dict

可以看见这边有特别多的词汇、这些词汇在实际的应用开发过程当中肯定是不够用的、我们要创建一个属于我们自己的词典。
5、创建一个自己的词典到config目录下,名字跟上面提到的一样叫做shipley_zeng.dict
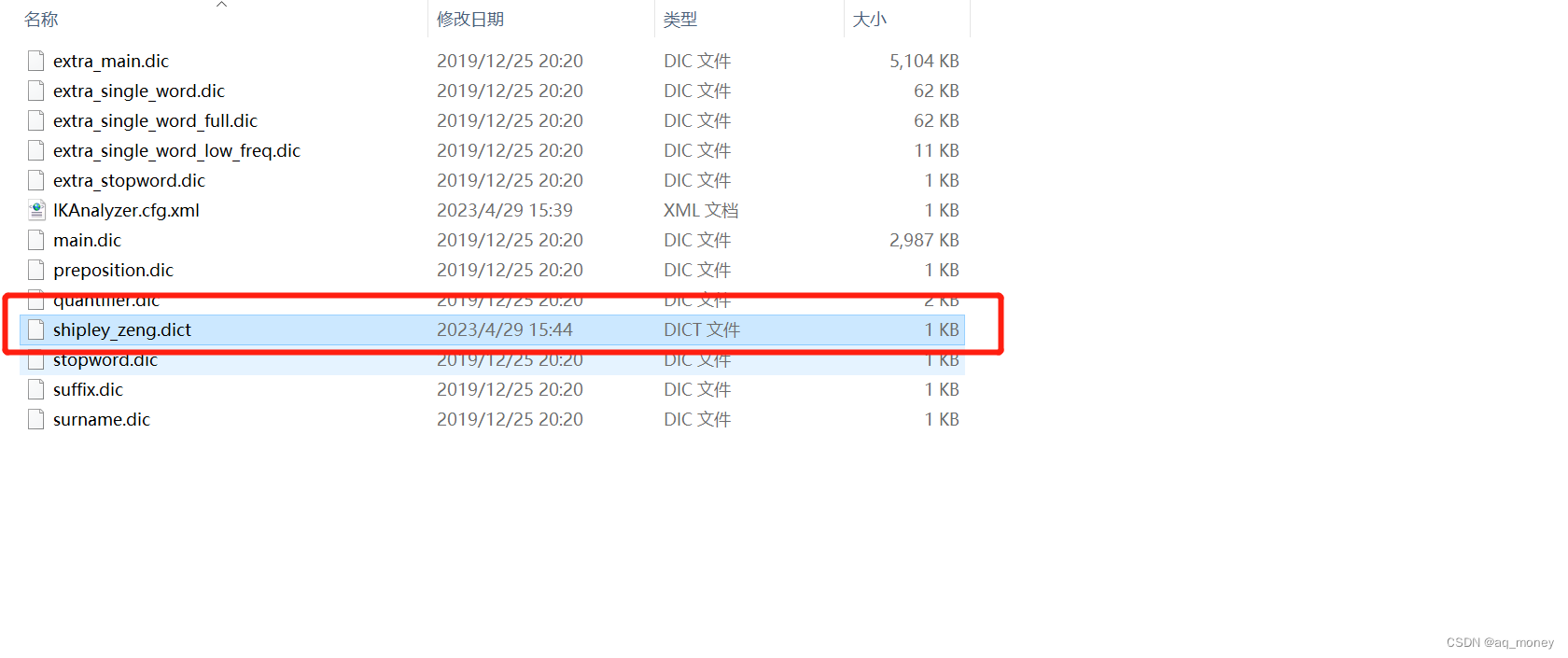
内容如下,这边我们要注意一下编码格式为UTF-8

6、加入这个词典后我们在重新启动es,可以看见已经成功的加载了我们创建的词典
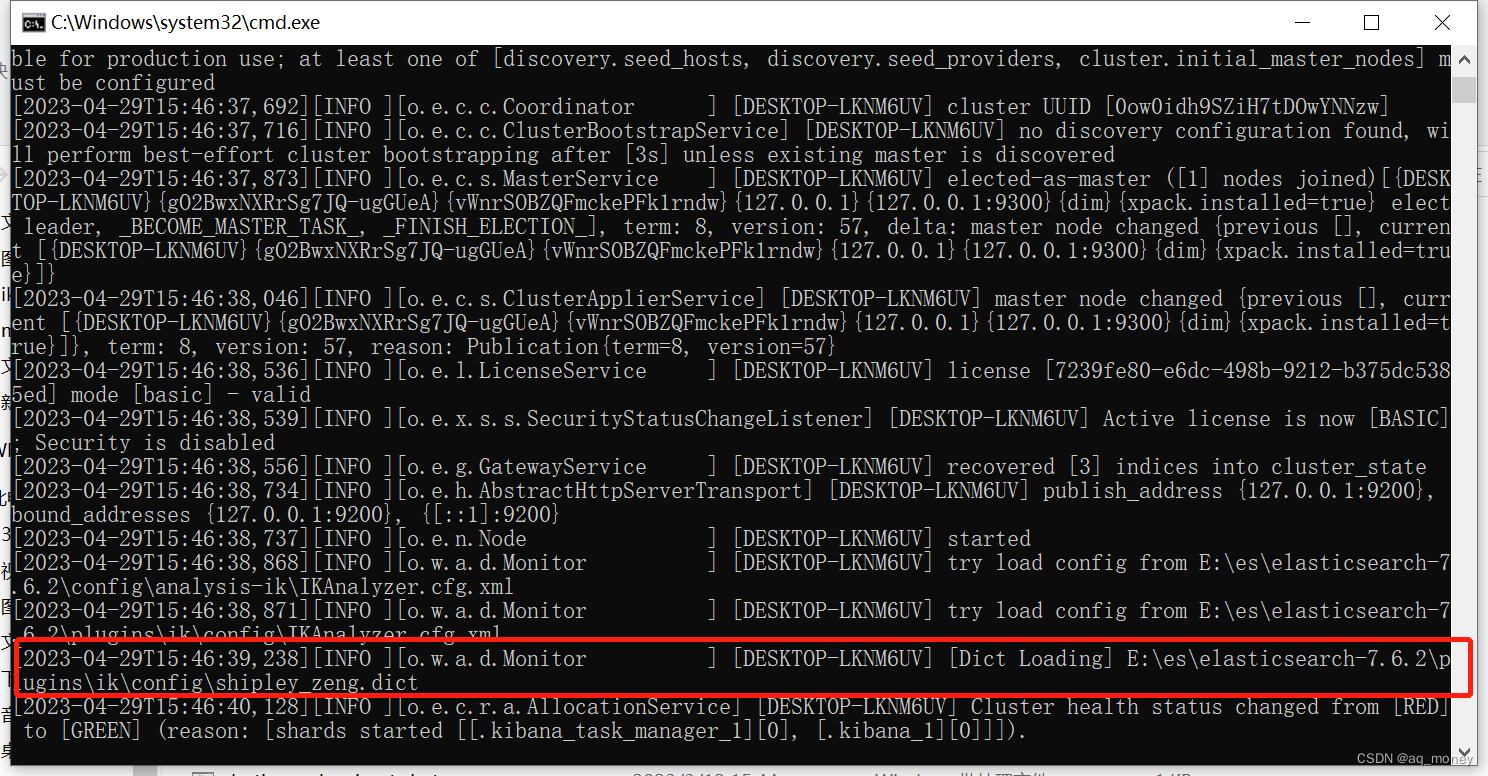
7、我们在使用 ik_max_word 最细粒度查询看看效果
GET /_analyze
{
"analyzer": "ik_max_word", // 最细粒度划分
"text": "曾舒琪董事长早上好"
}
执行结果如下:
{
"tokens" : [
{
"token" : "曾舒琪",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "舒琪",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "董事长",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "董事",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "长",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "早上好",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "早上",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "上好",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 7
}
]
}
8、使用 ik_smart 最粗粒度查询看看效果
GET /_analyze
{
"analyzer": "ik_smart", // 最粗粒度划分
"text": "曾舒琪董事长早上好"
}
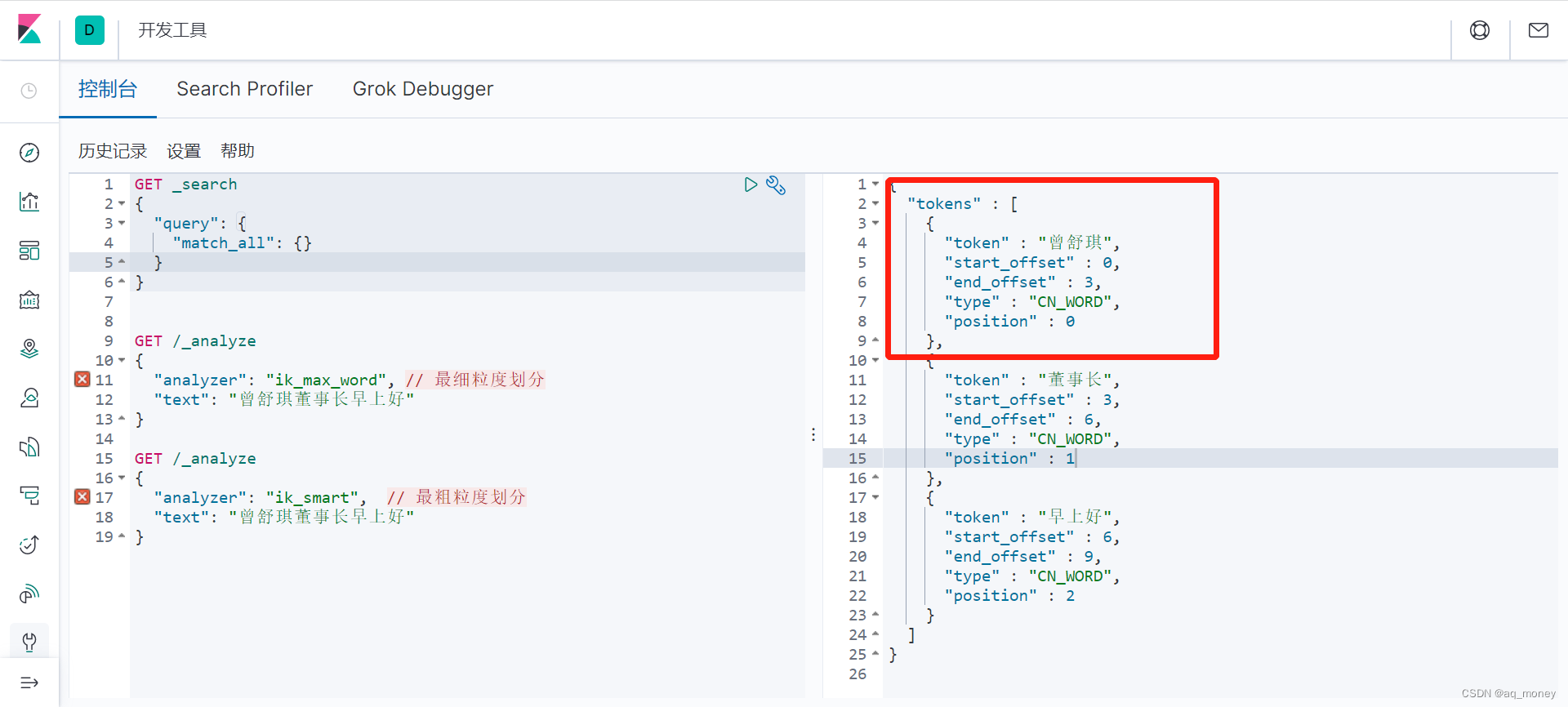
执行结果如下:
{
"tokens" : [
{
"token" : "曾舒琪",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "董事长",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "早上好",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 2
}
]
}
9、我们可以看见、现在不管使用ik_max_word还是ik_smart,他都能将曾舒琪这个词汇拆开组合,达到了我们所需要的诉求。
总结
以上就是本地elasticsearch中文分词器 ik分词器及使用,希望对刚刚接触es的小伙伴有所帮助,谢谢,如有疑问请随时联系我。