最近在做项目中,需要网页的大批数据,查询数据是一项体力劳动,原本的我

然而,奋斗了一天的我查到的数据却寥寥无几,后来的我是这样的

作为一个cv工程师,复制粘贴原本是一件很快乐的事情但是它缺给了我无尽的折磨,所以我利用4天时间查询各种资料,翻阅各种视频,终于了解了一个面向监狱编程 ------- python爬虫
在网上也没有明确的资料来介绍这方面的知识,所以我决定---------造福大众
其实我刚开始用java实现爬虫操作,但是java爬虫复杂的操作,深深的打击了我,听说python爬虫不仅操作简单而且库非常强大,作为一个python零基础的我,毅然决然的去学习python爬虫,结果也在意料之中,有编程基础得我学习python还是相对而言还是比较容易的,所以怎么样才能搭建一个scrapy框架呢?思来想去我总结了两点:
- 顺手的工具
- 基础的爬虫知识
工具: Pycharm(一个基于python语言的开发工具),但是相对于我们这种业余选手来说,社区版的功能我觉得已经足够我们自己使用了(爬虫功能)
基础的爬虫知识: python库的使用以及xpath等解析的用法(如果有需要,后期会发详细的xpath解析介绍)
库的安装:在python下的Scripts下安装对应的库 可以使用国内的镜像进行下载
pip install 库名 -i http://pypi.douban.com/simple
上才艺:
如何才能创建一个属于你自己的网络爬虫

- 创建爬虫文件(要在cmd控制面板进行操作)
注意:项目的名字不允许使用数字开头,同时也不能包括中文字符
cd 项目的名字\项目的名字\spidersscrapy genspider 爬虫的文件的名字 要爬取的网页(自动生成初始类)- 运行爬虫文件
scrapy crawl 爬虫文件-
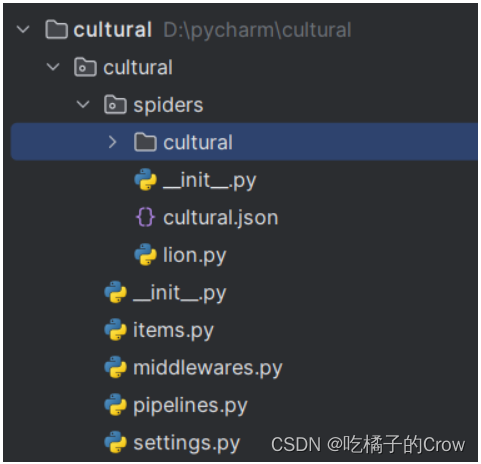
scrapy项目结构
项目的名字
项目的名字
spiders()(存储的是爬虫文件)
init
init
items 定义数据结构的地方,定义爬取的数据的属性(字段)
middleware 中间件 代理
piplines 管道 用来处理下载的数据
settings 配置文件 中间含有爬虫遵守的规则(roots协议) ua定义等- 常用方法
content = response.text //转字符串
content = response.body //二进制数据
response.extract() //提取seletor对象的data的属性值
response.extract_first() //提取seletor列表中的第一个数据
html = requests.get(url=url, headers=headers).text f = etree.HTML(html) //使得网页可以被xpath进行解析一个完整的爬虫案例(爬取非遗官网公告信息)
lion.py
import urllib.request
import requests
import scrapy
from lxml import etree
from cultural.items import CulturalItem
import time
import schedule
from datetime import datetime
from Scheduler import Scheduler
#如果想要多页进行下载,需要先观察每页之间发送的url有什么规律,然后模拟服务器进行发送请求
class LionSpider(scrapy.Spider):
name = "lion"
#允许通过地址的规则
allowed_domains = ["www.sxfycc.com"]
start_urls = ["https://www.sxfycc.com/portal/qwfb/index.html"]
base_urls = "https://www.sxfycc.com/portal/qwfb/index.html?page="
page = 1
def parse(self, response):
li_list = response.xpath("//ul[@class='fabu_list_box']/li")
for li in li_list:
# 获取题目
tltle = li.xpath(".//h2/strong/text()").extract_first()
#获取照片
npic = li.xpath(".//img/@src").extract_first()
#获取内容
content = li.xpath(".//p/text()").extract_first()
# 二级页面
url1 = li.xpath("./a/@href").extract_first()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58",
"Referer": "https://www.sxfycc.com/portal/qwfb/index.html",
"sec-ch-ua": "\"Chromium\";v=\"112\", \"Microsoft Edge\";v=\"112\", \"Not:A-Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0", "sec-ch-ua-platform": "\"Windows\""
}
url = "https://www.sxfycc.com/" + str(url1)
html = requests.get(url=url, headers=headers).text
f = etree.HTML(html)
contentone = f.xpath('//div[@class="news_xq"]//span/text()')
cultural = CulturalItem(title=tltle, npic=npic, content=content, contentone=contentone)
# 获取一个就将cultural对象交给管道
yield cultural
if self.page < 2:
self.page = self.page + 1
url = self.base_urls + str(self.page)
# 怎么调用parse方法
# scrapy.Request就是scrpay的get请求
# callback你要执行的那个函数,不需要加圆括号
yield scrapy.Request(url=url, callback=self.parse)pipelines.py:
import urllib.request
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import datetime
import random
from scrapy.utils.project import get_project_settings
import pymysql
#这样写不必写一次管道开关一次,有利用节约内存资源
class CulturalPipeline:
def open_spider(self, spider):
self.fp = open('cultural.json', 'w', encoding='utf8')
def process_item(self, item, spider):
#'a' 可以对内容进行追加
with open("cultural.json", "a", encoding='utf8') as fp:
fp.write(str(item))
def close_spider(self, spider):
self.fp.close()
# 下载图片的管道
class FeistyPicturePipeline:
def process_item(self, item, spider):
url = item.get('npic')
now = datetime.datetime.now()
year = now.year
month = now.month
day = now.day
hour = now.hour
second = now.second
reslut = str(year) + str(month) + str(day) + str(hour) + str(second) + str(random.randint(0, 10000))
filename = './cultural/' + reslut + '.jpg'
#通过url链接下载图片,并声明文件名字
urllib.request.urlretrieve(url=url, filename=filename)
return item
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_host']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
contentone=str(item.get('contentone')).strip("['''']")
sql = 'insert into cultural (title,content,npic,contentone,oper_time)values("{}","{}","{}","{}","{}")'.format(
item['title'], item['content'], item['npic'],contentone, datetime.datetime.now())
# 执行sql
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settongs.py:
BOT_NAME = "cultural"
SPIDER_MODULES = ["cultural.spiders"]
NEWSPIDER_MODULE = "cultural.spiders"
#只在控制台打印错误的信息
LOG_LEVEL = 'WARNING'
#创建管道并声明优先级
ITEM_PIPELINES = {
"cultural.pipelines.CulturalPipeline": 300,
"cultural.pipelines.FeistyPicturePipeline": 299,#优先级需要比CulturalPipeline低,不然会报错
"cultural.pipelines.MysqlPipeline": 100#优先级需要比CulturalPipeline低,不然会报错
}
#声明与数据库的连接
DB_host = '127.0.0.1' #ip地址
DB_PORT = 3306 #数据库端口号
DB_USER = 'root' #数据库用户名
DB_PASSWORD = 'root' #数据库密码
DB_NAME = "crawler" #数据库库名
# utf-8不允许写
DB_CHARSET = 'utf8' #"utf-8"要写成'utf8',数据库不识别-
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"items.py:
import scrapy
class CulturalItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#声明与数据库相同的字段
content = scrapy.Field()
npic = scrapy.Field()
title = scrapy.Field()
contentone = scrapy.Field()![【五一创作】[论文笔记]图片人群计数CSRNet,Switch-CNN](https://img-blog.csdnimg.cn/5abbde6b1cff4016a1f479272b588994.png)
![[遗传学]近亲繁殖与杂种优势](https://img-blog.csdnimg.cn/img_convert/55831ca4975f6d36dfbdc7eb4b06885d.png)