一、文本生成
我们在前面的文章中介绍了LSTM,根据输入时序数据可以输出下一个可能性最高的数据,如果应用在文字上,就是根据输入的文字,可以预测下一个可能性最高的文字。利用这个特点,我们可以用LSTM来生成文本。输入一个单词,做embedding处理后,再输入到LSTM,会输出备选单词的得分,经过softmax得到概率,我们选择概率最高的单词作为输出。这种输出叫做确定性输出,如下图所示:
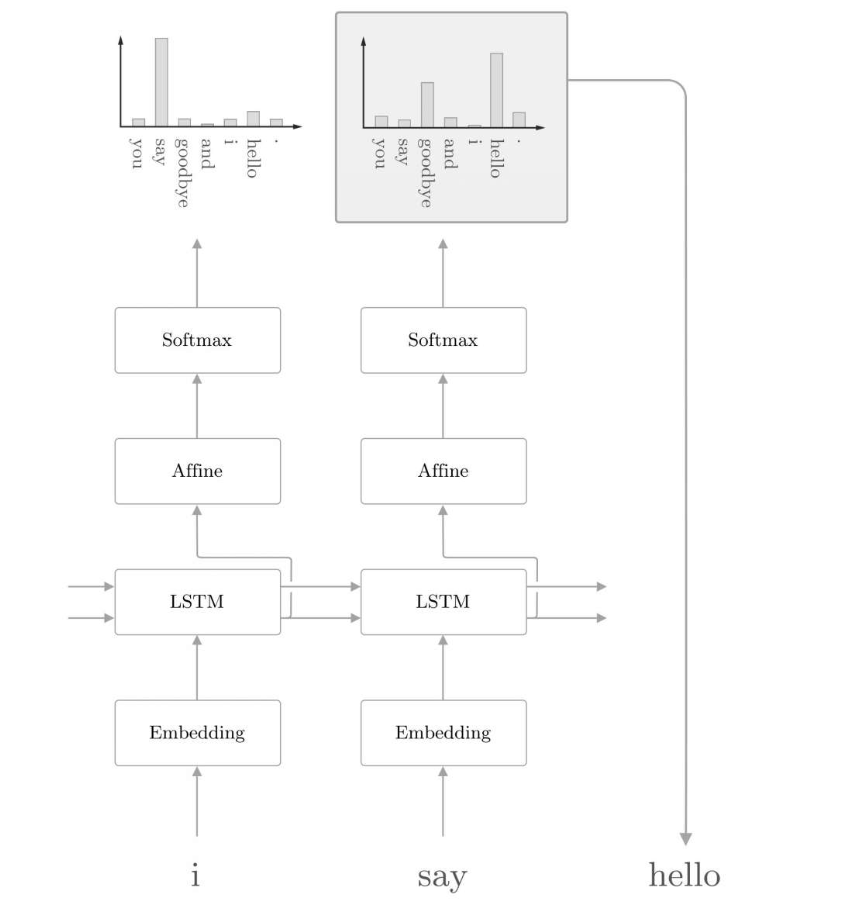
如果我们根据概率随机选择一个单词输出,这叫做概率性输出,类似于大语言模型中的temperature,当temperature高时,生成的变化越多,确定性越低。下面的代码是根据RNN模型生成文字的代码,其中start_id代表生成开始的第一个单词编号,skip_ids代表需要过滤的单词,比如空或者数字等等,sample_size代表采样大小,这里就是生成的单词的数量。
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id] # 最终的单词编号列表
x = start_id # 第一个单词编号
# 如果生成的单词列表长度还小于sample_size就继续生成
while len(word_ids) < sample_size:
# 转变shape便于输入模型
x = np.array(x).reshape(1,1)
# 根据模型预测输出单词得分
score = self.predict(x)
# 得到概率
p = softmax(score.flatten())
# 根据概率选择输出的单词编号
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
corpus, word_to_id, id_to_word = load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
# 设定start单词和skip单词
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N','<unk>','$']
skip_ids = [word_to_id[w] for w in skip_words]
# 生成文本
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join(id_to_word[i] for i in word_ids)
txt = txt.replace(' <eos>','.\n')
print(txt)
# 输出:
you freshman retreat teeth instantly enhanced university brands exceptionally affiliates
various unfair leslie our assumes studies begin monitored bart leap reasonably gary poorer
industry southeast cemetery tables epo supportive nervous sooner inc soybeans scientific
expertise applying lufthansa introduction leventhal casting lights carries feared revamping
solar sachs widen training reins moves industrials technologies extent diagnostic narcotics
regularly literally hanover primarily reinsurance pro-life serve specifications fm jumbo
penalty actions l.p. ann keenan princeton despite stuart arise instrumentation classic exposed
violation dishonesty warner-lambert nicaragua infringed fantasy marcus portrait imported jordan
spurring component perestroika undo remic sacrifice veterans arms-control postal relying
homelessness quack voters可以看到输出的文字几乎没有什么含义,这是因为我们使用的模型是原始的LSTM,没有经过训练,如果我们加载了上篇文字训练过后的模型BetterRnnlm后,效果会有明显提升。
... ...
model = RnnlmGen()
model.load_params('Rnnlm.pkl')
... ...
# 输出:
you place a short part of their nation 's relatively rumored air.
far everyone agreed and yet as out next is a market to insist in out of wohlstetter
is violates that on why it took the max for one. a caution on a chiefs of substantial
chips three-year firstsouth in the ratio for candidates more investors the tax in
medical lawsuits will be something about three to government simultaneous.
a new market will n't be surprising these specify must very be exactly like economic
houses to manufacturers competitors where he adds some error in not new二、序列到序列模型
用RNN生成文本,还有一种更通用的用法,称为序列到序列的模型,也就是sequence to sequence。最典型的seq2seq应用就是机器翻译,输入一串用某种语言表示的文字,输出用另一种文字表示的文字。另外典型的应用包括:
自动摘要,它是输入一个长文本,输出一个表达核心含义的短文本;
问答系统:输入一个问题文本,输出一个答案文本;
聊天机器人:输入人类的文本,输出机器的文本;
算法学习:输入一串算法描述,输出计算答案;
图像文字生成:输入图像,这里图像也可以通过CNN等网络表示成一串向量,输出描述图像的文字;
可以看出,seq2seq可以有两个模块构成,一个模块处理输入文本,一个模块生成输出文本,处理输入文本的模块我们称为Encoder,生成文本的模块我们称为Decoder。一般来说,一个seq2seq就是由一个Encoder和一个Decoder合并在一起得到的。以书中的例子,日语翻译成英语为例的话,流程图如下:
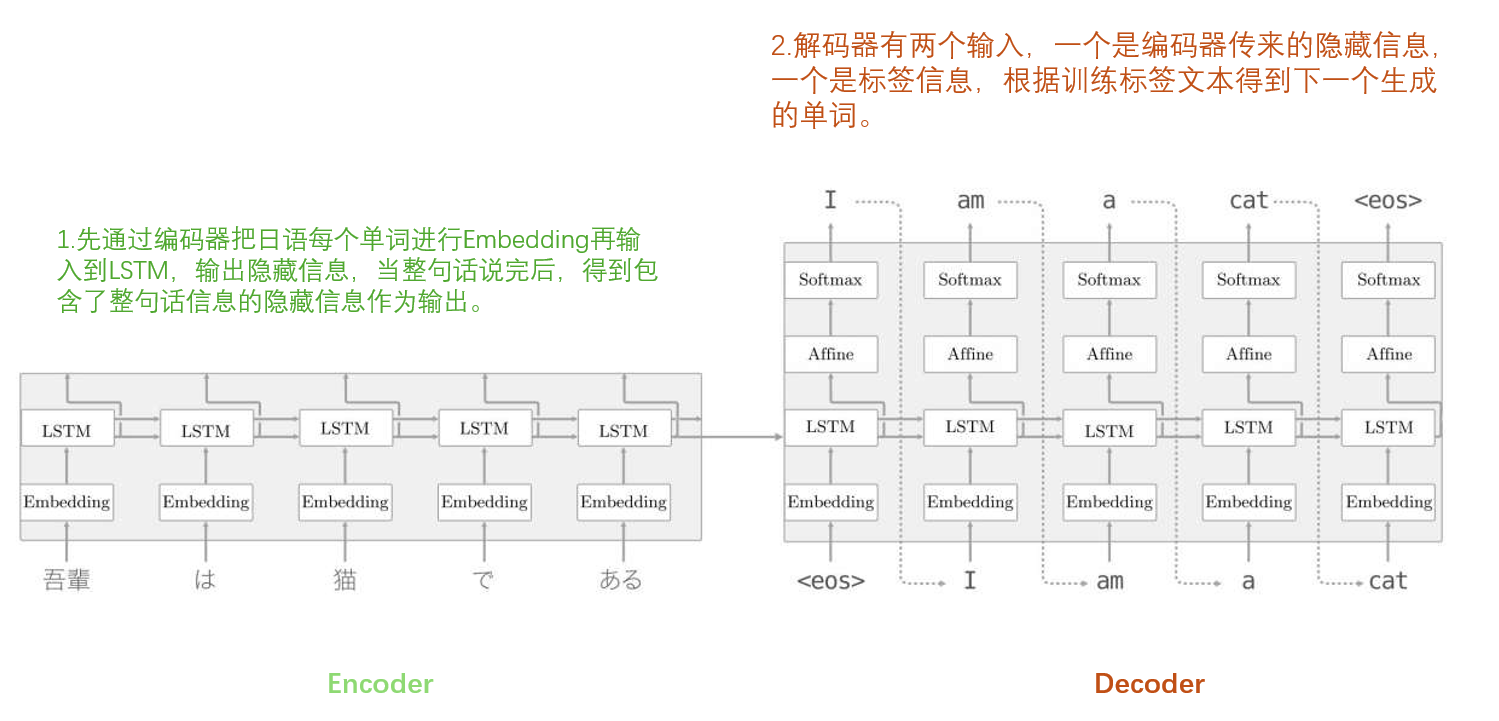
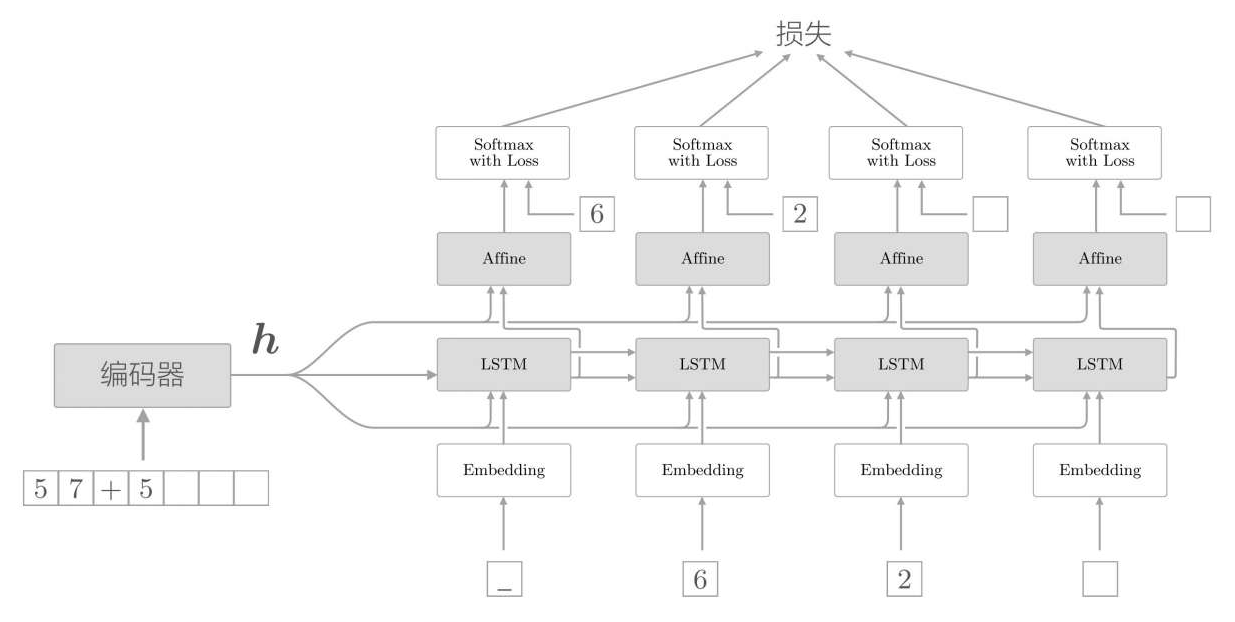
下面我们以模拟一个加法的学习来实现这个seq2seq模型。这个模型的输入是一个三位数字以内的加法表达式,如“32+100”,输出是运算的结果,如“132”,编码器对“32+100”这个表达式拆分成“3”,“2”,“+”,“1”,“0”,“0”等几个字符,作为文本输入到编码器,得到隐藏信息,解码器输入隐藏信息以及“1”,“3”,“2”作为标签值,得到输出值,将输出值与“1”,“3”,“2”比较,得到损失,进行反向传播,实现整个训练过程。
不过这里有几个需要注意的地方:因为输入到编码器中的加法表达式长度可能不同,所以需要解决这个问题,最方便的方法是padding,也就是在表达式的前后插入填充字符。如:
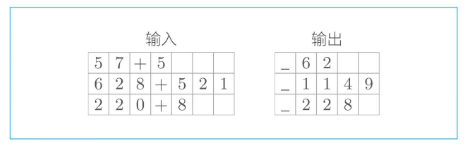
总体流程如下图所示。训练的时候采用编码器和解码器训练,实际使用中,把编码器得到的隐藏信息输出到生成器,生成结果。

代码实现是基于之前的LSTM代码基础之上的,其实和LSTM的代码构建有很多类似的地方,编码器基本就是一个普通的LSTM,编码器代码:
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D,4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H,4*H)/np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful = False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self,xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return self.hs[:,-1,:]
def backward(self,dh):
dhs = np.zeros_like(self.hs)
dhs[:,-1,:] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout解码器和编码器的区别就在于,解码器还要多输入一个隐藏信息,并且正向传播输出多一个打分步骤。generate是实际生成文本结果的函数,和前面所述生成文本的区别在于,这里是生成加法结果的,所以不用概率性输出,而采用确定性输出,就是用argmax选择得分最高的输出,解码器代码:
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D,4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H,4*H)/np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H,V)/np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful = True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1,1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled基于上述编码器和解码器,构建seq2seq模型:
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V,D,H)
self.decoder = Decoder(V,D,H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
# 样本从开始到倒数第二个,标签从第1个开始到最后一个
decoder_xs, decoder_ts = ts[:,:-1], ts[:,1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled采用该模型训练25个epoch后,预测精确度约在11%左右。一个改进办法是,将输入的表达式反转:
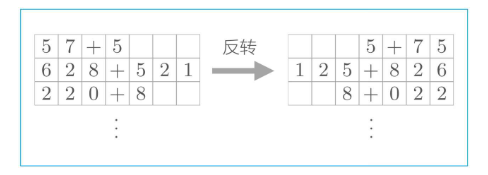
另一个改进方法是Peeky,它的特点就是把编码器传过来的隐藏信息,都输入到解码器的每个节点中,而之前只有解码器的第一个节点接收编码器传过来的隐藏信息。
训练代码如下(完整代码可以参考书的附带源代码):
# 读入数据集
(x_train,t_train),(x_test,t_test) = load_data('addition.txt', seed=1984)
char_to_id, id_to_char = get_vocab()
x_train, x_test = x_train[:,::-1], x_test[:,::-1] # 反转
# 设定超参数
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
# 生成模型/优化器/训练器
model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct, id_to_char, verbose)
acc = float(correct_num)/len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc*100))
acc_list3 = acc_list
plt.plot([i for i in range(max_epoch)], [acc*100 for acc in acc_list3], label='peeky+reverse', c='r',linestyle='--',marker='o')
plt.plot([i for i in range(max_epoch)], [acc*100 for acc in acc_list2], label='reverse', c='y',linestyle='-.',marker='>')
plt.plot([i for i in range(max_epoch)], [acc*100 for acc in acc_list1], label='original', c='g',linestyle=':',marker='*')
plt.xlabel('iterations')
plt.ylabel('accuracy')
plt.legend()
plt.show()这里,我稍微修改了一下书中代码,我把三个精度图放在一起比较了。acc_list1代表原始seq2seq模型的训练精度,acc_list2代表输入反转后的模型训练精度,acc_list3代码输入反转并且加入Peeky后的模型训练精度。
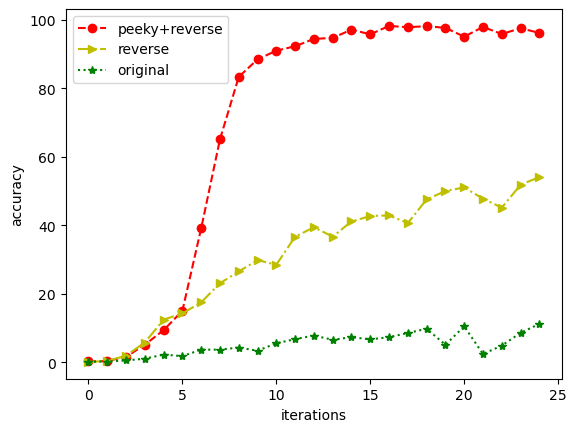
可以看到,原始的seq2seq模型在训练25个epoch后,精度大约11%,反转输入后,训练精度大概55%,再加入Peeky后,精度已经非常接近100%了,一般可以达到96%~98%之间。