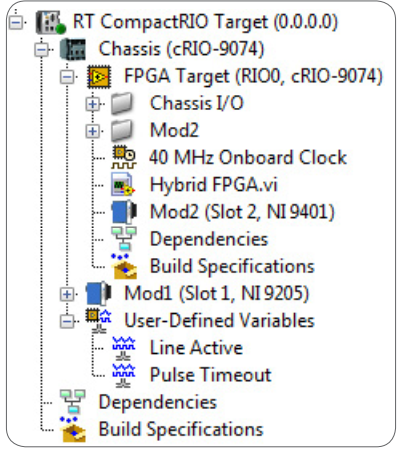
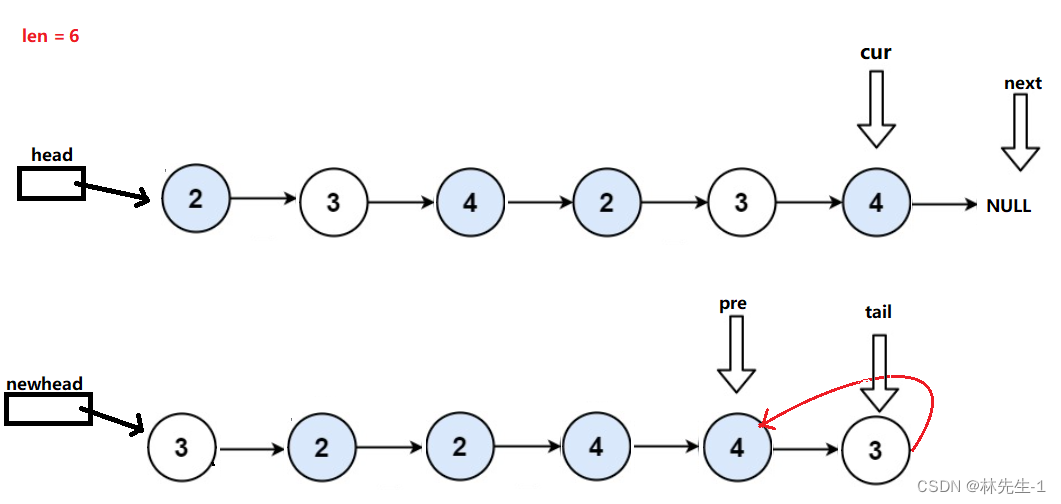
重要性采样(importance sampling)是一种用于估计概率密度函数期望值的常用蒙特卡罗积分方法。其基本思想是利用一个已知的概率密度函数来生成样本,从而近似计算另一个概率密度函数的期望值。
想从复杂概率分布中采样的一个主要原因是能够使用式(11.1)计算期望。重要采样(importance sampling)的方法提供了直接近似期望的框架,但是它本身并没有提供从概率分布
p
(
z
)
p(z)
p(z)中采样的方法,也就是我们无法从式(11.1)直接过渡到(11.2)
E
[
f
]
=
∫
f
(
z
)
p
(
z
)
d
z
(11.1)
\mathbb{E}[f] = \int f(z)p(z)dz \tag{11.1}
E[f]=∫f(z)p(z)dz(11.1)
f
^
=
1
L
∑
l
=
1
L
f
(
z
(
l
)
)
(11.2)
\hat{f} = \frac{1}{L}\sum\limits_{l=1}^L f(z^{(l)}) \tag{11.2}
f^=L1l=1∑Lf(z(l))(11.2)公式(11.2)给出的期望的有限和近似依赖于能够从概率分布
p
(
z
)
p(z)
p(z)中采样。然而,假设直接从
p
(
z
)
p(z)
p(z)中采样无法完成,但是对于任意给定的
z
z
z值,我们可以很容易地计算
p
(
z
)
p(z)
p(z)。一种简单的计算期望的方法是将
z
z
z空间离散化为均匀的格点,将被积函数使用求和的方式计算,形式为
E
[
f
]
≃
∑
l
=
1
L
p
(
z
(
l
)
)
f
(
z
(
l
)
)
\mathbb{E}[f] \simeq \sum\limits_{l=1}^Lp(z^{(l)})f(z^{(l)})
E[f]≃l=1∑Lp(z(l))f(z(l))这种方法的一个明显的问题是求和式中的项的数量随着
z
z
z的维度指数增长。此外,正如我们已经注意到的那样,我们感兴趣的概率分布通常将它们的大部分质量限制在
z
z
z空间的一个很小的区域,因此均匀地采样非常低效,因为在高维的问题中,只有非常小的一部分样本会对求和式产生巨大的贡献。我们希望从
p
(
z
)
p(z)
p(z)的值较大的区域中采样,或理想情况下,从
p
(
z
)
f
(
z
)
p(z)f(z)
p(z)f(z)的值较大的区域中采样。
与拒绝采样的情形相同,重要采样基于的是对提议分布 q ( z ) q(z) q(z)的使用,我们很容易从提议分布中采样,如下图所示:

重要采样解决的是计算函数 f ( z ) f(z) f(z)关于分布 p ( z ) p(z) p(z)的期望的问题,其中,从 p ( z ) p(z) p(z)中直接采样比较困难。相反,样本 z ( l ) {z^{(l)}} z(l)从一个简单的概率分布 q ( z ) q(z) q(z)中抽取,求和式中的对应项的权值为 p ( z ( l ) ) / q ( z ( l ) ) p(z^{(l)})/q(z^{(l)}) p(z(l))/q(z(l)),这样就可以还原到从 p ( z ) p(z) p(z)中取样。
上述过程中的式子,我们可以通过
q
(
z
)
q(z)
q(z)中的样本
{
z
(
l
)
}
\{z^{(l)}\}
{z(l)}的有限和的形式来表示期望
E
=
∫
f
(
z
)
p
(
z
)
d
z
=
∫
f
(
z
)
p
(
z
)
q
(
z
)
q
(
z
)
d
z
≃
1
L
∑
l
=
1
L
p
(
z
(
l
)
)
q
(
z
(
l
)
)
f
(
z
(
l
)
)
\mathbb{E} = \int f(z)p(z)dz \ = \int f(z)\frac{p(z)}{q(z)}q(z)dz \ \simeq \frac{1}{L}\sum\limits_{l=1}^L\frac{p(z^{(l)})}{q(z^{(l)})}f(z^{(l)})
E=∫f(z)p(z)dz =∫f(z)q(z)p(z)q(z)dz ≃L1l=1∑Lq(z(l))p(z(l))f(z(l))其中
r
l
=
p
(
z
(
l
)
)
/
q
(
z
(
l
)
)
r_l = p(z^{(l)}) / q(z^{(l)})
rl=p(z(l))/q(z(l))被称为重要性权重(importance weights),修正了由于从错误的概率分布
q
(
z
)
q(z)
q(z)中采样引入的偏差。
对于上述过程,举个栗子:
我们的待计算函数为 h ( x ) = e − 2 ∣ x − 5 ∣ h(x)=e^{-2|x-5|} h(x)=e−2∣x−5∣,待采样分布为 p ( x ) = 1 10 , x ∼ u ( 0 , 10 ) p(x)=\dfrac{1}{10} ,x \sim\mathcal{u}(0,10) p(x)=101,x∼u(0,10),从 h ( x ) h(x) h(x)的图像中明显可以看出,在中间部分的 h ( x ) p ( x ) h(x)p(x) h(x)p(x)对期望贡献较大,而两边几乎可以忽略不计,所以此时使用均匀分布采样并不合理。

基于此,我们引入了新的采样分布函数 q ( x ) = 1 2 π e − ( x − 5 ) 2 2 q(x)=\dfrac{1}{\sqrt{2\pi}}e^{-\frac{(x-5)^2}{2}} q(x)=2π1e−2(x−5)2

这使得在
h
(
x
)
h(x)
h(x)较大的位置取值更多,需要的采样点更少。
而更常见的情形是,概率分布
p
p
p的计算结果没有标准化,也就是
p
(
z
)
=
p
~
(
z
)
/
Z
p
p(z) = \tilde{p}(z) / Z_p
p(z)=p~(z)/Zp中我们只知道
p
~
(
z
)
\tilde{p}(z)
p~(z),其中
p
~
(
z
)
\tilde{p}(z)
p~(z)可以很容易地由
z
z
z计算出来(可能没有函数表达式),而
Z
p
Z_p
Zp未知(
p
~
(
z
)
\tilde{p}(z)
p~(z)无法积分算)。类似的,我们可能希望使用重要采样分布
q
(
z
)
=
q
~
(
z
)
/
Z
q
q(z) = \tilde{q}(z) / Z_q
q(z)=q~(z)/Zq中的
q
~
(
z
)
\tilde{q}(z)
q~(z),它具有相同的性质。于是我们得到:
E
[
f
]
=
∫
f
(
z
)
p
(
z
)
d
z
=
Z
q
Z
p
∫
f
(
z
)
p
~
(
z
)
q
~
(
z
)
q
(
z
)
d
z
≃
Z
q
Z
p
1
L
∑
l
=
1
L
r
~
l
f
(
z
(
l
)
)
\mathbb{E}[f] = \int f(z)p(z)dz \ = \frac{Z_q}{Z_p}\int f(z)\frac{\tilde{p}(z)}{\tilde{q}(z)}q(z)dz \ \simeq \frac{Z_q}{Z_p}\frac{1}{L}\sum\limits_{l=1}^L\tilde{r}_lf(z^{(l)})
E[f]=∫f(z)p(z)dz =ZpZq∫f(z)q~(z)p~(z)q(z)dz ≃ZpZqL1l=1∑Lr~lf(z(l))
其中
r
~
l
=
p
~
(
z
(
l
)
)
/
q
~
(
z
(
l
)
)
\tilde{r}_l = \tilde{p}(z^{(l)}) / \tilde{q}(z^{(l)})
r~l=p~(z(l))/q~(z(l))。
我们还可以使用同样的样本集合来计算比值
Z
p
/
Z
q
Z_p / Z_q
Zp/Zq,结果为:
Z
p
Z
q
=
1
Z
q
∫
p
~
(
z
)
d
z
=
∫
p
~
(
z
)
q
~
(
z
)
q
(
z
)
d
z
≃
1
L
∑
l
=
1
L
r
~
l
\frac{Z_p}{Z_q} = \frac{1}{Z_q}\int\tilde{p}(z)dz = \int\frac{\tilde{p}(z)}{\tilde{q}(z)}q(z)dz \ \simeq \frac{1}{L}\sum\limits_{l=1}^L\tilde{r}_l
ZqZp=Zq1∫p~(z)dz=∫q~(z)p~(z)q(z)dz ≃L1l=1∑Lr~l
第一个等式中 Z p Z_p Zp用 ∫ p ~ ( z ) d z \int\tilde{p}(z)dz ∫p~(z)dz等价计算了出来,第二个等式中 Z q Z_q Zq用 q ( z ) = q ~ ( z ) / Z q q(z) = \tilde{q}(z) / Z_q q(z)=q~(z)/Zq替代
因此:
E
[
f
]
≃
∑
l
=
1
L
w
l
f
(
z
(
l
)
)
\mathbb{E}[f] \simeq \sum\limits_{l=1}^Lw_lf(z^{(l)})
E[f]≃l=1∑Lwlf(z(l))其中:
w
l
=
r
~
l
∑
m
r
~
m
=
p
~
(
z
(
l
)
)
/
q
(
z
(
l
)
)
∑
m
p
~
(
z
(
l
)
)
/
q
(
z
(
l
)
)
w_l = \frac{\tilde{r}_l}{\sum_m\tilde{r}_m} = \frac{\tilde{p}(z^{(l)})/q(z^{(l)})}{\sum_m\tilde{p}(z^{(l)})/q(z^{(l)})}
wl=∑mr~mr~l=∑mp~(z(l))/q(z(l))p~(z(l))/q(z(l))
这也就是我们最终要找样本点计算的式子
最终,我们达到了“利用一个已知的概率密度函数
q
(
z
)
q(z)
q(z)来生成样本,从而近似计算另一个概率密度函数的期望值
E
[
f
]
=
∫
f
(
z
)
p
(
z
)
d
z
\mathbb{E}[f] = \int f(z)p(z)dz
E[f]=∫f(z)p(z)dz”这一目的。
参考:
- 【PRML】【模式识别和机器学习】【从零开始的公式推导】11.1.4重要性采样 11.1.5采样-重要性-重采样 11.1.6采样与EM算法
- Importance Sampling - VISUALLY EXPLAINED with EXAMPLES!