文章题目:Self-supervised Point Cloud Representation Learning via Separating Mixed Shapes
作者:Chao Sun, Zhedong Zheng, Xiaohan Wang, Mingliang Xu and Yi Yang
论文链接:https://www.zdzheng.xyz/files/TMM_3D_Pre_Training.pdf
代码链接:GitHub - cyysc1998/3D-Pretraining: Self-supervised Point Cloud Representation Learning via Separating Mixed Shapes
摘要:
大规模点云的手动注释需要花费大量时间,并且在恶劣的现实世界场景中通常不可用。 受视觉和语言任务中预训练和微调范式取得巨大成功的启发,我们认为预训练也是获得 3D 点云下游任务的可扩展模型的一种潜在解决方案。 因此,在本文中,我们探索了一种新的自监督学习方法,称为混合和分离 (MD),用于 3D 点云表示学习。 顾名思义,我们混合两个输入形状并要求模型学习将输入与混合形状分开。 我们利用这个重建任务作为自我监督学习的借口优化目标。 有两个主要优点:
1)与流行的图像数据集(例如 ImageNet)相比,点云数据集实际上很小。 混合过程可以提供更大的在线训练样本池。
2)另一方面,解耦过程(Disentangle)促使模型挖掘几何先验知识,例如关键点。
为了验证所提出借口任务的有效性,我们构建了一个基线网络,该网络由一个编码器和一个解码器组成。 在预训练期间,我们混合两个原始形状并从编码器获得几何感知嵌入,然后应用实例自适应解码器从嵌入中恢复原始形状。 尽管简单,但预训练编码器可以捕获看不见的点云的关键点,并在下游任务上超越从头开始训练的编码器。 所提出的方法在点云分类和分割任务方面提高了 ModelNet-40 和 ShapeNet-Part 数据集的经验性能。 我们进一步进行消融研究以探索每个组件的效果,并通过利用不同的主干来验证我们提出的策略的泛化。
Motivation:
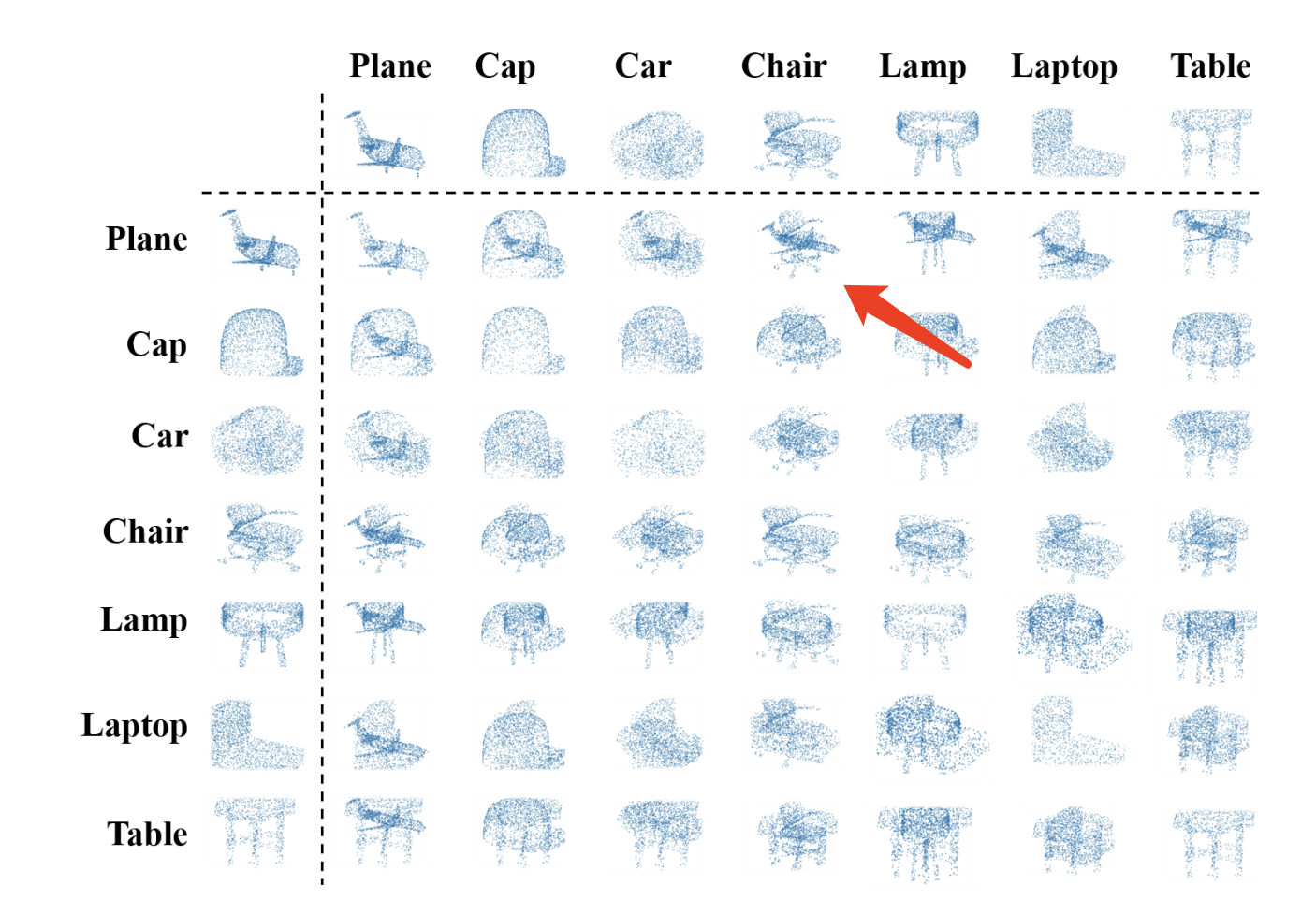
我们的出发点其实很简单,如下图 红色箭头所指的 混合点云,我们很容易就能看出 他是由 飞机(Plane) 和 椅子(Chair) 混合而成。甚至我们可以看出 哪些点 是来自于 飞机 , 哪些点来自于 椅子。
What:
基于这种观察,我们很自然的提出一个拆玩具的任务,网络需要能区分 一个 混合的点云中 那些点 是来自 点云A,哪些是来自点云B。因为 我们 人 也可以做到。
在这个区分的过程中,网络需要理解一些(1)高层的语义,AB分别是什么,来帮助 区分; (2)寻找到一些keypoints,来区分两个原始点云。
How:
其实encoder很容易理解,用一个传统的PointNet 或者 DGCNN都行。
Decoder的话,设计类似于 拼乐高的过程,我们可以看一个成品图(condition),就能拼出一个3D模型。

所以我们提出给一个 2D projection给 Decoder 作为condition,让他知道 如果遇到A的投影,就decode A的点云(红色虚线);如果 遇到B的投影,就重构 B的 点云(蓝色虚线) ,如下图。
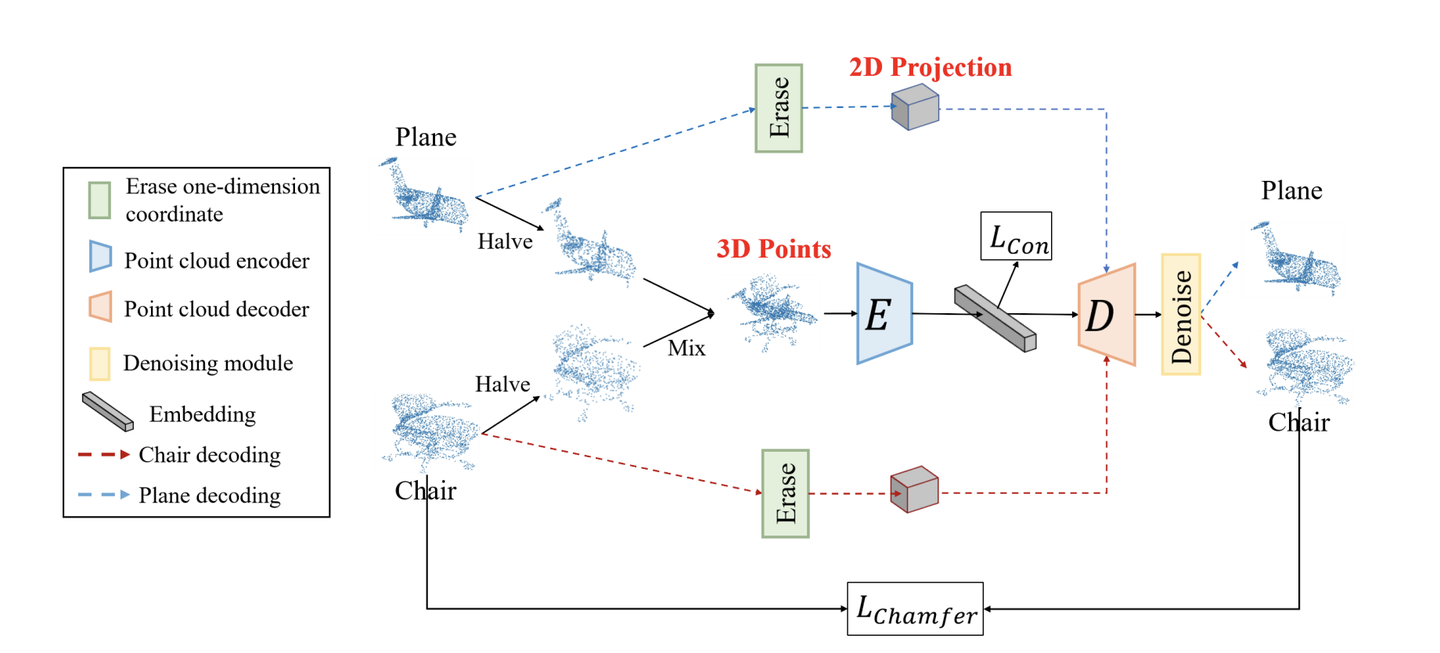
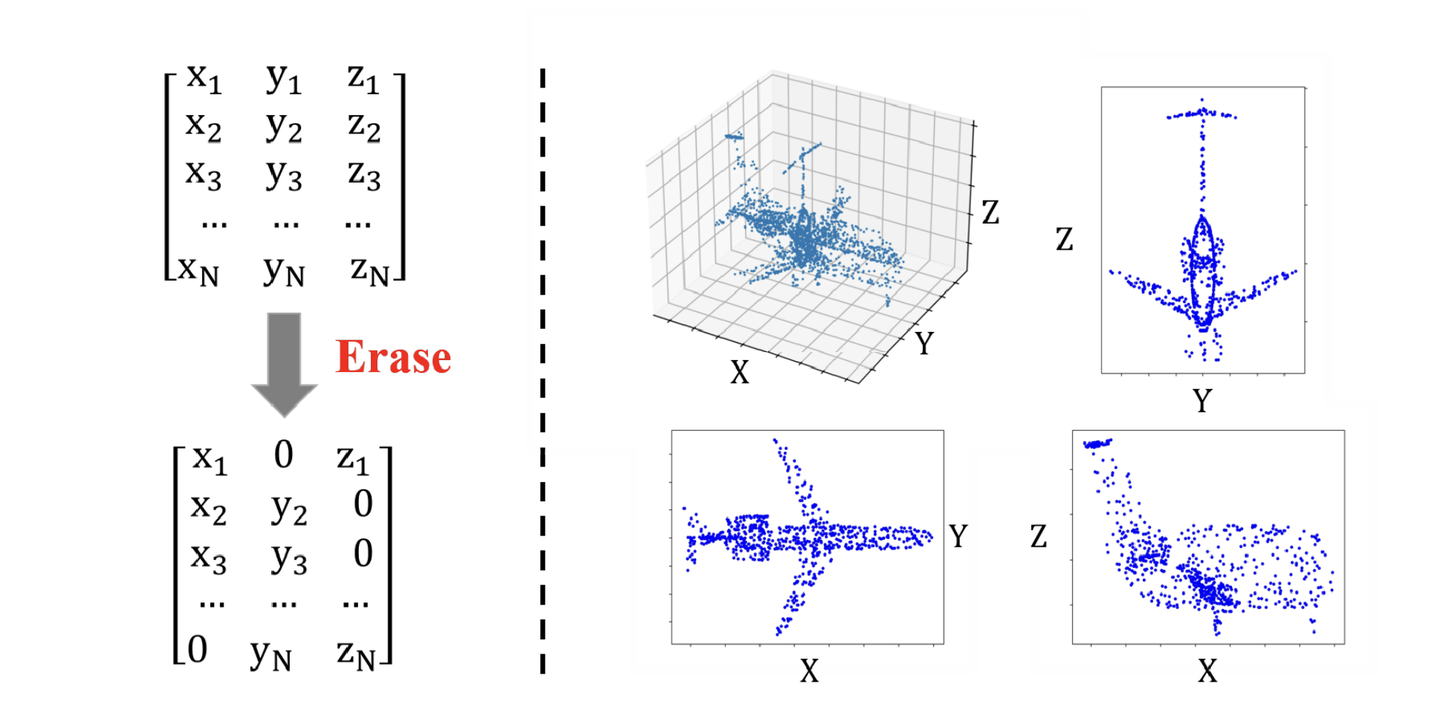
投影的话 可以选择 XY平面,YZ平面 或者 XZ平面 如下图,同时我们还会 擦除一些信息,提升难度。
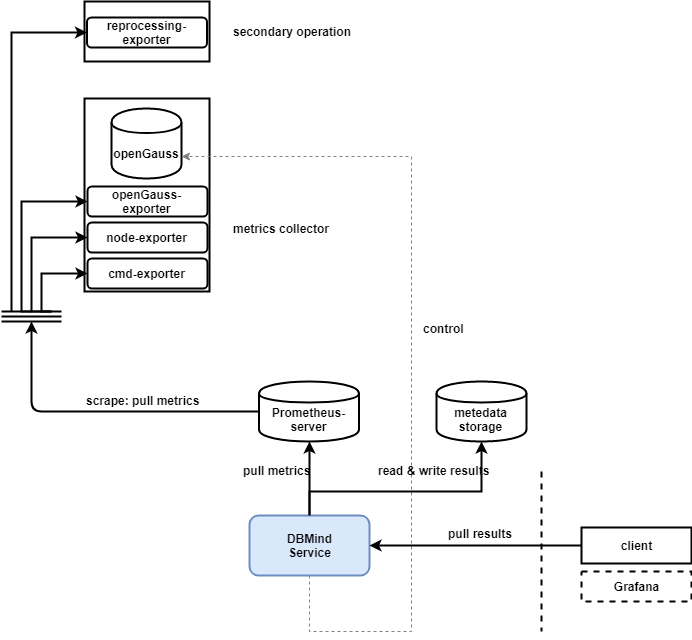
Ok 所以具体最后的模型 如下图。预训练的时候我们需要decoder,训练完 finetune下游任务,我们只要保留encoder就行。
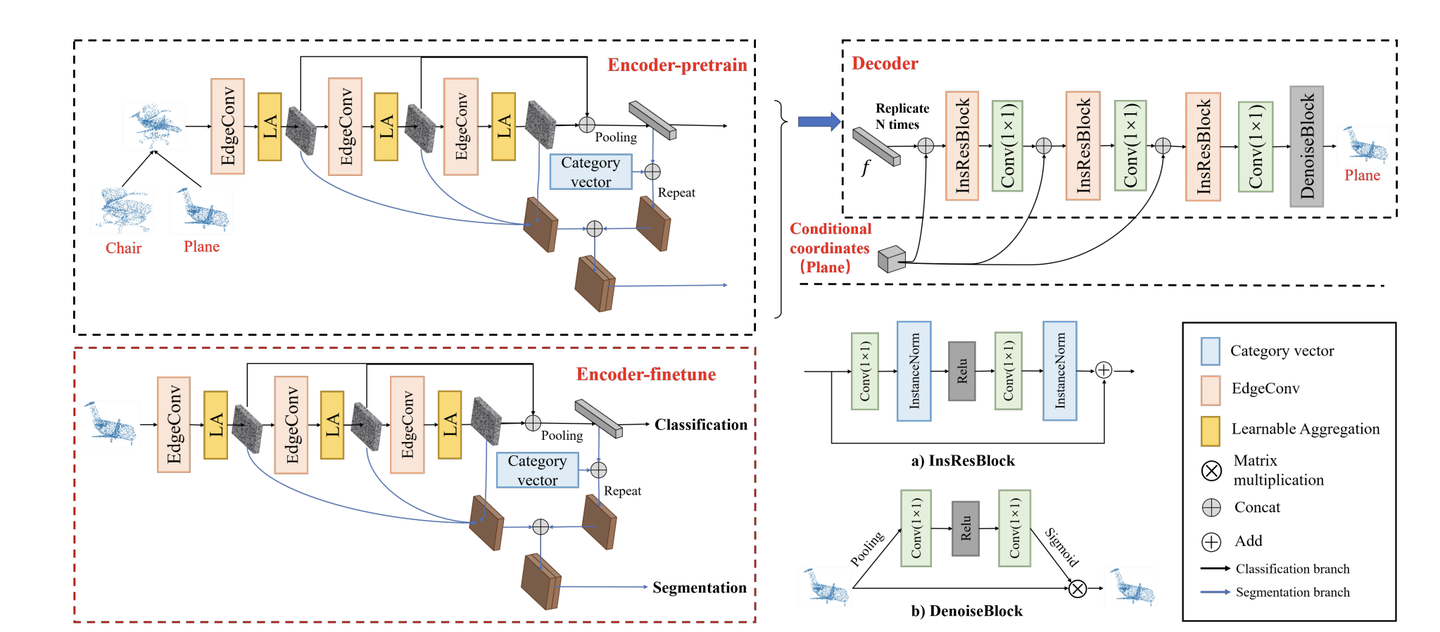
我们的方法可以做 点云分类,也可以做点云分割。
在Loss,方面我们用传统的点云重构loss,Chamfer loss就行 。
实验:
-
定量实验:
-
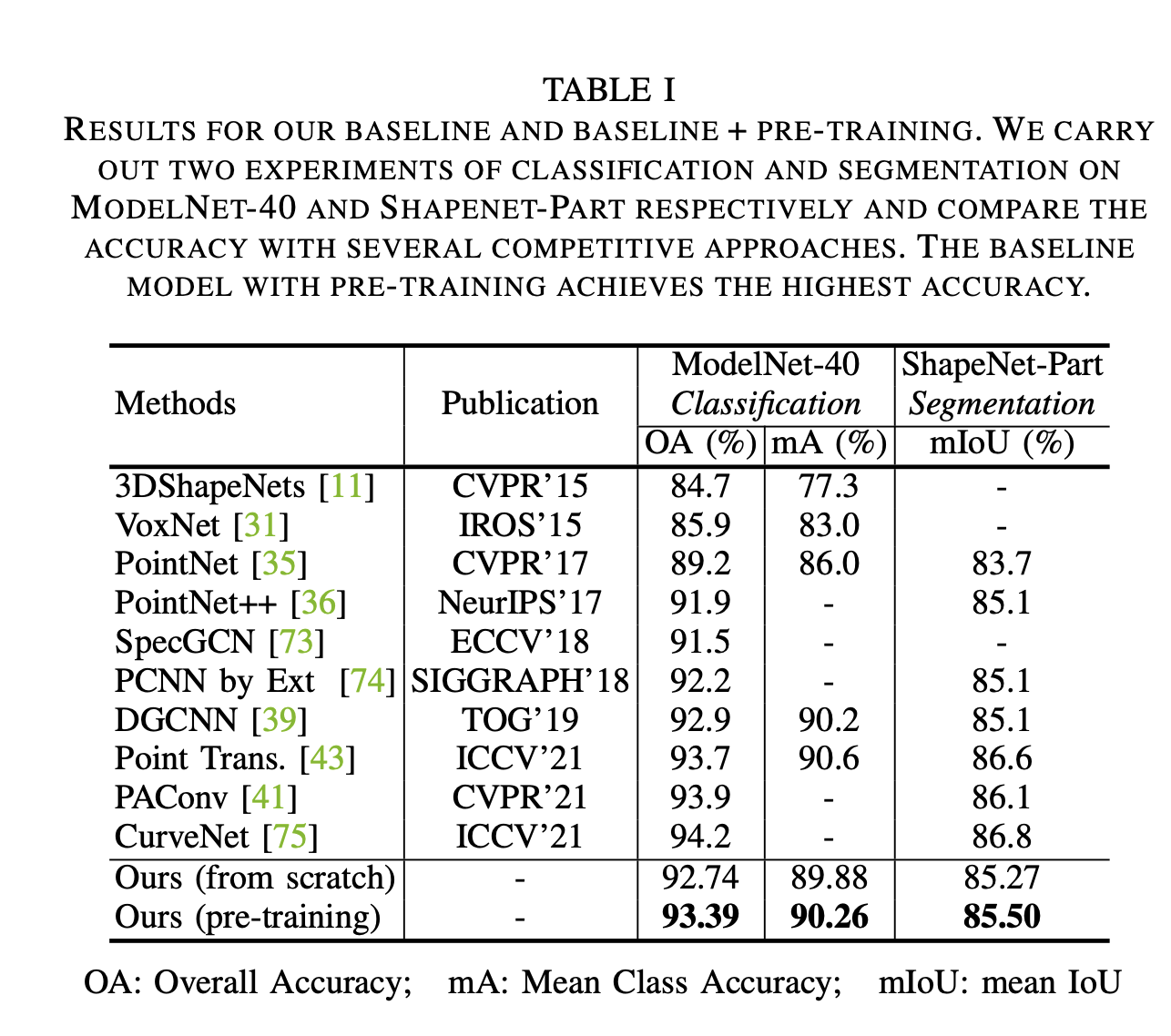
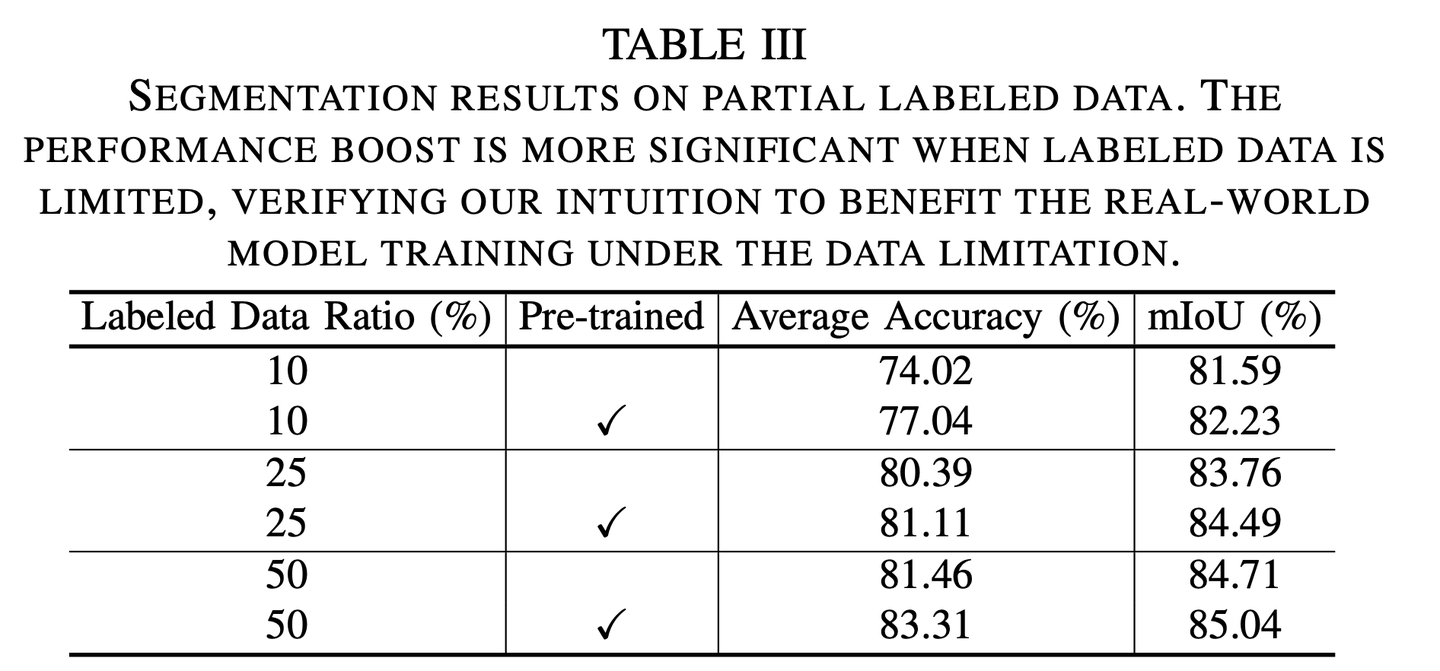
基于我们的模型做了一些finetune,可以在下游任务上得到较好的提升。
-
特别是下游标注数据量比较少的时候,预训练带来的好处越明显。
2.定性实验
-
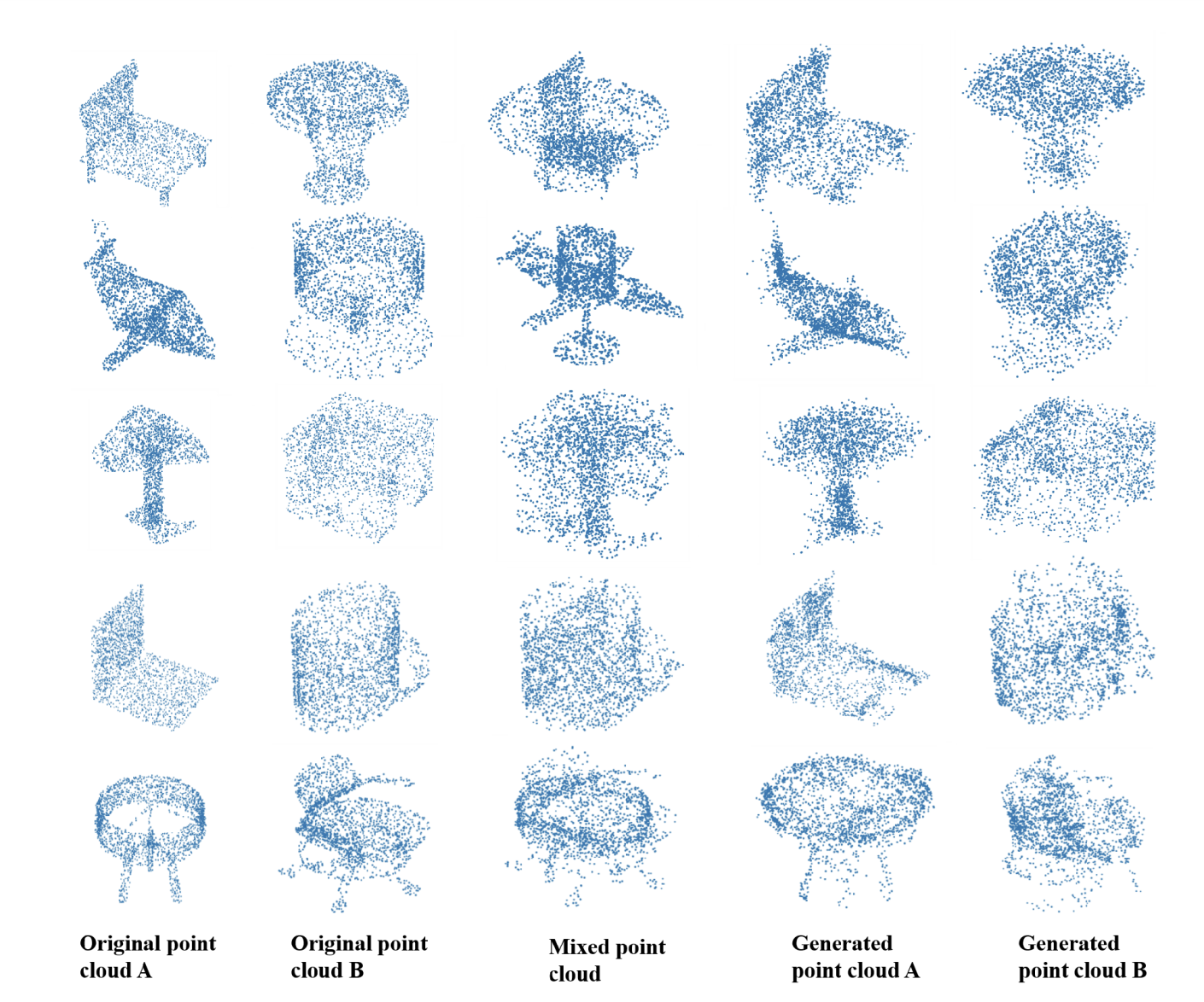
训练后我们确实观察到网络可以轻松分离两个点云,如下图。
-
我们还尝试可视化 ,encoder 特征中 激活值最大的前25%的点(红色)。可见网络抓到一些边缘的点(对结构理解最有帮助的点)。

感谢您看完,欢迎点赞分享收藏,以及关注我们的一些其他工作。
郑哲东:ACM MM23 Workshop|多媒体+无人机 - 知乎

郑哲东:TOMM | 用CNN分100,000类图像 - 知乎

郑哲东: TOMM | 用CNN分100,000类图像 - 知乎