从红帽 Ceph 存储 3.0 开始,红帽增加了对 容器化存储守护进程 (CSD),允许软件定义的存储组件(Ceph MON、OSD、MGR、RGW 等)在容器内运行。CSD 避免了存储服务专用节点的需要,从而通过共置存储容器化守护程序来降低资本支出和运营支出。
Ceph-Ansible 提供了将资源屏蔽到每个存储容器所需的机制,这对于在一个物理节点上运行多个存储守护程序容器非常有用。在这篇博文中,我们将介绍部署 RGW 容器的策略及其资源大小调整指南。在我们深入研究性能之前,让我们了解部署 RGW 的不同方法。
共址 RGW
-
RGW不需要专用节点(可以降低资本支出和运营支出)。
-
Ceph RGW 容器的单个实例放置在与其他存储容器共同驻留的存储节点上。
-
从 Ceph Storage 3.0 开始,这是部署 RGW 的首选方法。
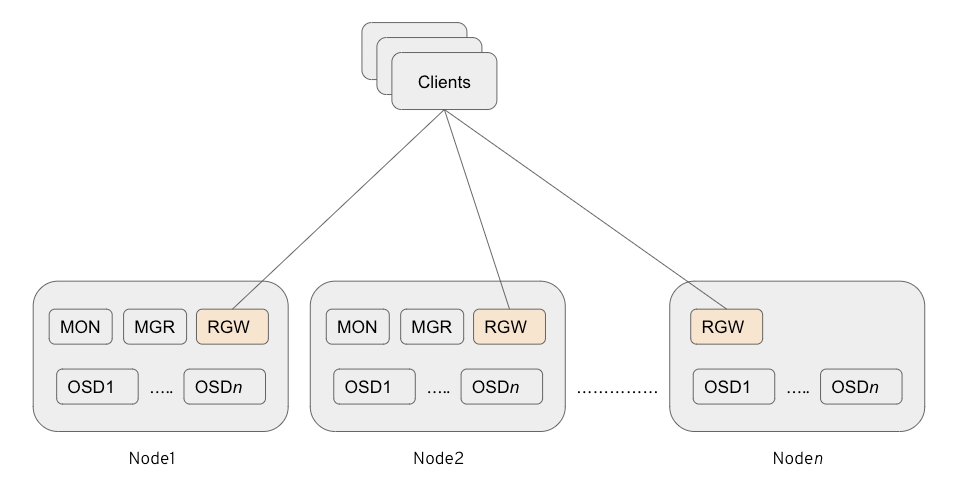
图 1:共存 RGW 部署策略
多址 RGW
-
不需要RGW的专用节点(可以帮助降低资本支出和运营支出)。
-
多个 Ceph RGW 实例(当前测试的每个存储节点 2 个实例)与其他存储容器共同驻留。
-
我们的测试表明,此选项可提供最高的性能,而不会产生额外费用。
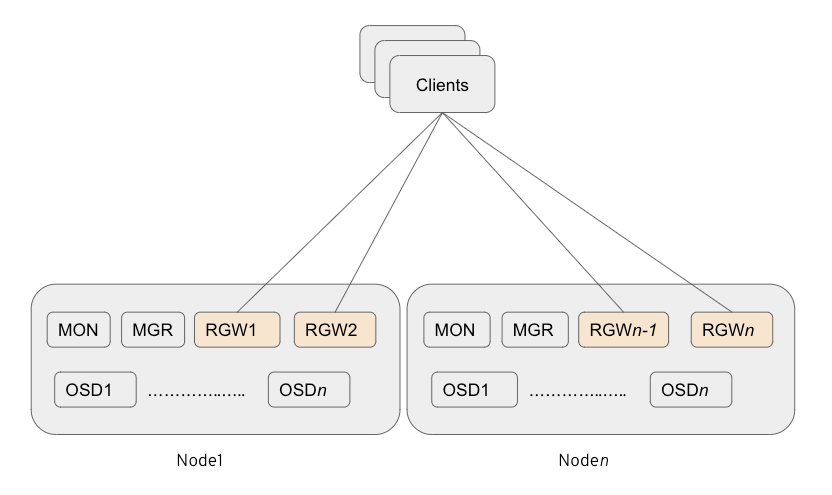
图 2:多个共存(2 x RGW 实例)部署策略
独立 RGW
-
需要 RGW 的专用节点。
-
Ceph RGW 组件部署在专用的物理/虚拟节点上。
-
从 Ceph Storage 3.0 开始,这不再是部署 RGW 的首选方法。
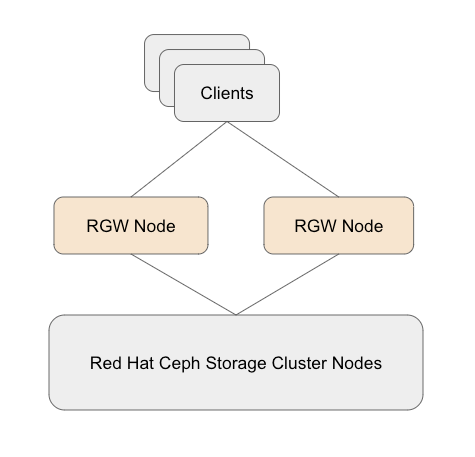
图 3:独立 RGW 部署策略
性能摘要
(I) RGW 部署和大小调整准则
在上一节中,我们研究了部署 Ceph RGW 的不同方法。我们将比较每种方法之间的性能差异。为了衡量性能,我们通过调整 RGW 部署策略以及大小写入和读取工作负载的 RGW CPU 内核数来执行多项测试。结果如下。
100% 写入工作负载
如图1和图2所示
-
共置 (1x) RGW 实例在小型和大型对象大小方面均优于独立 RGW 部署。
-
同样,多个共同驻留 (2x) RGW 实例的性能优于共同驻留 (1x) RGW 实例部署。因此,多个共驻 (2x) RGW 实例分别为小型和大型对象大小提供了 2328 Ops 和 1879 MBps 的性能。
-
在多个测试中,发现 4 个 CPU 核心/RGW 实例是 CPU 资源与 RGW 实例之间的最佳比率。为 RGW 实例分配更多 CPU 内核并未提供更高的性能。
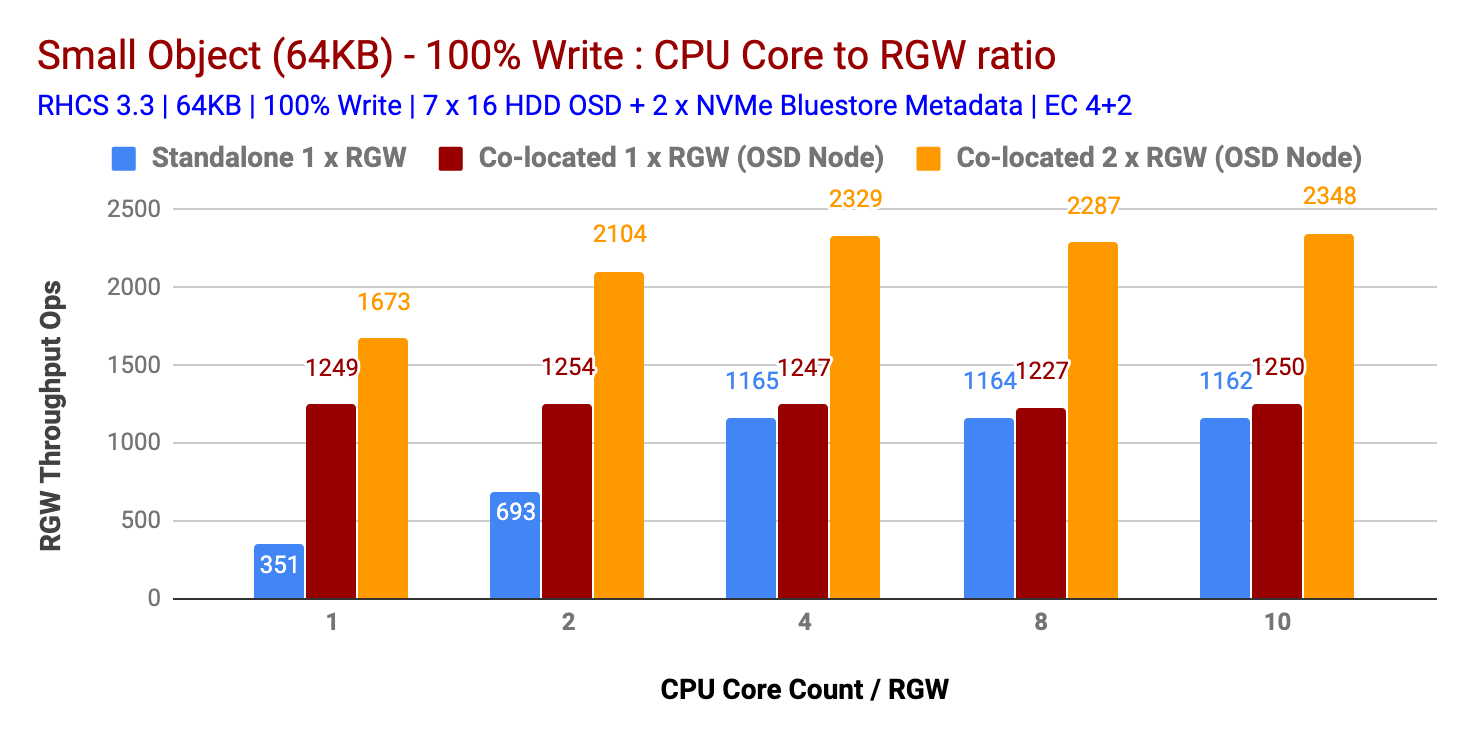
图 1:小对象 100% 写入测试
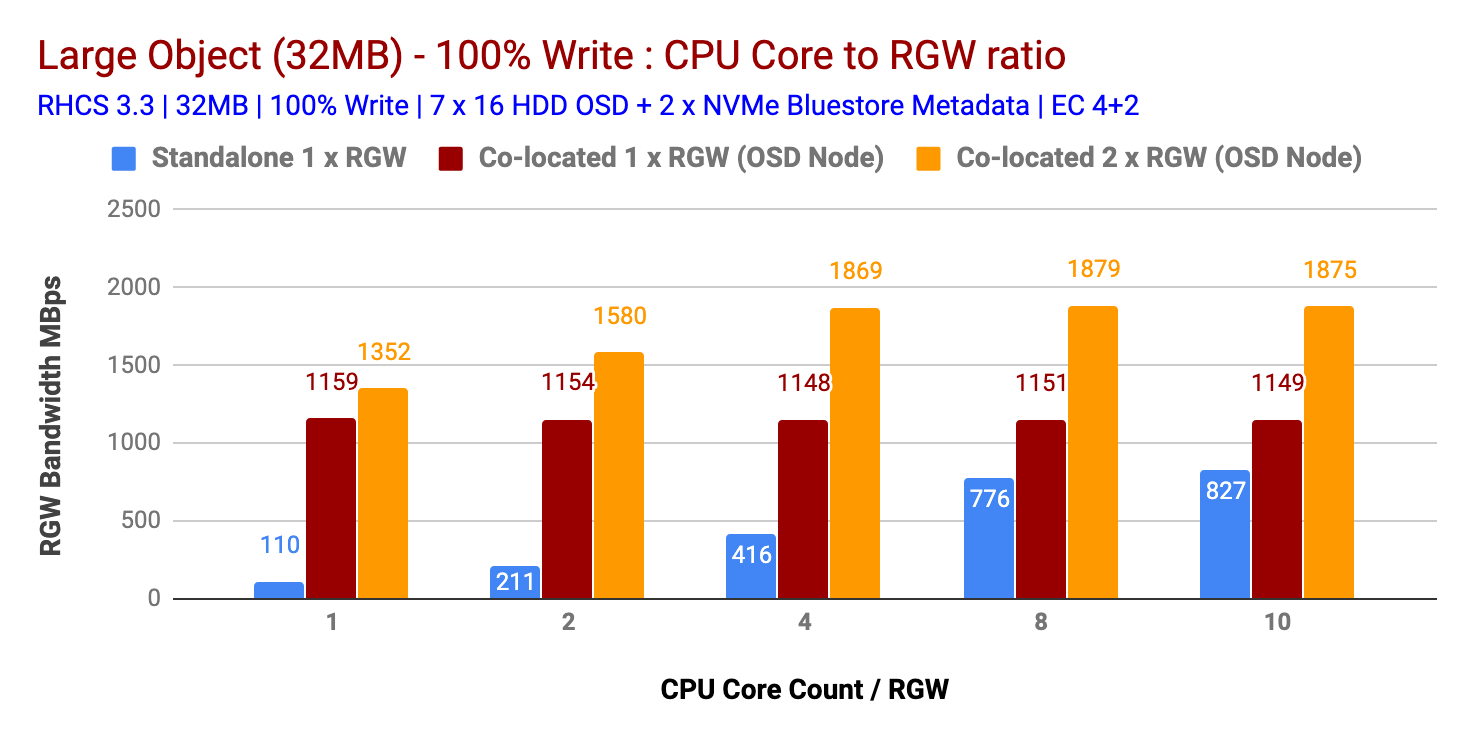
图表 2:大型对象 100% 写入测试
100% 读取工作负载性能
有趣的是,对于读取工作负载,增加每个 RGW 实例的 CPU 内核并不能提高小型和大型对象大小的性能。因此,每个 RGW 实例 1 个 CPU 内核的结果与每个 RGW 实例 10 个 CPU 内核的结果几乎相似。
事实上,根据我们之前的测试,我们观察到类似的结果,读取工作负载不会消耗大量 CPU,这可能是因为 Ceph 利用了系统的纠删码,并且在读取过程中不需要解码块。因此,我们发现,如果 RGW 工作负载是读取密集型的,则过度分配 CPU 无济于事。
将独立 RGW 与共存 (1x) RGW 测试的结果进行比较发现非常相似。然而,只要再添加一个同地RGW(2x),在小物体的情况下,性能提高了~200%,在大物体尺寸的情况下提高了~90%。
因此,如果工作负载是读取密集型的,则运行多个共存 (2x) RGW 实例可以显著提高整体读取性能。
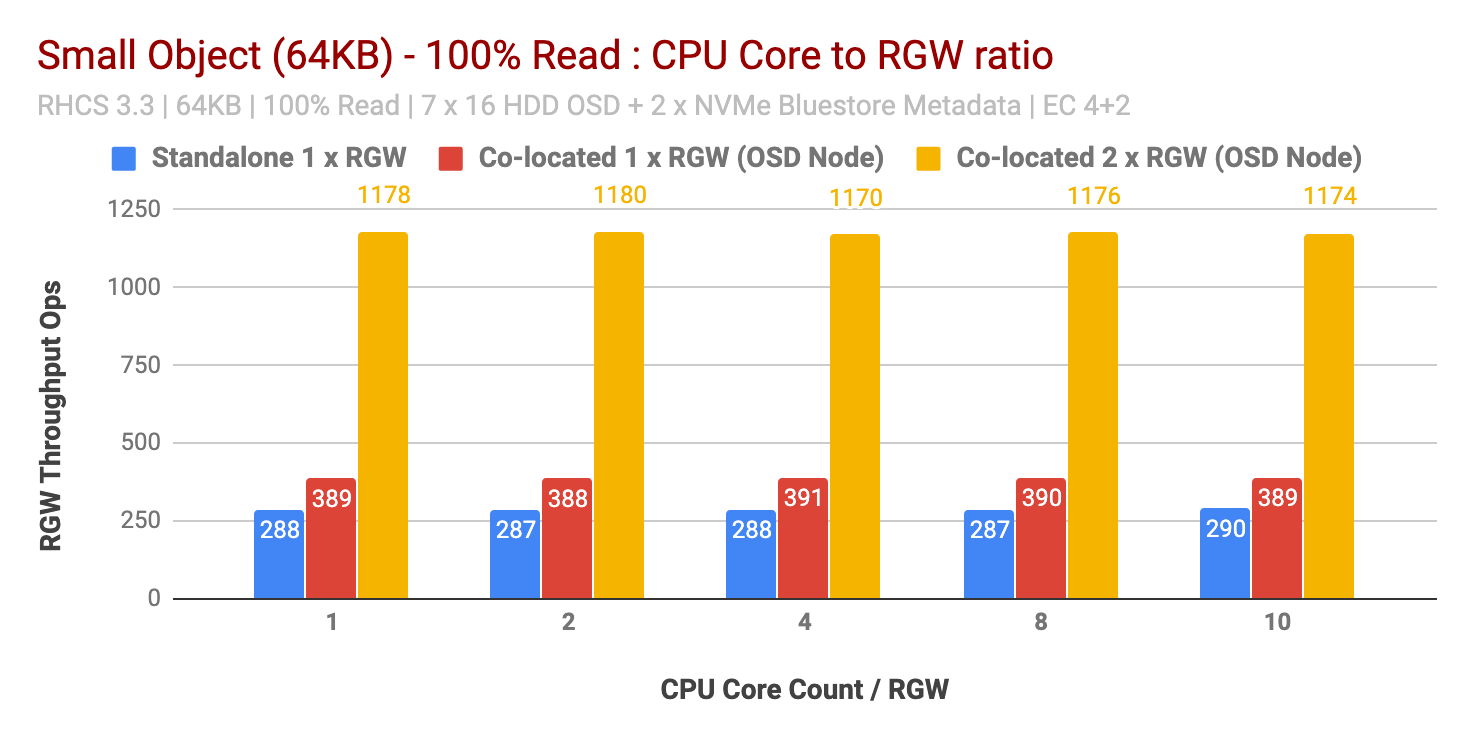
图表 3:小物体 100% 读取测试
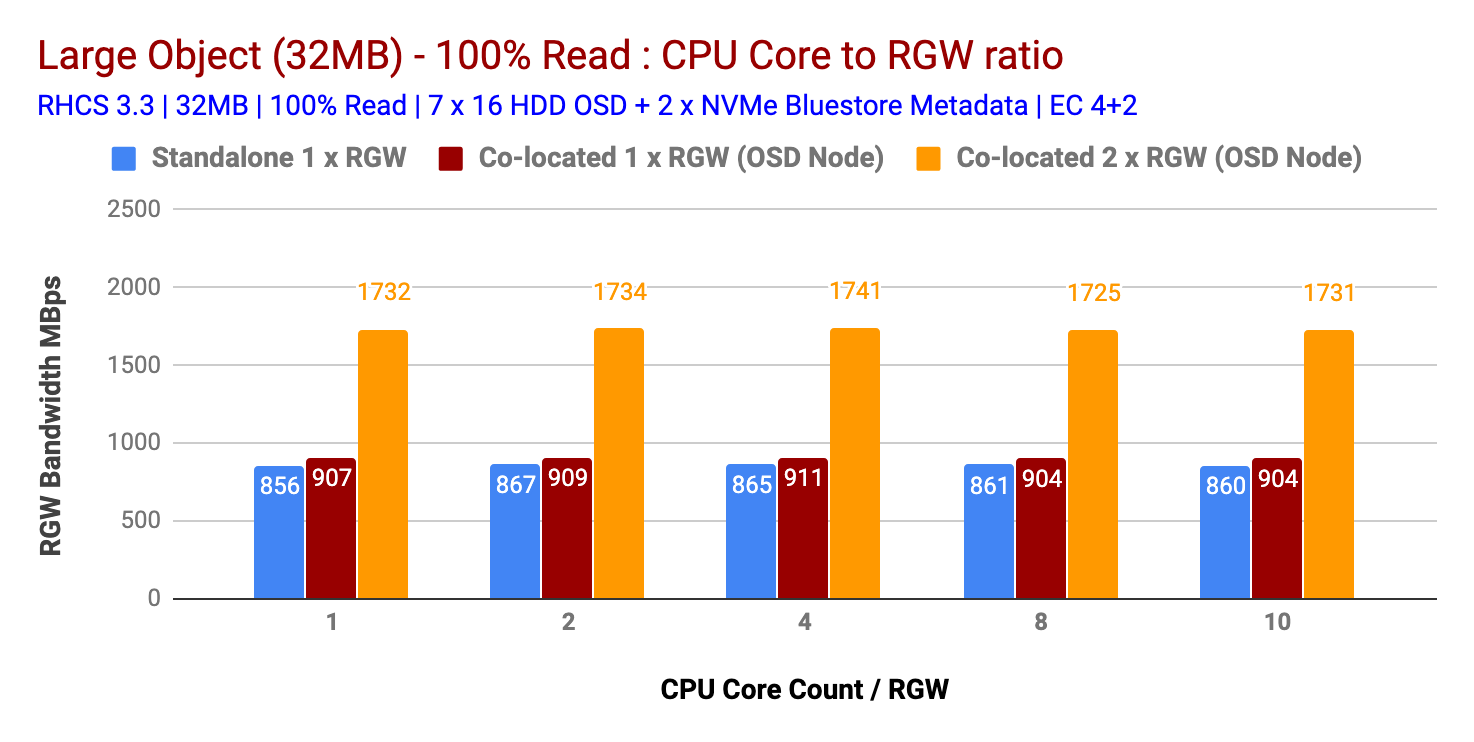
图表 4:大型对象 100% 读取测试
(二)RGW线程池大小调整准则
在决定 RGW 实例的 CPU 核心分配时,RGW 调整参数之一非常相关,它负责 Beast 生成的与 HTTP 请求对应的线程数。这有效地限制了 Beast 前端可以服务的并发连接数。rgw_thread_pool_size
为了确定此可调参数的最合适值,我们通过改变 RGW 实例之前的 CPU 核心计数来运行测试。如图表 5 和图表 6 所示,我们发现 设置为 512 可在 4 个 CPU 核心预 RGW 实例上提供最大性能。增加 CPU 内核数量并没有 做得更好。 rgw_thread_pool_sizergw_thread_pool_sizergw_thread_pool_size
我们确实承认,如果我们再进行几轮低于 512 的测试,这个测试可能会更好 。我们的假设是,由于Beast Web服务器基于异步c10k Web服务器,因此它不需要每个连接一个线程,因此在较低线程下应该表现良好。不幸的是,我们无法测试,但将来会尝试解决这个问题。rgw_thread_pool_size
As such multi-collocated (2x) RGW instance with 4 CPU Core per RGW instance and of 512 delivers the maximum performance.rgw_thread_pool_size
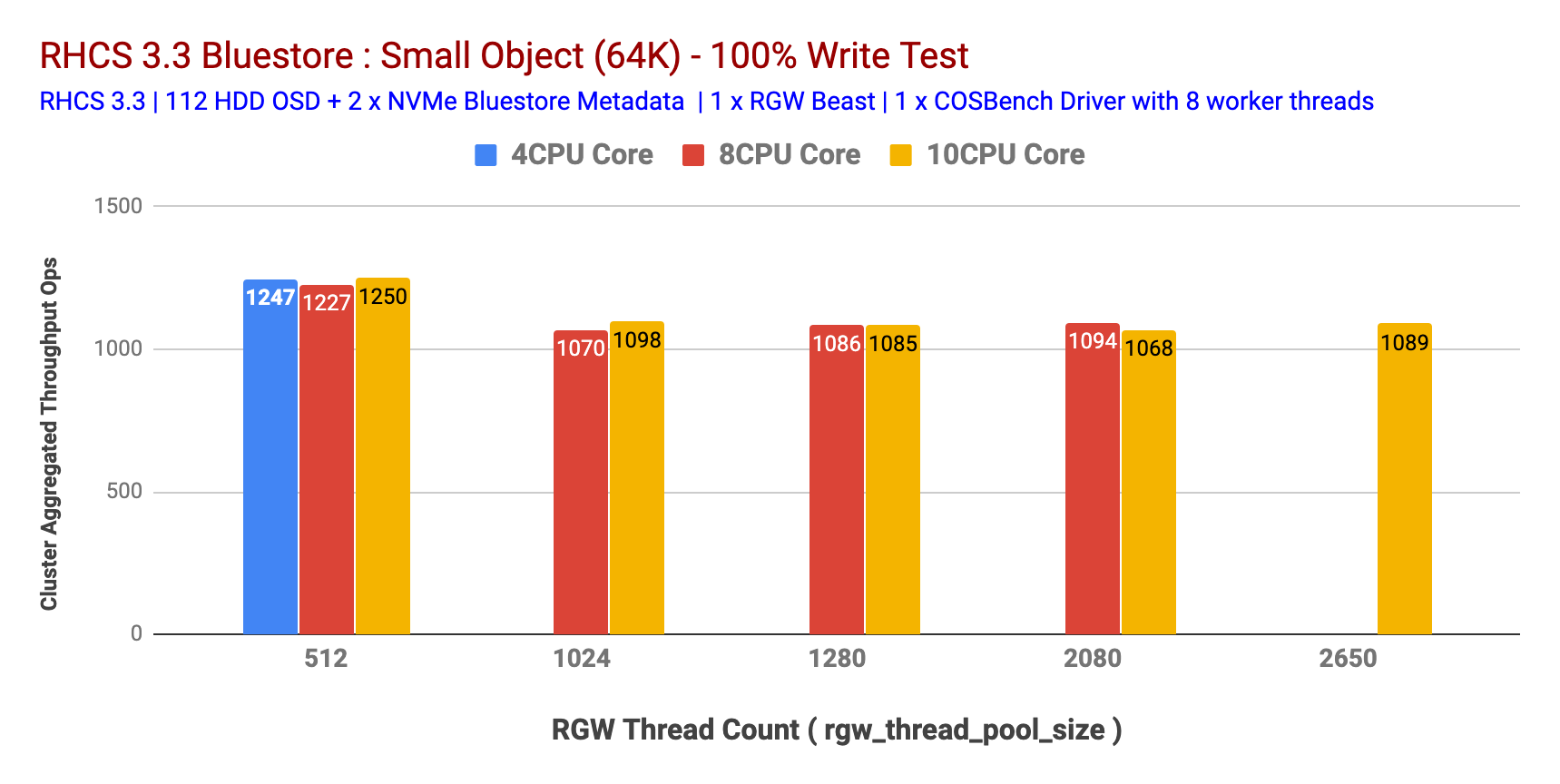
Chart 5: Small Object 100% Write test
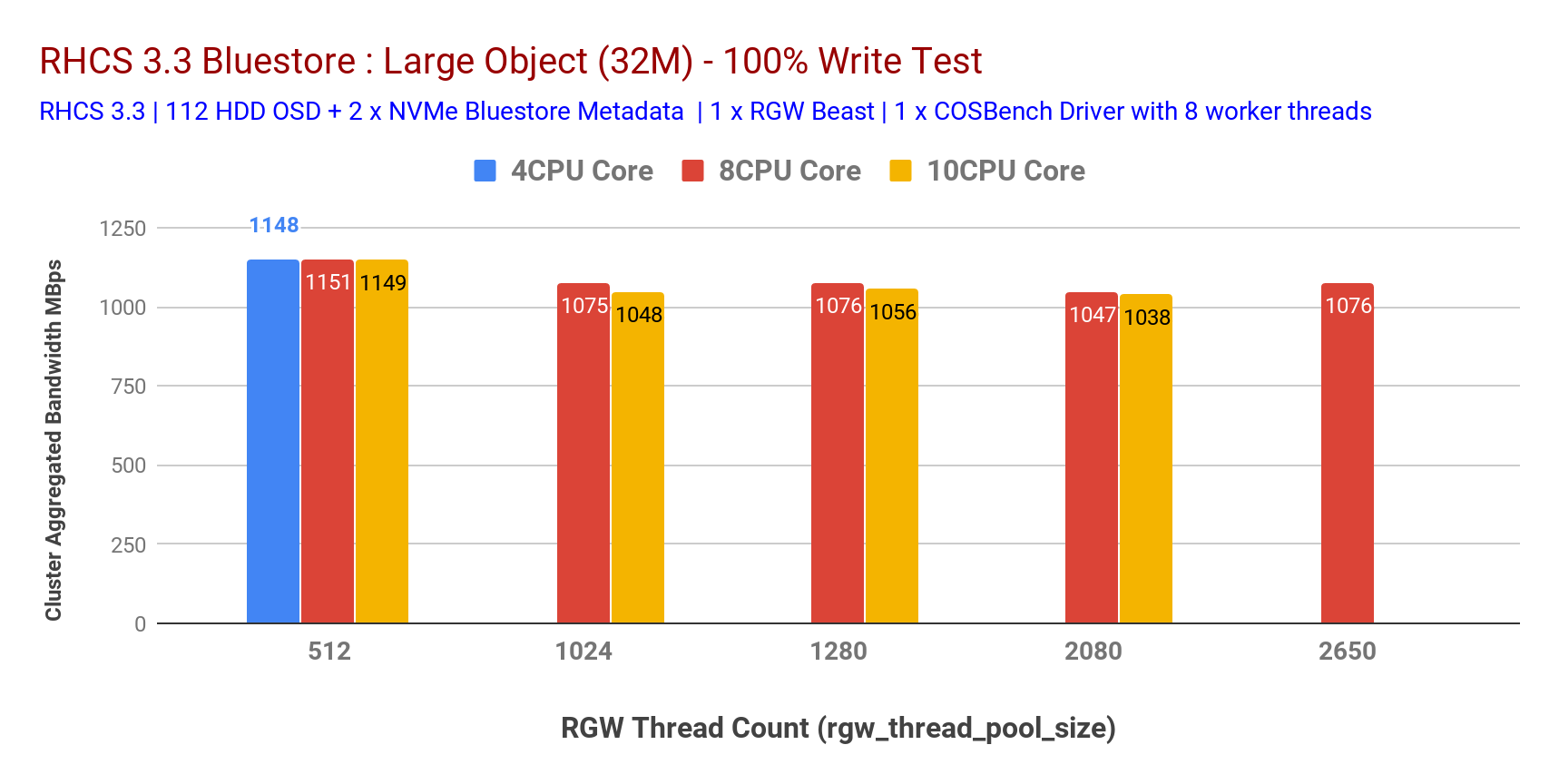
图表 6:大型对象 100% 写入测试
摘要和下一个
在这篇文章中,我们了解到,多地并置 (2x) RGW 实例,每个 RGW 实例有 4 个 CPU 核心,512 个,可在不增加整体硬件成本的情况下提供最大性能。在下一篇文章中,我们将学习如何从固定大小的集群实现最大的对象存储性能。rgw_thread_pool_size