多级页表
- 🏝️1. 考虑使用更大的页
- 🏖️2. 使用段页式管理
- 📖2.1 为什么采用段页式管理?
- 📖2.2 段页式管理的缺点
- 🏞️3. 多级页表
- 📖3.1 多级页表的优点
- 📖3.2 多级页表的缺点
- 📖3.3 一个简单的多级页表示例
- 📖3.4 更深层次的多级页表
- 📖3.3 32位地址空间下的多级页表
- 🏜️4. 倒排页表
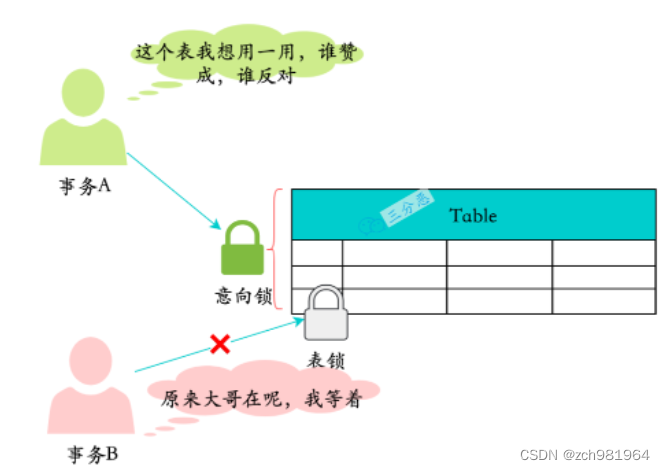
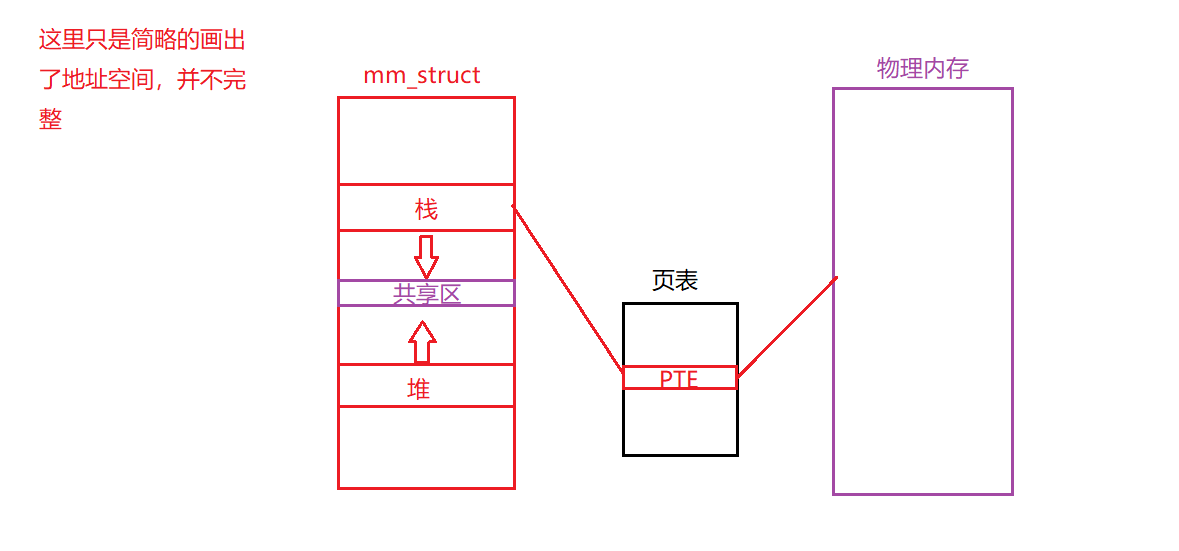
我们需要解决 分页引入的一个问题: 页表太大,占用内存过多.
如果我们使用线性页表,假设一个32位的地址空间,页大小为4kB,4字节的页表项(PTE),一个地址空间中大约有一百万个虚拟页面,再乘以页表项的大小,页表大小为4MB.
往往在系统中我们是由许多进程的,而每个进程都有一个页表,如果有一百个进程,那么仅仅是页表所占空间就达到了400MB,这显然不合理,所以,接下来我们会介绍一种多级页表的技术来解决这个问题.

🏝️1. 考虑使用更大的页
我们可以使用一种简单的方法减小页表的大小:使用更大的页,因为页的大小变大,那么PTE就变少,页表也就随之变小.
以32位地址空间为例:这次我们使用16KB的页,因此,会有18位的VPN(虚拟页号)加上14位的偏移量,假设页表项依然为4字节,这时页表的大小就变成了1MB.
但是,这种方法的问题是:大内存页会导致每页内的浪费,这被称为内部碎片问题(浪费在分配的存储单元内部). 应用程序分配页,但只使用每页的一小部分,而内存很快就会充满这些过大的页.
🏖️2. 使用段页式管理
📖2.1 为什么采用段页式管理?
段页式管理将分页和分段相结合,以减少页表的内存开销.
我们先来看看典型的线性页表,就能理解这种方法为什么可能有用,假设我们有一个32位的地址空间,在这个地址空间中,我们只使用了很少的部分:
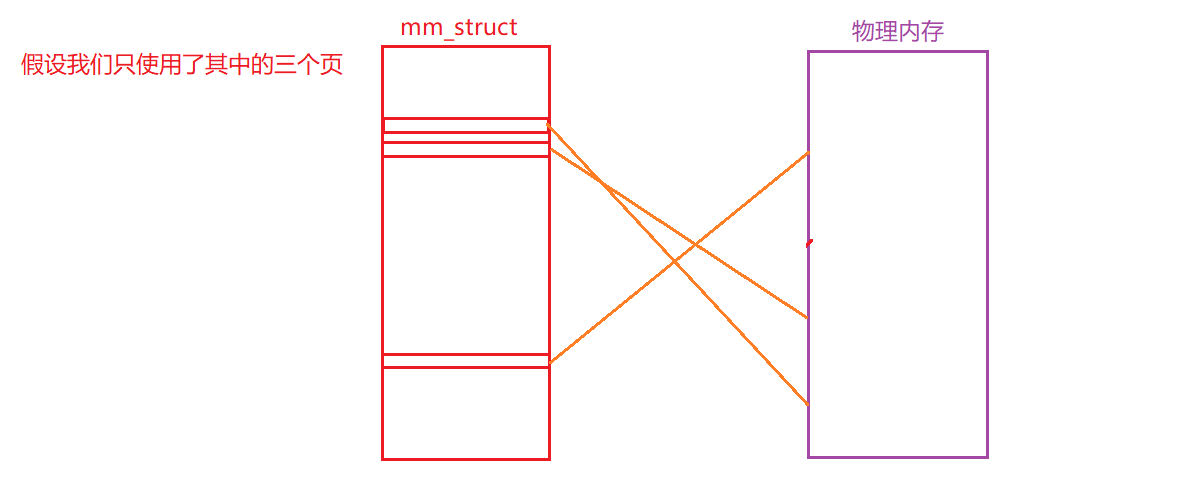
也就是说,在为这个地址空间所建立的页表当中,充满了无效的页表项,浪费了许多空间.
因此在段页式管理中,我们不再为进程的整个地址空间提供单个页表,而是为每个逻辑分段都提供一个,在我们的例子中,提供3个页表:地址空间中的代码段、堆、栈部分各有一个.
在分段中,我们有一个基址寄存器,告诉我们每个段在物理内存中的位置,还有一个界限寄存器,告诉我们该段的大小.
在段页式方案中,我们仍然拥有这些结构,但是,使用基址指向页表的物理地址,界限寄存器指示页表的结尾.
我们通过一个简单的例子来说明:假设32位虚拟地址空间包含4KB页面,并且地址空间分为4个段,在这里,我们只使用三个段:一个用于代码,一个用于堆,一个用于栈.
要确定虚拟地址引用哪个段,我们会用地址空间的前两位,假设00是未使用的段,01是代码段,10是堆段,11是栈段,因此,虚拟地址如下:

在硬件中,我们假设有三个基址/界限对,代码、堆、栈各一个,当进程正在运行时,每个段的基址寄存器都包含该段的线程页表的物理地址. 因此,系统中的每个进程都有三个与其关联的页表,在上下文切换时,必须更改这些寄存器,以反映新运行进程的页表位置.
在TLB未命中时,硬件使用分段位来确定要使用哪个基址和界限对,然后硬件将页表的地址和VPN(虚拟页号),结合起来,形成PTE的地址.
段页式管理的关键区别在于:每个分段都有界限寄存器,每个界限寄存器中保存了段中最大有效页的值.
例如:如果代码段使用它的前三个页(0、1、2),则代码段页表将只有三个项分配给它,并且界限寄存器被设置为3,内存访问超出段的末尾,将可能导致进程终止. 段页式管理显著的节省了内存,地址空间中未分配的页不再占用页表的空间.
📖2.2 段页式管理的缺点
段页式管理仍然要求分段,分段不灵活,因为它假定地址空间有一定的使用模式,如果有一个大而稀疏的堆,仍然可能导致大量的页表浪费. 并且它会导致外部碎片.
🏞️3. 多级页表
📖3.1 多级页表的优点
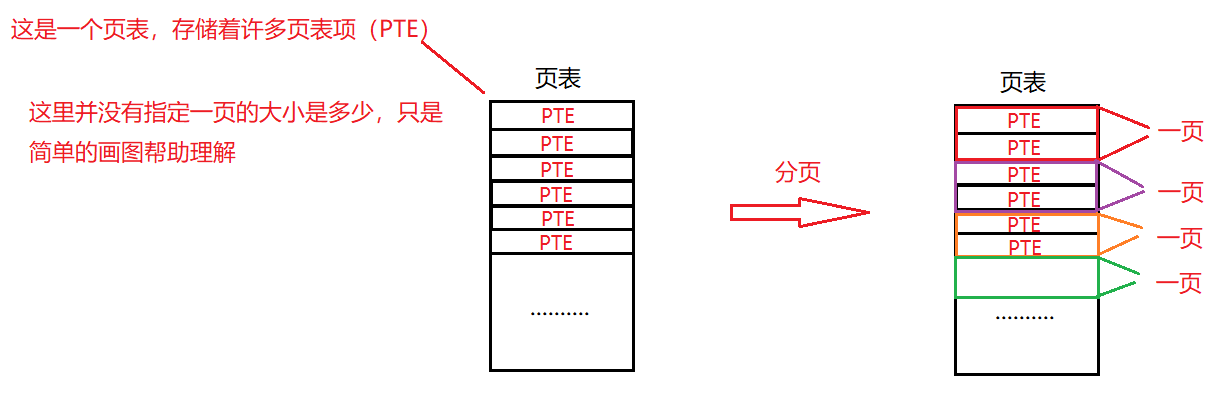
多级页表的思想很简单:首先,将页表分成页大小的单元,如果哪一页的页表项都是无效的,就完全不分配该页的页表. 为了追踪页表的页是否有效(以及如果有效,它放在内存的什么位置),使用了名为页目录的新结构. 页目录存储页表的页是否有效以及如果有效,它存储在哪里.
在一个简单的两级页表中,页目录为每页页表包含了一项,它由多个页目录项组成. PDE拥有有效位(该页表的这一页是否有效)以及页帧号(存储页表的这一页在内存中的位置).
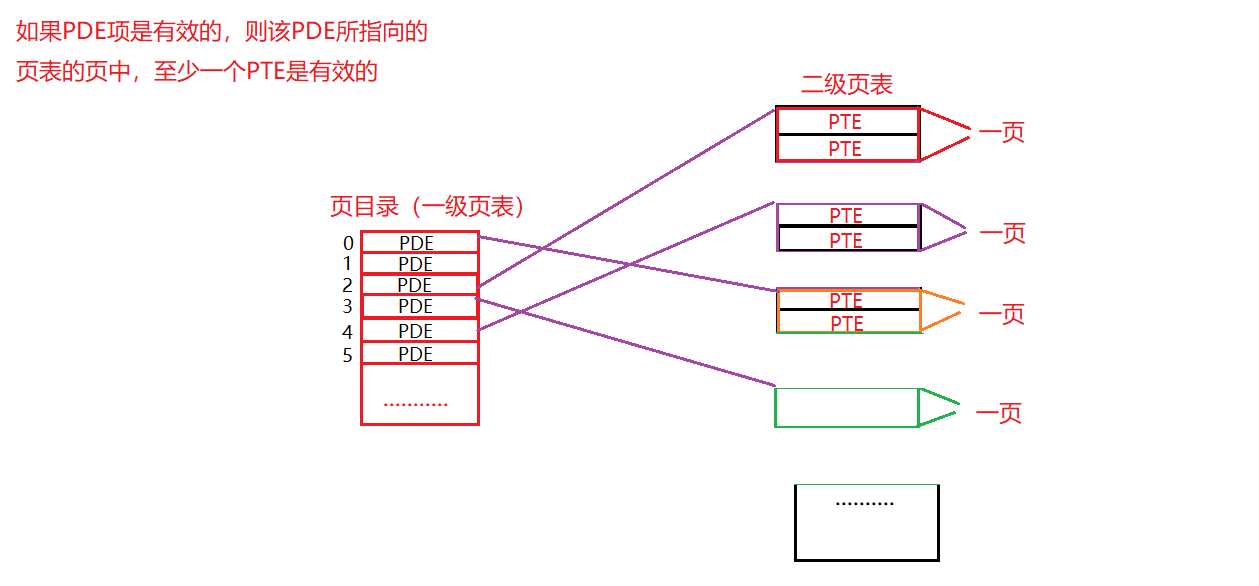
线性页表和多级页表的比较:
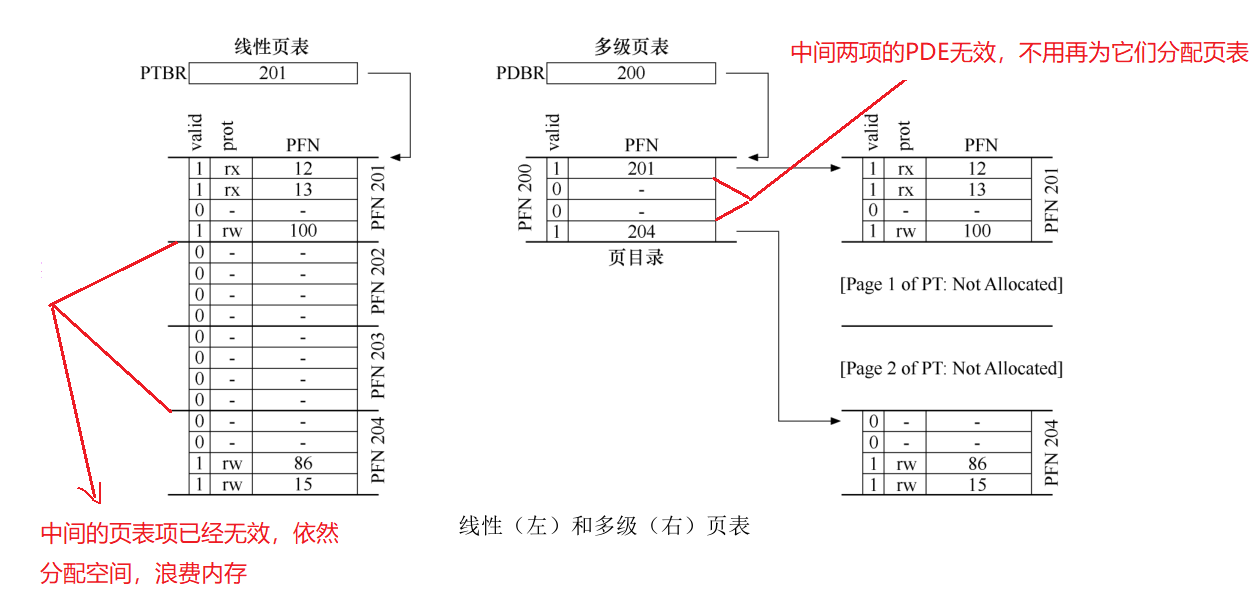
多级页表有一些明显的优势:
- 多级页表分配的页表空间,与你正在使用的地址空间内存量成正比,支持稀疏的地址空间.
- 页表的每一部分都可以整齐的放入一页中,从而更容易管理内存,操作系统可以在需要分配或增长页表时简单地获取下一个空闲页.
- 页表页可以放在内存中的任何位置,不需要寻找连续的内存空间
📖3.2 多级页表的缺点
- 访问多级页表是有成本的,在
TLB未命中时,需要从内存中加载两次,才能从页表中获取正确的地址转换信息(一次用于页目录,一次用于访问PTE),而用线性页表只需要一次加载,因此,多级页表是一个时间-空间折中的例子(牺牲时间,换取空间). - 无论是硬件还是操作系统来处理页表查找,都会比简单的线程页表查找更复杂,在多级页表下,我们为了节省宝贵的内存,使页表的查找更加复杂.
📖3.3 一个简单的多级页表示例
为了更好的理解多级页表背后的想法,我们来看一个例子:设想一个大小为16KB的小地址空间,页大小为64字节,这个地址空间共可以分成256个页,即我们有256个PTE需要管理.
因此,我们有一个14位的虚拟地址空间,VPN占8位(2 ^ 8 = 256),偏移量6位(2 ^ 6 = 64).
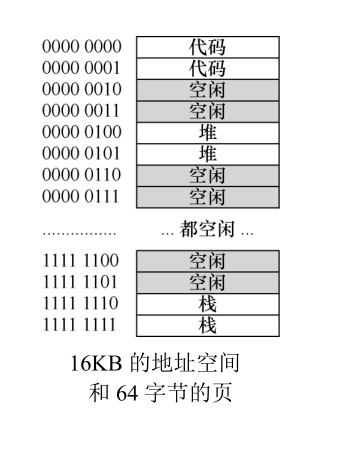
在这个例子中,虚拟页0和1用于代码,虚拟页4和5用于堆,虚拟页254和255用于栈,地址空间的其余页均未使用.
现在,我们需要为这个地址空间构建一个两级页表:

接下来,我们需要知道,如何通过虚拟地址访问到物理内存:
我们需要获取VPN(虚拟页号),并用它首先索引到页目录中,然后再索引到页目录项指向的页中.
这个例子中的页表很小:256个项,分布在16个页上,页目录需要为页表的每页提供一项. 所以,它有16项,所以,我们在虚拟地址中使用4位来索引目录:
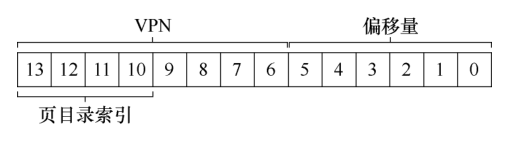
从VPN中提取到了页目录索引(PDIndex),就可以通过简单的计算来找到页目录项的地址:

如果页目录项标记为无效,则我们知道访问无效,从而引发异常,如果PDE有效,下一步我们需要从页目录项指向的页表中获取页表项
要找到这个PTE,我们必须使用VPN剩余的位索引到页表的部分:
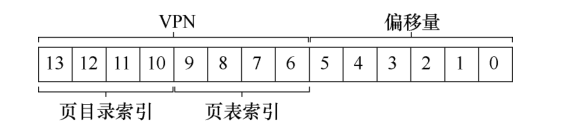
这个页表索引可以用来索引页表本身,从而找到PTE的地址:通过页表的基址 + 偏移量.
最终在PTE当中就找到了我们需要的物理地址.
为了确定这一切是否合理,我们现在代入一些包含实际值的多级页表:
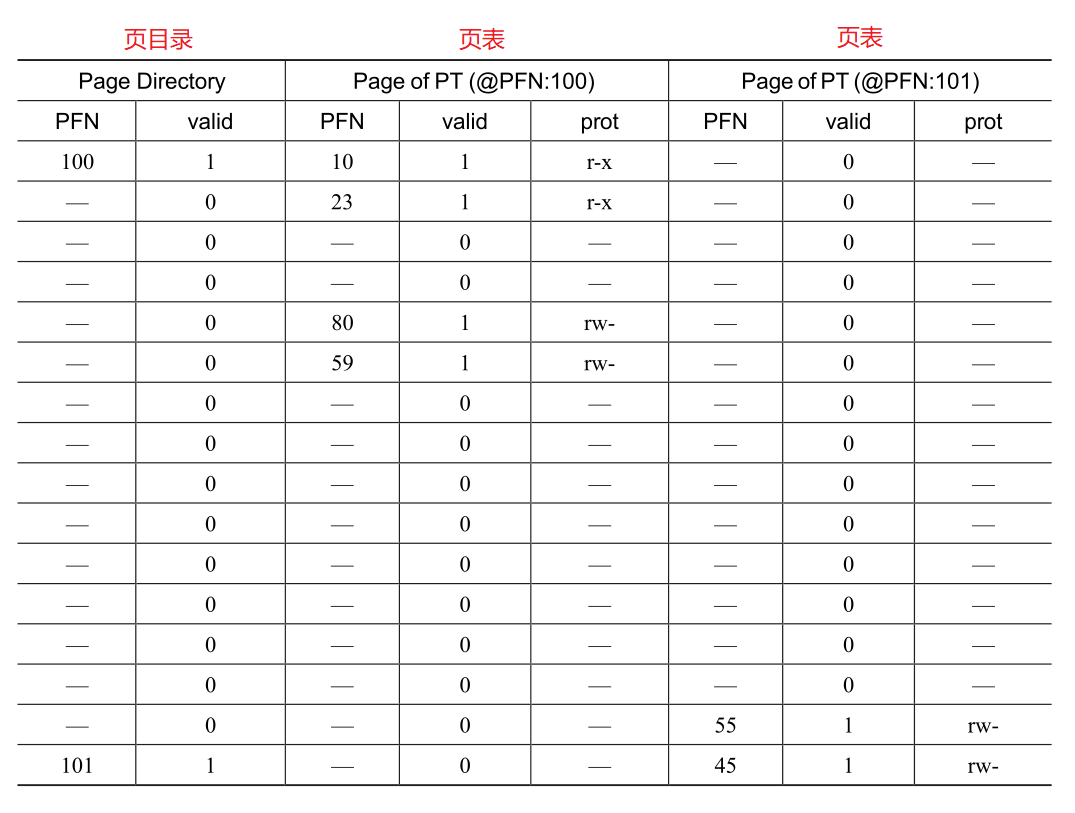
物理地址为100的页表中包含了前16个VPN的映射,VPN 0和1是有效的,4和5也是,页目录中有每个页的映射信息,其余项标记为无效.
在这个例子中,我们不是为一个线性页表分配完整的16页,而是分配3页:一个用于页目录,两个用于页表.
最后,我们试着用一个虚拟地址转换为物理地址:
给一个虚拟地址:指向VPN 254的第0个字节:0x3F80,二进制:11 1111 1000 0000

📖3.4 更深层次的多级页表
在刚才,我们举了二级页表的例子,现在假设我们有一个30位的虚拟地址空间,和一个小的(512字节)页,因此虚拟地址21位为虚拟页号,9位为偏移量.
所以,我们的虚拟地址分布为:

因为页的大小为512字节,假设PTE大小为4字节,单个页上能够存放128个PTE,所以我们使用VPN中的低7位来做页表索引.
但是,页目录索引占据了14位,也就是说,页目录中有2^14个项(PDE),那么它需要128个页来存储,因此多级页表每一部分都放入一页的目标失败了.
为了解决问题,我们需要构建三级页表:
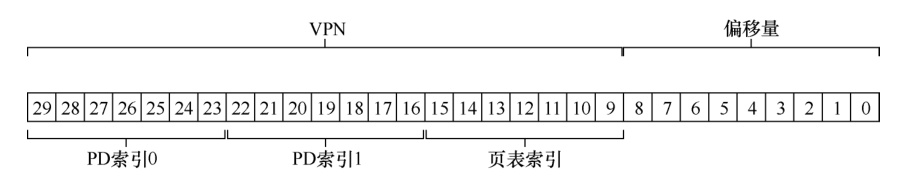
其实就是2^14 = 128 * 128.
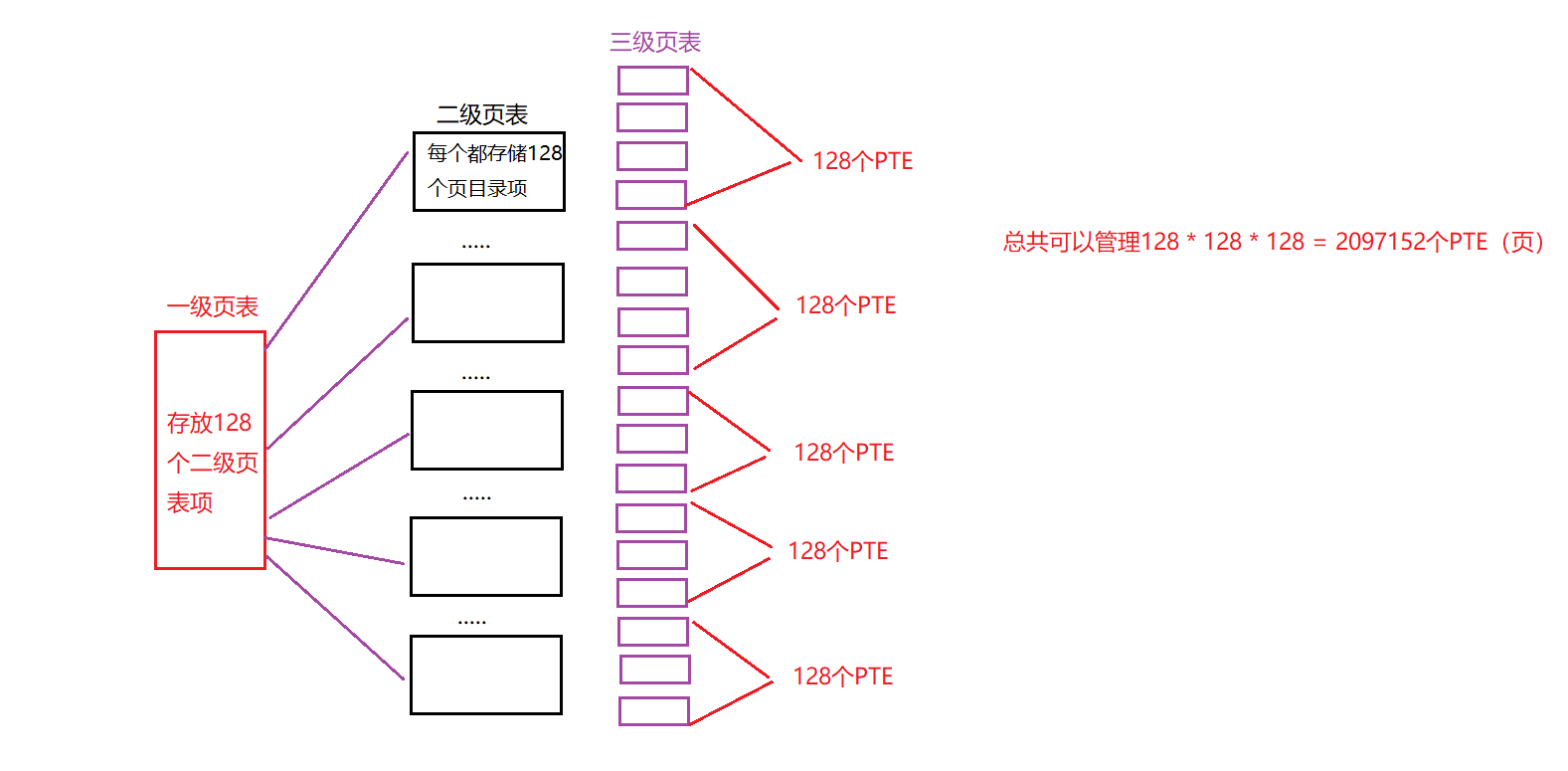
现在,当索引上层页目录时,我们使用虚拟地址的最高几位(PD 索引 0). 该索引用于从顶级页目录中获取页目录项. 如果有效,则通过组合来自顶级 PDE 的物理帧号和 VPN 的下一部分(PD 索引 1)来查阅页目录的第二级,如果有效,则可以通过使用与第二级页表PDE的地址组合和页表索引来形成PTE的地址.
📖3.3 32位地址空间下的多级页表
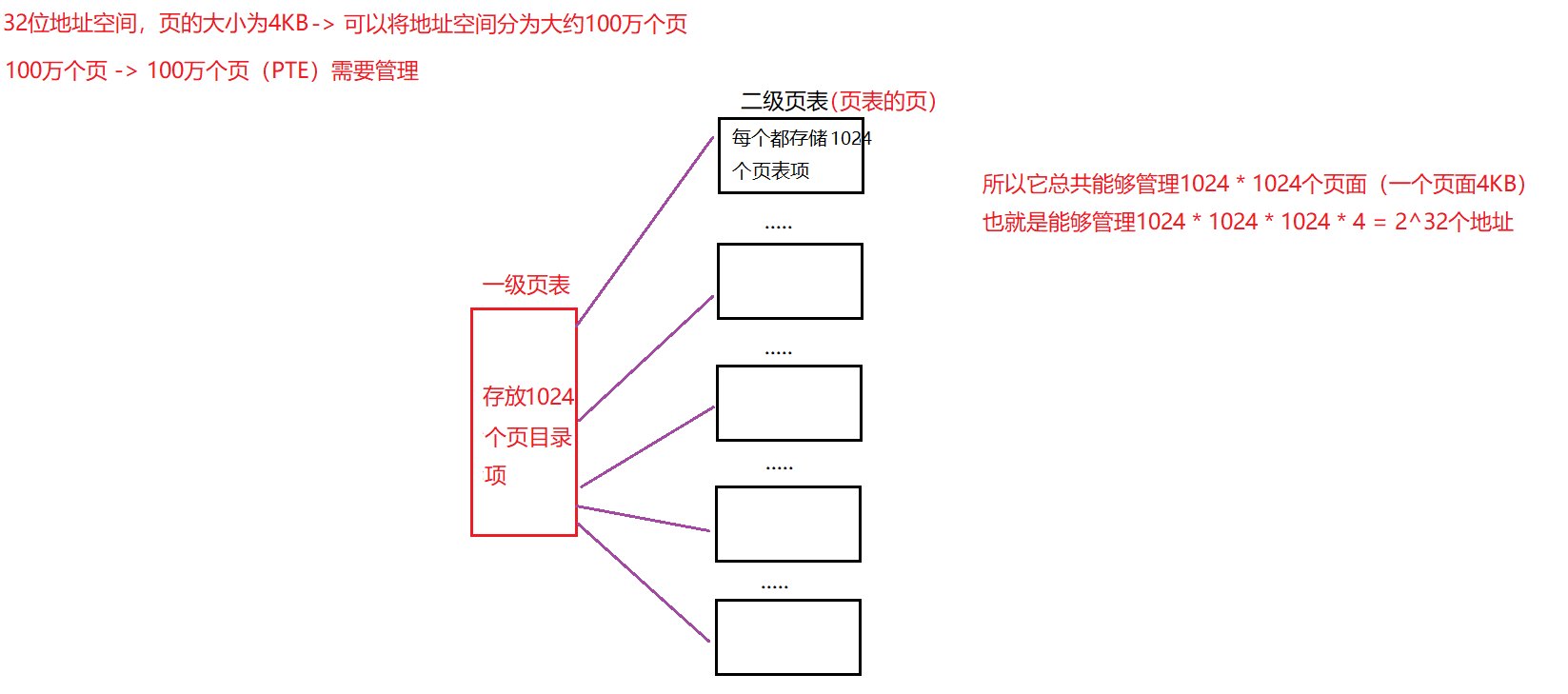
对于32位的地址,前10位存储一级页表(页目录)的索引,中间10位存储二级页表的页表索引,最后12位存储偏移量.
🏜️4. 倒排页表
在倒排页表中,只有一个页表,其中的项代表每个系统的物理页,而不是每个进程都有一个页表,页表项告诉我们哪个进程(PID)正在使用此页,以及该进程的哪个虚拟页映射到此物理页.
如果要寻找页表项,就搜索这个数据结构,在此结构的基础上建立一个散列表.