-
任务描述: 文本匹配是自然语言处理中一个非常核心的任务,主要目的是研究两段文本之间的关系。许多自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配,对话系统可以归结为前一句对话和回复的匹配,机器翻译则可以归结为两种语言的匹配。
-
数据集:https://download.csdn.net/download/qq_38735017/87202680是美国知识问答网站Quora发布的数据集,包括超过40万个问题对,旨在检测出重复的问题对。
-
运行环境:Python>=3.6, torch>=1.0, numpy, pandas, scikit-learn, matplotlib
-
方法概述:我们采用了类似MaLSTM的孪生网络结构。
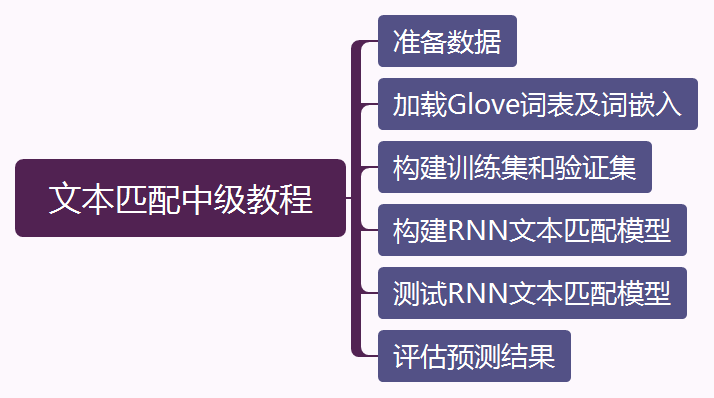
首先,我们基于预训练的Glov