文章目录
- 前言
- 实验 0 环境的搭建
- 实验原理&材料
- 实验流程
- 建议
- 实验1 输出硬件参数
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 实验2 实现系统调用
- 实验内容
- whoami()
- 评分标准
- 基础知识
- 实验代码
- 实验结果
- 实验3 进程运行轨迹的跟踪
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 结合自己的体会 从程序设计者的角度看 单进程编程和多进程编程最大的区别是什么
- 你是如何修改时间片的? 仅仅针对样本程序建立的进程,在修改时间片前后 log文件的统计结果都是怎么样的,结合你的修改分析一下为什么会这样,或者为什么没变化?
- 实验4 实现信号量
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 实验5 实现共享内存
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 实验6 字符显示
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 实验7 proc文件系统的实现
- 实验内容
- 基础知识
- 实验代码
- 实验结果
- 总结
前言
操作系统是计算机科学与技术专业的一门重要的专业课。其对于培养系统思维,体会大型系统的复杂与折衷,巩固并串联所学的知识都是大有裨益的。
但是操作系统并不是那么好学的。如果只是学会书上的那些概念,记记各种算法,那也太简单了,不能算是学会了操作系统。只能说你知道有这么个东西。如果你只是想知道有这么个东西,那其实也不用再做实验了。但我们毕竟学的是计算机科学与技术,不是使用计算机。学习层次不能只停留在了解上,你得深入实践。就算无法真正做一个操作系统,你至少也得知道具体的操作系统该如何编写。同时,操作系统是紧密贴合底层的系统。采取模拟的方式进行实验,就好像是通过学习如何用积木搭建并管理城市,去代替实际城市的建立和管理一样。是这么回事但又不是这么回事。
一句话,you learn it by do it.
但是操作系统毕竟是人所能创造的最复杂的系统,初学就去碰windows和现代linux是不太明智的。你会迷失在细节当中,无法脱身。不是所有学生未来都会真正做一个操作系统,不应该让这些细节问题在实验中耽误了对系统整体的把握。因此本实验采取的是一个功能完备但是代码量相对较少的操作系统——Linux0.11。通过在其之上完成各种功能的过程中,运用所学课程的知识去解决实现功能中的问题,达到巩固、学习操作系统的目的。
本实验总共有8个验证性实验。涉及到系统调用、进程、信号量、内存、文件系统等知识点。
本实验所有的代码可见https://github.com/TheWindISeek/HIT-OSLAB
本实验的参考手册可见https://hoverwinter.gitbooks.io/hit-oslab-manual/content/environment.html
本实验更详细的实验记录可见 https://blog.csdn.net/SDDHDY/article/details/128101819?spm=1001.2014.3001.5501
本实验的参考书为Linux0.11源码剖析
实验 0 环境的搭建
没错,这也是一个实验。在搭建过程中已经体会到了操作系统的复杂性。
实验原理&材料
由于linux0.11已经是上世纪90年代的操作系统,其所依赖的硬件环境早已不存在。因此,需要使用虚拟机软件去模拟具体的硬件环境。
为了做到很好的移植性,能够让环境在多种操作系统上都能运行。采取的是免费且开源的虚拟机软件bochs。有关其的信息可在https://bochs.sourceforge.io/中获得。
同时为了便于Linux0.11(以后简称为0.11)的测试与编写。本实验采用ubuntu14.04-64bit作为运行bochs虚拟机的操作系统。后续任何的操作都是ubuntu14.04中进行。但由于我的主系统是window11家庭版,所以使用了VBox去做了一个虚拟机。
Linux的内核是用GCC所编译的。编译0.11所需要用的GCC版本是3.4,更高版本的GCC编译会报错。
0.11中内置了GCC编译器,用于在0.11上编译程序(建议在ubantu下编写程序,可使用gedit, vim.emacs等软件)。
为了让0.11能用上ubantu中编写的程序,需要挂载hdc,(使用./mount-hdc)将编写的程序复制到hdc/usr/root/下。(其他文件夹也可以,不过hdc/usr/root是默认文件夹)
在0.11中的编译流程通常为
gcc test.c -o test
# 用于查看链接和汇编文件
gcc -E test.c -o test.i
gcc -S test.i
gcc -c test.s
# 运行可执行文件
./test
# 输出重定向到文件
./test > filename
需要注意的是编译Linux0.11内核程序的GCC版本和当前系统中所使用的GCC版本是不一样的。
0.11的代码可在如下网站获取http://www.oldlinux.org/lxr/http/source/
其采用了Makefile文件,简化了编译流程。关于Makefile的介绍见该网站https://www.zhaixue.cc/makefile/makefile-intro.html
所有的实验材料可在https://github.com/hoverwinter/HIT-OSLab/tree/master/Resources获得
实验流程
具体的环境(64位系统,ubuntu版本大于14.04会存在其他的问题,可参见HIT-Linux-0.11/准备安装环境.md at master · Wangzhike/HIT-Linux-0.11 (github.com))搭建 首先打开终端
64位系统需要下载32位的兼容库,否则会出现问题。多用help ?man google baidu去解决问题
sudo apt-get install g++-multilib
# 如果没有git的话 需要先下git
sudo apt-get install git
# 复制项目到~/hit-oslab 这样你就能在工作目录下找到这个文件路径
git clone https://github.com/hit-oslab.git ~/hit-oslab
# 进入这个文件夹
cd ~/hit-oslab
# 执行初始化脚本
./setup.sh
# 此时观察主目录 是否有oslab 或者类似命名的文件夹
cd oslab
#此时你就完成了环境的搭建
接着我们进入到linux-0.11文件夹,执行如下命令。只需要使用如下操作即可完成编译运行
# 进入linux-0.11文件夹
cd linux-0.11
# 清楚上边编译得到的文件
make clean
# 得到当前代码编译得到的系统镜像
make all
make clean && make all
# 回到上一级文件夹运行
cd ../
./run
最后会得到。
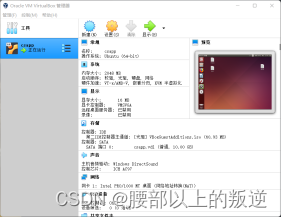
可以输入类似
pwd
ls
ls -l
cd ../
echo "this is linux0.11"
vi hello.c # esc shift&: wq
检查系统是否正常运行。
有关vi, vim, gedit,emacs等编辑器的使用请自行查询。
最后点击左上角的关闭按钮,关闭该操作系统。(0.11没有关机)
如果到现在,你都运行成功了,那么你的环境就配置完成了。
建议
在主系统和ubuntu系统下做一个共享文件夹,用于保存之前实验的数据
另外建议使用git做代码的版本管理。
还建议多使用脚本来简化操作。
实验1 输出硬件参数
实验内容
改写bootsect.s在屏幕上打印一段提示信息"…"(自选)
改写setup.s在屏幕上打印一段提示信息“…”(自选)
在setup.s中输出硬件参数。(内存,显卡,硬盘。至少1个,参数可参见bochs/bochsrc.bxrc)
基础知识
操作系统的引导中发生的事情可参见为什么BIOS要将主引导扇区(MBR)加载到0x7c00这个地址?_greatgeek的博客-CSDN博客
以及关于BIOS加载BOOT.S的经典解答_秋海csdn的博客-CSDN博客
另外,0.11所使用的汇编代码的格式不是常用的x86格式,不过较为相似。只是立即数和寄存器的使用有点不一样。多参考0.11源码的注释即可看懂。
至于如何像屏幕输出字符串,可参考0.11源码中的输出字符串和该博文babyos (一)——利用BIOS 中断INT 0x10显示字符和字符串_孤舟钓客的博客-CSDN博客
获取硬件参数可参见如下博文。[操作系统启动过程_kuangd_1992的博客-CSDN博客_操作系统启动过程](https://blog.csdn.net/kuangd_1992/article/details/119858396?ops_request_misc=%7B%22request%5Fid%22%3A%22166964426916782428615887%22%2C%22scm%22%3A%2220140713.130102334.pc%5Fall.%22%7D&request_id=166964426916782428615887&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-2-119858396-null-null.142v67control,201v3add_ask,213v2t3_control1&utm_term=7c00 9000&spm=1018.2226.3001.4187)
实验代码
bootsect.s
! Print some inane message
! read the cursor position
mov ah,#0x03 ! read cursor pos
xor bh,bh
int 0x10
mov cx,#46 ! length of string for output #
mov bx,#0x0007 ! page 0, attribute 7 (normal)
mov bp,#msg1
mov ax,#0x1301 ! write string, move cursor
int 0x10
msg1:
.byte 13,10
.ascii "Lucifer system Created by rebelOverWaist"
.byte 13,10,13,10
setup.s
mov ax, #SETUPSEG
mov es, ax
mov ah, #0x03
xor bh, bh
int 0x10
mov cx, #12
mov bx, #0x0007
mov bp, #msg
mov ax, #0x1301
int 0x10
msg:
.byte 13, 10
.ascii "setup..."
.byte 13, 10, 13, 10
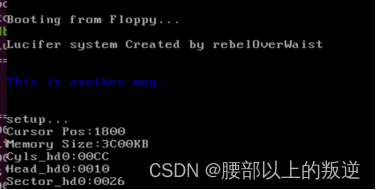
硬件参数
!以16进制方式打印栈顶的16位数
print_hex:
mov cx,#4 ! 4个十六进制数字
mov dx,(bp) ! 将(bp)所指的值放入dx中,如果bp是指向栈顶的话
print_digit:
rol dx,#4 ! 循环以使低4比特用上 !! 取dx的高4比特移到低4比特处。
mov ax,#0xe0f ! ah = 请求的功能值,al = 半字节(4个比特)掩码。
and al,dl ! 取dl的低4比特值。
add al,#0x30 ! 给al数字加上十六进制0x30
cmp al,#0x3a
jl outp !是一个不大于十的数字
add al,#0x07 !是a~f,要多加7
outp:
int 0x10
loop print_digit
ret
实验结果
实验2 实现系统调用
实验内容
实现系统调用 iam()
int iam(const char* name);
完成的功能是将字符串参数name的内容拷贝到内核中保存下来。要求name的长度不能超过23个字符。返回值是拷贝的字符数。如果name的字符个数超过了23,则返回“-1”,并置errno为EINVAL。
whoami()
第二个系统调用是whoami(),其原型为:
int whoami(char* name, unsigned int size);
它将内核中由iam()保存的名字拷贝到name指向的用户地址空间中,同时确保不会对name越界访存(name的大小由size说明)。返回值是拷贝的字符数。如果size小于需要的空间,则返回“-1”,并置errno为EINVAL。
上述两个系统调用都在kernal/who.c中实现。
评分标准
files中有testlab2.sh testlab2.c两个程序,将其复制到0.11的/usr/root/文件夹中,编译运行testlab2.c,运行testlab2.sh,它们就会输出你程序的得分。(我编写了一个挂载脚本syscall.sh和iam.c whoami.c程序用于单纯对系统调用进行测试 放在之前给出的代码中了)
基础知识
系统调用的实现
应用程序调用库函数(API);
API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
中断处理函数返回到API中;
API将EAX返回给应用程序。
使用get_fs_byte,.put_fs_byte在内核态和用户态之间传输数据。具体代码可参见/include/asm/segment.h不过知道这个接口怎么用即可。
添加系统调用需要去修改/include/linux/unistd.h中的系统调用号、system_call.s中的系统调用总数nr_system_calls,以及sys_call_table系统调用号对应的函数。
另外,在hdc/usr/include/下的文件和0.11下的/include的文件不是一个文件,当你修改了/include文件中的内容,还需要同步在hdc/usr/include/中进行修改
如果在实验过程中感到困惑,可参见0.11自己实现的一些系统调用,比如exit fork open write(在/kernel 和/lib下)
实验代码
为节约篇幅,删除了一些 注释
#include <errno.h> // get the errno and EINVAL
#include <linux/kernel.h>// get printk
#include <asm/segment.h>//unsigned char get get_fs_byte(const char* addr) void put_fs_byte(char val, char *addr)
#include <string.h> // strlen()
static char system_name [24];
int sys_iam(const char* name) {
char fs;
int size = 0;
char* first = name;
while((fs = get_fs_byte(first++))) {
++size;
if(size > 23) {
printk("\nthis is the last char %c\n", fs);
errno = -EINVAL;
return -1;
}
system_name[size-1] = fs;
}
system_name[size] = '\0';
printk("lucifer system's first system call sys_iam\n");
printk("this is the name ::%s::\n", system_name);
return size;
}
int sys_whoami(char* name, unsigned int size) {
unsigned int i = 0;
unsigned int length = strlen(system_name);
printk("\n\nthis is the whoami fun\nlength: %d\n", length);
//boundary
if(size-1 < length) {
errno = -EINVAL;
return -1;
}
printk("exec copy\n");
//copy
while(system_name[i]) {
put_fs_byte(system_name[i++], name++);
}
printk("from->%d\n",(int)system_name[i]);
printk("finished copy\n");
printk("i = %d\n", i);
//end flag '\0'
put_fs_byte(system_name[i], name);
printk("lucifer system's second system call sys_whoami\n");
return length;
}
实验结果
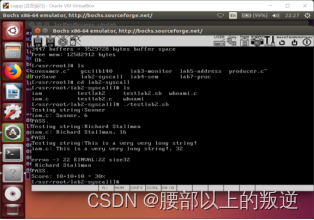
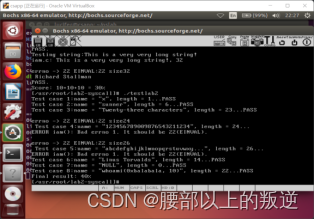
上述不知道为啥,超过24的我的就是不对,但是用自己写的iam.c whoami.c程序测试没问题。emmm…
实验3 进程运行轨迹的跟踪
实验内容
基于process.c(file/process.c)实现如下功能。
- 所有子进程都并行运行,每个子进程的实际运行时间一般不超过30秒;
- 父进程向标准输出打印所有子进程的id,并在所有子进程都退出后才退出;
在0.11上创建/var/process.log,记录操作系统从一开始到结束的进程运行轨迹。
格式应该为
%ld\t%ld\t%ld\n
pid X time
X:N(新建),J(就绪),R(运行),W(阻塞),E(退出)
如
12 N 1056
12 J 1057
4 W 1057
12 R 1057
13 N 1058
13 J 1059
使用/file/stat_log.py 对log进行统计,得到等待时间、周转时间和运行时间等信息。(./stat_log.py 你的process.log的路径)更多的请参考实验手册
修改0.11的时间片,对比前后的信息,回答如下问题。
结合自己的体会,谈谈从程序设计者的角度看,单进程编程和多进程编程最大的区别是什么?
你是如何修改时间片的?仅针对样本程序建立的进程,在修改时间片前后,log文件的统计结果(不包括Graphic)都是什么样?结合你的修改分析一下为什么会这样变化,或者为什么没变化?
基础知识
使用fork和wait两个系统调用,请自行查询。使用man, help, google, baidu等工具。查询时请注意0.11版本和当前系统的版本。
为了能监控所有进程的信息,日志文件需要在进程1之前就开始挂载,因此需要将init/main.c中文件系统初始化的代码从init函数中移动到其之前。
并使用下列代码创建/var/process.log文件
(void) open("/var/process.log",O_CREAT|O_TRUNC|O_WRONLY,0666);
0.11中没有fprintf,下面给出了源码(/kernel/printk.c)
#include <linux/sched.h>
#include <sys/stat.h>
static char logbuf[1024];
int fprintk(int fd, const char *fmt, ...)
{
va_list args;
int count;
struct file * file;
struct m_inode * inode;
va_start(args, fmt);
count=vsprintf(logbuf, fmt, args);
va_end(args);
if (fd < 3) /* 如果输出到stdout或stderr,直接调用sys_write即可 */
{
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t" /* 注意对于Windows环境来说,是_logbuf,下同 */
"pushl %1\n\t"
"call sys_write\n\t" /* 注意对于Windows环境来说,是_sys_write,下同 */
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (fd):"ax","cx","dx");
}
else /* 假定>=3的描述符都与文件关联。事实上,还存在很多其它情况,这里并没有考虑。*/
{
if (!(file=task[0]->filp[fd])) /* 从进程0的文件描述符表中得到文件句柄 */
return 0;
inode=file->f_inode;
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"pushl %2\n\t"
"call file_write\n\t"
"addl $12,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (file),"r" (inode):"ax","cx","dx");
}
return count;
}
jiffies,滴答记录了从开机以来的时钟中断次数(10ms一次),log文件中用其作为时间。
请在退出系统前,使用sync将信息强制写入到磁盘上。否则log中的信息不全。
会对进程状态切换的函数有sleep_on,fork,do_exit,sched,wake_up,pause等。
实验代码
int do_exit() {
...
/*process exit*/
fprintk(3, "%d\tE\t%ld\n", current->pid, jiffies);
/*end print*/
tell_father(current->father);
schedule();
return (-1);
...
}
schedule()
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE) {
/*wake up interruptible process*/
fprintk(3, "%d\tJ\t%ld\n", (*p)->pid, jiffies);
/*end wake up*/
(*p)->state=TASK_RUNNING;
}
...
if(task[next]->pid != current->pid) {
/*current process will sleep*/
// fprintk(3, "%d\tW\t%ld\n", pid, sleep_jiffies);
/*end sleep*/
/*Running */
if(current->state == TASK_RUNNING) {
fprintk(3, "%d\tJ\t%ld\n", current->pid, jiffies);
}
fprintk(3, "%d\tR\t%ld\n",task[next]->pid, jiffies);
/*end*/
}
switch_to(next);
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
if(current->pid != 0) {
/*interruptible*/
fprintk(3, "%d\tW\t%ld\n", current->pid, jiffies);
/*end interruptible*/
}
schedule();
return 0;
}
void sleep_on()
fprintk(3, "%d\tW\t%ld\n", tmp->pid, jiffies);
/*end print sleep*/
schedule();//give CPU to others
if (tmp) {
/*wake up*/
fprintk(3, "%d\tJ\t%ld\n", tmp->pid, jiffies);
/*end print*/
tmp->state=TASK_RUNNING;//wake up queue's nearly process
}
void interruptible_sleep_on
repeat: current->state = TASK_INTERRUPTIBLE;
/*process sleep*/
fprintk(3, "%d\tW\t%ld\n", tmp->pid, jiffies);
/*end print sleep*/
schedule();
if (*p && *p != current) {
/*wake up */
fprintk(3, "%d\tJ\t%ld\n", (**p).pid, jiffies);
/*end print*/
(**p).state=TASK_RUNNING;
goto repeat;
}
*p=NULL;
if (tmp) {
/*wake up*/
fprintk(3, "%d\tJ\t%ld\n", tmp->pid, jiffies);
/*end print*/
tmp->state=TASK_RUNNING;
}
void wake_up(struct task_struct **p)
{
if (p && *p) {
/*wake up*/
fprintk(3, "%d\tJ\t%ld\n", (**p).pid, jiffies);
/*end print*/
(**p).state=TASK_RUNNING;
*p=NULL;
}
}
copy_process()
task[nr] = p;
/*process created*/
fprintk(3, "%d\tN\t%ld\n", last_pid, jiffies);
/*ready to run*/
fprintk(3, "%d\tJ\t%ld\n", last_pid, jiffies);
/*write end*/
return last_pid;
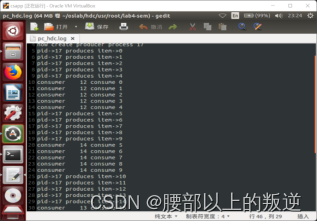
实验结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-15Ww6EMI-1669713106415)(file:///D:\QQ数据\1071698617\Image\C2C])]8TCJZAGH7LM1`]C%YV_MY.png)](https://img-blog.csdnimg.cn/22735ca1037e42139413e6dec57396b1.png)
结合自己的体会 从程序设计者的角度看 单进程编程和多进程编程最大的区别是什么
考虑问题不再是竖着线性的了。
同时需要去保证各类资源的访问的先后顺序。
单进程可以一路到底,代码的书写顺序就是执行顺序,但是多进程中,可能会存在一些其他的进程,修改了当前进程的资源,导致结果和预期的顺序结构不再一样;
你是如何修改时间片的? 仅仅针对样本程序建立的进程,在修改时间片前后 log文件的统计结果都是怎么样的,结合你的修改分析一下为什么会这样,或者为什么没变化?
修改进程0的初始值即可。(INIT_TASK)
当时间片权值增加后,单个任务运行时间增加,但是相应的,等待时间会增加。
如果时间片变短,内核时间会变少,因为cpu的主要时间花在调度进程上了。所以这是一个权衡的系统。没有最好的方法。
实验4 实现信号量
实验内容
在ubuntu下利用信号量用文件作为缓冲区解决生产者消费者问题
在0.11下实现信号量。
信号量各个函数的声明是(sem_t请自行实现)
sem_t *sem_open(const char *name, unsigned int value);
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
int sem_unlink(const char *name);
将ubuntu下的程序移植到0.11中,检验信号量是否正确。
该程序应当完成以下功能
- 建立一个生产者进程,N个消费者进程(N>1);
- 用文件建立一个共享缓冲区;
- 生产者进程依次向缓冲区写入整数0,1,2,…,M,M>=500;
- 消费者进程从缓冲区读数,每次读一个,并将读出的数字从缓冲区删除,然后将本进程ID和数字输出到标准输出;
- 缓冲区同时最多只能保存10个数。(M和缓冲区大小可适当调整)
如果正确。输出结果可能如下
10: 0
10: 1
10: 2
10: 3
10: 4
11: 5
11: 6
12: 7
10: 8
12: 9
后面的数字0开始从增长,前面的进程ID不确定。
基础知识
sem_open,sem_close,sem_wait,sem_post自行查阅。ubuntu下的接口和我们实现的接口并不一样。编译时需要带上-pthread
生产者消费者问题如何用信号量解决请参阅操作系统的书。
原子操作如何实现请参考kernel/blk_drv/ll_rw_blk.c中的lock_buffer和unlock_buffer函数。除了关注原子操作,还需要弄清楚sleep_on函数和wake_up函数的功能。
最好不要使用string.h。进行文件操作时,最好使用0.11的open,read,write,lseek,close等系统调用。具体用法见0.11源码。
使用printf输出后请使用fflush(stdout)刷新,否则输出次序可能不对。另外建议将输出重定向到文件中,0.11向终端信息输出过多就会混乱。
实验代码
删除了一定注释
ubuntu下pc.c
#define __LIBRARY__
#include <unistd.h>
#include <semaphore.h>
#include <stdio.h>
#include <linux/sched.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#define NR_TASKS 5 /*how many tasks created*/
#define NR_ITEMS 20 /*how many items produced*/
#define BUFFER_SIZE 5 /*size of file buffer*/
#define FULL "full"
#define MUTEX "mutex"
#define EMPTY "empty"
const char* FILENAME = "pc.log";
int kill = 0;
//Produce item put them into buffer
// file WRONLY
void producer(int file, sem_t *full, sem_t *empty, sem_t *mutex) {
unsigned int i;
int pid = getpid();
int pfull, pempty, pmutex;
/*get this value*/
sem_getvalue(full,&pfull);
sem_getvalue(empty,&pempty);
sem_getvalue(mutex,&pmutex);
printf("full \tvalue=%d\n",pfull);
printf("empty \tvalue=%d\n",pempty);
printf("mutex \tvalue=%d\n",pmutex);
for(i = 0; i < NR_ITEMS; ++i) {
sem_wait(empty);
sem_wait(mutex);
// if full then put from head
if(!(i%BUFFER_SIZE)) {
lseek(file, 0, SEEK_SET);
}
write(file, (char*)&i, sizeof(i));
printf("pid->%d\tproduces item->%d\n", pid,i);
fflush(stdout);
sem_post(mutex);
sem_post(full);
}
// producer have produced all items then kill all consumer
kill = 1;
}
//consume item from buffer
//file RDONLY
void consumer(int file, sem_t *full, sem_t *empty, sem_t *mutex) {
int pid = getpid();
unsigned int i;
printf("consumer%d have been created\n", pid);
while(!kill) {
sem_wait(full);
sem_wait(mutex);
if(!read(file, (char*)&i, sizeof(i))) {
lseek(file, 0, SEEK_SET);
read(file, (char*)&i, sizeof(i));
}
printf("consumer\t%d consume %d\n", pid, i);
sem_post(mutex);
sem_post(empty);
}
printf("pid %d now dead\n", pid);
fflush(stdout);
}
int main (int argc, char* argv[]) {
int i;
int fi, fo;
char* filename;
sem_t *full, *empty, *mutex;
// if have cmd arg then use it, otherwise use default path
filename = argc > 1 ? argv[1] : FILENAME;
fi = open(FILENAME,O_WRONLY);
fo = open(FILENAME,O_RDONLY);
full=sem_open(FULL,O_CREAT,0666,0);
empty=sem_open(EMPTY,O_CREAT,0666,BUFFER_SIZE);
mutex = sem_open(MUTEX, O_CREAT,0666,1);
if(full==(void*)-1
|| empty==(void*)-1
|| mutex==(void*)-1){
perror("sem_open failure");
}
//create producer process
if(!fork()) {
printf("now create producer process\n");
fflush(stdout);
producer(fi, full, empty, mutex);
goto END;
}
//create consumer process
for(i = 0; i < NR_TASKS; ++i) {
if(!fork()) {
consumer(fo, full, empty, mutex);
goto END;
}
}
//wait all subprocess exit
wait(&i);
END:
//release resoureces
close(fi);
close(fo);
//
sem_close(full);
sem_close(empty);
sem_close(mutex);
sem_unlink(FULL);
sem_unlink(EMPTY);
sem_unlink(MUTEX);
return 0;
}
0.11下pc.c
#define __LIBRARY__
#include <unistd.h>
#include <linux/semaphore.h>
#include <stdio.h>
#include <linux/sched.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
_syscall2(sem_t*, sem_open, const char*, name, unsigned int, value)
_syscall1(int, sem_wait, sem_t*, sem)
_syscall1(int, sem_post, sem_t*, sem)
_syscall1(int, sem_unlink, const char*, name)
#define NR_CONSUMERS 5
#define NR_ITEMS 20
#define BUFFER_SIZE 5
const char* FILENAME = "pc.log";
int ckill = 0;
void producer(int file, sem_t *full, sem_t *empty, sem_t *mutex) {
unsigned int i;
int pid = getpid();
for(i = 0; i < NR_ITEMS; ++i) {
sem_wait(empty);
sem_wait(mutex);
if(!(i%BUFFER_SIZE)) {
lseek(file, 0, SEEK_SET);
}
write(file, (char*)&i, sizeof(i));
printf("pid->%d\tproduces item->%d\n", pid,i);
fflush(stdout);
sem_post(mutex);
sem_post(full);
}
ckill = 1;
}
void consumer(int file, sem_t *full, sem_t *empty, sem_t *mutex) {
int pid = getpid();
unsigned int i;
printf("consumer%d have been created\n", pid);
while(!ckill) {
sem_wait(full);
sem_wait(mutex);
if(!read(file, (char*)&i, sizeof(i))) {
lseek(file, 0, SEEK_SET);
read(file, (char*)&i, sizeof(i));
}
printf("consumer\t%d consume %d\n", pid, i);
sem_post(mutex);
sem_post(empty);
}
printf("pid %d now dead\n", pid);
fflush(stdout);
}
int main (int argc, char* argv[]) {
int i;
int fi, fo;
int pfull, pempty, pmutex;
char* filename;
sem_t *full, *empty, *mutex;
filename = argc > 1 ? argv[1] : FILENAME;
fi = open(FILENAME,O_WRONLY);
fo = open(FILENAME,O_RDONLY);
full = sem_open("full", 0);
empty = sem_open("empty", BUFFER_SIZE);
mutex = sem_open("mutex", 1);
if(!fork()) {
printf("now create producer process\n");
fflush(stdout);
producer(fi, full, empty, mutex);
goto END;
}
for(i = 0; i < NR_CONSUMERS; ++i) {
if(!fork()) {
consumer(fo, full, empty, mutex);
goto END;
}
}
wait(&i);
END:
close(fi);
close(fo);
sem_unlink("full");
sem_unlink("empty");
sem_unlink("mutex");
return 0;
}
semaphore.h
#ifndefine __SEMAPHORE__
#define __SEMAPHORE__
typedef struct SEMAPHORE{
const char* name;//name of semaphore
struct task_struct *wait_task;//wait task of current semphore
struct SEMAPHORE *next;
unsigned int value;//value of semaphore
}sem_t;
#endif
sem.c
#include <linux/sem.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <asm/segment.h>
#include <unistd.h>
#include <asm/system.h>
sem_t *sem_head = NULL;
int sem_strcmp(char *p, char *s) {
for(;*p == *s; ++p, ++s) {
if(*p == '\0')
return 0;
}
return (*p - *s);
}
char* get_string_from_usr(char *usr) {
unsigned int length = 1;
char c;
char *kernel, *p = usr, *first;
while((c = get_fs_byte(p))) {
++length;
++p;
}
first = kernel = (char*)malloc(length);
p = usr;
while((c = get_fs_byte(p))) {
*first = c;
++p;
++first;
}
*first = '\0';
return kernel;
}
sem_t* sys_sem_open(const char *name, unsigned int value) {
//dummy head
if(!sem_head) {
sem_head = (sem_t*)malloc(sizeof(sem_t));
sem_head->next = NULL;
}
//check sem name if is created
char *pname = get_string_from_usr(name);
sem_t *sem = sem_head;
while(sem->next) {
//if found
if(sem_strcmp(sem->next->name, pname) == 0) {
return sem->next;
}
sem = sem->next;
}
//assign value to sem->next
sem->next = (sem_t*)malloc(sizeof(sem_t));
sem = sem->next;
sem->name = pname;
sem->value = value;
sem->wait_task = NULL;
return sem;
}
int sys_sem_unlink(const char *name) {
if(!sem_head || !sem_head->next) {//empty linked list
return -1;
}
sem_t *sem = sem_head, *tmp;
char *pname = get_string_from_usr(name);
while(sem->next) {
if(sem_strcmp(sem->next->name, pname) == 0) {
//delete it
tmp = sem->next;
sem->next = tmp->next;
//release space
free(tmp->name);
free(tmp);
free(pname);
return 0;
}
sem = sem->next;
}
free(pname);
return -1;
}
int sys_sem_wait(sem_t *sem) {
cli();
if(sem->value < 0) {
sleep_on(&sem->wait_task);
}
--sem->value;
sti();
return 0;
}
int sys_sem_post(sem_t* sem) {
cli();
++sem->value;
if(sem->value <= 1) {
wake_up(&sem->wait_task);
}
sti();
return 0;
}
实验结果
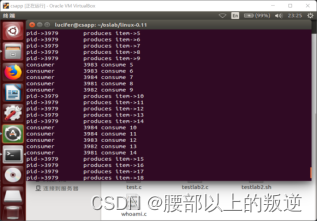
实验5 实现共享内存
实验内容
在ubuntu上编写利用共享内存做缓冲区的解决生产者消费者问题的代码。
在0.11上实现共享内存。
将ubuntu上的代码移植到0.11上,检验程序正确性。(请注意,代码运行完后系统应该能正常运行)
基础知识
段页式内存管理请参阅操作系统书。
共享内存函数shmget,shmat,shmdt请自行查阅。
在0.11下只要求实现shmget,shmat。(请注意,shmget的第一个参数不要用IPC_PRIVATE)
如何获得空闲物理页面请参考cope_process和get_free_page函数。如何进行地址映射请参考do_no_page,put_page。
如何找到空闲的线性地址请参考change_ldt函数。
实验代码
#define __LIBRARY__
#include <unistd.h>
#include <semaphore.h>
#include <stdio.h>
#include <linux/sched.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define NR_TASKS 5 /*how many tasks created*/
#define NR_ITEMS 20 /*how many items produced*/
#define BUFFER_SIZE 5 /*size of file buffer*/
#define FULL "full"
#define MUTEX "mutex"
#define EMPTY "empty"
int kill = 0;
void producer(int shmid, sem_t *full, sem_t *empty, sem_t *mutex) {
unsigned int i;
int pid = getpid();
int pfull, pempty, pmutex;
//mapping shmid to current process and get the pointer
void *shared_memory = shmat(shmid, NULL, 0);
unsigned int *shared = (unsigned int*)shared_memory;
fflush(stdout);
for(i = 0; i < NR_ITEMS; ++i) {
sem_wait(empty);
sem_wait(mutex);
// if full then put from head
shared[i%BUFFER_SIZE] = i;
printf("pid->%d\tproduces item->%d\n", pid,i);
fflush(stdout);
sem_post(mutex);
sem_post(full);
}
// producer have produced all items then kill all consumer
kill = 1;
if(shmdt(shared_memory) == -1) {
printf("%d producer shmdt failed\n", pid);
}
}
//consume item from buffer
//file RDONLY
void consumer(int shmid, sem_t *full, sem_t *empty, sem_t *mutex) {
int pid = getpid();
unsigned int i;
printf("consumer%d have been created\n", pid);
//mapping shmid to current process
void* shared_memory = shmat(shmid, NULL, 0);
unsigned int *shared = (unsigned int*)shared_memory;
while(!kill) {
sem_wait(full);
sem_wait(mutex);
i = shared[shared[BUFFER_SIZE]];
shared[BUFFER_SIZE] = (shared[BUFFER_SIZE]+1)%BUFFER_SIZE;
printf("consumer\t%d consume %d\n", pid, i);
sem_post(mutex);
sem_post(empty);
}
printf("pid %d now dead\n", pid);
fflush(stdout);
if(shmdt(shared_memory) == -1) {
printf("%d consumer shmdt failed\n", pid);
}
}
int main (int argc, char* argv[]) {
int i;
sem_t *full, *empty, *mutex;
int shmid = shmget((key_t)1234,
(BUFFER_SIZE+1) * sizeof(unsigned int)
, 0666 | IPC_CREAT); full=sem_open(FULL,O_CREAT,0666,0);
empty=sem_open(EMPTY,O_CREAT,0666,BUFFER_SIZE);
mutex = sem_open(MUTEX, O_CREAT,0666,1);
if(full==(void*)-1
|| empty==(void*)-1
|| mutex==(void*)-1){
perror("sem_open failure");
}
if(!fork()) {
producer(shmid, full, empty, mutex);
goto END;
}
for(i = 0; i < NR_TASKS; ++i) {
if(!fork()) {
consumer(shmid, full, empty, mutex);
goto END;
}
}
wait(&i);
END:
sem_close(full);
sem_close(empty);
sem_close(mutex);
sem_unlink(FULL);
sem_unlink(EMPTY);
sem_unlink(MUTEX);
return 0;
}
#define __LIBRARY__
#include <unistd.h>
#include <linux/sem.h>
#include <stdio.h>
#include <linux/sched.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/shm.h>
_syscall2(sem_t*, sem_open, const char*, name, unsigned int, value);
_syscall1(int, sem_wait, sem_t*, sem);
_syscall1(int, sem_post, sem_t*, sem);
_syscall1(int, sem_unlink, const char*, name);
_syscall2(int, shmget, key_t, key, size_t, size);
_syscall2(int, shmat, int, shmid, void*, shmaddr);
_syscall1(int, shmdt, void*, shmaddr);
#define NR_TASKS 5
#define NR_ITEMS 20
#define BUFFER_SIZE 5
#define FULL "full"
#define MUTEX "mutex"
#define EMPTY "empty"
int kill = 0;
void producer(int shmid, sem_t *full, sem_t *empty, sem_t *mutex) {
unsigned int i;
int pid = getpid();
void *shared_memory = shmat(shmid, NULL);
unsigned int *shared = (unsigned int*)shared_memory;
for(i = 0; i < NR_ITEMS; ++i) {
sem_wait(empty);
sem_wait(mutex);
shared[i%BUFFER_SIZE] = i;
printf("pid->%d\tproduces item->%d\n", pid,i);
fflush(stdout);
sem_post(mutex);
sem_post(full);
}
kill = 1;
if(shmdt(shared_memory) == -1) {
printf("%d producer shmdt failed\n", pid);
}
}
void consumer(int shmid, sem_t *full, sem_t *empty, sem_t *mutex) {
int pid = getpid();
unsigned int i;
printf("consumer%d have been created\n", pid);
void* shared_memory = shmat(shmid, NULL);
unsigned int *shared = (unsigned int*)shared_memory;
while(!kill) {
sem_wait(full);
sem_wait(mutex);
i = shared[shared[BUFFER_SIZE]];
shared[BUFFER_SIZE] = (shared[BUFFER_SIZE]+1)%BUFFER_SIZE;
printf("consumer\t%d consume %d\n", pid, i);
fflush(stdout);
sem_post(mutex);
sem_post(empty);
}
printf("pid %d now dead\n", pid);
fflush(stdout);
if(shmdt(shared_memory) == -1) {
printf("%d consumer shmdt failed\n", pid);
fflush(stdout);
}
}
int main (int argc, char* argv[]) {
int i;
sem_t *full, *empty, *mutex;
int shmid = shmget((key_t)1234,
(BUFFER_SIZE+1) * sizeof(unsigned int));
full = sem_open(FULL, 0);
empty = sem_open(EMPTY, BUFFER_SIZE);
mutex = sem_open(MUTEX, 1);
if(!fork()) {
producer(shmid, full, empty, mutex);
goto END;
}
for(i = 0; i < NR_TASKS; ++i) {
if(!fork()) {
consumer(shmid, full, empty, mutex);
goto END;
}
}
wait(&i);
END:
sem_unlink(FULL);
sem_unlink(EMPTY);
sem_unlink(MUTEX);
return 0;
}
#include <linux/kernel.h>
#include <linux/sched.h>
#include <sys/shm.h>
#include <linux/mm.h>
#include <errno.h>
shm shm_list[SHM_SIZE] = {
{0, 0, 0, 0}
};
int sys_shmget(key_t key, size_t size) {
int i;
unsigned long page;
if(size > PAGE_SIZE) {
printk("shmget: size %u cannot be greater than the page size %ud. \n", size);
return -ENOMEM;
}
if(key == 0) {
printk("shmget: key cannot be 0.\n");
return -EINVAL;
}
//if have Created
for(i = 0; i < SHM_SIZE; ++i) {
if(shm_list[i].key == key) {
add_mapping(shm_list[i].page);
return i;
}
}
//create new page mm.h
page = get_free_page();
if(!page) // not free page
return -ENOMEM;
for(i = 0; i < SHM_SIZE; ++i) {
if(shm_list[i].key == 0) {
shm_list[i].key = key;
shm_list[i].size = size;
shm_list[i].page = page;
return i;
}
}
free_page(page);
return -1;
}
void *sys_shmat(int shmid, void *shmaddr) {
unsigned long data_base, brk;
if(shmid < 0 || SHM_SIZE <= shmid
|| shm_list[shmid].page == 0
|| shm_list[shmid].key <= 0)
return (void*)-EINVAL;
data_base = get_base(current->ldt[2]);
brk = current->brk + data_base;
current->brk += PAGE_SIZE;
if(put_page(shm_list[shmid].page, brk) == 0)
return (void*)-ENOMEM;
return (void*)(current->brk - PAGE_SIZE);
}
int sys_shmdt(void *shmaddr) {
return -1;
}
实验结果
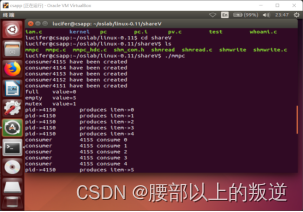
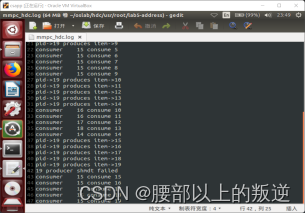
实验6 字符显示
实验内容
按下F12后,所有的数字字符和字母的输出都变成x
再次按下恢复原样。
如何做到向文件中的输出也变成x,如果你做到了的话,如何做到只改变终端的输出。
基础知识
当键盘上的键按下时,会触发键盘的终端。最后会让keyboard.S去解决。要实现按下之后的功能,参考其中代码即可编写出来。
对于终端的输出和文件的输出,需要分别修改console.c和file_dev.c中的代码。
实验代码
func:
pushl %eax
pushl %ecx
pushl %edx
call show_stat
popl %edx
popl %ecx
popl %eax
subb $0x3B,%al
jb end_func
cmpb $9,%al
jbe ok_func
subb $18,%al
cmpb $10,%al
jb end_func
cmpb $11,%al
ja end_func
ok_func:
cmpl $4,%ecx
jl end_func
movl func_table(,%eax,4),%eax
xorl %ebx,%ebx
jmp put_queue
end_func:
ret
int show_char = 0;
inline void press_F12(void) { show_char = !show_char;}
void con_write()
/*oslab 8*/
if(show_char) {
if((c >= 'A' && c <= 'Z')
||(c >= 'a' && c <= 'z')
||(c >= '0' && c <= '9'))
c = 'x';
}
/*oslab 8*/
int file_write()
tmp = get_fs_byte(buf++);
if(show_char &&
((tmp >= 'A' && tmp <= 'Z')
|| (tmp >= '0' && tmp <= '9')
|| (tmp >= 'a' && tmp <= 'z')
))
tmp = '*';
*(p++) = tmp;
实验结果

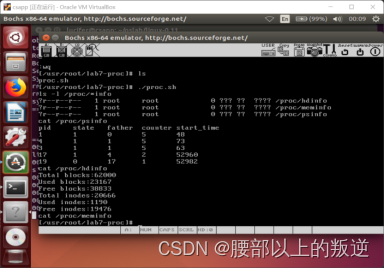
实验7 proc文件系统的实现
实验内容
实现proc文件系统中的psinfo,hdinfo读取此结点的信息时,显示当前进程所有的状态信息。
如利用cat /proc/psinfo
这些结点在内核启动时自动创建,功能在fs/proc.c中实现。
基础知识
proc是一个虚拟的文件,它并不存在,但是你可以像对待其他文件一样对待它。读取信息,显示。
cat 的基本功能仅仅是读取文件信息,输出到终端。注意观察read函数的作用。
#include <stdio.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
char buf[513] = {'\0'};
int nread;
int fd = open(argv[1], O_RDONLY, 0);
while(nread = read(fd, buf, 512))
{
buf[nread] = '\0';
puts(buf);
}
return 0;
}
更多,更丰富的内容可参考指导书。https://hoverwinter.gitbooks.io/hit-oslab-manual/content/sy7_proc.html
实验代码
#include <errno.h>
#include <linux/sched.h> // struct task_struct* task[NR_TASKS]
#include <linux/kernel.h> // include malloc() and free() size should less than 4KB 1 page
#include <linux/mm.h> // get free page calc_mem
#include <linux/head.h>//mm
#include <asm/segment.h>
typedef int (*pr_ptr)(char* buf, int count, off_t* pos);
#define set_bit(bitnr,addr) ({\
register int __res; \
__asm__("bt %2, %3;setb %%al":"=a"(__res):"a"(0),"r"(bitnr),"m"(*(addr))); \
__res; })
int read_hd(char* buf, int count, off_t* pos) {
struct super_block* sb;
int used = 0;
int read = 0;
int i, j;
char* proc_buf;
if(!(proc_buf = (char*)malloc(sizeof(1024)))) {
printk("no memory to alloc!\n");
return 0;
}
//dev 0x301 789
sb = get_super(0x301);
//blocks
read += sprintf(proc_buf+read, "Total blocks:%d\n",sb->s_nzones);
i = sb->s_nzones;
while(--i >= 0) {
if(set_bit(i & 8191, sb->s_zmap[i>>13]->b_data))
++used;
}
read += sprintf(proc_buf+read, "Used blocks:%d\n", used);
read += sprintf(proc_buf+read, "Free blocks:%d\n", sb->s_nzones-used);
// inodes
read += sprintf(proc_buf+read, "Total inodes:%d\n", sb->s_ninodes);
used = 0;
i = sb->s_ninodes+1;
while(--i >= 0){
if(set_bit(i&8191, sb->s_imap[i>>13]->b_data))
++used;
}
read += sprintf(proc_buf+read, "Used inodes:%d\n", used);
read += sprintf(proc_buf+read, "Free inodes:%d\n", sb->s_ninodes-used);
//to buffer
proc_buf[read] = '\0';
for(i = *pos, j = 0; i < read && j < count; ++i, ++j)
put_fs_byte(proc_buf[i], buf+j);
free(proc_buf);
*pos += j;
return j;
}
int read_ps(char* buf, int count, off_t* pos) {
int read = 0;
int i = *pos, j = 0;
struct task_struct ** p;
char* proc_buf;
if(!(proc_buf = (char*)malloc(1024))) {
printk("no memory to alloc!");
return 0;
}
read += sprintf(proc_buf+read,"pid\tstate\tfather\tcounter\tstart_time\n");
for(p = &FIRST_TASK + 1; p <= &LAST_TASK; ++p) {
if(*p) {
read += sprintf(proc_buf+read,"%ld\t%ld\t%ld\t%ld\t%ld\n",
(*p)->pid, (*p)->state, (*p)->father,
(*p)->counter,(*p)->start_time);
}
}
proc_buf[read] = '\0';
if(!read)
return 0;
for(; i < read && j < count; ++i, ++j) {
if(!proc_buf[i])
break;
put_fs_byte(proc_buf[i], buf+j);
}
free(proc_buf);
*pos += j;
return j;
}
int read_mem(char* buf, int count, off_t* pos) {
int i,j,k,free=0;
long* pg_tbl;
char* proc_buf;
int read = 0;
if(!(proc_buf = (char*)malloc(1024))) {
printk("no memory to alloc!\n");
return 0;
}
read += sprintf(proc_buf+read, "total page:%d\n", PAGING_PAGES);
for(i = 2; i < 1024; ++i) {
if(1 & pg_dir[i]) {
pg_tbl = (long*)(0xfffff000 & pg_dir[i]);
for(j=k=0; j < 1024; ++j) {
if(pg_tbl[j] & 1)
++k;
}
read += sprintf(proc_buf+read,"Pg-dir[%d] uses %d pages\n", i, k);
}
}
for(i = *pos, j = 0; i < read && j < count; ++i, ++j)
put_fs_byte(proc_buf[i], buf+j);
*pos += j;
return j;
}
static pr_ptr pr_table[] = {
read_ps, /* /proc/psinfo */
read_hd, /* /proc/hdinfo */
read_mem /* /proc/mminfo */
};
#define NR_DEVS ((sizeof (pr_table)) / (sizeof (pr_ptr)))
int read_proc(int dev, char* buf, int count, off_t* pos) {
int i = 0;
pr_ptr call_addr;
if(dev >= NR_DEVS)
return -ENODEV;
if(!(call_addr = pr_table[dev]))
return -ENODEV;
return call_addr(buf, count, pos);
}
实验结果
总结
一点一点按照实验的要求独立完成这些实验,难度还是有的。
网上的许多博客都不是太正确。给的代码和实际的运行结果差的也很多。
最开始本来以为有网上的代码保底,但是后来反而不想看了。
第0,6个实验每个花费半天,1 2 3 7每个花一整天,4 5 每个花整整2天。
平均每个实验要遇到4个大BUG,不知道多少个小bug。定位bug也是一件很痛苦的事情。
操作系统毕竟是个系统。你首先得知道bug出在哪里,这就得花费不少心血,看不少代码。
之后就是怎么去改,怎么改了才能对。一个bug常常就是几个钟头。
记忆比较深的是信号量的if(!fork),open,共享内存的free free page,文件系统的死循环。
再之后就是时常忘记备份,导致被改掉了没法看。
有时候备份又过多,都搞晕了,未来做系统肯定得先把这个流程设计好。其次是遇到问题之后,得通过多样的方式去记录问题,方便之后查看和定位错误。还有就是对不同的项目应该分在不同文件夹,干净。代码的注释更是不能少,多了就晕了。多个版本的代码应当备注版本和当前的功能与可能存在的bug,参考man的写法。写程序之前就得现有思路,不然越写越乱,就写不出来了。多查手册,少百度。真正的能在内核中跑的代码比我上面自己写的代码要好不少,当然一来就跟最优秀的人比肯定是比不过的。但是做事情总得有点精神。编程也是,通过看别人的,再比较一下自己的代码,其实就知道差距在哪里了。这倒不是说非得吹毛求疵,好像代码和人有一个能跑就行。只是一种做事的态度。能写得更好就做到更好。每个人多一点奉献,社会才会少一点麻烦的事情。
常言,迷时师渡,悟了自渡。我们不是六祖慧能,没那么高的天分,我们能做的是时时勤拂拭。具体到代码,就是时时刻刻锻炼,时时刻刻思考,不断地精益求精。另有一言,勿在浮沙筑高台,勿为繁华易匠心。这话算是我做操作系统实验的原因。操作系统对计科来到底意味着什么?意味着底层视角,意味着系统,意味着先进的技术,意味着编程的智慧,意味着软件立命根本,意味着核心与基础。基础牢固,你才知道你能做到什么样子,你才能更进一步的去谋划事情,再到做成事情。
大学的话说的很有道理啊!知物有本末,事有终始,则近道矣!
最后的最后,用linus的一句话结尾吧。
Talk is cheap, show me the code.










![[oeasy]python0022_ python虚拟机_反编译_cpu架构_二进制字节码_汇编语言](https://img-blog.csdnimg.cn/img_convert/ed53e6b51005e95514adaf4525ce37d3.png)