目录索引
- ==介绍:==
常见匹配模式:
- ==re.match()方法:==
常规匹配:泛匹配:
- ==匹配目标-匹配分组:==
贪婪匹配:非贪婪匹配:
介绍:
- 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特殊字符及这些特定字符的组合,组成一个 “规则字符串”, 这个“规则字符串”用来表达对字符串的一种逻辑过滤。
- 非python独有
- python里面是使用re模块来实现的,不需要额外进行安装,是python内置模块
常见匹配模式:
| 模式 | 描述 |
|---|---|
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面表达式。 |
| {n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| ( ) | 匹配括号内的表达式,也表示一个组 |
注 意:
- . *? 非常常用
- ^和$表示匹配的位置,一般不含有实际匹配意义
re.match()方法:
re.match()方法尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None
语法:
变量名 = re.match(正则表达式,待匹配字符串)
常规匹配:
这种匹配一般比较精确而具体
#举个例子:
#导入模块包
import re
content = 'Hello 123 456789 World_This is a Regex Demo' # 准备好的待匹配字符串
res=re.match('^Hello\s\d\d\d\s\d{6}\s\w{10}.*Demo$', content)
print(res) # 返回的是一个匹配对象
print(res.group()) # .group()获取匹配内容
print(res.span()) # 查看匹配长度
print(len(content)) # len统计字符串数量
呈现效果:
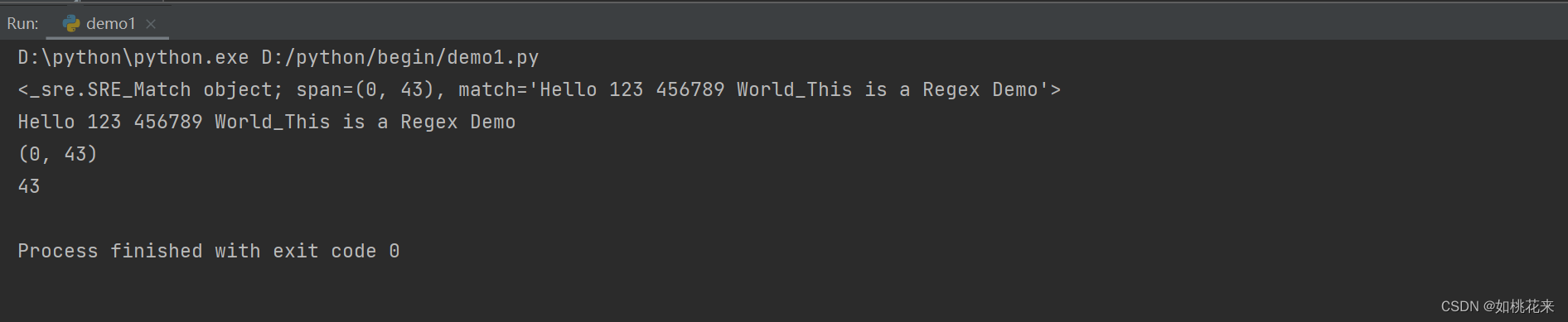
- 直接打印返回的是一个对象,所以我们要通过group进行输出,group从1开始,没写参数表示全部输出匹配内容。
- 第二行的意思是,从0开始,长度为43,计算规则(43-0)第二个参数减去第一个参数就是长度。
泛匹配:
匹配很宽泛,根据几个关键词展现匹配的相关内容。
#举个例子:
import re
content = 'Hello 123 4567 World_Thixs is a Regex'
result = re.match("He.*?Regex",content)
print(result.group())#获取匹配内容
print(result.span())#获取匹配长度
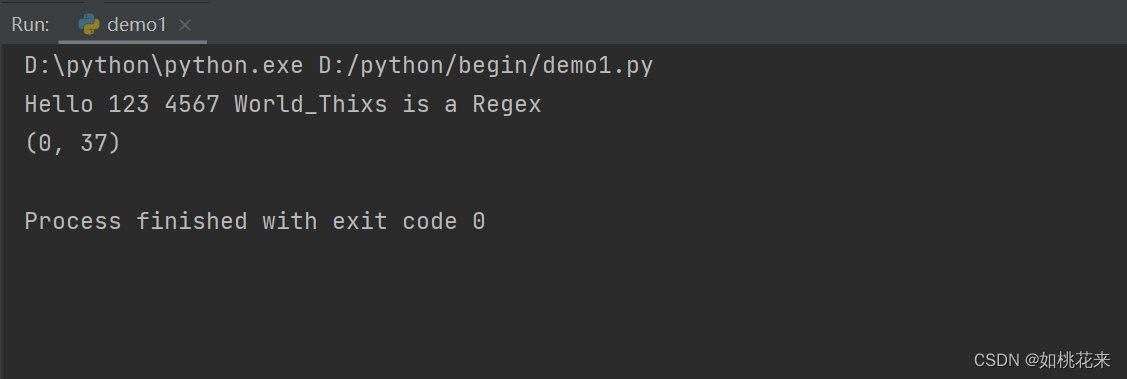
呈现效果:
匹配目标-匹配分组:
为了匹配字符串中具体的目标,可以使用()进行分组匹配
#举个例子:
import re
content = 'qwe Hello 1234567 World_This is a Regex Demo'
# 在匹配目标值的时候 目标值的前后特征一定要给明确(原样保留)(限定)
result = re.match('qwe\s(\w+)\s(\d{7}).*Demo',content)
print(result.group()) # 获取匹配内容
print(result.group(1)) # 提取第一组表达式内匹配到的字符
print(result.group(2)) # 提取第二组表达式内匹配的字符
- group的数从1开始,括号内的数据就是分组的数据
- 空格要用\s替换(推荐)
- +号表示匹配至少一个,通过\w+把字母串"Hello"匹配掉,通过\d{7}表示匹配七个任意数字
贪婪匹配:
尽可能多的去匹配,最大可能匹配多的字符
#举个例子:
import re
# 匹配尽可能多的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+)\s.*Demo$', content)
print(result)
print(result.group(1))
呈现效果:
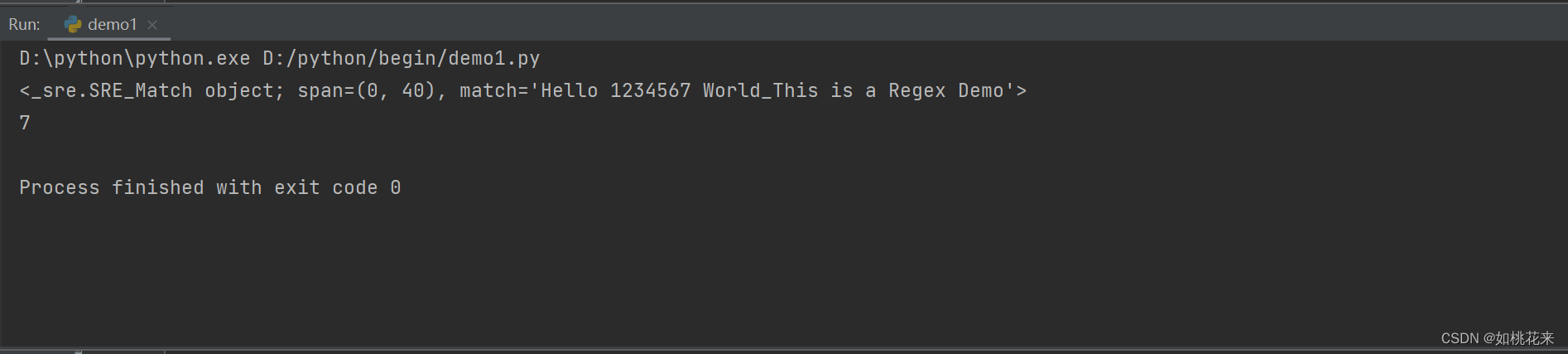
- 因为采用的是贪婪匹配,所以它会尽可能多匹配,d+只要求至少一个数字,那么贪婪匹配就只会给它留一个。
非贪婪匹配:
尽可能少的去匹配
#举个例子:
import re
# 匹配尽可能少的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
print(result.group(1))
呈现效果:
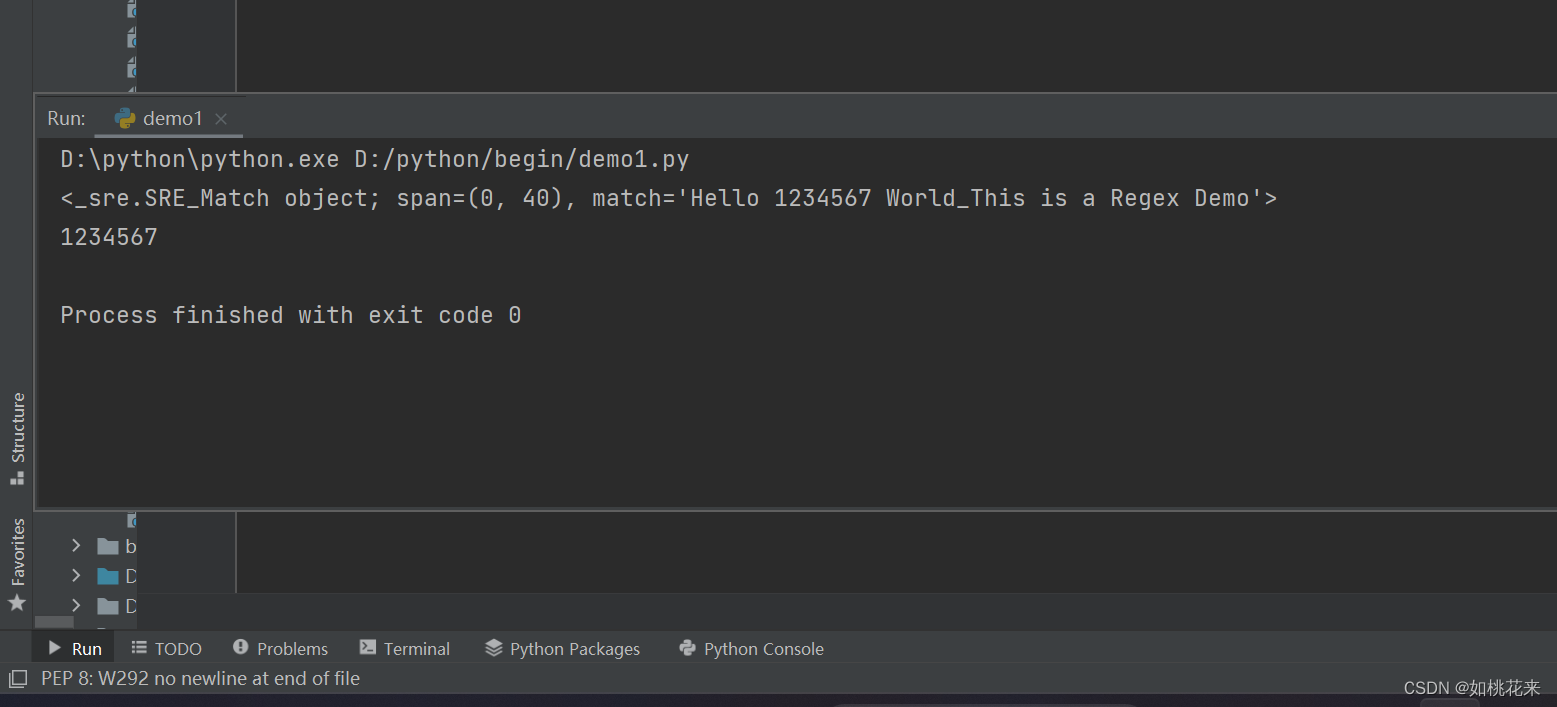
因为要尽可能少的去匹配,所以d+直接匹配了七个数字,.*? 可以以任意长度,那么0长度也可以。





![[架构之路-176]-《软考-系统分析师》-1-嵌入式系统分析与设计 - 实时性(任务切换时间、中断延迟时间、中断响应时间)、可靠性、功耗、体积、成本](https://img-blog.csdnimg.cn/4273303146bb413ea9ef10879cd6ede1.png)