WizardKM:Empowering Large Language Models to Follow Complex Instructions
- Introduction
- 参考
Introduction
作者表明当前nlp社区的指令数据比较单一,大部分都是总结、翻译的任务,但是在真实场景中,人们有各式各样的需求,这限制了模型的通用性。
作者提到这种人类标注的qa数据如果质量比较高,那么将很好的释放模型的性能,但是现在获取数据存在一些问题:
- 标注这类数据是非常费时费力的,并且十分昂贵。
- 由于labeler的专业程度有限,很难获取到优质的数据。
基于上述问题,作者提出了一个可以短时间内大量构建高质量数据的方法。
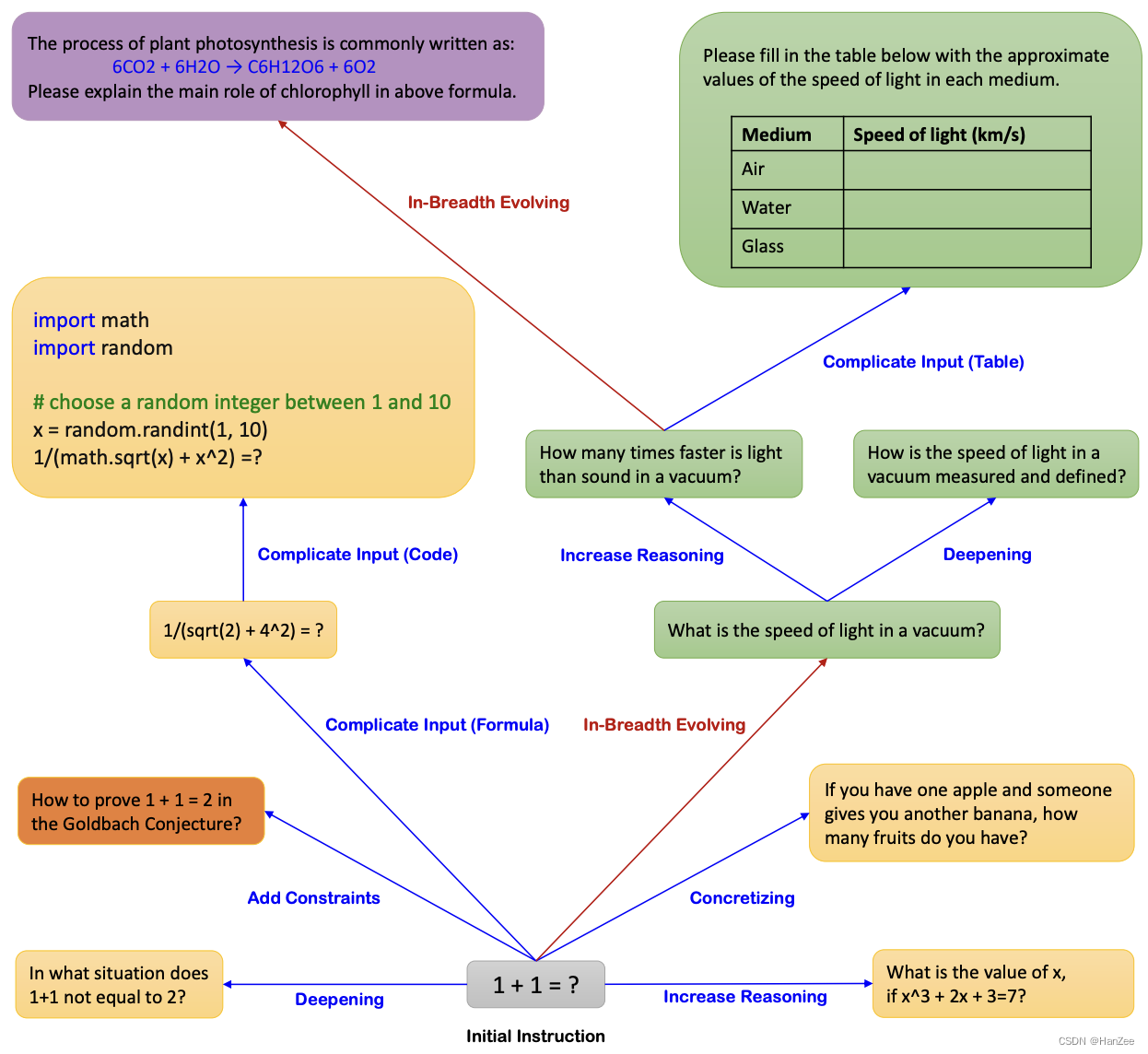
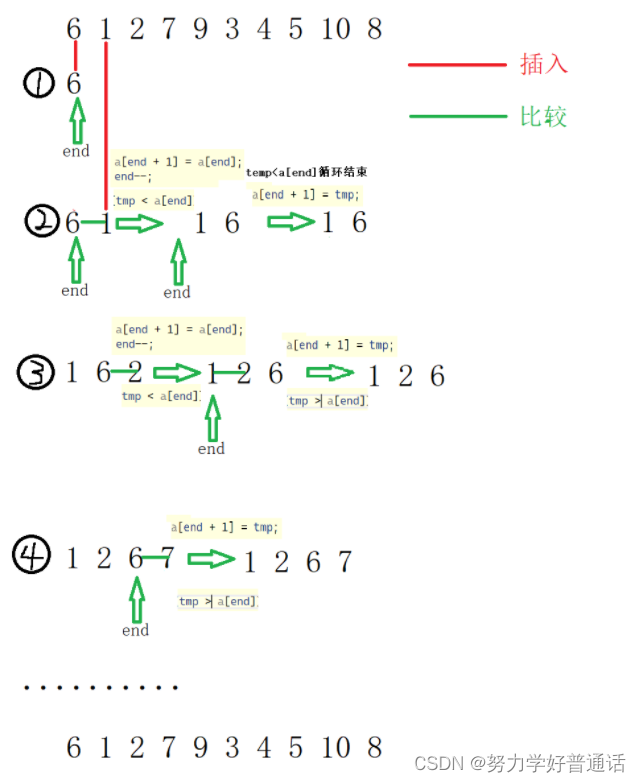
如上图,作者把这个方法叫做Evol-Instruct,从一个1+1等于多少开始,作者从两个方向对数据进行扩充:深度方向、广度方向。然后把问题送入ChatGPT获得qa数据对,然后对数据进行筛选。
为了验证这个方法的有效性,把用上述方法生成的数据,通过Llama7B微调,把它叫做WizardLM,然后与Alpaca、Vicuna进行对比。作者通过Alpaca的175条初始化数据通过Evol-Instrcut方法生成250k条数据,为了公平起见,作者在这些数据中sample了70k数据进行对比。
实验发现:
- Evol- instruct生成的数据优于ShareGPT的数据。
- 在复杂的测试指令下,标注者更喜欢WizardLM的输出,而不是ChatGPT的输出。
参考
https://arxiv.org/pdf/2304.12244.pdf