千呼万唤始出来,终于来到了bert。本篇博客先介绍预训练部分,dataset部分只介绍简洁输入输出,详细的另行更新新的blog。
目录
1.model
1.1bert总述
1.2输入表示
1.3Encoder
1.3.1验证输出
1.4掩敝语言模型mlm
1.4.1forward探索
LayerNorm与BatchNorm:
X[batch_idx, pred_positions]切片操作
1.4.2验证一下
1.5对下一句预测
1.6整合代码
2.BertDataset
3.预训练Bert
3.1准备数据
3.2定义一个小型的bert
3.3定义损失函数
3.4训练
3.5用Bert表示文本
3.5.1单个句子
3.5.2句子对
1.model
1.1bert总述
1.基于微调的nlp模型;
2.与训练模型时抽取了足够多的信息;
3.新的任务只需再添加输出层。
4.是只有编码器的transformer。
1.2输入表示
输入句子对+片段嵌入(segment)+可学习位置编码(pos)
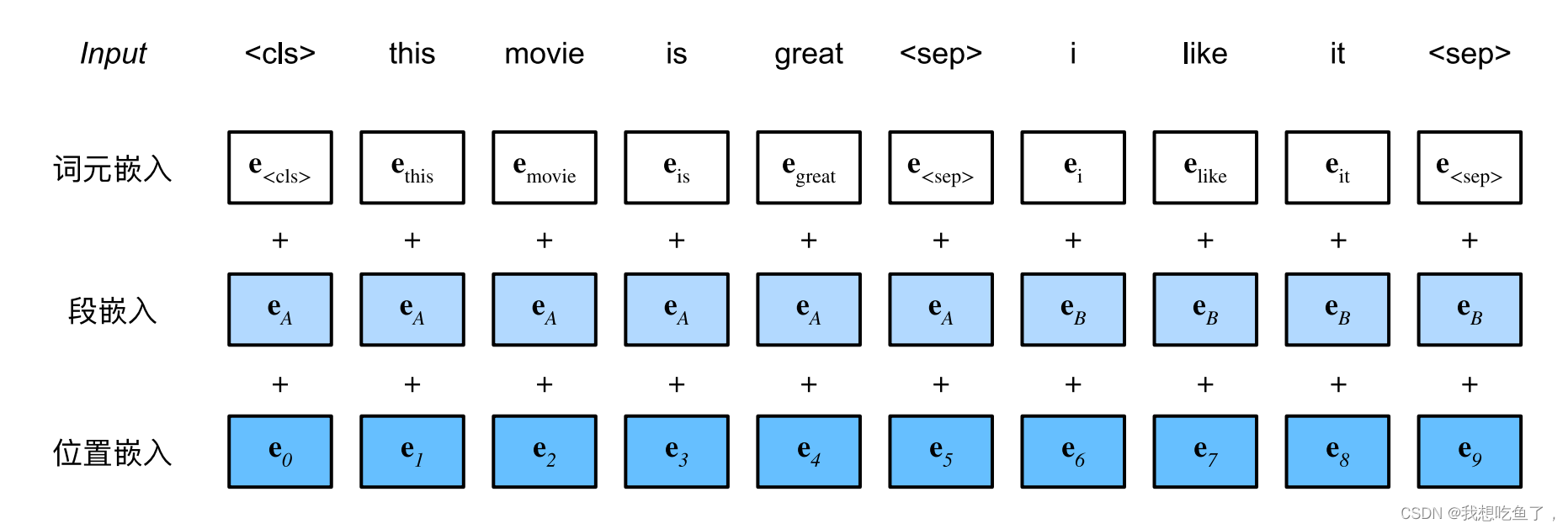
### 给两个句子变成bert的输入
### 在句子前加上cls和sep分隔符;segment标记(段嵌入)为0,如果有第二个句子(句子对),在第二个句子后面加上sep分隔符,并segments赋予1
总结一下:第一个句子+cls与sep;第二个句子+sep。
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输⼊序列的词元及其⽚段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记⽚段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments1.3Encoder
### 新加了segment_emb,输入是2,因为句子对的segments分别为0,1
### 随机初始化pos,bs=1
### 类比Transformer多了一个segment_emb和可学习的pos
### 对于emb,传入(bs,T),传出(bs,T,emb),在此emb=h;;在emb之前,T里面的数[0,vocabsize],emb需要传入取值范围数目和emb嵌入数,将里面的T表达的数映射到emb个表达。
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌⼊是可学习的,因此我们创建⼀个⾜够⻓的位置嵌⼊参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量⼤⼩,最⼤序列⻓度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X在forward里面,传入的只是前面函数的tokens(bs,T),与segments(bs,T),pos是在里面添加的,且tokens与seg也是在里面做emb的。---(bs,T)--(bs,T,emb(h)). emb=h
补充一下,emb里面的nn.Embedding(vocab_size, num_hiddens),表示原来(bs,T)中的T,值域为[0,vocabsize],所以使用emb也就是h来表示这么多数的独特位置。emb取值没有特定的要求,但通常会在几十到几百之间,具体取决于数据集的大小和复杂性。
关于bert里面的pos切分:创建了一个randn的tensor,每次从里面抽取数值,且必须是3维,因为X是(bs,T,h),使用三维且第一维为1可利用广播在每个bs上添加pos
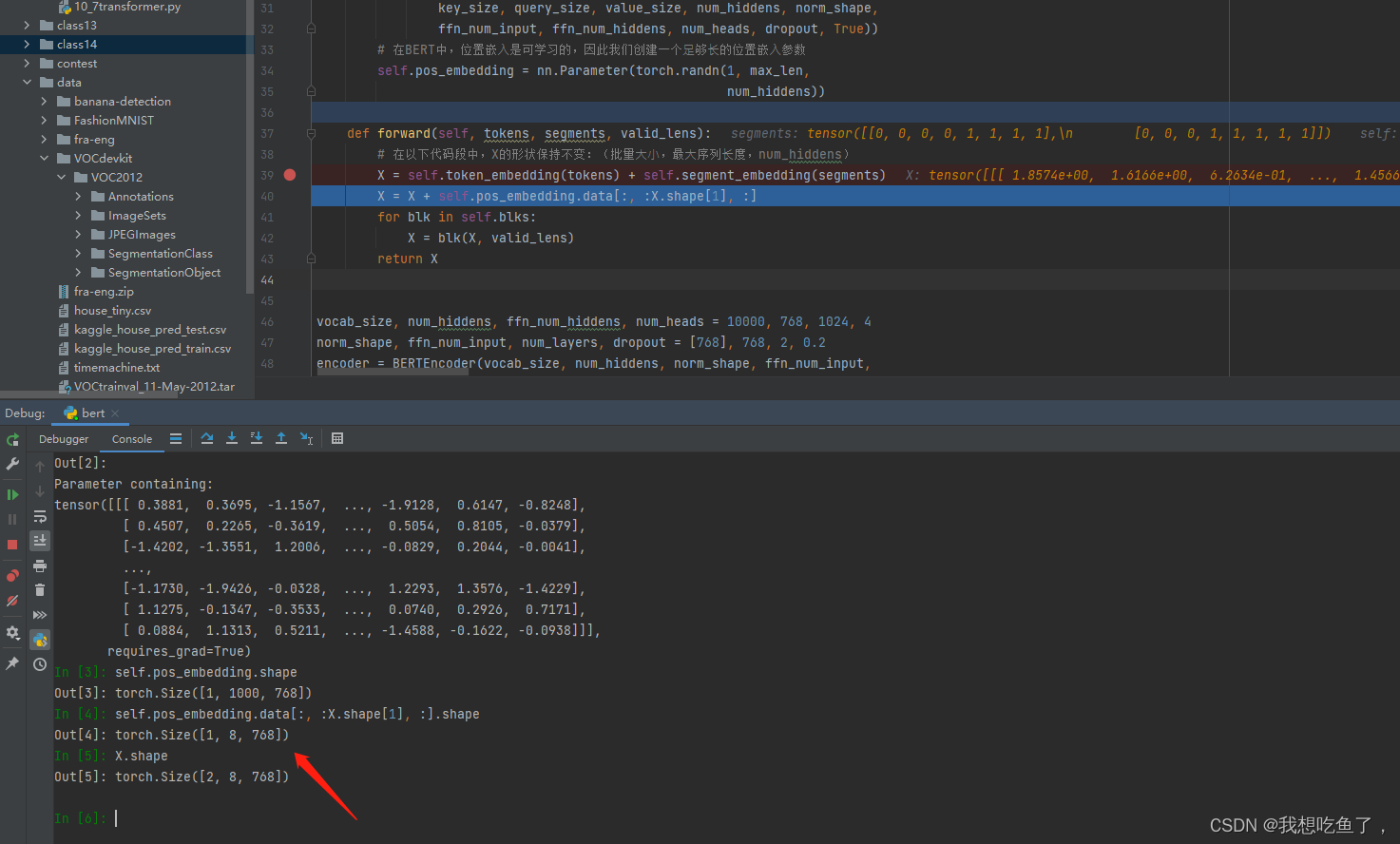
最终得到的X为加上seg与pos的,加法形状是不会改变的,输出的为(bs,T,h)。
1.3.1验证输出
### 验证一下,其中vocab为1w,h=768,heads=4
### tokens为(bs,T),segments为(bs,T)为tokens里面相应的句段位置标记。
### 经过encoder后,shape为(bs,T,h),对每个句子提取了h维度的信息
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
'''
torch.Size([2, 8, 768])
'''1.4掩敝语言模型mlm
### 传入encoder的输出X(bs,T,h),并传入pred_positions(bs,Tmask)表示要预测的位置。计算得到各个预测位置对应的预测值--类似cls。输出形状为(bs,Tmask,len(v)).
#@save
class MaskLM(nn.Module):
"""BERT的掩蔽语⾔模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat1.4.1forward探索
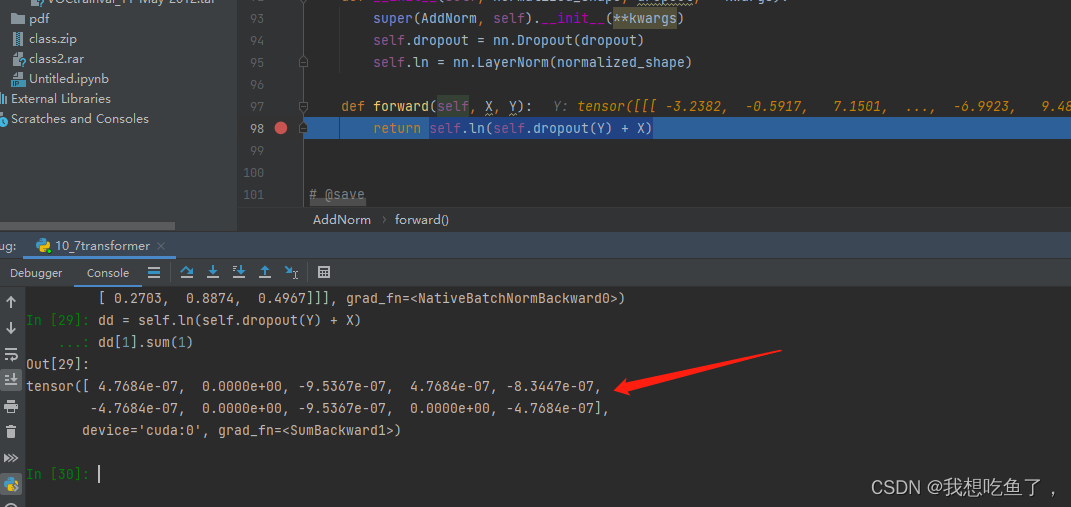
LayerNorm与BatchNorm:
LayerNorm是对每个每个样本的所有特征做归一化(0,1),对最后一维进行操作,所以传入的参数是最后一维(h)

原代码验证一下,确实是对每个tensor的最后一维进行了归一化:
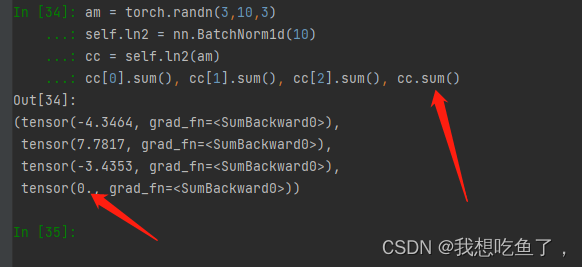
BN则是对所有的bs进行了整体归一化:
X[batch_idx, pred_positions]切片操作
X是个三维tensor,bidx和npp都是一维tensor,则切片的时候,对应的是第一个维度里面的数字代表X切的第一个维度位置,第二个维度里面的数字表示X要切的第二个维度位置。每次切片都是索引前两维位置,然后对应第三维的数全取。
举个例子,这里好演示将h=2赋值。X1是(bs,T,h)也就是enc_output,要索引的位置分别为第一个bs[1,5,2];第二个[6,1,5]。所以分别repeat_interleave操作将batch_idx(0,1)分别对应npp的数量复制,确保npp里面的每个元素都有对应的batch_idx。以切片后的[18,19]为例,其对应的切片就是0,1;第1个bs里面的第1位。
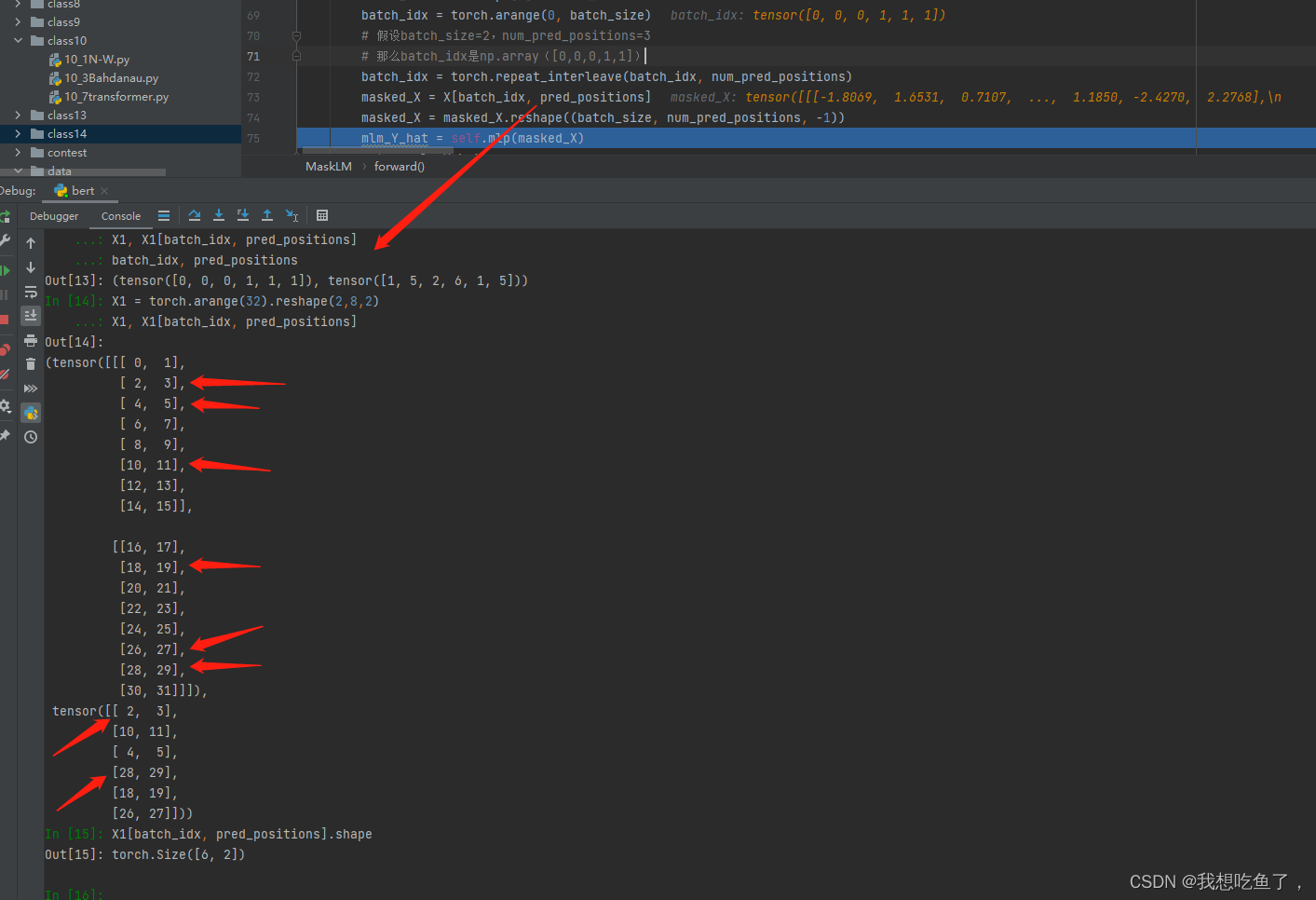
切片后为(bs*Tmask,h),再重新reshape为(bs,Tmask,h)其中Tmask为一个T中mask的数量。
1.4.2验证一下
### 标注的都是Tmask的位置,mlm_Y的形状为(bs,Tmask)
### 送入交叉熵的是hat(bs×T,vocab)表示对每个Tmask的预测概率值,共有vocab个预测,有些像cls;与(bs×Tmask,)每个元素都是对应Tmask的对应vocab的标记类:
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape
'''
torch.Size([6])
'''1.5对下一句预测
这里注意,是在整合的时候传入的是抽取<cls>类后的encoder_out,并不是全部的,所以输入尺寸为(bs,1,h).
#@save
class NextSentencePred(nn.Module):
"""BERT的下⼀句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,T×num_hiddens)
return self.output(X)encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输⼊形状:(batchsize,1×num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
'''
torch.Size([2, 2])
'''flatten里面的start_dim=1,表示从dim=1开始展平,输出为(bs,1×h)。
最终输出为(bs,2)。
1.6整合代码
#@save
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# ⽤于下⼀句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat强调一下:encoder传入tokens(bs,T),输出(bs,T,len(v))。
2.BertDataset
这一块先简单写写传出值,bert的文本操作还是很复杂的,值得单独给他出一篇blog。
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)
for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y) in train_iter:
print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,
pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,
nsp_y.shape)
break
'''
torch.Size([512, 64]) torch.Size([512, 64]) torch.Size([512]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512])
'''tokens_X为传入数据(bs,T) ;
segments_X为传入数据的段位置(bs,T) ; valid_lens_x就是有效长度(bs) ;
pred_positions_X为预测mask的位置(bs,Tmask),其中Tmask是T的15% ;
mlm_weights_X为是否真的要预测(bs,Tmask),1为真,0为对应pad部分,不用预测 ;
mlm_Y为要预测的真实标记值(bs,Tmask) ; nsp_Y为是否下一句连续为(bs)。
3.预训练Bert
3.1准备数据
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)3.2定义一个小型的bert
### n_heads=2,h=128,n_layers=2
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()3.3定义损失函数
### 构造辅助损失函数,用于计算mlm和nsp的损失值,相加
### mlm_Y_hat为(bs,Tmask,len(v))为对应Tmask预测的各个类分数;nsp_Y_hat为(bs,2),为对应句子对是否为相连的。
#@save
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X,
segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y):
# 前向传播
_, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X,
valid_lens_x.reshape(-1),
pred_positions_X)
# 计算遮蔽语⾔模型损失
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1, 1)
mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
# 计算下⼀句⼦预测任务的损失
nsp_l = loss(nsp_Y_hat, nsp_y)
l = mlm_l + nsp_l
return mlm_l, nsp_l, l这里计算损失就不要encoder_out了。注意mlm_l计算式,除weights是<pad>不算loss,最后再除weights数表示对每个预测取平均值。
3.4训练
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.Adam(net.parameters(), lr=0.01)
step, timer = 0, d2l.Timer()
animator = d2l.Animator(xlabel='step', ylabel='loss',
xlim=[1, num_steps], legend=['mlm', 'nsp'])
# 遮蔽语⾔模型损失的和,下⼀句预测任务损失的和,句⼦对的数量,计数
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,\
mlm_weights_X, mlm_Y, nsp_y in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_x = valid_lens_x.to(devices[0])
pred_positions_X = pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0])
trainer.zero_grad()
timer.start()
mlm_l, nsp_l, l = _get_batch_loss_bert(
net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)
l.backward()
trainer.step()
metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1,
(metric[0] / metric[3], metric[1] / metric[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print(f'MLM loss {metric[0] / metric[3]:.3f}, '
f'NSP loss {metric[1] / metric[3]:.3f}')
print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on '
f'{str(devices)}')中间有一托都是挪到gpu上
训练命令行:
train_bert(train_iter, net, loss, len(vocab), devices, 50)3.5用Bert表示文本
训练完bert后,可以用它来表示单个文本、文本对或其中的任何单元。
def get_bert_encoding(net, tokens_a, tokens_b=None):
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
token_ids = torch.tensor(vocab[tokens], device=devices[0]).unsqueeze(0)
segments = torch.tensor(segments, device=devices[0]).unsqueeze(0)
valid_len = torch.tensor(len(tokens), device=devices[0]).unsqueeze(0)
encoded_X, _, _ = net(token_ids, segments, valid_len)
return encoded_X返回的是经过encoder的(1,T,h)
3.5.1单个句子
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]
'''
(torch.Size([1, 6, 128]),
torch.Size([1, 128]),
tensor([0.0302, 1.1762, 0.0397], device='cuda:0', grad_fn=<SliceBackward0>))
'''其中,0表示的是'<cls>'词元。encoded_text[:, 0, :]其本质是将句子中<cls>对应的h个encoder信息抽出来,其表示整个句子的BERT表示。
3.5.2句子对
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]
'''
(torch.Size([1, 10, 128]),
torch.Size([1, 128]),
tensor([-1.1622, 0.5201, -0.1601], device='cuda:0', grad_fn=<SliceBackward0>))
'''前一个句子+2(cls与sep),后一个句子+1(sep)。所以T=4+2+3+1=10。