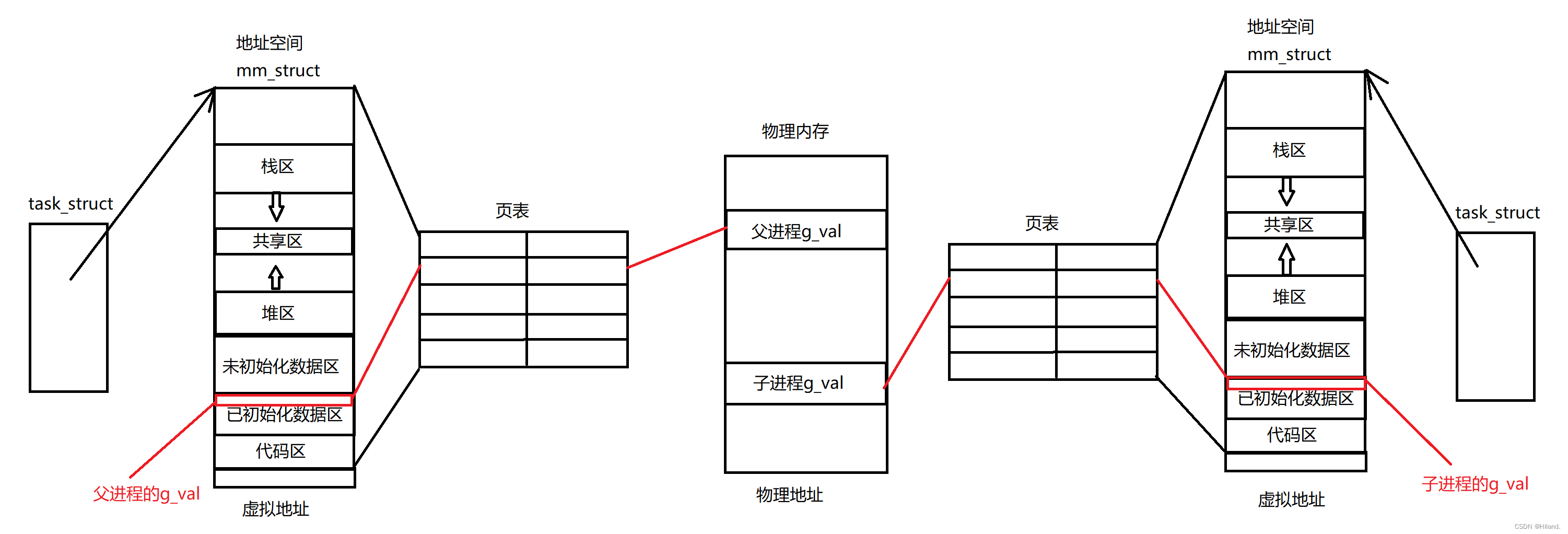
你好,我是何辉。今天我们来聊一聊Dubbo的大厂高频面试题。
大厂面试,一般重点考察对技术理解的深度,和中小厂的区别在于,不仅要你精于实战,还要你深懂原理,勤于思考并针对功能进行合理的设计。
网上一直流传着“面试造火箭,工作拧螺丝”的大厂面试要求,其实原因也很简单,一来面试竞争者多,需要设置门槛,二来是期望尽可能挑选出综合素质能力出众的面试者,在对应岗位上能把事情做精做细,更加智能简单,最好每一次的功能迭代都是一次性的、稳定的、高效的、靠谱的,没有反反复复的 BUG 修改。
因为这样无形中可以节省很多成本(修复BUG成本、沟通成本、人力成本、时间成本等等),简单来讲,企业希望大家用最少的时间,干最多的活,而且一出手就是王炸级别的高可用、高可扩展、高性能,稳定靠谱地在产线运行。
现在,你还会不会觉得大厂在面试环节故意问各种底层原理来刁难你呢?其实面试官也犯不着为难你,只要你能力出众,对于老江湖的伯乐面试官而言是可遇不可求的。但也不乏有点小心思的面试官,担心强者会逐渐取代自己,不过,如果你有技术、有思想、有能力,即便这一家没面上,换一家就是了,天下之大,总有你的一席之地。
如果大厂在面试中问到Dubbo,一般会问框架的整体架构、常用技术点背后的底层逻辑、生僻的底层技术点,或者让你谈谈对一些问题的看法,总之,希望能从中看到你对 Dubbo 框架的掌握程度,以此来评判你是否具有驾驭 Dubbo 框架的深厚功底。
如果遇到对 Dubbo 特别精通的面试者,大概率会作为重要候选人,入司的话会考虑把一些核心的系统或功能,或偏底层的通用功能开发交付,给这样的人选来处理。
我也整理了常见的14个Dubbo大厂面试问题,你可以先尝试自己回答一下。
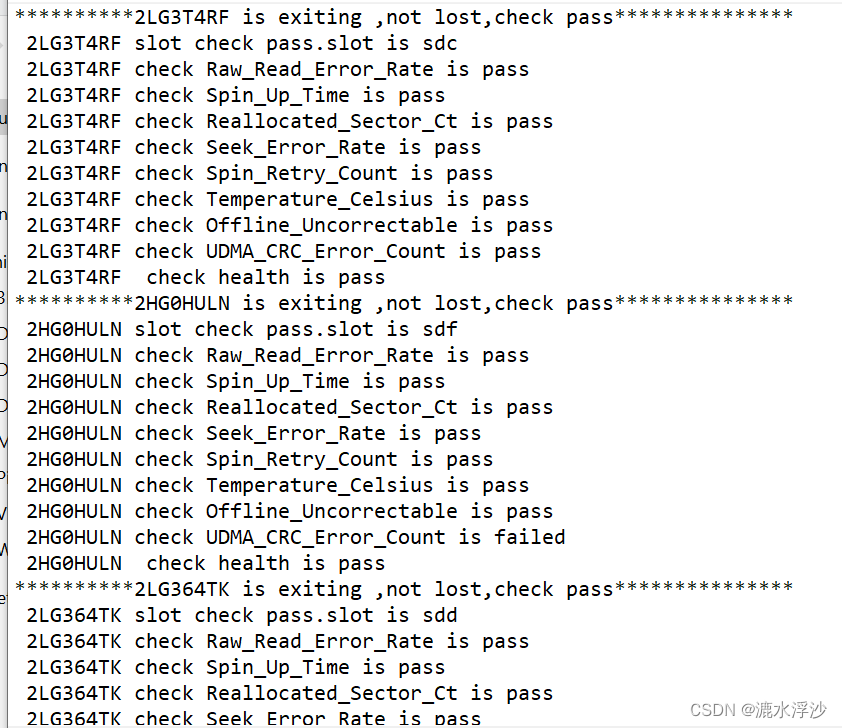
1.Dubbo 源码分层模块是怎样的? 2.Dubbo 是如何扫描含有 @DubboService 这种注解的类的? 3.Dubbo SPI 解决了 JDK SPI 的什么问题? 4.简要描述下 Dubbo SPI 与 Spring SPI 的加载原理? 5.LinkedHashMap 可以设计成 LRU 么? 6.利用 Dubbo 框架怎么做分布式限流呢? 7.Wrapper 是怎么降低调用开销的? 8.使用 Javassist 编译的有哪些关键要素环节? 9.使用 ASM 编译有哪些基本步骤? 10.Dubbo 是怎么完成实例注入与切面拦截的? 11.服务发布的流程是怎样的? 12.服务订阅的流程是怎样的? 13.消费方调用流程是怎样的? 14.你有研究过 Dubbo 的协议帧格式么?
这些问题,都是我们课程中讲过的知识点,所以你也可以考核一下自己的学习情况。我们来看看每个知识点你掌握得如何。
问题一
- Dubbo 源码分层模块是怎样的?
这个问题是想对 Dubbo 整体代码分层结构的熟悉程度,判断你有没有深入研究过 Dubbo 框架体系,一般答到有 Config、Proxy、Cluster 层就差不多及格了,如果能至上而下纵向详细说出 Dubbo 的十个层次模块,就更好了,会让面试官刮目相看。
我们在“源码框架”中就通过一个简单的消费方调用逐步分析过 Dubbo 的十层模块,如果不太记得,你可以复习巩固一下。
主要分为三大块,第一大块是和business紧密相关的 Service 层,第二大块是和RPC紧密相关的Config、Proxy、Registry、Cluster、Monitor和Protocol,剩下的第三大块是和Remoting 紧密相关的Exchange、Transport、Serialize。

- Service,与业务逻辑关联紧密的一层称为服务层。
- Config,专门存储与读取配置打交道的层次称为配置层。
- Proxy,代理接口发起远程调用,或代理接收请求进行实例分发处理的层次,称为服务代理层。
- Registry,与注册中心打交道的层次,称为注册中心层。
- Cluster,封装多个提供者并承担路由过滤和负载均衡的层次,称为路由层。
- Monitor,同步调用结果的层次称为监控层。
- Protocol,封装调用过程的层次称为远程调用层。
- Exchange,封装请求并根据同步异步模式获取响应结果的层次,称为信息交换层。
- Transport,将数据通过网络发送至对端服务的层次称为网络传输层。
- Serialize,把对象与二进制进行相互转换的正反序列化的层次称为数据序列化层。
问题二
- Dubbo 如何扫描含有 @DubboService 这种注解的类?
这个问题是想看你对 Dubbo 扫描自定义注解的掌握程度,一般说到“生成了代理”就基本沾边及格了,如果能详细说出扫描器的源头是利用了Spring扫描特性,就更好,因为懂了这些原理,之后公司有需求,要你根据业务功能抽象插件,或者在系统中通过无侵入性进行技术改造,对你来说就是小菜一碟。
我们在“集成框架”中仿照 Spring 类扫描机制对 integration 层代码进行改造时,提到过这些。
Dubbo 利用了一个 DubboClassPathBeanDefinitionScanner 类继承了 ClassPathBeanDefinitionScanner,充分利用 Spring 自身已有的扩展特性来扫描自己需要关注的三个注解类,org.apache.dubbo.config.annotation.DubboService、org.apache.dubbo.config.annotation.Service、com.alibaba.dubbo.config.annotation.Service,然后完成 BeanDefinition 对象的创建。
在 BeanDefinition 对象的实例化完成后,在容器触发刷新的事件过程中,通过回调了 ServiceConfig 的 export 方法完成了服务导出,即完成 Proxy 代理对象的创建,最后在运行时就可以直接被拿来使用了。
问题三
- Dubbo SPI 解决了 JDK SPI 的什么问题?
这个问题是想看你对 Dubbo SPI 在算法性能层面的掌握,一般说出“利用了缓存功能”就及格了,如果能说出 JDK SPI 的不足,以及 Dubbo SPI 怎么解决不足,怎样通过算法改善的,就更好了。能这么详细地描述前后对比情况,说明平常你在编写代码时,会主动思考功能的性能优化,这是一种难能可贵的自我思考意识,比较受面试官的喜爱。
我们在“SPI 机制”中通过运行 JDK SPI 的程序,分析过 JDK SPI 的不足问题,也分析如何改善。
JDK SPI 使用一次,就会一次性实例化所有实现类。为了弥补我们分析的 JDK SPI 的不足,Dubbo 也定义出了自己的一套 SPI 机制逻辑,既要通过 O(1) 的时间复杂度来获取指定的实例对象,还要控制缓存创建出来的对象,做到按需加载获取指定实现类。
Dubbo SPI 在实现的过程中,采用了两种方式来优化。
- 方式一,增加缓存,来降低磁盘IO访问以及减少对象的生成。
- 方式二,使用Map的hash查找,来提升检索指定实现类的性能。
通过两种方式的优化后,在面对大量高频调用时,JDK SPI 可能会出现磁盘 IO 吞吐下降、大量对象产生和查询指定实现类的 O(n) 复杂度等问题,而 Dubbo SPI 采用缓存+Map的组合方式更加友好地避免了这些情况,即使大量调用,也问题不大。
问题四
- 简要描述下 Dubbo SPI 与 Spring SPI 的加载原理?
在问题三的基础上,这是想继续看你对 Dubbo SPI 加载实现的底层原理的掌握程度,一般说出“通过加载资源文件目录的文件”就及格了,如果能详细说出有哪些资源目录,然后根据自己的理解,说明这些目录一般存放什么类型的 SPI 接口,就更好。
能充分说明你不但知晓 Dubbo SPI 的优势点,还能知道 Dubbo SPI 为了提供这样的优势,是如何完成底层实现的,并且还能横向掌握 Spring SPI 的加载原理。足以说明你不但对 Dubbo SPI 有过研究,Spring SPI 这种高级特性的底层原理,也有过深入研究,那么针对工作中一些技术类改造的需求,你应该比较擅长灵活扩展。
我们在“SPI 机制”的思考题答案中有讲过,如果不太记得,可以复习巩固一下。
Dubbo SPI 的核心加载原理,就是加载了以下三个资源路径下的文件内容,资源分别为。
- META-INF/dubbo/internal/
- META-INF/dubbo/
- META-INF/services/
我们自己设计的 SPI 接口,放到这 3 个资源路径下都可以,不过从路径的名称上可以看出,META-INF/dubbo/internal/ 存放的是 Dubbo 内置的一些扩展点,META-INF/services/ 存放的是 Dubbo 自身的一些业务逻辑所需要的一些扩展点,而 META-INF/dubbo/ 存放的是上层业务系统自身的一些定制 Dubbo 的相关扩展点。
而相比于 JDK 原生的SPI,Spring 中的 SPI 功能也很强大,主是通过 org.springframework.core.io.support.SpringFactoriesLoader#loadFactories 方法读取所有 jar 包的“META-INF/spring.factories”资源文件,并从文件中读取一堆的类似 EnableAutoConfiguration 标识的类路径,把这些类创建对应的 Spring Bean 对象注入到容器中,就完成了 SpringBoot 的自动装配。
问题五
- LinkedHashMap 可以设计成 LRU 么?
这个问题是想看你对 Map 工具类的掌握程度,说出通过自定义工具类并内部组合使用 Map,在 put 操作时进行 LRU 功能设计,在设计层面一般及格了。
如果能充分挖掘 Map 的底层特性,通过继承 Map 并重写 removeEldestEntry 方法来灵活扩展为 LRU,并且还能说出 Dubbo 框架在什么功能也对比进行扩展过,就更好了,能充分说明你对 Map 工具类的掌握非常深,对 Map 的底层原理了解非常透彻,还能知道该特性在 Dubbo 框架中的应用,难能可贵。
LinkedHashMap 可以设计成 LRU,在“缓存操作”那讲中,我们跟踪了一个所谓的 LRU2Cache 缓存类,它的底层实现原理就是继承了 LinkedHashMap 的类,然后重写了父类 LinkedHashMap 中的 removeEldestEntry 方法,当 LRU2Cache 存储的数据个数大于设置的容量后,会删除最先存储的数据,让最新的数据能够保存进来。
细节处的源码跟踪,我也展示在这里。
// LRU2Cache 的带参构造方法,在 LruCache 构造方法中,默认传入的大小是 1000
org.apache.dubbo.common.utils.LRU2Cache#LRU2Cache(int)
public LRU2Cache(int maxCapacity) {
super(16, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
this.preCache = new PreCache<>(maxCapacity);
}
// 若继续放数据时,若发现现有数据个数大于 maxCapacity 最大容量的话
// 则会考虑抛弃掉最古老的一个,也就是会抛弃最早进入缓存的那个对象
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
↓
// JDK 中的 LinkedHashMap 源码在发生节点插入后
// 给了子类一个扩展删除最旧数据的机制
java.util.LinkedHashMap#afterNodeInsertion
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}问题六
- 利用 Dubbo 框架怎么来做分布式限流呢?
这个问题是想看你利用 Dubbo 过滤器的特性来处理分布式功能的掌握程度,一般答到 Filter、Redis 等关键词就算是及格了,如果能总结出使用过滤器进行限流改造的方法流程,就更好了,至少可以说明你不但对过滤器十分了解,平时还注重方法流程的总结,这些总结出来的方法流程,你应该可以很好地平移到其他框架的学习上,快速上手新项目。
关键一点是需要利用 Dubbo 框架的过滤器特性,结合方法层面的参数设置,就可以很好的做到分布式限流的控制。具体可以参考“流量控制”的分布式限流方案改造。
这里也提炼下控制流量的三个关键环节。
- 第一,寻找请求流经的必经之路,并在必经之路上找到可扩展的接口。
- 第二,找到该接口的众多实现类,研究在触发调用的入口可以拿到哪些数据,再研究关于方法的入参数据、方法本身信息以及方法归属类的信息可以通过哪些 API 拿到。
- 第三,根据限流的核心计算模块,逐渐横向扩展,从单个方法到多个方法,从单个服务到多个服务,从单个节点到集群节点,尽可能周全地考虑通用处理方式,同时站在使用者的角度,做到简单易用的效果。
问题七
- Wrapper 是怎么降低调用开销的?
这个问题是想看你对 Dubbo 底层处理调用时的性能开销掌握程度,一般能答到生成代理类就沾边了,如果能一针见血说出 Wrapper 代理类,并且描述代理类的执行逻辑,那就更完美了。
能描述出代理类的执行逻辑,基本上都对 Wrapper 机制有过深入研究,因为 Wrapper 代理类是运行时的对象,如果不刻意去断点调试生成文件查看,是很难挖掘出 Wrapper 的核心内幕的,所以,能把调用开销讲明白的人,能迅速研究透各种底层框架的核心调用流程。
我们在“Wrapper 机制”中详细讲过。
首先得搞清楚,Wrapper 用在哪里了。看一段代码,提供方是这么使用 Wrapper 来生成代理类的。
// org.apache.dubbo.rpc.proxy.javassist.JavassistProxyFactory#getInvoker
// 创建一个 Invoker 的包装类
@Override
public <T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) {
// 这里就是生成 Wrapper 代理对象的核心一行代码
final Wrapper wrapper = Wrapper.getWrapper(proxy.getClass().getName().indexOf('$') < 0 ? proxy.getClass() : type);
// 包装一个 Invoker 对象
return new AbstractProxyInvoker<T>(proxy, type, url) {
@Override
protected Object doInvoke(T proxy, String methodName,
Class<?>[] parameterTypes,
Object[] arguments) throws Throwable {
// 使用 wrapper 代理对象调用自己的 invokeMethod 方法
// 以此来避免反射调用引起的性能开销
// 通过强转来实现统一方法调用
return wrapper.invokeMethod(proxy, methodName, parameterTypes, arguments);
}
};
}Wrapper 最终调用了 getWrapper 方法来生成一个代理类。
- 以源对象的类属性为维度,与生成的代理类建立缓存映射关系,避免频繁创建代理类影响性能。
- 生成了一个继承 Wrapper 的动态类,并且暴露了一个公有 invokeMethod 方法来调用源对象的方法。
- 在invokeMethod 方法中,通过生成的 if...else 逻辑代码来识别调用源对象的不同方法。
这里也总结一下原理细节的代码流程。
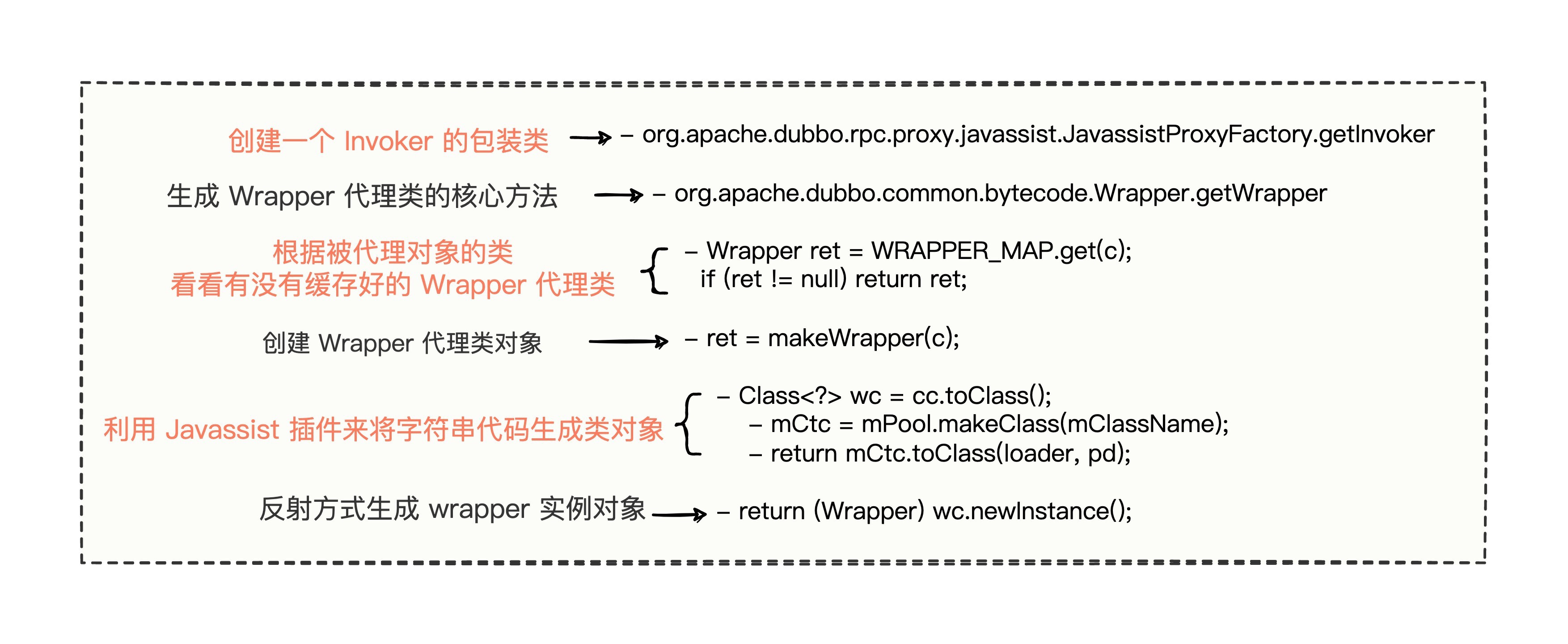
总之,Wrapper 降低开销的主要有 2 个关键要素的原因。
- 原因一,生成了代理类缓存起来,避免频繁创建对象。
- 原因二,代理类中的逻辑,是通过 if...else 的普通代码进行了强转操作,转为原始对象后继续调用方法,而不是采用反射方式来调用方法的。
问题八
- 使用 Javassist 编译的有哪些关键要素环节?
这个问题是想看你两方面的知识,一有没有了解过 Javassist,二有没有研究过如何使用 Javassist 生成过代理对象,一般答出可以用 Javassist 生成代理对象就算是及格了,如果能详细说出使用 Javassist 来生成代理类的流程步骤,说明你确实有底层框架的开发经验,具备比较深厚的抽象能力,是开发底层功能的好苗子。
在“Compile 编译”中,我们利用 Javassist 编写了实战案例,也总结了方法流程。
- 首先,设计一个代码模板。
- 然后,使用 Javassist 的相关 API,通过 ClassPool.makeClass 得到一个操控类的 CtClass 对象,然后针对 CtClass 进行 addField 添加字段、addMethod 添加方法、addConstructor 添加构造方法等等。
- 最后,调用 CtClass.toClass 方法并编译得到一个类信息,有了类信息,就可以实例化对象处理业务逻辑了。
问题九
- 使用 ASM 编译有哪些基本步骤?
在问题八的基础上,问这个问题是想再看看,你能否用更为底层的 ASM 进行开发,大多数情况下,项目组很少有人会去深入研究这块,一般能说出可以利用非常底层的 ASM 进行字节码操作就算是不错的了,如果能详细讲出如何利用 ASM 来生成代理类,那非常厉害了。
我们在“Compile 编译”中也花了大量篇幅学习 ASM 的开发步骤流程,如果不太记得,可以复习巩固一下。
使用 ASM 编译,流程操作和 Javassist 有点类似。
- 首先,还是设计一个代码模板。
- 其次,通过 IDEA 的协助得到代码模板的字节码指令内容。
- 然后,使用 Asm 的相关 API 依次将字节码指令翻译为 Asm 对应的语法,比如创建 ClassWriter 相当于创建了一个类,继续调用 ClassWriter.visitMethod 方法相当于创建了一个方法等等,对于生僻的字节码指令实在找不到对应的官方文档的话,可以通过“MethodVisitor + 字节码指令”来快速查找对应的 Asm API。
- 最后,调用 ClassWriter.toByteArray 得到字节码的字节数组,传递到 ClassLoader.defineClass 交给 JVM 虚拟机得出一个 Class 类信息。
问题十
- Dubbo 是怎么完成实例注入与切面拦截的?
这个问题考察 Dubbo 框架中,实例对象创建过程中的扩展机制。一般答到具有 setter 注入的特性原理就算是及格了,如果能更为详细地描述前置、后置等扩展机制,以及如何进行构造方法注入变为包装对象等底层原理,就非常漂亮了。
如果你能把这种对象创建过程的原理弄得非常透彻,其他框架的对象创建过程都是类似的,研究起来就会轻而易举。我们在“实例注入”中详细跟踪了源码。
Dubbo 完成实例注入,主要是当 ExtensionLoader 的 getExtension 方法被调用时,才会酌情考虑是取缓存对象,还是直接创建对象并进行实例注入。
直接创建对象的过程,主要是通过反射创建出来一个婴儿对象,然后经历前置初始化前置处理(postProcessBeforeInitialization)、注入扩展点(injectExtension)、初始化后置处理(postProcessAfterInitialization)三个阶段,经过三段处理的对象,我们暂且称为“原始对象”。
然后,这个原始对象,会根据 getExtension 传入的 wrap 变量,决定是否需要将原始对象再次进行包裹处理,若需要包裹,会将该 SPI 接口的所有包装类排序好,以套娃的形式,将原始对象层层包裹。而包装类上可以设置 @Wrapper 注解,结合注解,有 3 种情况决定是否需要包装。
- 无 @Wrapper 注解,则需要包装。
- 有 @Wrapper 注解,但是注解中的 matches 字段值为空,则需要包装。
- 有 @Wrapper 注解,但是注解中的 matches 字段值包含入参的扩展点名称,并且 mismatches 字段值不包含入参的扩展点名称,则需要包装。
不过重点要关注 injectExtension 方法,该方法中会从根据对象的 setter 方法获取扩展点名称,然后直接从容器中找到对应的实例,完成实例注入。
总而言之,创建扩展点对象的时候,不但会通过 setter 方法进行实例注入,而且还会通过包装类层层包裹,就像这样:

问题十一
- 服务发布的流程是怎样的?
这个问题考察你平常编写提供方服务时,对提供服务能力流程的掌握,一般能提到服务导出开启了Netty服务就算是及格了,如果能从所使用的注解开始,划分流程步骤分别讲解,那样就更好,因为你能把服务发布流程研究得非常透彻,说明你对 Dubbo 怎么提供服务能力的体系流程比较关注,想必在日常开发编码时,对整个需求实现的流程体系把控也不会差。
在“发布流程”中,我们针对提供方的架构示意图,展开了详细的源码分析。
服务发布的流程,主要可以从配置、导出、注册三方面描述。
- 配置流程,通过扫描指定包路径下含有 @DubboService 注解的 Bean 定义,把扫描出来的 Bean 定义属性,全部转移至新创建的 ServiceBean 类型的 Bean 定义中,为后续导出做准备。
- 导出流程,主要有两块,一块是 injvm 协议的本地导出,一块是暴露协议的远程导出,远程导出与本地导出有着实质性的区别,远程导出会使用协议端口,通过 Netty 绑定来提供端口服务。
- 注册流程,其实是远程导出的一个分支流程,会将提供方的服务接口信息,通过 Curator 客户端,写到 Zookeeper 注册中心服务端去。

问题十二
- 服务订阅的流程是怎样的?
在上一个问题“提供方服务发布流程”的基础上,再看看你对消费方服务订阅流程的掌握程度,一般能提到从注册中心获取提供方信息就算及格了,如果能详细说出具体的流程,并与服务发布建立流程对比,就更好了,起码能说明你是非常细心的,在提供方和消费方之间发现了可对比的流程环节,在对比中,发现问题,研究问题,这种学习方式是值得称赞的。
我们在“订阅流程”中通过与服务发布建立对比关系,边猜测边验证,进行了详细的流程分析。
相比于服务的发布流程,服务订阅流程大体类似,概括起来有 4 个步骤。
- 首先,在程序上,往往会通过 @DubboReference 注解来标识需要订阅哪些接口的服务,并使用这些服务进行调用。在源码跟踪上,可以通过该注解一路探索出背后的核心类 ReferenceConfig。
- 紧接着,在ReferenceConfig 的 get 方法会先后进行本地引用与远程引用的两大主干流程。
- 然后,在本地引用环节中使用的 invoker 对象是从 InjvmProtocol 中 exporterMap 获取到的。而在远程引用环节中,创建 invoker 的核心逻辑是在 RegistryProtocol 的 doCreateInvoker 方法中完成的。
- 最后,在这段 doCreateInvoker 逻辑中,还进行了消费者注册和接口订阅逻辑,订阅逻辑的本质就是启动环节从注册中心拉取一遍接口的所有提供方信息,然后为这些接口添加监听操作,以便在后续的环节中,提供方有任何变化,消费方这边也能通过监听策略,及时感知到提供方节点的变化。
消费方订阅的整体流程,也给你总结了图片。

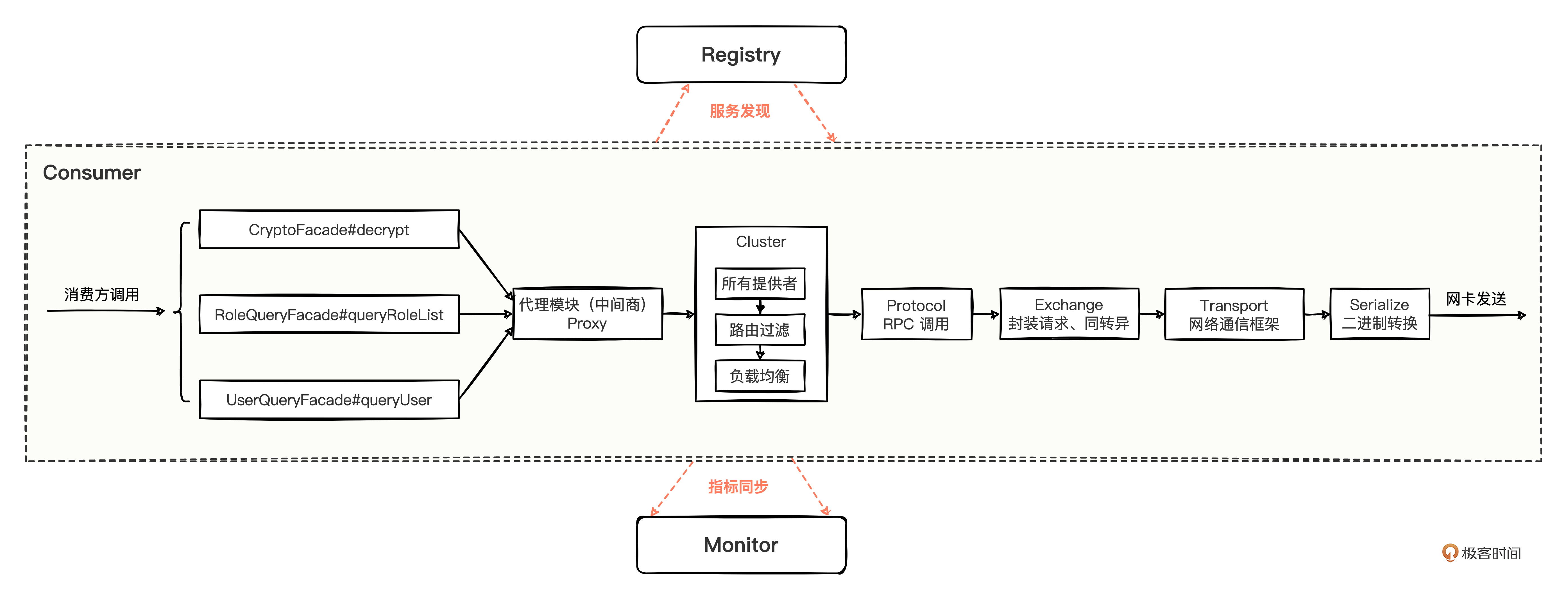
问题十三
- 消费方调用流程是怎样的?
在掌握服务发布、服务订阅的基础上,考核你对消费方调用流程的掌握程度。
通过生成的 Proxy 代理,在 Cluster 集群扩展器中,负载均衡通过 Transport 层的 Netty 通信框架发送数据,说到这里就基本及格了,如果能像讲述十层模块一样,自上而下说出调用环节设计的层次模块和关键核心方法或类,就更好了,可以说明你平时非常注重底层原理流程的研究,是个不可多得的人才。
我们在“调用流程”中,从消费方的简单调用代码开始,详细分析了,如果不太记得,可以复习巩固一下。
这里我就用一张图总结。消费方的调用流程,比较简单,只要顺着消费方代码调用的地方,顺着一路往下追踪,就能抓出整个调用流程。

问题十四
- 你有研究过 Dubbo 的协议帧格式么?
这个问题是想看你对数据收发底层协议格式的掌握程度,一般能提到“定长+变长的协议格式”就及格了,如果能详细说出 Dubbo 协议帧格式的细节字段,那就更好,说明你在数据收发粘包、半包这块了解深入,操控底层 Socket 进行数据收发基本上没什么问题。
我们在“协议编解码”中通过在 NettyCodecAdapter 中进行了断点,详细研究了编解码代码,如果不太记得,可以复习巩固一下。
Dubbo 的协议帧本质就是“定长 + 变长”的整个报文格式。
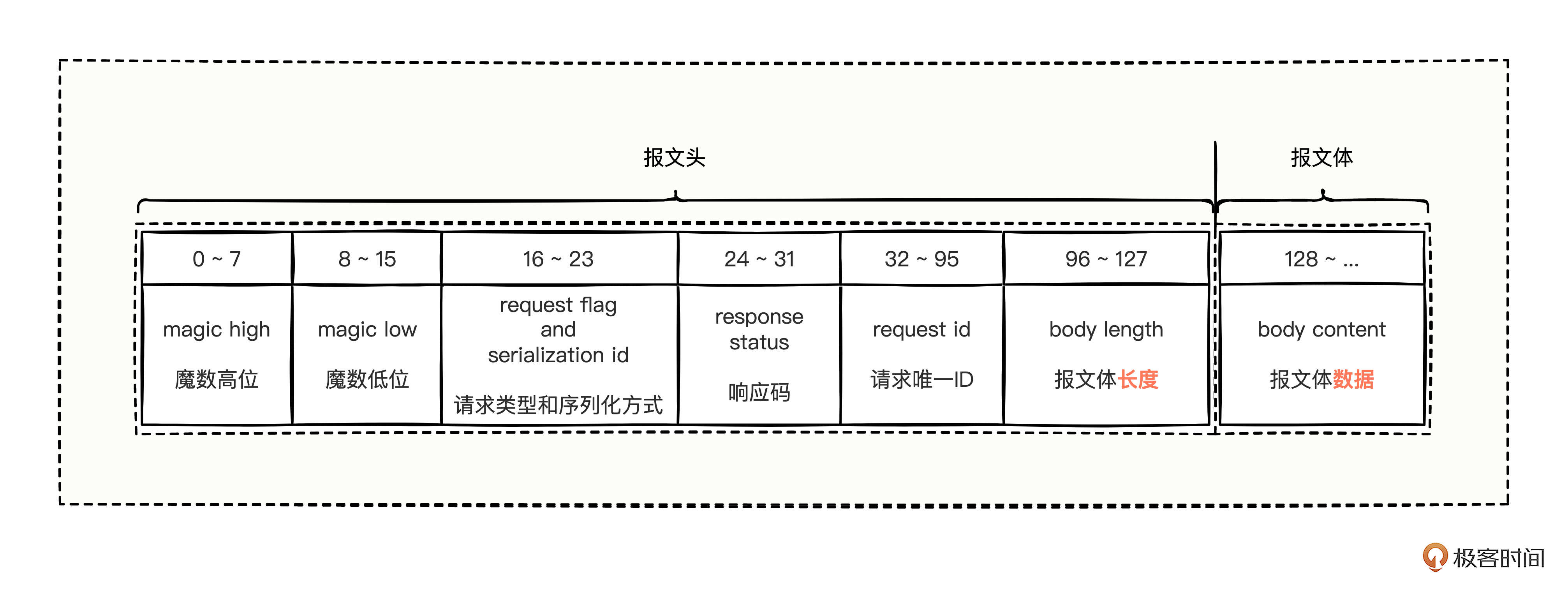
- magic high:魔术高位,占用 8 bit,也就是 1 byte。该值固定为 0xda,是一种标识符。
- magic low:魔术低位,占用 8 bit,也就是 1 byte。该值固定为 0xbb,也是一种标识符。
魔术低位和魔术高位合并起来就是 0xdabb,代表着 dubbo 数据协议报文的开始。如果从通信 socket 收到的报文不是以 0xdabb 开始的,可以认为是非法报文。
request flag and serialization id:请求类型和序列化方式,占用 8 bit,也就是 1 byte。前面 4 bit 是请求类型,后面 4 bit 是序列化方式,合起来用 1 个 byte 来表示。
response status:响应码,占用 8 bit,也是 1 byte。因为已经明确是响应码了,所以一个请求发送出去的时候,不用填充这个值,响应回来的时候,这里就有值了。
但是这个响应码,并不是那些真实业务数据功能的响应码,而是 Dubbo 通信层面的错误码*,比如通信响应成功码、消费方超时码、服务方超时码、请求格式错误码等等,都是一些 Dubbo 框架自己易于通信识别错误的码,并非那些真正上层业务功能的错误码。
request id:请求唯一ID,占用 64 bit,也就是 8 byte。标识请求的唯一性,用来证明你收到的响应,就是你曾经发出去的请求返回来的数据。
body length:报文体长度,占用 32 bit,也就是 4 byte。体现真正的业务报文数据到底有多长。
因为真实的业务数据有大有小,如果报文里不告知业务数据的长度,服务方就不知道要读取多长的字节,所以,就需要知道业务报文数据到底有多长。当客户端发送数据时,把要发送的业务数据报文计算一下长度后,放到这个位置,服务方看到该长度后,就会读取指定长度的字节,读完就结束,也就收到了一个完整的报文数据。
- body content:报文体数据,占用的 bit 未知,占用的 byte 字节个数也未知。这里是我们真正业务数据的内容,至于真正的业务数据的长度有多长,完全由报文体长度决定。
Dubbo 的协议帧格式,整体不难,我们只需要按照上面的帧格式一步步构建出这样的字节数组出来,然后利用 socket,write 出去就可以了。服务方在接收数据的时候,也是一样,严格按照报文格式进行解析,不是 oxdabb 开头的就直接丢弃,是的话就继续往后读取,按照数据帧格式,直到读完整个报文为止。
面试小技巧
这 14 个大厂常见的面试题,总的来说,都是比较偏底层的知识点,你在完成日常需求开发后,如果能再研究一下框架,提升自己驾驭框架的能力,回答这些问题应该比较轻松。
像这种偏底层面试问题,切记,捡重要环节分步骤回答,千万不要想自己平常是怎么看源码的,就凭记忆从上到下,一把梭哈讲,这样会让面试官觉得你毫无主次,没有逻辑概念。
针对这种底层原理分析类的问题,我给你个小建议:
- 拿到问题,先沉思几秒,快速在脑海中回忆自己曾经研究的整个过程。
- 回答时,把刚刚回忆的流程分为几个步骤,一般不超过4步,太多反而会显得啰嗦。
- 针对每个步骤,捡关键的讲,能体现源码的关键类也最好说出来,显得你不但有过深入研究,还非常专业细致。
- 回答后,记得谈一下自己对这个问题的看法,实在没有啥看法不说也行。 好,中小厂和大厂的高频面试题和面试技巧,我们就都讲完了。
期待你在技术这条道路上精益求精,既要精通技术实战,也要深懂底层原理,更要做思考的引领者,让自己在技术路上越走越远,越走越香。
文章来源:极客时间《Dubbo 源码剖析与实战》