1.分区规则

ps."&"指的是按位与运算,可以强制转换为正数
ps."%",假设reduceTask的个数为3,则余数为0,1,2正好指代了三个分区
以上代码的含义就是对key的hash值强制取正之后,对reduce的个数取余,这样的话,如果key相同,则hash值相同,则余数相同,则会放到同一分区。
但是如果某一种key过多,则会导致分区不均匀,此问题称为数据倾斜
2.自定义分区
自定义分区用于解决数据倾斜问题
案例:
数据:一堆手机号
需求:手机号136、137、138、139开头都分别放到一个独立的4个分区中,其他开头的放到一个分区中,然后对总流量进行倒序排序
重点:(1)全局排序是不能分区的(2)把流量当作key来排序
3.1 bean阶段(自定义排序规则:继承WritableComparable接口)
public class FlowBean implements WritableComparable<FlowBean>{
private Integer upFlow;
private Integer downFlow;
private Integer sumFlow;
}生成set/get阶段:
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getSumFlow() {
return sumFlow;
}
public void setSumFlow(Integer sumFlow) {
this.sumFlow = sumFlow;
}重写toString方法:
public String toString() {
return upFlow + "\t" + downFlow + "\t" +sumFlow;
}序列化方法与反序列化方法:
// 序列化
public void write(DataOutput out) throws IOException {
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(sumFlow);
}
// 反序列化
public void readFields(DataInput in) throws IOException {
upFlow = in.readInt();
downFlow = in.readInt();
sumFlow = in.readInt();
} 计算总流量
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}自定义排序规则:倒叙输出:当this.getSumFlow()大于o.getSumFlow()时候,返回负数
public int compareTo(FlowBean o) {
return -this.getSumFlow().compareTo(o.getSumFlow());
}3.2 自定义分区规则:需要继承Hadoop的提供的Partitioner对象
public class PhonePartitioner extends Partitioner<FlowBean,Text> {
public int getPartition(FlowBean flowBean,Text text,int numPartitions) {
int phonePartitions;
// 获取手机号
String phoneNum = text.toString();
if(phoneNum.startsWith("136")){
phonePartitions = 0;
}else if(phoneNum.startsWith("137")){
phonePartitions = 1;
}else if(phoneNum.startsWith("138")){
phonePartitions = 2;
}else if(phoneNum.startsWith("139")){
phonePartitions = 3;
}else {
phonePartitions =4;
}
return phonePartitions;
}
}3.3 map阶段:要求输出时以流量做为k,以手机号为v
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private Text outv = new Text();
private FlowBean outk = new FlowBean();
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取当前行数据
String line = value.toString();
// 切割数据
String[] phoneDatas = line.split("\t");
// 获取输出数据的key(手机号)
outv.set(phoneDatas[1]);
// 获取输出数据的value
outk.setUpFlow(Integer.parseInt(phoneDatas[phoneDatas.length-3]));
outk.setDownFlow(Integer.parseInt(phoneDatas[phoneDatas.length-2]));
outk.setSumFlow();
// 将数据输出
context.write(outk, outv);
}
}3.4 recue阶段:reduce做的事情就是把数据翻转着写出去
public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
private FlowBean outv = new FlowBean();
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 遍历输出
for (Text value : values) {
context.write(value,key);
}
}
}3.5 driver阶段:将以上代码整合起来

3.Combiner
定义:就是数据合并,将map的输出结果预聚合,减小网络传输量,比如:
(map,1)(map,1) (map,1) => (map,3)
Combiner和reducer的差别:
Combiner是对每一个mapper进行汇总,reducer是对所有的mapper进行汇总
使用前提:不能影响最终的业务逻辑,combiner输出的kv应该和reducer输出的kv对应
假如有3,5,7,2,6求平均值,使用combiner做局部合并和使用reducer做全局合并:

位置:mapper中,处于分区快排之后,溢写之前
使用案例:对wordCount使用Combiner
1.自定义Combiner类:重写reducer方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 汇总操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 写出
context.write(key, new IntWritable(count));
}
}
2.在driver中添加Combiner类:
job.setCombinerClass(WordcountCombiner.class);4.shuffle流程总结
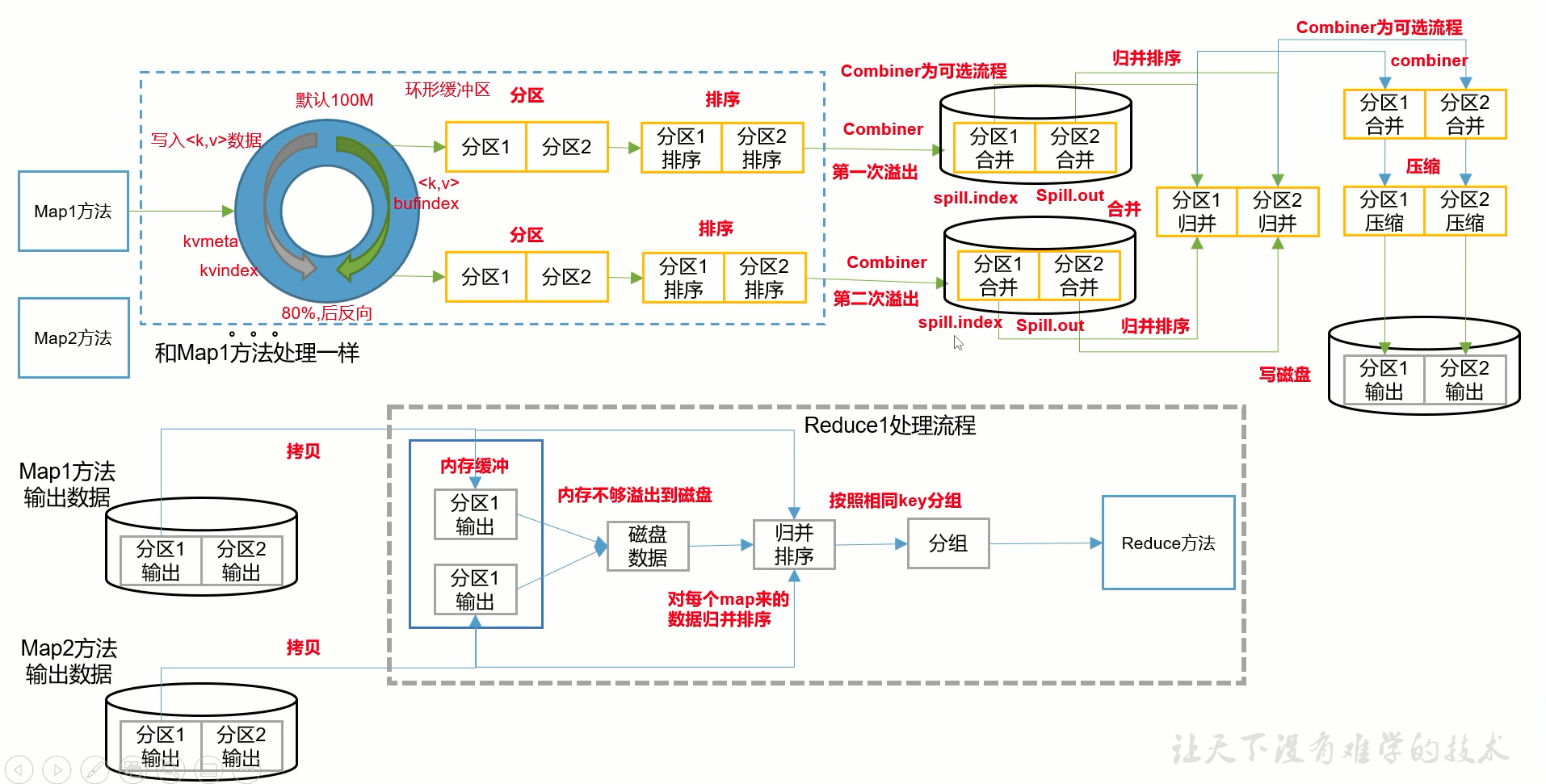
ps1.map缓冲区:
环形缓冲区,右边写数据,左边写元数据。但是环形缓冲区是不能碰头的,否则一端的数据会覆盖另一端的数据,所以达到80%就开始溢写
ps2.reduce缓冲区:
如果缓冲区足够大,整个归排就直接在内存中执行,否则就溢写到磁盘进行,最后在发给reduc