-
#pragma comment。将一个注释记录放置到对象文件或可执行文件中。
#pragma pack。用来改变编译器的字节对齐方式。
#pragma code_seg。它能够设置程序中的函数在obj文件中所在的代码段。如果未指定参数,函数将放置在默认代码段.text中
#pragma once。保证所在文件只会被包含一次,它是基于磁盘文件的,而#ifndef则是基于宏的。 -
当类不包含任何成员的时候,大小本该是0,但是为了便于区分,大小是1
-
.c是标准C程序文件名的后缀;.cpp则是C++程序文件名的后缀;.obj是源程序经编译后所生成的目标文件的扩展名;.exe则是源程序经编译、链接后所生成的执行文件的扩展名。
-
结构体变量不管其包含有多少个成员,都应当看成是一个整体。在程序运行期间,只要在变量的生存期内,所有成员一直驻留在内存中
-
C提供的三种预处理功能:宏定义 文件包含 条件编译
-
在C语言程序中,若对函数类型未加显式说明,则函数的隐含类型为int,C++中为void
-
const 限定一个数据为只读属性。
(1)const char p; 限定变量 p 为只读。
(2)const char p; p 为一个指向 char 类型的指针,const 限定 p 指向的数据为只读。所以 *p 的值不能被修改,而指针变量 p 本身的值可以被修改。
(3)char * const p; 限定此指针变量为只读,所以p的值不能被修改,而 *p 的值可以被修改。
(4)const char const p; 两者皆限定为只读,不能修改。 -
一个指向指针的指针,它指向的指针是指向一个整型数 int a;
一个有10个指针的数组,该指针是指向一个整型数的 int a[10];
一个指向有10个整型数数组的指针 int (a)[10]; -
gcc和g++的主要区别
(1)对于 .c和.cpp文件,gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的)
(2)对于 .c和.cpp文件,g++则统一当做cpp文件编译
(3)使用g++编译文件时,g++会自动链接标准库STL,而gcc不会自动链接STL
(4) gcc在编译C文件时,可使用的预定义宏是比较少的
(5)gcc在编译cpp文件时/g++在编译c文件和cpp文件时(这时候gcc和g++调用的都是cpp文件的编译器),会加入一些额外的宏 -
ftell() 函数用于得到文件位置指针当前位置相对于文件首的偏移字节数;
fseek() 函数用于设置文件指针的位置;
rewind() 函数用于将文件内部的位置指针重新指向一个流(数据流/文件)的开头;
ferror() 函数可以用于检查调用输入输出函数时出现的错误。 -
结构体的内存分配
结构体在内存中分配一块连续的内存,但结构体内的变量并不一定是连续存放的,这涉及到内存对齐。
原则1 数据成员对齐规则: 结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)。
原则2 结构体作为成员: 如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。)
原则3 收尾工作: 结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。 -
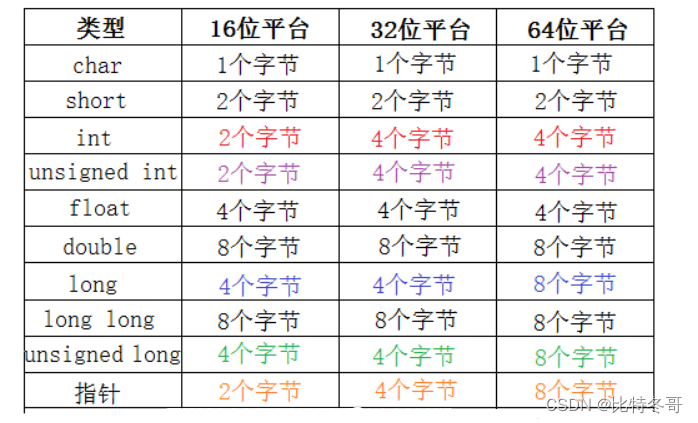
不同系统下数据类型的字节大小
-
int (*(*p)[10])(int *)
先看未定义标识符p,p的左边是*,*p表示一个指针,跳出括号,由于[ ]的结合性大于*,所以*p指向一个大小为10的数组,即(*p)[10]。左边又有一个*号,修释数组的元素,*(*p)[10]表示*p指向一个大小为10的数组,且每个数组的元素为一个指针。跳出括号,根据右边(int *)可以判断(*(*p)[10])是一个函数指针,该函数的参数是int*,返回值是int。 -
结构体和联合的区别
(1) 联合和结构体都是由多个不同的数据类型成员组成,但在任何同一时刻,联合只存放了一个被选中的成员,而结构体的所有成员都存在。
(2) 对于联合的不同成员赋值,将会对其它成员重写,原来成员的值就不存在了,而对于结构体的不同成员赋值是互不影响的。
结构体中各成员都有自己的内存空间,是同时共存的,长度是所有成员的和。考虑内存对齐。
联合体中所有的成员只有一个内存空间,不同时刻储存不同类型的值,长度是它最长成员的长度。 -
fopen(fname,"w") 函数的打开方式
"r"以“只读”方式打开文件。只允许读取,不允许写入。文件必须存在,否则打开失败。
"w"以“写入”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。
"a"以“追加”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。
"r+"以“读写”方式打开文件。既可以读取也可以写入,也就是随意更新文件。文件必须存在,否则打开失败。
"w+"以“写入/更新”方式打开文件,相当于w和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。
"a+"以“追加/更新”方式打开文件,相当于a和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 -
#include <filename.h> 用来包含开发环境提供的库头文件,
#include"filename.h" 用来包含自己编写的头文件 -
关键字 inline 只是一种编译器建议,inline编译阶段嵌入,运行时不算调用,因此不需要栈
-
BSS段:存放程序中未初始化的全局变量的一块内存区域,BSS段属于静态内存分配。
数据段:存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:存放程序执行代码的一块内存区域。
堆(heap):存放进程运行中被动态分配的内存段,内存手动申请手动释放
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。内存自动申请自动释放 -
Char *const *(*next)();请对这一行代码进行一下解释?
Next是一个函数指针,指向一个没有参数的函数,并且该函数的返回值是一个指针,该指针指向一个类型为char的指针常量。 -
Char *(*c[10])(int **p);
*c[10]为一个指针数组,其数组中的每一个元素都是函数指针,所指向的函数返回值是char*类型,且函数参数为int **p是一个指向指针的指针 -
请问一下代码是否有问题,如果有问题请指出,没问题运行结果是什么?
Char *pt=”AAA”;
Printf(“%s”,pt); //输出为 AAA
*pt=’B’;
Printf(“%s”,pt); //出错 (段错,核心已转存)
pt=”BBB”;
Printf(“%s”,pt); //输出为 BBB
答”AAA”为字符串常量,编译后放置在内存区的只读区域,只读区域不允许修改,指针指向地址的内容不允许修改,但指针的指向可以修改。
- 在某工程中,要求设置一绝对内存地址为0x40020800的位置,将该地址里面的内容设置为整型值0x3456。编写代码完成这一任务。
以下提供三种方法:
① int *pt;
pt=(unsigned long *)0x40020800;
*pt=0x3456;
② *(unsigned long *)0x40020800=0x3456;
③ #define ADDR (*(volatile unsigned long *)0x40020800)
ADDR=0x3456;
- typedef在C语言中频繁用以声明一个已经存在的数据类型的同义字。也可以用预处理器做类似的事。例如,思考一下下面的例子:
#define dPS (struct s *)
typedef (struct s *) tPS;
以上两种情况的意图都是要定义dPS和tPS作为一个指向结构s指针。哪种方法更好呢?
①定义一个变量的情况下:
dps p1; --->struct s *p1; //俩者没什么区别
tps p2; --->struct s *p2;
②定义多个变量的情况下:
dps p1,p2; --->struct s *p1,p2; //p1是结构体指针,p2是结构体s的对象
tps p3,p4; --->struct s *p3,p4; //p3,p4都是结构体指针
综上,给数据类型起别名 建议用typedef
- 下列代码是否有问题,如果有问题,那么编译运行后的结果是什么,并说明问题的原因是什么,那该如何修改。
#include <stdio.h>
char *get_str(void) ;
int main (void)
{
char *p = get_str() ;
printf ("%s \n", p);
return 0;
}
char *get_str(void)
{
char str[] = {"abcd"};
return str;
}
答:运行出错,str为局部变量,存放在栈区,随着get_str函数结束而被系统回收,所以main函数中的p=NULL,修改:
①将str放置内存的静态存储区,不会随着get_str函数的结束而被系统回收
char str[] = {"abcd"} ; ------> static char str[] = {"abcd"} ;
②令str作为指针指向字符串常量,存放在固定区域,get_str函数结束str指向的字符串常量不会消失。
char str[] = {"abcd"} ; ------> char *str = {"abcd"} ;
- 下面所示的代码运行的结果是什么?
#include <stdio.h>
int main (void)
{
unsigned int a= 6;
int=-20;
(a+b > 6) ? puts(">6") : puts("<=6"); // 输出 >6
Printf(“a+b=%d”,a+b); //输出 -14 %d是显示有符号整数
Printf(“a+b=%u”,a+b); //输出 4294967282 %u是显示无符号整数
return 0;
}
答:>6。因为数字在计算机中都是以补码的形式存在,当无符号整数与有符号整数相加时,会发生自动类型转换,及 将有符号数转换为无符号数。
正数的补码=原码=反码
负数的反码等于原码取反(符号位不变),补码=反码+1
- 什么是大端模式,什么是小端模式,编写段代码测试你的计算机是大端模式还是小端模式?
答:
大端模式:数据的低位放在内存高地址中,数据的高位放在内存的低地址中
小端模式:数据的高位放在内存高地址中,数据的低位放在内存的低地址中
#include <stdio.h>
int main(void)
{
int i;
union Test
{
unsigned int n;
char arr[ 4];
};
union Test num;
num. n = 0x12345678; //12、34、56、78分别占一字节
for(i = 0; i< 4; i++)
printf ( "&arr[ %d]= %p, arr[%d] =#x\n",i,&num.arr[i],i,num.arr[i]);
}
union内成员公用内存空间,该所占内存大小为4字节
输出:
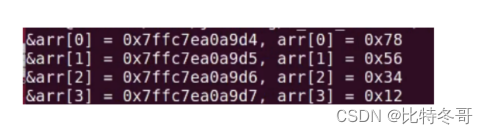
- 取出当前计算机系统下无符号整数int类型的0值和其最大值
unsigned int zero = 0;
unsigned int compzero= ~0;
- printf()函数的返回值为打印字符的个数
int i = 43;
printf ("%d \n", printf ("%d",printf("%d",i))) ; //输出为4321
- 举例说明,通过 #运算符,利用宏参数创建字符串
①
#define SQUARE(x) (printf("x square is : %d\n",(×)*(x)))
SQUARE(4); //输出为: x square is:16
②
#define SQUARE(x) (printf(""#x" square is : %d\n",(×)*(x)))
SQUARE(4); //输出为: 4 square is:16
“#”可以将普通文本替换成语言符号
- 举例说明,“##”运算符的作用。
预处理的粘合剂,用它把两个语言符号合并成个语言符号
#define XNAME(n) x##n
则有 int x1=10 等价于 int XNAME(1)=10
- 结构体变量中使用字符数组优于字符指针
struct std
{
unsigned int id;
char *name;
unsigned int age;
}per;
strcpy(per.name,"Micheal Jackson"); //报错,name未初始化且未申请内存,野指针 存在一定风险
- C和C++中,
free()和delete是如何操作指向动态开辟内存的指针的?
// char *p=(char *)malloc(100); //c语言
char *p=new char[100]; //c++
Strcpy(p,”ABCDEF”);
cout<<”p=”<<p; //输出 ABCDEF
// free(p);
delete []p;
If(p!=0){ //c++中可用0来表示空指针
Strcpy(p,”hello world”);
cout<<”p=”<<p; //输出 hello world
}
所以指针一般释放完后不再使用,而是置空 free(p); p=NULL;
free和delete:将该指针所指向的内存给释放掉,但是并没有把指针本身给消除掉
#define offsetof(TYPE,MEMBER) ((size_t)&((TYPE *)0)->MEMBER)请尝试解释下上面这行语句的含义。
1)(TYPE*)0:将0强制类型转换为TPYE类型的指针,p = (TYPE*)0
2)((TYPE *)0)->MEMBER----> p->MEMBER—>访问MEMBER成员变量
3)&((TYPE *)0)->MEMBER: 取出MEMBER成员变量的地址
4)(size t)&((TYPE*)))->MEMBER: size_t相当于类型转换,将MEMBER成员变量的地址转换为size_t类型的数据,size_t== int
总结:该宏的作用就是求出MEMBER成员变量在TYPE中的偏移量
- const关键字作用:
(1)const定义一个常量,这个常量在定义时必须进行初始化,否则以后就没有机会了
(2)实际上const定义的变量并不是一个真正的常量(指针,数组两种方式验证这个观点)
const int i=10;
// int a[i]; 会报错,因为i并没有成为真正意义上的常量
int *pt=&i;
*pt=20;
printf(“i=%d”,i); //输出20,即可证明i并不是真正的常量,本质依旧是变量
(3)const和指针的用法
const int *pt; //两者相同,都代表pt指针可以指向任意对象,但是不能通过pt指针来修改指向对象的值。
int const *pt;
Int *const pt; //可以修改指向对象的值,不可以修改为指向其他对象
(4)const修饰形参
-
Fork()函数 下面这段代码共创建几个进程
int main()
{
fork()||fork();
}
一共会创建3个子进程,左边先第一个fork()函数时,父进程返回子进程pid号,子进程返回0,所以父进程不再去运行右边的fork()函数,而子进程则会去运行右边的fork()函数进而生成一个孙子进程,所以一个有3个进程 -
若MyClass为一个类,执行“
MyClass a[4],*p[5];”语句时会自动调用该类构造函数的次数是?
答:4次,构造函数是每创建一个类的对象调用一次,则a[4]调用4次,而*p[5]为指向对象的指针 不会调用构造函数 -
统计二进制数中1的个数 例:求下面函数的返回值
int func (int x)
{
int countx = 0;
while(x)
{
countx++;x=x& (x-1);
}
return countx;
}
答:
x-1: 将二进制数从右往左数,遇到的第一个1变成0,右边的所有0变成1,左边的所有数保持不变
200 ---> 11001000
200-1 ----> 11000111
200&200-1 ----> 11001000 & 11000111 --->11000000
x&(x-1) -->从右往左数,遇到的第一个1变成0,左边的数不变,右边的数全部为0 即将二进制数从右往左数,遇到的第一个1变成0。
- 判断一个数是否为2的n次方
2--->10 4--->100 8--->1000 16--->10000 32--->100000 ....
所以也可以用37题那样用x&x-1进行判断,如果结果等于0 则为2的n次方
- 变量置位和清零操作 给定一个整型变量a,写两段代码,第一个设置a的bit3,第二个清除a的bit3。
答:
只要出现置1:或操作
只要出现清0:与操作
移位操作:左移:<< 右移:>>
a第三位置1 : a|=(1<<3)
a第三位置0: a&=~(1<<3)
- sizeof运算符中的表达式 请说明下面代码的运行结果:
#include <stdio.h>
int main (void)
{
int i ;i = 10;
printf ("%d\n", i); //输出10
printf ("%1d\n", sizeof(i++)) ; //输出4 (int占4字节)
printf ("%d\n", i); //③输出10
return 0;
}
③sizeof不是函数,sizeof是运算符
sizeof不会计算里面表达式的值,只判断表达式结果是什么类型就可以(即sizeof(i++)不会运行i++这个表达式)
- 指针+整数 请说明下面代码的运行结果:
unsigned char *p1 ;
unsigned long *p2;
pl = (unsigned char *)0x801000;
p2 = (unsigend long *)0x801000;
请问:p1 + 5 = ?p2 + 5 = ?
答:
指针+1:指针+1不是地址加1,所增加的地址值为这个指针指向的类型所占用的内存大小,指针+1 ==地址+ sizeof(指向数据的类型),且 sizeof(指向数据的类型)为十进制需转换为16进制再相加
p1 + 1 = 0x801000 + sizeof(unsigned char)=0x801000 + 1 = 0x801000
p2 +1 = 0x801000 + sizeof (unsigned long)=0x801000 + 4 = 0x801004
p1 + 5 = 0x801000 + sizeof(unsigned char)*5= 0x801005
p2 + 5 = 0x801000 + sizeof (unsigned long)*5= 0x801000 + 4 *5 = 0x801014 //(20=0x16)
- volatile关键字 下面的函数有什么错误:
int square(volatile int *pt)
{
return (*pt)*(*pt) ;
}
答:
编译器会对这段代码进行如下处理;
int square(volatile int *pt)
{
int a,b;
a= *pt; //每使用一次*pt编译器都会重新定义一个数指定它 即可能出现
b = *pt; //当a指向*pt=4时,b再指向*pt 就可能变成5了,*pt可能发生变化
return a * b;
}
正确写法:
Int square(volatile int *pt)
{
int a;
a=*pt;
return a*a;
}
- 如果a为数组,则a和&a的区别
int main()
{
int a[5]={1,2,3,4,5};
int *pt=(int *)(&a+1); //&a是指向整个数组的地址,*pt是指向单个元素的
printf(“%d,%d”,*(a+1),*(pt-1)); //输出 2 和 5 地址,所以需强制转换
return 0;
}
(1) a==&a a+1!=&a+1
a:数组名,表示数组中第一个元素的地址,指向的是数组中元素的地址
&a:整个数组再内存中的起始地址,指向的是整个数组作为一个单元的起始地址
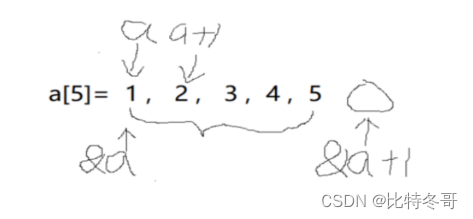
- 不使用第三个变量的情况下 交换俩个变量的值
a=a+b;
b=a-b;
a=a-b;
- 运算符优先级
cout<<(5>6)?5:6; //输出0 <<优先级大于 ? : ;
cout<<((5>6)?5:6); //输出6 加(),()优先级高
-
字符指针,浮点数指针,以及函数指针这三种类型的变量,占用内存一样大
-
交换8位整数的高四位和低四位 如
0xC2 ----> 0x2C
void convert(unsigned int *pt)
{
unsigned int temp=*pt & 0x0F; //get low 4bit
*pt=*pt & 0xF0; //get high 4bit
*pt=(temp<<4)|(*pt>>4);
}
- 一级指针和二级指针 假如有如下定义:
char *str[4] ={"ABCD","EFGH","IJKL","MNOP"};
如何定义一个指针指向str?
char **pt=str;
(char *pt[]==char **pt)
一级指针: int *pt; --> pt指针指向的地址里面存放的是int类型的数据
二级指针: int **pt; -->pt指针指向的地址里面存放的是一个指向整型变量的地址
- 数组x复制50个字节到数组y的最简单方式 (字节!=元素,char类型1元素=1字节)
memcpy(y,x,50); //(字节复制函数) int类型 1元素=4字节
- 将数字字符串转换为整数
为下面这个函数原型编写函数定义:int ascii_to_integer (char *string) ;
这个字符串参数必须包含一个或多个数字,函数应该把这些数字字符转换为整数并返回这个整数,如何字符串参数包含了任何非数字字符,函数就返回0.
int ascii_to_integer (char *string)
{
int value=0;
while(*string>=’0’&&*string<=’9’)
{
value*=10;
value+=*string-’0’;
string++;
}
if(*string!=’\0’) return 0;
return value;
}
- typedef定义函数指针类型 请问如下语句是什么意思?
typedef int (*funcptr) () ;
(1)int (*funcptr) () ;
funcptr:函数指针,指向的函数无参数,并且返回值类型是int类型的函数
(2)typedef int (*funcptr) () ;
funcptr:表示类型,函数指针类型
(3)funcptr fp1,fp2; 等价于 int (*fp1)(); int (*fp2)();
-
C和C++语言中const关键字的区别
在C语言中,const int n=5; int a[n]; 会报错,因为n并没有变成真正意义上的常量,实质上仍是变量,而在C++中,不会报错,const 修饰过后的n可以当成常量使用 -
浮点数四舍五入取整
(int)(x<0?x-0.5:x+0.5)
- 字符数组和字符指针的区别
char str1[]=”abc”;
char str2[]=”abc”;
const char str3[]=”abc”;
const char str4[]=”abc”;
const char *str5=”abc”;
const char *str6=”abc”;
char *str7=”abc”;
char *str8=”abc”; //可能会出现(warning/error),指针指向字符串常量地址,不允许修改指向的地址内容
cout<<(str1==str2)<<endl; //输出0,俩数组str指向不同的地址
cout<<(str3==str4)<<endl; //输出0,俩数组str指向不同的地址
cout<<(str5==str6)<<endl; //输出1,俩个常量指针str指向同一块地址
cout<<(str7==str8)<<endl; //输出1,俩指针指向同一块地址
- 一个类中公有成员函数的调用一定要通过类的对象来调用。 (错)
因为构造函数可以不通过类的对象被调用
class A{
public:
A(){cout<<”hello”;}
void B(void)
{
cout<<”nihao”;
}
};
int mian()
{
A(); //构造函数可以不通过类的对象被调用
B(); //报错,必须通过类的对象被调用
}
- 函数指针 一个函数如下所示,简单分析下这个函数并指出这个函数的功能
void call_each (void (**a)(void),int size)
{
int n = size;
while(--n >=0)
{
void (*p)(void)= *a++; //取出a数组中的一个函数指针 赋值给p
if(p)
(*p)(); //如果p不为NULL,则通过函数指针p来调用指向的函数
}
}
(1)**a==*a[] —> a是数组,数组中每个元素的类型是void (*)(void),即a为函数指针数组
(2)void (*p)(void)=*a++; //函数指针的赋值语句
void (*p)(void) p为函数指针,*a为函数指针数组中的内容,即函数指针
- C++临时变量 假如有如下C++函数:
void bar (string &s);
为什么下面的调用是错误的?
bar ("He1lo world") ; //报错
如果想正确调用,该如何实现?
C++中实参类型正确,但不是左值 会产生临时变量,临时变量指向”HelloWorld”为const string变量,而void bar (string &s); 为string型,所以信号不匹配 会报错
正确调用:void bar (const string &s);
- 任意进制的整数转换为十进制 编写一段代码,将任意一个n进制整数x转换为十进制。输入进制2->bin 8->oct 16->hex
键盘输入数字,键盘输入的实际是一个字符串123 --> 字符‘1’,‘2’,‘3’
#include<stdio.h>
#include<ctype.h>
int main()
{
int n;
int i=0;
int result=0;
char ch[64];
printf("Please enter your choice:2->bin,8->oct,16->hex\n");
scanf("%d",&n);
printf("Please enter a number:");
getchar(); //捕获回车键
while((ch[i]=getchar())!='\n'){
if(ch[i]>='A'){
ch[i]=tolower(ch[i]); //转换为小写字母
result=result*n+(ch[i]-'a'+10);
}
else
result=result*n+(ch[i]-'0');
i++;
}
printf("After convert: %d\n",result);
}
- 编写一个lambda,捕获它所在的函数的int,并接受一个int参数,lambda应该返回捕获的int和int参数的和。
①int a=10; auto sum=[a](int b){ cout<<a+b; } sum(20); //输出30
②int a=10; auto sum=[=](int b){ cout<<a+b; } sum(20); //输出30
③int a=10; auto sum=[&](int b){ cout<<a+b; } sum(20); //输出30
- 前向声明和不完全类型 定义一对类X和Y,其中X包含一个类型为Y的对象,而Y包含一个指向X的指针。
class X; //前向声明
class Y {
X *x;
};
class X{
Y y;
};
前向声明为不完全类,可以定义指向不完全类的指针,但不能创建不完全类的对象
- 初始化vector对象的六种方法
①vector<int> list1={1,2,3,4,5,6}; or vector<int> list1{1,2,3,4,5,6};
②vector<int> list2;
③vector<int> list3=list1;
④vector<int> list4(list1.begin()+2,list1.end()-1); //list4={3,4,5};
⑤vector<int> list5(10); //初始化list5,里面有10个元素,且都为0
⑥vector<int> list6(10,3); //初始化list6,里面有10给元素,且都为3
- 内存分配 查看下面代码,看有无问题,如果有问题如何修改
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
void getmeory(char *p);
int main()
{
char *str=NULL;
getmeory(str);
strcpy(str,”Hello world!”);
printf(“%s\n”,str);
}
void getmeory(char *p)
{
p=(char *)malloc(100);
}
答:第一,getmeory函数中p为局部变量,调用完后会被系统回收,而实参str仍为NULL;第二,主函数里面str为char型指针,而getmeory传入的也是char型指针,可见为值传递,并不是地址传递,若按地址传递,则形参与实参共同拥有一段内存空间,形参的变化也就是实参的变化。所以按地址传递,这里需用到指向指针的指针具体修改如下:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
void getmeory(char **p);
int main()
{
char *str=NULL;
getmeory(&str);
strcpy(str,"hello world!");
printf("%s\n",str);
}
void getmeory(char **p)
{
*p=(char *)malloc(100);
}
- 如何在类声明中定义常量 这个类声明正确吗?为什么?
class A{
const int size=10;
};
不正确。一个类在没有创建类的对象之前是没有内存空间去分配 以下给出3种方法:
①enum{ size=10 }; //枚举类型
②static const int size=10; //静态成员变量
③public: A(const int size=10){}; //构造函数
- 简述
SPI IIC UART接口的区别和各自收发数据的方法
- UART是全双工通信方式,两根数据线RX和TX,通信时双方需要共地,数据的传输速度由波特率决定,所以每位数据的收发完全依靠精确的时间来控制。
- IIC总线是半双工通信方式,支持一个主机多个从机,在通信时主机必须固定,通过地址来区分从机,两根数据线SCL,SDA,数据的收发依靠时钟线进行控制。
- SPI总线是全双工通信方式,支持一个主机多个从机,通信是主机可以发生改变,是真正的多主机总线,4跟数据线,CS,MISO,MOSI,SCL,通过片选线来控制与哪个从机进行通信,通过时钟线控制数据收发。
- 试描述TCP建立和断开连接时的三次握手和四次挥手
- 三次握手:
(1)客户端先发送标志位SYN=1,seq=x请求与服务器建立连接
(2)服务器收到客户端的TCP报文后,返回标志位SYN=1,ACK=1,seq=y,ack=x+1的报文应答客户端并同意建议连接
(3)客户端收到服务器的TCP报文后,返回标志位ACK=1,seq=x+1,ack=y+1的报文表示接收到服务器的消息并建立连接 - 四次挥手:
(1)客户端向服务器发送标志位FIN=1,seq=x的报文请求断开连接
(2)服务器收到后,返回标志位ACK=1,seq=y,ack=x+1的报文告诉客户端收到报文,并准备断开连接
(3)服务器做好断开连接的准备后,给客户端发送标志位FIN=1,ACK=1,seq=u,ack=x+1的报文告诉客户端已做好准备断开连接
(4)客户端收到报文后,返回标志位ACK=1,seq=x+1,ack=u+1的报文表示收到消息并断开连接
-
工厂生产摩拜单车包含两道工序,工序A每5min生产一辆摩拜单车,生产完成后送到工序B检测,每1min检测一辆,检测失败的需要返回工序A重新生产;试用多线程(多任务)的机制实现上述的生产工序,实现产能的最大化。
(1) 创建两个线程ThreadA,ThreadB,分别用于A和B两个工序,创建消息队列QueueA用于A发送给B两个线程之前做消息通讯,创建一个链表List,用于存放B返回给A的单车,同事链表有一个互斥锁,Lock,用于保护链表,避免A B两个线程同时进行操作;
(2) ThreadA,生产完一辆单车,通过消息队列发送给ThreadB,然后检测链表list,是否有需要重新生产的单车,若有则进行重新生产;
(3) ThreadB,处于监听消息队列,若监听到A发过来的消息队列在,进行检测处理,若有不合格的单车,则把单车加入到链表List中; -
写出 float x 与“零值”比较的 if 语句
if(x > -0.000001 && x < 0.000001);
解读:因为计算机在处理浮点数的时候是有误差的,所以不能将浮点型变量用“==”或“!=”与数字比较,应该设法转化成“>”或“<”此类形式。
- 下面代码有什么错误?
char *s = "AAA";
答:"AAA"是字符串常量,s是指针,指向这个字符串常量,所以声明s的时候就有问题,应该是const char* s=“AAA”。
- 假设在一个32位little endian 的机器上运行下面的程序,结果是多少?
#include<stdio.h>
int main()
{
long long a=1,b=2,c=3;
printf("%d %d %d",a,b,c);
return 0;
}
答:输出为 1 0 2
解析:小端模式,高位在高地址,即a、b、c存放为:
a:1 ----> 0001 0000 0000 0000 0000 0000 0000 0000
b:2 ----> 0010 0000 0000 0000 0000 0000 0000 0000
c:3 ----> 0011 0000 0000 0000 0000 0000 0000 0000
printf()函数中%d为连续4字节输出,而long long为8字节,所以输出形式为:a分2次输出,再输出b的4字节,即%d %d %d 对应 0001 0000 0000 0000 0000 0000 0000 0000 0010 0000 0000 0000
因此,第一个%d输出1,第二个%d输出0,第三个%d输出2。
如果改成printf(“%d “, a);printf(”%d “, b);printf(”%d\n”, c);那结果就是1,2,3.
- 当参数*x=1, *y=1, *z=1时,下列不可能是函数add的返回值的( )?
int add(int *x, int *y, int *z){
*x += *x;
*y += *x;
*z += *y;
return *z;
}
A. 4 B.5 C.6 D.7
答案为:D
以上可分为以下5种情况:
① x、y、z指向同一块区域时 add返回8;
② x、y指向同一块区域时 add返回5;
③ x、z指向同一块区域时 add返回5;
④ y、z指向同一块区域时 add返回6;
⑤ x、y、z各自指向不同区域时 add返回4;
- sizeof指所占内存大小,遇到“\0”结束,数组末尾还有隐藏的“\0”,占一字节,strlen是字符串长度,如:
char a[]="abcdef";
int b[5]={1,2,3,4,5};
printf("%d %d %d\n",sizeof(a),strlen(a),sizeof(b)); //7 6 20
即 sizeof(a)=7; strlen(a)=6; sizeof(b)=20;
-
点乘和叉乘的区别
假如 有 向量a(x1, y1),向量b(x2, y2)
点乘:又叫内积/数量积,记作a·b,点乘的结果是个标量,它的几何意义是 向量a在向量b上的投影长度乘以向量b的长度,计算公式为x1 * x2 + y1 * y2 = |a|*|b| *cos<a,b>
叉乘:又叫外积/向量积,记作axb,注意叉乘的结果是个向量,所以它有方向和模长,可以理解为平行四边形的有向面积,计算公式为x1 * y2 - x2 * y1 = |a|*|b|* sin<a,b> -
C++ cout输出字符型指针 下面代码运行的结果是什么?指针还是字符串?
const char *prt=”Hello world”;
cout<<ptr<<endl; //输出Hello world
int i=10;
int *pt=&i;
cout<<pt; //输出为i的地址
输出为“Hello world”,因为C++用指针字符串存储位置的指针来表示字符串,指针的形式可以是char数组名、显示的char指针或用引号括起的字符串。所以 下面的cout语句也都显示字符串:
char name[20]=”Hello”;
char *p=”world”;
cout<<”nihao”; //输出nihao
cout<<name; //输出Hello
cout<<p; //输出world
若要获得字符串的地址,则必须将其强制转换为其他类型,如下面代码片所示:
char *amount=”dozen”;
cout<<(void*)amount; //输出为字符串的地址
- 野指针引发的错误 看下面一段程序 是否有什么错误?
void swap(int *p1,int *p2)
{
int *p;
*p=*p1;
*p1=*p2;
*p2=*p;
}
报错:段错误,核心已转存,int *p为一个野指针,可能指向内存中一个位置的地方,且指向的地方有可能不允许我们去访问(为内存当中受保护的区域)。
修正:
void swap(int *p1,int *p2)
{
int p;
p=*p1;
*p1=*p2;
*p2=p;
}
- 引用的数组和数组的引用 下面语句代表什么含义?请指出是否有不正确的.
(1)int &arr[10]; ---> 报错,引用的数组是不存在的
(2)int num[3]={10,20,30};
int (&arr)[10]=num; ----> arr是引用,是数组的引用,是绑定有10个int元素的数组
可以有数组的引用,但是没有引用的数组
#include<iostream>
using namespace std;
int main()
{
int a=10,b=20,c=30;
int &ra=a;
int &rb=b;
int &rc=c;
//int &arr[3]={ra,rb,rc}; 报错,不存在引用的数组
int num[3]={a,b,c};
int (&arr)[3]=num; //数组的引用
for(int i=0;i<3;i++)
cout<<arr[i]<<" "; //输出10 20 30
cout<<endl;
return 0;
}
- 用C代码查看一个文件大小
#include<stdio.h>
#include<stdlib.h>
int main()
{
FILE *fp;
long int size=0;
fp=fopen("test.txt","r"); //以只读的方式打开当前目录下test.txt文件
fseek(fp,0,SEEK_END); //将文件位置指针指向文件末尾
size=ftell(fp); //获取文件位置指针相对于文件首的偏移字节数
fclose(fp);
printf("The size of file is:%ld\n",size);
return 0;
}
- 逗号表达式 下列语句的运算结果是:
int main()
{
int x=10,y=3,z;
printf(“%d\n”,z=(x%y,x/y));
return 0;
}
逗号表达式的一般形式:(表达式1,表达式2,表达式3…表达式n) ---->整个表达式的值为表达式n,即上面z=(1,3); 所以z=3;
- 成员初始化列表(只限于构造函数和非静态const数据成员)
①如果Classy是一个类,而mem1、mem2和mem3都是这个类的数据成员,则类构造函数可以使用如下的语法来初始化数据成员:
Classy::Classy(int n,int m):mem1(n),mem2(0),mem3(n*m+2)
{
}
上述代码将mem1初始化为n,将mem2初始化为0,将mem3初始化为n*m+2。
②派生类(子类)构造函数可以使用初始化器列表机制将值传递给基类(父类)构造函数
创建派生类对象时,程序首先调用基类构造函数,然后再调用派生类构造函数,先调用派生类的析构函数,再调用基类的析构函数
#include<iostream>
using namespace std;
class BASE
{
char c;
public:
BASE(char n):c(n) // 类的成员初始化列表的方法
{
}
virtual ~BASE() //基类里要有一个虚析构函数
{
cout<<c; //输出Y
}
};
class DERIVED:public BASE //继承BASE
{
char c;
public:
DERIVED(char n):BASE(n+1),c(n) //派生类(子类)构造函数可以使用初始化器列表机制将值传递给基类(父类)构造函数
{
}
~DERIVED()
{
cout<<c; //输出X
}
};
int main(){
DERIVED('X'); //匿名的DERIVED类对象 先调用基类构造函数,再调用派生类构造函数,先调用派生类的析构函数,再调用基类的析构函数
return 0;
}
输出为 XY
-
运算符优先级和结合律
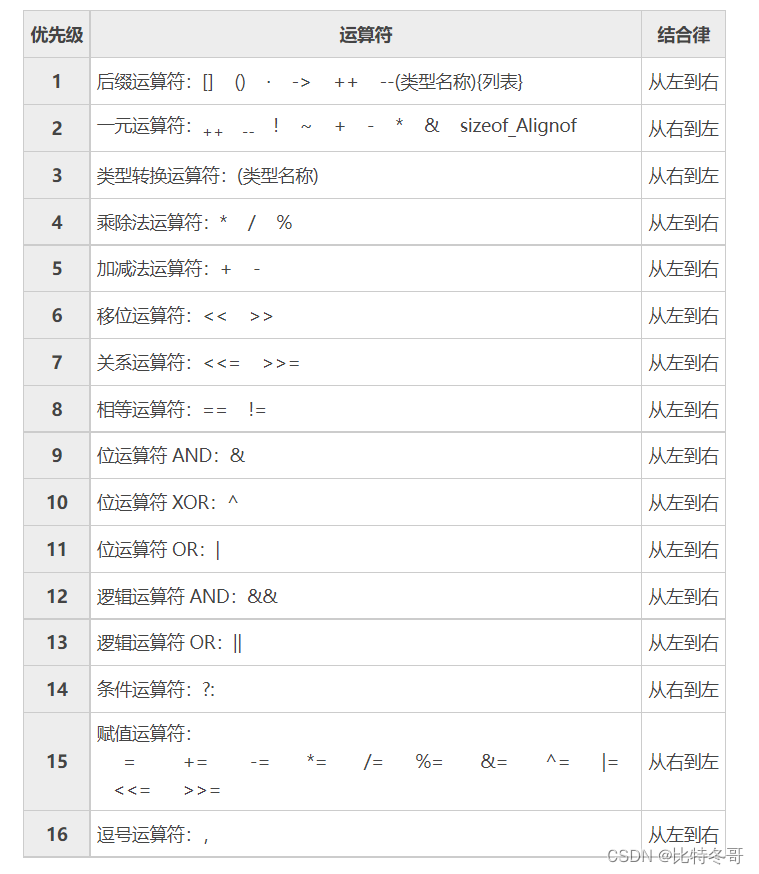
-
浮点数与位操作 下列表达式式中,()是合法的。已知double m=3.2,int n=3;
A.!m*=n B. (m+n)|n C. m=5,n=3.1,m+n D. m<<2
答案选C
A: !优先级高于*=,所以 !m*=n —> flase*=n —> 0*=3 0不能再赋值,所以错误
B: (m+n)|n —> 6.2|3 由于”|”位操作运算符 俩侧都必须是整数,所以错误
C: m=5.0,n=3, 则m+n=5.0+3.0=8.0 正确
D: m<<2 —> 3.2<<2 “<<”位操作运算符 运算符俩侧都必须为整数,所以错误 -
new运算符 假定p是具有
int **类型的指针变量,则给p赋值的正确语句为()
A、p=new int;B、p=new int[10];
C、p=new int*;D、p=new int**;
答案选C
A:new int;开辟一段内存空间,里面存放的是整数,new运算符返回的是地址 用指针接受,即定义一个指向证书的指针。int *p=new int;
B:new int[10];开辟一段内存空间,里面存放的是数组,new int[10]返回这段内存空间的首地址,即定义一个指向数组的指针。int arr[10]={0};int *p=arr;—>int *p=new int[10];
C:new int*;开辟一段内存空间,里面存放的是指针,则需要定义一个指向指针的指针作为new int*的返回值。int **p=new int*;
D:int ***p=new int**; -
有符号数和无符号数 下面程序的输出结果是()
int main()
{
char x=0xFF;
printf(“%d\n”,x--);
return 0;
}
A、-1 B、0 C、255 D、256
答案选A
char x=0xFF —> 1111 1111 —>%d的格式转换显示 十进制+有符号
有符号的最高位为1 那么说明这个数一定是负数
有符号数在内存当中是以补码的形式存储的 ,所以补码(反码+1)为 1111 1111,即可求出反码为 1111 1110,原码=反码取反(符号位不变):1000 0001 ----> 原码=-1
-
请问在C语言中,关键字static有哪三个明显的作用?
①在函数体,一个被声明为静态的变量在这一函数被调用过程中维持其值不变。
②在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所用函数访问,但不能被模块外其它函数访问,它是一个本地的全局变量。
③在模块内,一个被声明为静态的函数只可被这一模块内的其它函数调用。那就是,这个函数被限制在声明它的模块的本地范围内使用。 -
如何让程序陷入无限循环(C语言)
// for循环
for(;;);
// while 循环
while(1);
// do while
do{}while(1);
// goto方式
state:
goto state;
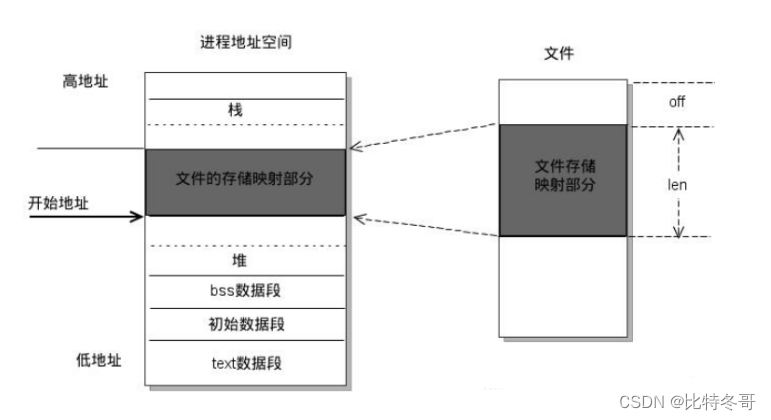
- 进程通信的方式?共享内存是怎么做的?
①进程通信方式:
a. 信号量
b. 消息队列
c. 管道
i. 匿名(需要血缘关系)
ii. 有名(不需要血缘关系)
iii. 高级(另一个程序在当前程序打开,算是当前程序的子进程,称高级管道)
d. socket(套接字)
e. 共享内存通信(最快)
②共享内存怎么做?
特别提醒:共享内存并未提供同步机制,也就是说,在第一个进程结束对共享内存的写操作之前,并无自动机制可以阻止第二个进程开始对它进行读取。所以我们通常需要用其他的机制来同步对共享内存的访问,例如信号量。
a. 创建共享内存,指定key、size、mode(权限)
b. 将当前进程连接到共享内存
c. 把共享内存的地址读取出来,并强制转换为本地变量
d. 读写操作了
做法:将同一段物理内存映射到堆与栈之间的那一段虚拟内存中
- C语言如何面向对象
多态
#include "stdio.h"
typedef struct Person{
char *name;
void (*eat)();
}Person;
void fun1(){
printf("student eat!\r\n");
}
void fun2(){
printf("teacher eat!\r\n");
}
int main(){
Person student={"student",fun1};
Person teacher={"teacher",fun2};
student.eat();
teacher.eat();
}
-
线程和进程的区别
① 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
②进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
③进程是资源分配的最小单位,线程是CPU调度的最小单位;
④系统开销: 进程切换的开销也远大于线程切换的开销。
⑤通信:由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
⑥进程间不会相互影响 ;线程一个线程挂掉将导致整个进程挂掉 -
实现strcpy和swap
#include "stdio.h"
void mstrcpy(char * dest,const char * src){
while(*src!='\0'){
*dest++=*src++;
}
}
void swap(int *a,int *b){
*a=*a+*b;// a=11
*b=*a-*b;// b=11-6=5
*a=*a-*b;// a=11-5=6
}
int main(){
char buf[20]={0};
mstrcpy(buf,"123123123123");
printf("\r\n%s\r\n",buf);
int a=10;
int b=20;
swap(&a,&b);
printf("\r\n%d,%d\r\n",a,b);
return 0;
}
-
请问什么是预编译,何时需要预编译?
总是使用不经常改动的大型代码体;程序由多个模块组成,所有模块都使用一组标准的包含文件和相同的编译选项。在这种情况下,可以将所有包含文件预编译为一个预编译头。
预编译指令指示了在程序正式编译前就由编译器进行的操作,可以放在程序中的任何位置。 -
请问局部变量能否和全局变量重名
能,局部会屏蔽全局。
局部变量可以与全局变量同名,在函数内引用这个变量时,会用到同名的局部变量,而不会用到全局变量 -
请问引用与指针有什么区别?
1)引用必须被初始化,指针不必。
2)引用初始化以后不能被改变,指针可以改变所指的对象。
3)不存在指向空值的引用,但是存在指向空值的指针。 -
请问以下代码有什么问题:
int main()
{
char a;
char *str=&a;
strcpy(str,"hello");
printf(str);
return 0;
}
没有为str分配内存空间,将会发生异常,问题出在将一个字符串复制进一个字符变量指针所指地址。虽然可以正确输出结果,但因为越界进行内在读写而导致程序崩溃。
- 联合体和结构体占内存大小 观察以下代码在64位系统下分别输出多少?
#include <iostream>
using namespace std;
typedef union
{
long i;
char k[13];
char c;
} DATE;
struct data
{
int cat;
DATE cow;
double dog;
} too;
int main()
{
DATE max;
cout<<sizeof(struct data)<<endl<<sizeof(max);
return 0;
}
输出为 32 16
①联合体中,所有成员共用一块内存,在64为系统下long为8字节,即为8字节对齐,又char k[13]占13字节,所以sizeof(max)=16;
②结构体中,各成员各自占有一块内存,同时共存,在上述结构体中,由于DATE为8字节对齐,所以int car占8字节,其次DATE cow占16字节,最后double dog占8字节,一起占32字节,即sizeof(struct data)=32;
- 预处理器
①用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
#define SECONDS_PER_YEAR (60 * 60 * 24 * 365)UL //UL表示无符号长整形
②已知一个数组table,用一个宏定义,求出数据的元素个数。
#define NTBL (sizeof(table) / sizeof(table[0]))
③写一个"标准"宏MIN ,这个宏输入两个参数并返回较小的一个。
#define MIN(A,B) ( (A) <= (B) ? (A) : (B))
- 数据声明
用变量a给出下面的定义
a) 一个整型数
b)一个指向整型数的指针
c)一个指向指针的的指针,它指向的指针是指向一个整型数
d)一个有10个整型数的数组
e) 一个有10个指针的数组,该指针是指向一个整型数的
f) 一个指向有10个整型数数组的指针
g) 一个指向函数的指针,该函数有一个整型参数并返回一个整型数
h) 一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数
a) int a;
b) int *a;
c) int **a;
d) int a[10];
e) int *a[10];
f) int (*a)[10];
g) int (*a)(int);
h) int (*a[10])(int);
- 将一个链表逆置 如abcd —> dcba
NODE *fun(NODE *h){
NODE *p, *q, *r;
p=h;
if(p==NULL){
return NULL;
}
q=p->next;
p->next=NULL;
while(q){
r=q->next;
q->next=p;
p=q;
q=r;
}
return p;
}
-
设数组data[m]作为循环队列的存储空间。front为队头指针,rear为队尾指针,则执行出队操作后其头指针front值为(D)
A.front=front+1
B.front=(front+1)%(m-1)
C.front=(front-1)%m
D.front=(front+1)%m
解析:循环队列中出队操作后头指针需在循环意义下加1,因此为front=(front+l)%m -
死锁的四个条件及处理方法
(1)互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。解决死锁的方法分为死锁的预防,避免,检测与恢复三种
-
写出两个排序算法,并说明哪个好?
答:一般使用冒泡法和快速排序法,对堆栈局域比较小的单片机来说冒泡法比较好,对时间要求苛刻的实时响应来说快速排序法好。
题注:时间复杂度:一个算法花费的时间与算法中语句的执行次数成正比例,用T(n)表示,n为问题的规模,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。时间频度不同,但时间复杂度可能相同。如:T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
本题中,最坏的情况要计算9+8+7+6+5+4+3+2+1次,即n的级数,结果为n*n/2=(n2)/2。所以冒泡法时间复杂度O(n2)
1) 冒泡法:从小到大排,时间复杂度O(n2)
#define MAX_NUM 10
int a_data[MAX_NUM]={1, 2, 3, 4, 5, 6, 7, 8, 9, 0}; // 也可以用scanf获取
int main(void)
{
int i=0, j=0, tmp=0;
for(i=0; i<MAX_NUM-1; i++) {
for(j=i+1; j<MAX_NUM; j++) {
if(a_data[i] > a_data[j]) { // 如果i不是小于j,则调换
tmp = a_data[i];
a_data[i] = a_data[j];
a_data[j] = tmp;
}
}
}
return 0;
}
2)交换排序-快速排序,类似于二分法:采用递归。选第一个点或中间的点,左边放最小值,右边放最大值,依次递归到最低层的两个元素。因为每递归一次要压栈一次,占用存储空间,所以空间复杂度较高。时间复杂度O(nlog2n)
#define MAX_NUM 16
int a_data[MAX_NUM]={1, 2, 3, 4, 5, 6, 7, 8, 9, 0,11,12,13,14,15,16}; // 也可以用scanf获取
//快速排序
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); // 将中间的这个数和第一个数交换 可换可不换
int i = l, j = r, x = s[l]; // s[l]会先被替换,最后这个值会被写回到s[i],它们也充当了临时变量的角色
while (i < j)
{
while (i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if (i < j)
s[i++] = s[j];
while (i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if (i < j)
s[j--] = s[i];
}
s[i] = x;
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}
int main(void)
{
sort(a_data, 0, MAX_NUM - 1);
}