论文题目:Bidirectional Learning for Domain Adaptation of Semantic Segmentation
本文的域位移是针对虚拟数据和真实数据之间的。
本文的贡献是:
-
提出了一种语义分割的双向学习系统 ,其是一个学习分割适应模型和图像翻译模型的闭环学习系统。
-
对于语义分割,提出了一种基于图像的翻译结果的自监督学习算法。该算法在特征层次上逐步调整目标域和源域。
-
在图像到图像的翻译过程中,引入了感知损失,通过更新分割自适应模型来监督图像的翻译过程。
方法

模型
双向学习
我们学习过程如图b:
F
F
F是在没有成对例子的情况下。学习将图像从
S
S
S域转换到
T
T
T域。
T
T
T是在
F
(
s
)
F(s)
F(s)上训练的分割网络,
S
S
S有标签。
T
T
T没有标签》
前向过程是用
F
F
F翻译结果图像分
F
(
s
)
F(s)
F(s)和T来训练M。
F
(
s
)
F(s)
F(s)的标签还是
S
S
S的标签,M的Losss的函数为:

前一项是对抗损失,后一项是分割损失。
后面的过程是本文新添加的,为了提高翻译结果的质量,在图像翻译网咯中使用了一种感知损失,它测量从一个预先实现好的目标网络中获得特征距离,这里。我们用M来计算特征来获得感知损失,通过加入另外两个损失,**GAN的损失和图形重建损失。**定义学习F的损失函数为:


提高M的自监督学习(SSL)
我们可以预测T的虚假标签,一旦获得了,M的损失函数1变为:

Tssl是
T
T
T的子集,一开始可以是空的。当一个更好的分割适应模型M被实现时,我们可以使用M来预测更多的T的高置信度标签,导致Tssl的大小增长。最近的工作[39]也使用SSL来适应分段。相比之下,我们工作中使用的SSL与对抗性学习相结合,对抗性学习可以更好地适应分段自适应模型。
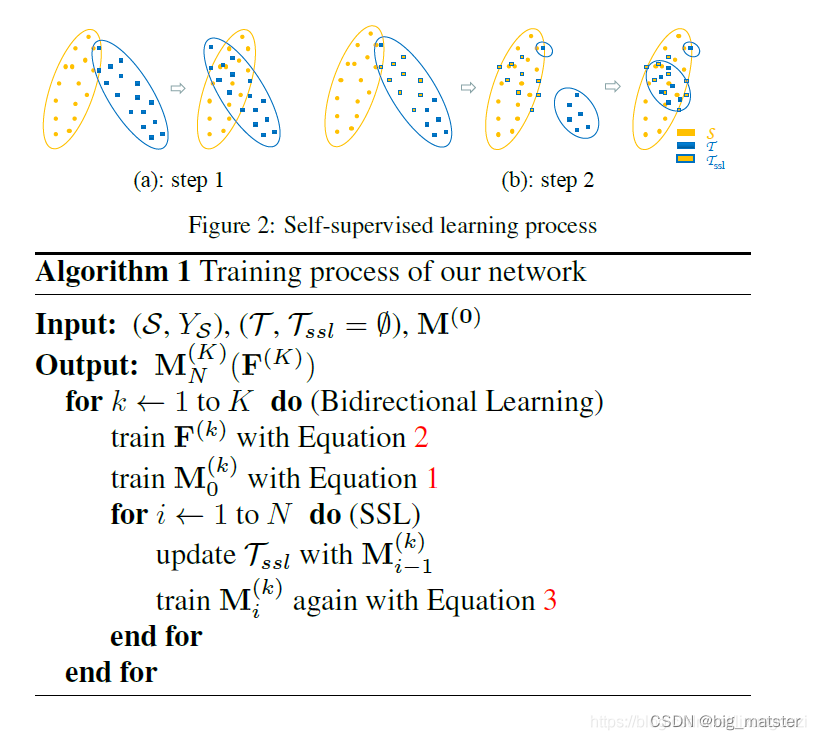
自监督的SSL的过程。第一次分割域适应。TssL先是空集。先训练F,在训练M得到Tss的伪标签。选择T中与S对齐良好的点构成TSSL。
在第二步中。我们可以很容易的将TSSL转换为S。并通过伪标签提供分割的损失来保持它们的对齐。这个过程如图2的中间所示。
因此,需要与S对齐的T中的数据量减少了。我们能继续剩余的数据转移到步骤一中。SSL比LADV更容易关注T与S的不对齐的每一步。
网络与损失函数
前两个损失函数

感知损失连接了图像翻译模型和语义分割自适应模型。
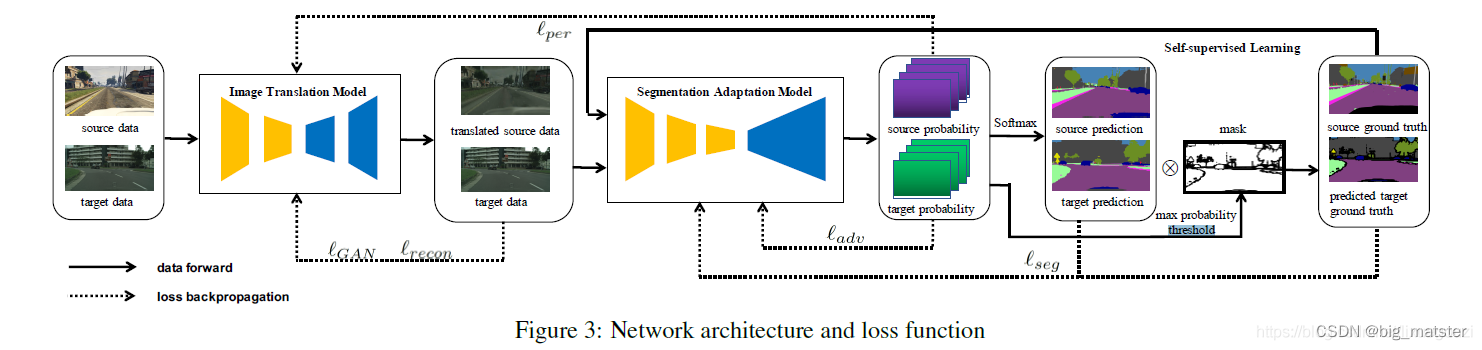
上述描述了整体网路结构和损失函数:双向感知损失变为:
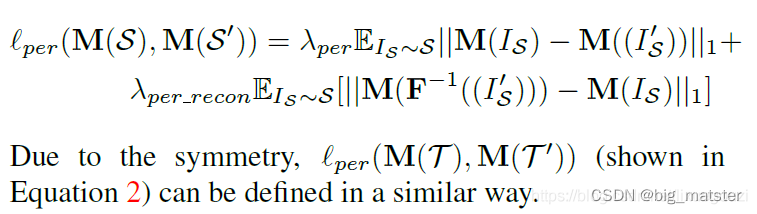

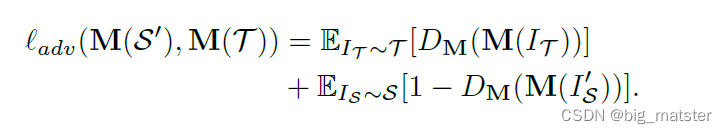
分割损失使用交叉熵损失,源头域图像ls的分割损失为:

对于没有标签的目标域来说,我们使用最大可能性阈值(MPT),
选取预测值中的最大置信度。称为伪标签。分割损失函数定义为:

我们在算法1中给出了训练处理,训练过程由两个循环组成。外环主要是通过前向和后向学习翻译模型和分割适应模型。内部循环主要用于实现SSL流程。
具体算法和参数选择
论文使用GTAS作为训练数据集****,Cityscapes作为目标数据集,翻译模型为**:CycleGAN.分短适应模型**为:DeepLab V2,主干为ResNet101。
- 伪标签的阈值为:0.9
- SSL迭代次数为2.