文章目录
- 一、负载均衡概论
- 1、服务器负载均衡
- 2、客户端负载均衡
- 3、客户端负载均衡策略(SpringCloudRibbon)
- 4、客户端负载均衡策略(SpringCloudLoadBalancer)
- 二、SpringCloudOpenFeign服务调用
- 1、OpenFeign服务调用的使用
- 2、OpenFeign服务调用的日志增强
- 3、OpenFeign服务调用超时机制
- 三、SpringCloudResilience4J服务断路器1
- 1、服务雪崩的解决方案
- 2、SpringCloudResilience4J服务断路器
- 3、Resilience4J的超时降级 (timelimiter)
- 4、Resilience4J的重试机制(retry)
- 5、Resilience4J的熔断降级(circuitbreaker)
- 6、Resilience4J的慢调用熔断降级(slowcircuitbreaker)
- 四、SpringCloudResilience4J服务断路器2
- 1、Resilience4J信号量服务隔离(bulkhead)
- 2、Resilience4J线程池服务隔离(bulkhead)
- 3、Resilience4J的服务限流(ratelimiter)
- 总结(SpringCloud 2022.0.2和SpringBoot 3.0.5)
一、负载均衡概论
1、服务器负载均衡
- 在服务集群内设置一个中心化负载均衡器,例如Nginx。发起服务间调用的时候,服务请求并不直接发向目标服务器,而是发给这个全局负载均衡器,它再根据配置的负载均衡策略将请求转发到目标服务。
- 优点,服务端负载均衡应用范围很广,它不依赖于服务发现技术,客户端并不需要拉取完整的服务列表;同时,发起服务调用的客户端也不用操心该使用什么负载均衡策略。
- 劣势,网络消耗以及复杂度和故障率提升。
2、客户端负载均衡
- SpringCloudLoadbalancer采用了客户端负载均衡技术,每个发起服务调用的客户端都存有完整的目标服务地址列表,根据配置的负载均衡策略,由客户端自己决定向哪台服务器发起调用。
- 优势,网络开销小并且配置灵活
- 劣势,需要满足一个前置条件,发起服务调用的客户端需要获取所有目标服务的地址,这样它才能使用负载均衡规则选取要调用的服务。即客户端负载均衡技术需要依赖服务发现技术来获取服务列表。
- 客户端负载均衡,可以使用Eureka来获取微服务实例清单,缓存到本地;然后通过Loadbalancer根据负载均衡策略从服务实例清单列表中选择具体实例。
- SpringCloudRibbon,是NetFlix发布的负载均衡器,它有助于http和tcp的客户端行为。可以根据负载均衡算法(轮询、随机或自定义)自动帮助服务消费者请求,默认就是轮询。
- SpringCloudLoadBalancer,由于Ribbon已经进入停更维护状态,并且Ribbon 2并不与Ribbon 1相互兼容,所以Spring Cloud全家桶在Spring Cloud Commons项目中,添加了Spring cloud Loadbalancer作为新的负载均衡器,并且做了向前兼容,就算你的项目中继续用 Spring Cloud Netflix 套装(包括Ribbon,Eureka,Zuul,Hystrix等等)让你的项目中有这些依赖,你也可以通过简单的配置,把Ribbon替换成Spring Cloud LoadBalancer。
3、客户端负载均衡策略(SpringCloudRibbon)
- RandomRule(随机)
- RoundRobinRule(轮询)
- RetryRule(重试)
即失败后,在指定时间内重试。 - WeightedResponseTimeRule
即根据响应时间的长短给权重。响应时间越短,权重越大,也就是被选中的概率越大。 - BestAvailableRule
在过滤掉故障服务后,它会基于过去30分钟的统计结果选取当前并发量最小的服务节点作为目标地址。如果统计结果尚未生成,则采用轮询的方式选定节点。 - AvailabilityFilteringRule
每次AvailabilityFilteringRule(简称AFR)都会请求RobinRule挑选一个节点,然后对这个节点做以下两步检查:是否处于不可用,节点当前的active请求连接数超过阈值,超过了则表示节点目前太忙,不适合接客,就会让RobinRule重新选择一个服务节点。
如果被选中的server不幸挂掉了,那么AFR会自动重试(次数最多10次),还是没连上的话就会让RobinRule重新选择一个服务节点。 - ZoneAvoidanceRule
复合判断server所在区域的性能和server的可用性选择服务器
4、客户端负载均衡策略(SpringCloudLoadBalancer)
- RandomLoadBalancer(随机)
- RoundRobinLoadBalancer(默认轮询)
二、SpringCloudOpenFeign服务调用
1、OpenFeign服务调用的使用
之前使用RestTemplate比较麻烦,改用OpenFeign进行服务的调用会更得心应手。
-
在cloud父工程下,创建一个子模块cloud-consumer-openfeign-order80
即用openfeign服务调用的order模块去替换原先的RestTemplate服务调用的order模块。 -
在POM文件中添加依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>cloud</artifactId> <groupId>com.zzx</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>cloud-consumer-openfeign-order80</artifactId> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> </properties> <dependencies> <!-- 引入OpenFeign依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!-- 引入Eureka client依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- actuator监控信息完善 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> </dependencies> </project>即比原先多了一个OpenFeign依赖。
-
在resources目录下创建application.yml文件
server: port: 80 eureka: instance: # 注册的实例名 instance-id: cloud-consumer-openfeign-order80 client: service-url: # Eureka server的地址 #单机 #defaultZone: http://localhost:7001/eureka/ #集群 defaultZone: http://localhost:7001/eureka,http://localhost:7002/eureka spring: application: #设置应用名 name: cloud-order-consumer即修改了该消费者在Eureka的注册的实例名。
-
创建主启动类OrderFeignMain80
package com.zzx; import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.openfeign.EnableFeignClients; @Slf4j @SpringBootApplication //开启openfeign服务调用 @EnableFeignClients public class OrderFeignMain80 { public static void main(String[] args) { SpringApplication.run(OrderFeignMain80.class,args); log.info("***** OrderFeignMain80 启动成功 ******"); } }此时多了一个开启Openfeign服务调用的注解
-
在com.zzx包中创建一个service包,在该包下创建OpenFeign服务调用的接口PaymentFeignService
package com.zzx.service; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; /** * 支付远程调用OpenFeign接口 */ //根据服务生产者的名字调用 @FeignClient("CLOUD-PAYMENT-PROVIDER") public interface PaymentFeignService { @GetMapping("/payment/index") String index(); }即将服务的应用名给到OpenFeign,再由它去获取Eureka中对应的实例的uri,通过该uri再拼接上GetMapping中的url即可调用服务对应的方法。
-
在com.zzx包中创建一个controller包,在该包下创建OpenFeign服务调用的控制类OrderController
package com.zzx.controller; import com.zzx.service.PaymentFeignService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("order") public class OrderController { @Autowired private PaymentFeignService paymentFeignService; /** * openfeign远程服务调用 */ @RequestMapping("index") public String index(){ return paymentFeignService.index(); } }即可以通过浏览器访问并映射到该Controller对应地址的方法上,该Controller对应的方法就会调用该OpenFeign接口的对应方法,该接口方法就会通过OpenFeign调用Eureka对应实例的方法,最后返回结果到浏览器。
-
测试
1)在浏览器中打开:localhost:80/order/index
2、OpenFeign服务调用的日志增强
-
OpenFeign的日志级别:
1)NONE:默认的,不显示任何日志;
2)BASIC:仅记录请求方法、URL、响应状态码及执行时间;
3)HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息;
4)FULL:除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据。 -
在子模块openfeign的com.zzx包下,创建config包,在该包下创建类OpenFeignConfig
package com.zzx.config; import feign.Logger; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class OpenFeignConfig { /** * 日志级别定义 */ @Bean Logger.Level feignLoggerLevel(){ return Logger.Level.FULL; } }即将该类指定为配置类,创建一个方法返回Feign的日志级别对象,指定为Bean对象交给SpringIOC容器。
-
在application.yml文件中添加如下
logging: level: com.zzx.service: debugcom.zzx.service是openfeign接口所在的包名。
-
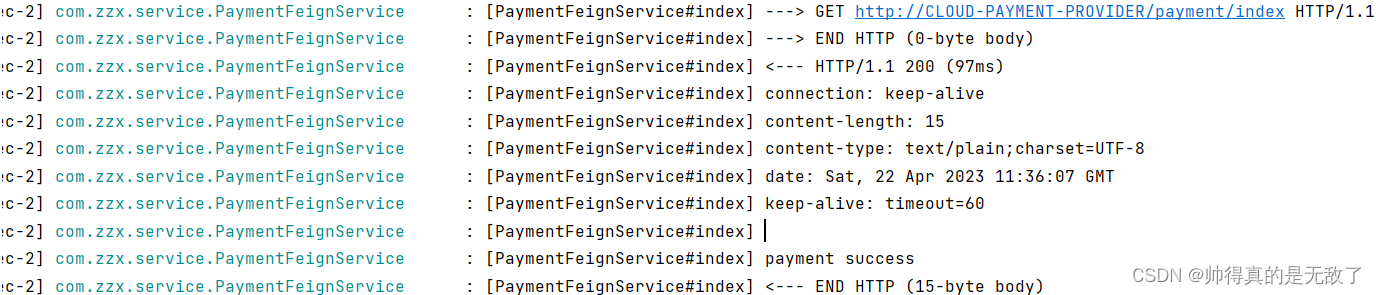
测试
1)在浏览器中访问:localhost:80/order/index
3、OpenFeign服务调用超时机制
-
服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一直等待下去。
在某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆积,势必会造成雪崩。
利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务访问,则自动断开连接。 -
在子模块openfeign中的yml文件中,添加如下超时时间的配置
spring: application: #设置应用名 name: cloud-order-consumer cloud: #默认超时时间 openfeign: client: config: default: #连接超时时间 connectTimeout: 2000 #读取超时时间 readTimeout: 2000 -
在子模块payment中的com.zzx.controller包下的PaymentController类中,添加如下代码
@GetMapping("timeout") public String timeout() throws InterruptedException { TimeUnit.SECONDS.sleep(5); return "payment timeout"; }即用来模拟超时的方法,让openfeign调用。
-
在子模块openfeign中的com.zzx.service包下的PaymentFeignService类中,添加如下代码
@GetMapping("/payment/timeout") String timeout(); -
在子模块openfeign中的com.zzx.controller包下的OrderController类中,添加如下代码
@GetMapping("/timeout") public String timeout() { return paymentFeignService.timeout(); }即调用提供者Payment的超时方法。
-
测试
1)重启服务提供者和消费者
2)浏览器访问:http://localhost:80/order/timeout
3)控制台报读取数据超时错误
三、SpringCloudResilience4J服务断路器1
1、服务雪崩的解决方案
- 服务雪崩:服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
造成雪崩的原因:
1)服务提供者不可用(硬件故障、程序bug、缓存击穿、用户大量请求)
2)重试加大流量(用户重试,代码逻辑重试)
3)服务调用者不可用(同步等待造成的资源耗尽) - 服务熔断
熔断就跟保险丝一样,当一个服务请求并发特别大,服务器已经招架不住了,调用错误率飙升,当错误率达到一定阈值后,就将这个服务熔断了。熔断之后,后续的请求就不会再请求服务器了,以减缓服务器的压力。 - 服务降级
1)服务降级 fallback
概念:服务器繁忙,请稍后重试,不让客户端等待并立即返回一个友好的提示。
2)使用场景:当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
3)出现服务降级的情况:
程序运行异常
超时
服务熔断触发服务降级
线程池/信号量打满也会导致服务降级 - 服务隔离
1)线程池隔离
将用户请求线程和服务执行线程分割开来,同时约定了每个服务最多可用线程数。
支持超时,可直接返回
支持熔断,当线程池到达maxSize后,再请求会触发fallback接口进行熔断
隔离原理:每个服务单独使用线程池
可以是异步,也可以是同步。看调用的方法
资源消耗大,大量线程的上下文切换,容易造成机器负载高
2)信号量隔离
它和线程池技术一样,控制了服务可以被同时访问的并发数量。
不支持超时,如果阻塞,只能通过调用协议(如:socket超时才能返回)
支持熔断,当信号量达到maxConcurrentRequests后。再请求会触发fallback
隔离原理:通过信号量的计数器
支持同步调用,不支持异步
资源消耗小,只是个计数器 - 服务限流
1)限流模式主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
2)限流的目的是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理。
3)流量控制
网关限流:防止大量请求进入系统,消息队列Mq实现流量消峰
用户交流限流:提交按钮限制、点击频率限制等
2、SpringCloudResilience4J服务断路器
- Resilience4J服务断路器
1)Hystrix,这个断路器是SpringCloud中最早支持的一种容错方案,现在这个断路器已经处于维护状态,已经不再更新了,Hystrix依赖了Archaius ,Archaius本身又依赖很多第三方包,例如 Guava、Apache Commons Configuration 等。
2)Resilience4J是一个轻量级的容错组件,其灵感来自于Hystrix,但主要为Java 8和函数式编程所设计,也就是我们的lambda表达式。轻量级体现在其只用 Vavr 库(前身是 Javaslang),没有任何外部依赖。 - Resilience4J的可用性功能:
1)resilience4j-circuitbreaker:熔断
2)resilience4j-ratelimiter:限流
3)resilience4j-bulkhead:隔离
4)resilience4j-retry:自动重试
5)resilience4j-cache:结果缓存
6)resilience4j-timelimiter:超时处理
在使用Resilience4j的过程中,不需要引入所有的依赖,只引入需要的依赖即可。 - 断路器CircuitBreaker通常存在三种状态(CLOSE、OPEN、HALF_OPEN),并通过一个时间或数量窗口来记录当前的请求成功率或慢速率,从而根据这些指标来作出正确的容错响应。
6种状态:
1)CLOSED: 关闭状态,代表正常情况下的状态,允许所有请求通过,能通过状态转换为OPEN
2)HALF_OPEN: 半开状态,即允许一部分请求通过,能通过状态转换为CLOSED和OPEN
3)OPEN: 熔断状态,即不允许请求通过,能通过状态转为为HALF_OPEN
4)DISABLED: 禁用状态,即允许所有请求通过,出现失败率达到给定的阈值也不会熔断,不会发生状态转换。
5)METRICS_ONLY: 和DISABLED状态一样,也允许所有请求通过不会发生熔断,但是会记录失败率等信息,不会发生状态转换。
6)FORCED_OPEN: 与DISABLED状态正好相反,启用CircuitBreaker,但是不允许任何请求通过,不会发生状态转换。 - 主要的3种状态
1)closed -> open : 关闭状态到熔断状态, 当失败的调用率(比如超时、异常等)默认50%,达到一定的阈值服务转为open状态,在open状态下,所有的请求都被拦截。
2)open-> half_open: 当经过一定的时间后,CircubitBreaker中默认为60s服务调用者允许一定的请求到达服务提供者。
3)half_open -> open: 当half_open状态的调用失败率超过给定的阈值,转为open状态
half_open -> closed: 失败率低于给定的阈值则默认转换为closed状态
3、Resilience4J的超时降级 (timelimiter)
-
在cloud父工程下创建一个子模块cloud-consumer-resilience4j-order80
-
在该子模块的POM文件中,添加如下依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>cloud</artifactId> <groupId>com.zzx</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>cloud-consumer-resilience4j-order80</artifactId> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> </properties> <dependencies> <!-- 引入Eureka 客户端依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <!-- 引入服务调用依赖 OpenFigen --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.22</version> </dependency> <!-- actuator监控信息完善 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!-- 引入断路器依赖resilience4j --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId> </dependency> </dependencies> </project>springcloud新版本不需要引入io.github.resilience4j的包。
-
在该子模块中的java目录中创建包com.zzx,并在该包下创建主启动类OrderResilience4JMain80
package com.zzx; import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.openfeign.EnableFeignClients; /** * 主启动类 */ @EnableFeignClients @SpringBootApplication @Slf4j public class OrderResilience4JMain80 { public static void main(String[] args) { SpringApplication.run(OrderResilience4JMain80.class,args); log.info("***** OrderResilience4JMain80服务 启动成功 *****"); } } -
在该子模块中的包com.zzx下,创建包service,并在该包下创建OpenFeign服务调用的接口PaymentOpenFeignService
package com.zzx.service; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; /** * 支付远程调用OpenFeign接口 */ //根据服务生产者的名字调用 @FeignClient("CLOUD-PAYMENT-PROVIDER") public interface PaymentOpenFeignService { @GetMapping("/payment/timeout") String timeout(); }调用支付服务提供者的测试超时方法。
-
在resources目录中创建application.yml文件,代码如下
server: port: 80 eureka: instance: # 注册的实例名 instance-id: cloud-consumer-resilience4j-order80 client: service-url: # Eureka server的地址 #单机 #defaultZone: http://localhost:7001/eureka/ #集群 defaultZone: http://localhost:7001/eureka,http://localhost:7002/eureka spring: application: #设置应用名 name: cloud-order-consumer #超时机制 resilience4j: timelimiter: instances: delay: # 设置超时时间2s timeout-duration: 2即配置resilience4j的超时机制。
-
在该子模块中的包com.zzx下,创建包controller,并在该包下创建控制层类OrderController
package com.zzx.controller; import com.zzx.service.PaymentOpenFeignService; import io.github.resilience4j.timelimiter.annotation.TimeLimiter; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.concurrent.CompletableFuture; import java.util.function.Supplier; /** * 订单控制层 */ @Slf4j @RestController @RequestMapping("order") public class OrderController { @Autowired private PaymentOpenFeignService paymentOpenFeignService; /** * 测试超时降级 * * @return */ @GetMapping("timeout") @TimeLimiter(name = "delay", fallbackMethod = "timeoutfallback") public CompletableFuture<String> timeout() { log.info("*********进入方法*********"); //异步操作 CompletableFuture<String> timeout = CompletableFuture.supplyAsync((Supplier<String>)()->paymentOpenFeignService.timeout()); log.info("*********离开方法*********"); return timeout; } /** * 超时服务降级方法 * @param e * @return */ public CompletableFuture<ResponseEntity> timeoutfallback(Exception e){ e.printStackTrace(); return CompletableFuture.completedFuture(ResponseEntity.ok("读取超时")); } }即使用OpenFeign调用支付服务提供者的测试超时方法。此时异步操作返回类型为
CompletableFuture<String>,使用注解@TimeLimiter来实现超时,注解中的name属性的值跟yml文件的resilience4j.timelimiter.instances的下一个属性名相同,然后在yml文件中该属性名的下一个属性,也就是在设置超时时间的属性中设置超时时间的值。
fallbackMethod属性,即设置超时的时候回调的方法名,该方法可以使服务降级等,即直接返回一个友好提示信息。
supplyAsync需要使用函数作为参数,此时应用lambda箭头函数()->的方式。 -
访问浏览器进行测试:
http://localhost/order/timeout

4、Resilience4J的重试机制(retry)
-
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加重试机制的方法retry
/** * 重试 * @return */ @GetMapping("retry") @Retry(name = "backendA") public CompletableFuture<String> retry() { log.info("*********进入方法*********"); //异步操作 CompletableFuture<String> timeout = CompletableFuture.supplyAsync((Supplier<String>)()->paymentOpenFeignService.timeout()); log.info("*********离开方法*********"); return timeout; }此时使用resilience4j的retry注解,name的属性值与yml文件中对应。
-
在yml文件中添加重试机制的配置
resilience4j: #超时机制 timelimiter: instances: delay: # 设置超时时间2s timeout-duration: 2 #重试机制 retry: instances: backendA: #最大重试次数 max-attempts: 3 #固定的重试间隔 wait-duration: 10s enable-exponential-backoff: true exponential-backoff-multiplier: 2每隔10s重试一次,最多重试3次。
-
测试重试机制
1)此时重启子模块cloud-consumer-resilience4j-order80,并且关闭子模块支付提供者payment8001服务。因为当连接不上服务提供者时,会进行重试。
2)浏览器访问:http://localhost/order/retry
5、Resilience4J的熔断降级(circuitbreaker)
-
JMETER的安装使用:
https://blog.csdn.net/weixin_49076273/article/details/126022329 -
在yml文件中配置熔断机制
#熔断机制 resilience4j.circuitbreaker: configs: default: # 熔断器打开的失败阈值30% failureRateThreshold: 30 # 默认滑动窗口大小,circuitbreaker使用基于计数和时间范围欢动窗口聚合统计失败率 slidingWindowSize: 10 # 计算比率的最小值,和滑动窗口大小去最小值,即当请求发生5次才会计算失败率 minimumNumberOfCalls: 5 # 滑动窗口类型,默认为基于计数的滑动窗口 slidingWindowType: TIME_BASED # 半开状态允许的请求数 permittedNumberOfCallsInHalfOpenState: 3 # 是否自动从打开到半开 automaticTransitionFromOpenToHalfOpenEnabled: true # 熔断器从打开到半开需要的时间 waitDurationInOpenState: 2s recordExceptions: - java.lang.Exception instances: backendA: baseConfig: default -
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加熔断机制的方法circuitbreaker
/** * 熔断降级 * @return */ @GetMapping("circuitbreaker") @CircuitBreaker(name = "backendA",fallbackMethod = "circuitbreakerfallback") public String circuitbreaker() { log.info("*********进入方法*********"); String index = paymentOpenFeignService.index(); log.info("*********离开方法*********"); return index; } public String circuitbreakerfallback(Exception e){ e.printStackTrace(); return "服务器繁忙,请稍后重试"; } -
用Jmeter进行测试:
在配置完参数后,点击运行即可。
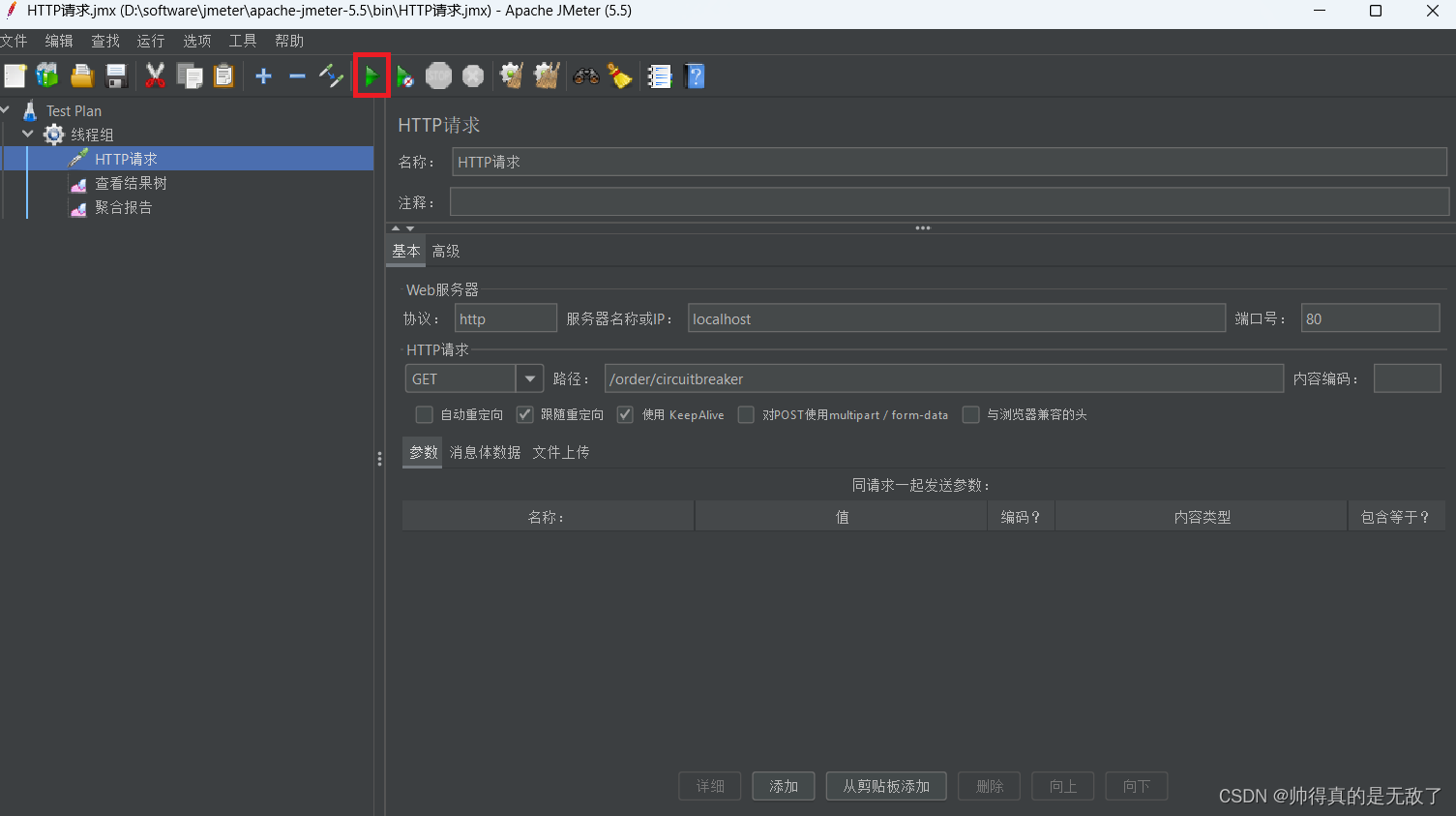
此时有10个http请求该地址,先把payment8001服务关闭,使错误率提高,让cirvuitbreaker熔断器的状态切换为打开,即不再接收http请求。过了2秒又切换为半开状态,此时半开最多只能接收3个请求,如果此时3个请求错误率还是很高,则又会切换到打开状态。等2秒又切换回半开,直到3个请求的成功率达到阈值,才会将状态切换为关闭。
然后这里使用了熔断降级,所以,每次当状态为打开时,后面2秒的http请求都会返回一个友好提示信息。直接半开或关闭状态才继续接收http请求去访问服务提供者。
6、Resilience4J的慢调用熔断降级(slowcircuitbreaker)
-
在yml文件中配置慢调用熔断降级
#慢调用熔断降级 backendB: # 熔断器打开的失败阈值 failureRateThreshold: 50 # 慢调用时间阈值 高于这个阈值的 slowCallDurationThreshold: 2s # 慢调用百分比阈值,断路器调用时间大于slow slowCallRateThreshold: 30 slidingWindowSize: 10 slidingWindowType: TIME_BASED minimumNumberOfCalls: 2 permittedNumberOfCallsInHalfOpenState: 2 waitDurationInOpenState: 2s eventConsumerBufferSize: 10与熔断降级有一些不同,慢调用熔断降级,顾名思义有慢调用的配置,也就是熔断器在http请求超时的配置。
该配置中,即http请求超过2s的比例高于等于30%或者失败的阈值高于50%,就开启熔断器。 -
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加慢调用熔断降级的方法slowcircuitbreaker
/** * 慢调用熔断降级 * @return */ @GetMapping("slowcircuitbreaker") @CircuitBreaker(name = "backendB",fallbackMethod = "slowcircuitbreakerfallback") public String slowcircuitbreaker() { log.info("*********进入方法*********"); String index = paymentOpenFeignService.timeout(); log.info("*********离开方法*********"); return index; } public String slowcircuitbreakerfallback(Exception e){ e.printStackTrace(); return "正在处理,请稍等"; } -
测试
1)使用Jmeter测试该url映射接口
2)JMeter在第一次发送http请求时,慢调用使熔断器处于关闭状态,2s后打开半开状态。在第二次发送http请求时,熔断器处于半开状态,这时候在访问两次http请求后,不会访问服务提供者payment8001,而是直接返回友好提示信息。
四、SpringCloudResilience4J服务断路器2
1、Resilience4J信号量服务隔离(bulkhead)
-
在消费者服务的yml文件中配置信号量隔离
resilience4j: #信号量隔离 bulkhead: instances: backendA: # 隔离允许并发线程执行的最大数量 maxConcurrentCalls: 5 # 当达到并发调用数量时,新的线程的阻塞时间 maxWaitDuration: 20ms -
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加信号量隔离的方法bulkhead
/** * 信号量隔离 * @return */ @GetMapping("bulkhead") @Bulkhead(name = "backendA",type = Bulkhead.Type.SEMAPHORE) public String bulkhead() { log.info("*********进入方法*********"); String index = paymentOpenFeignService.timeout(); log.info("*********离开方法*********"); return index; } -
测试
1)重启消费者服务后,配置访问的url接口进行测试
2、Resilience4J线程池服务隔离(bulkhead)
-
在消费者服务的yml文件中配置线程池隔离
#线程池隔离 esilience4j: thread-pool-bulkhead: instances: backendA: # 最大线程池大小 maxThreadPoolSize: 4 # 核心线程池大小 coreThreadPoolSize: 2 # 队列容量 #queueCapacity: 2 -
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加线程池隔离的方法future
/** * 线程池隔离 * @return */ @GetMapping("thread") @Bulkhead(name = "backendA",type = Bulkhead.Type.THREADPOOL) public CompletableFuture future() throws InterruptedException { log.info("*********进入方法*********"); TimeUnit.SECONDS.sleep(5); String index = paymentOpenFeignService.timeout(); log.info("*********离开方法*********"); return CompletableFuture.supplyAsync(()->"信号量"); }
3、Resilience4J的服务限流(ratelimiter)
-
在消费者服务的yml文件中配置服务限流
resilience4j: ratelimiter: instances: backendA: # 限流周期时长。 默认:500纳秒 limitRefreshPeriod: 5s # 周期内允许通过的请求数量。 默认:50 limitForPeriod: 2 -
在该子模块中的包com.zzx.controller下的控制层类OrderController中,添加服务限流的方法rateLimiter
/** * 限流 * @return */ @GetMapping("rate") @RateLimiter(name = "backendA") public String rateLimiter() throws InterruptedException { log.info("*********进入方法*********"); TimeUnit.SECONDS.sleep(5); //异步操作 String index = paymentOpenFeignService.index(); log.info("*********离开方法*********"); return index; } -
测试服务限流
1)使用JMeter测试

此时刚好5秒通过2次。
总结(SpringCloud 2022.0.2和SpringBoot 3.0.5)
- 1)客户端负载均衡,可以使用Eureka来获取微服务实例清单,缓存到本地;然后通过Loadbalancer根据负载均衡策略从服务实例清单列表中选择具体实例。
2)服务端负载均衡,发起服务间调用的时候,服务请求并不直接发向目标服务器,而是发给这个全局负载均衡器,它再根据配置的负载均衡策略将请求转发到目标服务。
3)客户端负载均衡,SpringCloudRibbon在Ribbon2已经停更,并且1和2不兼容,后面SpringCloud将SpringCloudLoadBalancer作为新的客户端负载均衡器。 - 1)SpringCloudOpenFeign的作用是服务调用,并且支持SpringMVC的标准注解。
OpenFeign服务调用的流程,即先创建一个OpenFeign的接口,并为其指定应用名,以及拼接上方法上对应的url;在Controller中自动装配后,再调用对应的接口方法即可。
2)OpenFeign服务调用的日志级别有4个,分别是NONE、BASIC、HEADERS、FULL。
设置OpenFeign的日志级别,需要定义一个配置类,在类中定义一个方法,返回OpenFeign的日志级别,将该方法上方添加@Bean注解,交给SpringIOC容器管理;并在yml文件中配置即可。
3)设置超时时间,首先需要在服务消费者的yml文件中配置OpenFeign的超时时间;然后通过消费者调用提供者,提供者超时则会报错。 - 避免造成雪崩的方案
1)服务熔断,调用错误率飙升,当错误率达到一定阈值后,就将这个服务熔断了。熔断之后,后续的请求就不会再请求服务器了,以减缓服务器的压力。
2)服务降级 fallback,不让客户端等待并立即返回一个友好的提示。触发服务降级的情况有程序运行异常、超时、服务熔断触发服务降级、线程池/信号量打满也会导致服务降级。
3)服务隔离,主要目的是为了解决服务与服务之间的影响。有信号量隔离和线程池隔离两种方式。线程池隔离支持的功能更多,但是资源消耗也更大。信号量隔离支持的功能比线程池隔离少,但是资源消耗也小。
4)服务限流,主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
服务熔断和服务隔离都属于出错后的容错处理机制,而限流模式则可以称为预防模式。 - 1)服务断路器Resilience4J,提供了6个避免服务雪崩的功能,熔断、限流、隔离、自动重试、结果缓存、超时处理。
Resilience4J只使用Vavr库,没有外部依赖。使用过程中只需要按需引入即可。
2)CircubitBreaker断路器有6种状态,分别是CLOSED、HALF_OPEN、OPEN、DISABLED、METRICS_ONLY、FORCED_OPEN;
主要的状态有3种,分别是CLOSED、HALF_OPEN、OPEN;closed可以转换为open,open转换为half_open,half_open转换为open或closed状态。
CircubitBreaker断路器最开始的状态为关闭状态。
3)Resilience4J的超时降级,Resilience4J需要使用注解@TimeLimiter,此时name需要跟yml文件的resilience4j.timelimiter.instances的下一个属性名相同,并在下一个属性中设置超时时间;它的fallbackMethod属性是超时的时候回调的方法名可以处理服务降级等操作,即直接返回一个友好提示信息。
异步操作时,返回类型为CompletableFuture<String>,supplyAsync需要使用函数作为参数,此时应用lambda箭头函数()->的方式去调用OpenFeign对应的方法即可。
并且还需要引入spring-cloud整合resilience4j的包即可。新版本的SpringCloud不需要引入io.github.resilience4j中的包;但是老版本的则需要引入该包。
4)Resilience4J的重试机制,即使用resilience4j中的retry注解,name属性值与yml文件对应的值绑定;并且配置retry重试机制的yml文件即可。
5)熔断机制降级,即需要在yml文件中配置熔断机制;在URL映射方法上使用@CircuitBreaker注解,以及降级的方法名。当http请求达到一定数量,并且错误率达到阈值时,则将熔断器的状态切换打开,过了设置的时间后,切换为半开,此时接收设置的http数量,如果错误率还是达到阈值,则再次切换为打开状态,直到成功率达到阈值,再切换为关闭状态。当处于打开状态时,http请求会得到一个友好提示,而不是访问payment8001服务。当处于半开或关闭的状态才会访问payment8001服务。
6)慢调用熔断降级,在调用服务提供者payment8001时,如果调用时间超时并且超时率达到阈值,则打开熔断器,过了指定的时间后,打开半开状态。半开状态设置只接收2次http请求,如果成功率达到阈值,则关闭熔断器;或者达到失败率则开启熔断器;否则一直处于半开状态。在打开状态时,所有http请求不访问服务提供者payment8001,而是直接返回友好提示信息;关闭状态时,所有http请求都直接访问服务提供者payment8001。 - Resilience4J在这里不知道是不是版本bug的原因,服务隔离bulkhead目前配置是不生效的,也就是说信号量和服务隔离配置不生效。
1)信号量服务隔离的基本原理就是一个计数器,它控制线程的并发数不超过一个指定数额,超过的话就进行隔离。使用@Bulkhead注解。
2)线程池服务隔离的基本原理就是通过指定核心线程池数和最大线程池数以及队列容量等来控制线程的并发数,从而实现服务的隔离。使用@Bulkhead注解。
3)服务限流,即指定服务的周期时间,以及在周期时间内通过的请求数量。使用@RateLimiter注解。