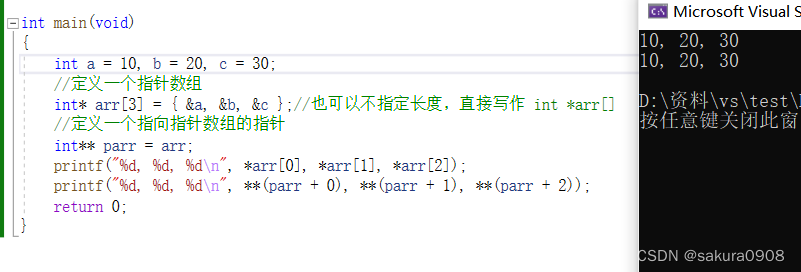
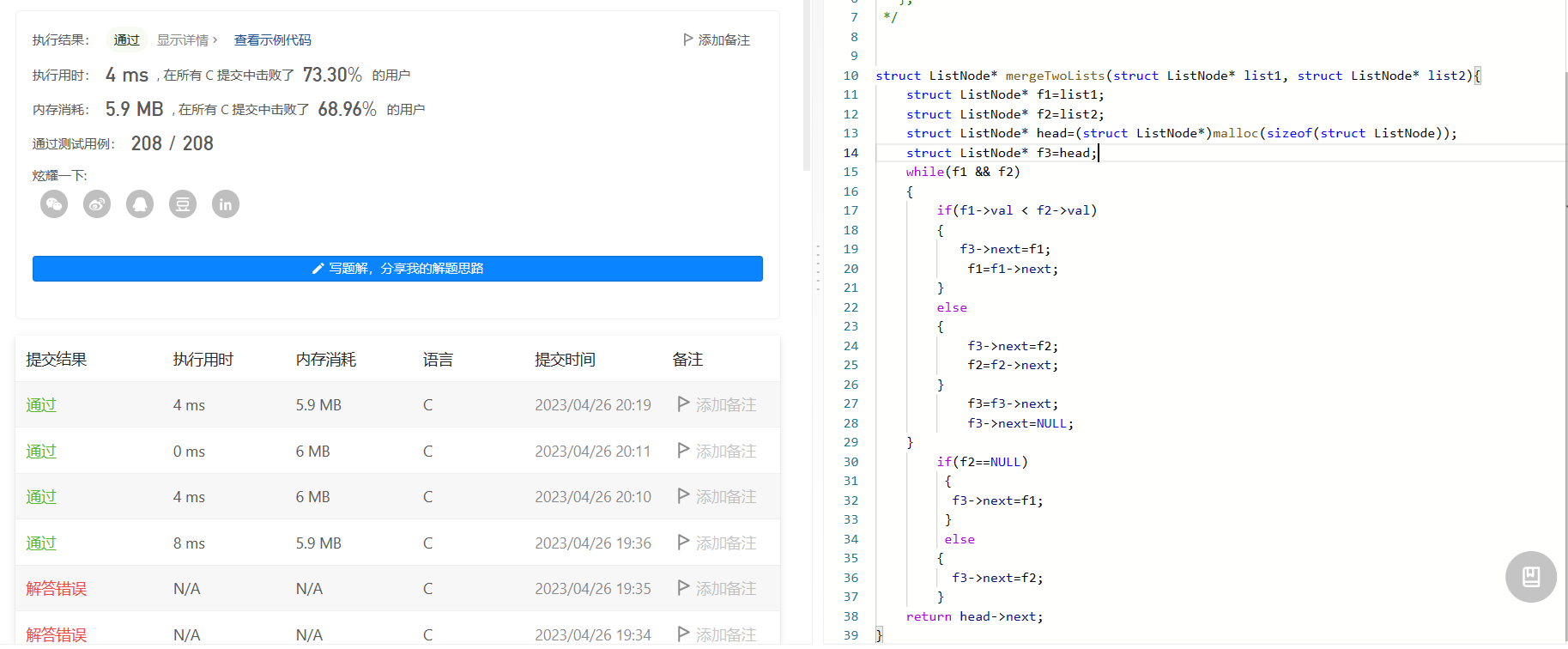
深度学习论文分享(二)Data-driven Feature Tracking for Event Cameras(CVPR2023)
- 前言
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Method
- 3.1. Feature Network
- 3.2. Frame Attention Module
- 3.3. Supervision
- 4. Experiments
- 5. Conclusion
- 6. Acknowledgment
- Supplementary补充部分
- 7. Future Work & Limitations
前言
论文原文:https://arxiv.org/abs/2211.12826
论文代码:https://github.com/uzh-rpg/deep_ev_tracker
Title:Data-driven Feature Tracking for Event Cameras
Authors:Nico Messikommer* Carter Fang∗ Mathias Gehrig Davide Scaramuzza
Robotics and Perception Group, University of Zurich, Switzerland
在此仅做翻译(经过个人修改,有基础的话应该不难理解),有时间会有详细精读笔记。
Abstract
由于其高时间分辨率、增强的运动模糊恢复能力和非常稀疏的输出,事件摄像机已被证明是低延迟和低带宽特征跟踪的理想选择,即使在具有挑战性的场景中也是如此。现有的事件摄像机特征跟踪方法要么是手工制作的,要么是从第一性原理推导出来的,但需要大量的参数调整,对噪声敏感,并且由于未建模的效果而不能推广泛化到不同的场景。为了解决这些不足,我们为事件摄像机引入了第一个数据驱动的特征跟踪器,它利用低延迟事件来跟踪在灰度帧中检测到的特征。我们通过一种新颖的帧注意力模块实现了稳健的性能,该模块跨特征轨迹共享信息。通过直接将零样本从合成数据传输到实际数据,我们的数据驱动跟踪器在相对特征年龄方面比现有方法高出120%,同时还实现了最低延迟。通过采用新颖的自我监督策略使我们的跟踪器适应真实数据,这一性能差距进一步扩大到130%。
第一性原理:原文是first principles,也不知道翻译成什么好,具体解释可以参考博客
https://www.zhihu.com/question/21459243
https://zhuanlan.zhihu.com/p/41263094
多媒体材料视频可在https://youtu.be/dtkXvNXcWRY上获取,代码可在https://github.com/uzh-rpg/deep_ev_tracker上获取
1. Introduction
尽管在现实世界中有许多成功的实现,但现有的特征跟踪器仍然主要受到标准相机硬件性能的限制。首先,标准相机受到带宽的制约,这明显限制了它们在快速移动下的性能:在低帧速率下,它们的带宽最小,但以增加延迟为代价;此外,低帧速率导致连续帧之间的外观变化较大,显著增加了跟踪特征的难度。在高帧速率下,以增加带宽开销和下游系统的功耗为代价来减少延迟。标准相机的另一个问题是运动模糊,这在高速低光场景中很突出,见图1。随着当前AR/VR设备的商品化,这些问题变得越来越突出。
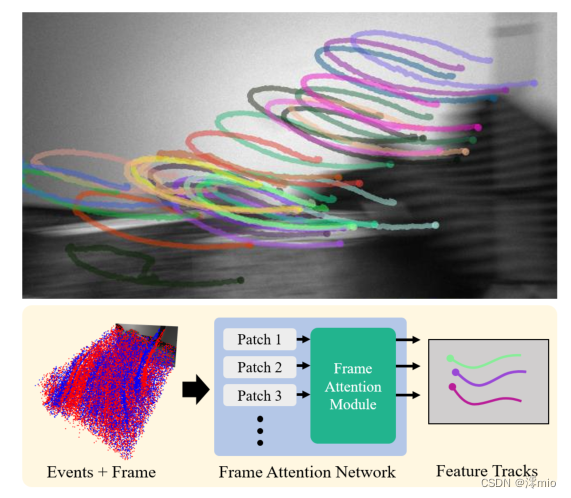
图1:我们的方法利用事件的高时间分辨率,在标准帧遭受运动模糊的高速运动中提供稳定的特征轨迹。为了实现这一点,我们提出了一种新的帧注意力模块,该模块将跨特征轨迹的信息进行组合。
事件摄像机已被证明是标准摄像机的理想补充,以解决带宽延迟权衡[16,17]。事件摄像机是受生物启发的视觉传感器,每当单个像素的亮度变化超过预定义阈值时,它就会异步触发信息。由于这种独特的工作原理,事件摄像机输出的稀疏事件流具有微秒量级的时间分辨率,并具有高动态范围和低功耗的特点。由于事件主要是根据边缘触发的,因此事件摄像机的带宽最小。这使它们成为克服标准相机缺点的理想选择。
在高速和高动态范围场景中,用于事件摄像机的现有功能跟踪器在延迟和跟踪鲁棒性方面显示出前所未有的结果[4,17]。尽管如此,到目前为止,基于事件的跟踪器是基于经典模型假设开发的,这通常会导致在存在噪声的情况下跟踪性能较差。它们要么依赖于运动参数的迭代优化[17,26,49],要么对特征的可能平移采用简单分类[4],因此,由于未建模的影响,不会推广到不同的场景。此外,它们通常具有复杂的模型参数,需要大量手动调整以适应不同的事件摄像机和新场景。
为了解决这些不足,我们提出了第一个用于事件摄像机的数据驱动特征跟踪器,该跟踪器利用事件摄像机的高时间分辨率与标准帧相结合,以最大限度地提高跟踪性能。使用神经网络,我们的方法通过在随后的事件补丁中定位灰度图像中的模板补丁来跟踪特征。网络体系结构的特点是分配有一个相关卷,并使用递归层来实现长期一致性。为了提高跟踪性能,我们引入了一种新的帧注意力模块,该模块在一幅图像的特征轨迹之间共享信息。我们首先在合成光流数据集上进行训练,然后使用我们新颖的基于使用相机姿态的3D点三角测量的自我监督方案对其进行微调。
在事件摄像机数据集基准[33]和最近发布的EDS数据集[22]上,我们的跟踪器分别比最先进的基线高出5.5%和130.2%。这种性能是在不需要大量手动调整参数的情况下实现的。此外,在不优化部署代码的情况下,我们的方法实现了比现有方法更快的推理。最后,我们展示了我们的方法与成熟的基于帧的跟踪器KLT[30]的组合如何在高速场景中发挥两全其美的作用。这种标准相机和事件相机的组合为基于跟踪质量的谨慎触发帧的概念铺平了道路,这是未来应用程序的关键工具,在这些应用程序中,运行时间和功耗至关重要。
2. Related Work
基于帧的特征跟踪:虽然以前没有利用深度学习来跟踪事件中的特征,但最近提出了使用标准帧进行特征跟踪的数据驱动方法。其中包括PIP[20],它估计整个图像序列的查询特征位置的轨迹,因此甚至可以通过利用前后的轨迹通过遮挡来跟踪特征。DPVO[40]不是处理整个序列,而是拍摄一系列图像,并实时估计场景深度和相机姿态。它通过从帧的特征图中随机采样补丁,并将其添加到二分帧图中来实现这一点,该二分帧图可通过将不同相机姿态下观察到的补丁的特征描述符进行关联来迭代优化。特征跟踪的相关研究领域是光流估计,即两帧之间的密集像素对应性估计。存在许多光流方法[13],其中基于相关性的网络[24,39]是最先进的。然而,尽管最近取得了进步,但基于帧的特征跟踪器仍然受到标准相机的硬件限制。为了解决这一缺点,我们提出了一种自监督跟踪器,该跟踪器可以解锁事件摄像机的鲁棒性特征,用于特征跟踪,并通过这样做,优于最先进的跟踪方法。
姿势监督:利用相机姿势之前曾被探索用于训练特征检测和匹配网络。Wang等人[44]使用姿态数据来监督用于逐像素对应估计的网络,其中两帧之间的核约束用于惩罚不正确的预测。最近,一种名为Patch2Pix[47]的对应细化网络通过使用桑普森距离而不是欧几里得距离来扩展对极约束监督。我们的自我监督策略不是只考虑两个相机姿势,而是使用DLT[1]为多帧中的每个预测轨迹计算一个3D点,这使我们的监督信号对误差更具鲁棒性。此外,我们通过计算重投影点和预测点之间的2D距离来监督我们的网络,而不存在到核线的距离的模糊性。
基于事件的特征跟踪:近年来,多项工作探索了基于事件的特性跟踪,以提高在具有挑战性的条件下的鲁棒性,例如时间步长之间像素位移较大的快速运动场景和具有非常亮和暗区域的HDR场景[17]。早期的工作[26,34,49]将特征作为事件的点集进行跟踪,并使用ICP[5]来估计时间步长之间的运动,这也可以与基于帧的跟踪器相结合以提高性能[12]。EKLT[17]不是点集,而是估计模板和亮度增量图像的目标块之间的参数变换以及特征的速度。其他基于事件的跟踪器在空间和时间上沿着Bézier曲线[37]或B样条曲线[10]对齐事件,以获得特征轨迹。
为了利用事件流固有的异步性,还提出了逐事件跟踪器[2,11]。其中之一是HASTE[4],它将可能的变换空间减少到固定数量的旋转和平移。在HASTE中,每个新事件都会导致假设的置信度更新,如果超过置信度阈值,则会导致状态转换。另一项名为eCDT[23]的工作首先将特征表示为事件集群,然后将传入事件合并到现有事件中,从而产生更新的质心,从而更新特征位置。在与特征跟踪类似的方向上,提出了几个基于事件的特征检测器[8,31],其中一些检测器基于图像中检测的接近度来执行特征跟踪[3,9]。除了基于事件的特征跟踪和检测外,多项工作还使用事件相机解决了对象跟踪问题[7,14,27,35,45,46]。
使用事件摄像机进行光流估计的任务也越来越受欢迎。Zhu等人[49]使用ICP和基于期望最大化的目标函数来估计来自事件的特征的光流,以求解仿射变换的参数。最近,提出了一种自适应块匹配算法[29]来估计光流。最后,最近基于事件的光流估计的数据驱动方法[18,48]利用了深度光流估计方面的进展。受这些进步的启发,我们的跟踪网络利用相关层来更新特征的位置。
3. Method
特征跟踪算法的目标是在随后的时间步长中跟踪参考帧中的给定点。他们通常通过提取参考系中特征位置周围的外观信息来实现这一点,然后在后续的参考系中进行匹配和定位。根据该流水线,我们在时间步长 t 0 t_0 t0提取给定特征位置的灰度帧中的图像补丁 P 0 P_0 P0,并使用异步事件流跟踪该特征。时间步 t j − 1 t_{j−1} tj−1和 t j t_j tj之间的事件流 E j = E_j= Ej= { e i e_i ei } i = 1 n j _{i=1}^{n_j} i=1nj由事件 e i e_i ei组成,每个事件 e i e_i ei编码像素坐标 x i x_i xi、具有微秒级分辨率 τ i τ_i τi的时间戳和亮度变化的极性 p i p_i pi∈{−1,1}。有关事件摄像机工作原理的更多信息,请参阅[15]。
给定参考补丁 P 0 P_0 P0,我们的网络使用在前一时间步长 t j − 1 t_{j−1} tj−1的特征位置的局部邻域中的相应事件流 E j E_j Ej来预测 t j − 1 t_{j−1} tj−1和 t j t_j tj期间的相对特征位移 ∆ f j ^ ∆\hat{f_j} ∆fj^。本地窗口内的事件被转换为密集事件表示 P j P_j Pj,特别是SBT[43]的最大时间戳版本,其中每个像素被分配最近事件的时间戳。一旦我们的网络已经将参考补丁 P 0 P_0 P0定位在当前事件补丁 P j P_j Pj内,则特征轨迹被更新,并且在新预测的特征位置处提取新的事件补丁 P j + 1 P_{j+1} Pj+1,同时保持参考补丁 P 0 P_0 P0。然后可以迭代地重复该过程,同时累积相对位移以构建一个连续的特征轨迹。我们的方法和新的框架注意力模块的概述如图2所示。
在第3.1节中,我们解释了特征网络如何独立处理每个特征轨迹。由此产生的输出作为我们的帧注意力模块的输入,该模块将来自一幅图像中所有特征轨迹的信息组合在一起,见第3.2节。最后,我们在第3.3节中介绍了我们对具有地面实况的数据的监督方案和基于相机姿态的自我监督策略。关于每个网络的具体架构细节,我们参考补充部分。
3.1. Feature Network
为了将模板补丁 P 0 P_0 P0定位在当前事件补丁 P j P_j Pj内,特征网络首先使用基于特征金字塔网络的单独编码器对两个补丁进行编码[28]。得到的输出是两个补丁的每像素特征图,这两个补丁包含上下文信息,同时保留空间信息。为了显式地计算事件补丁和模板补丁中每个像素之间的相似性度量,我们基于模板补丁编码器的瓶颈特征向量 R 0 R_0 R0和事件补丁的特征图构建了相关图 C j C_j Cj,如图2所示。然后将两个特征图与相关性图 C j C_j Cj一起作为输入提供给第二特征编码器,以便细化相关性图。该特征编码器由标准卷积和一个具有时间单元状态 F j F_j Fj的ConvLSTM块[38]组成。时间信息对于预测随时间变化的一致特征轨迹至关重要。此外,它能够集成由事件提供的运动信息。特征网络的输出是空间维度为1×1的单个特征向量。到目前为止,每个特征都是独立处理的。
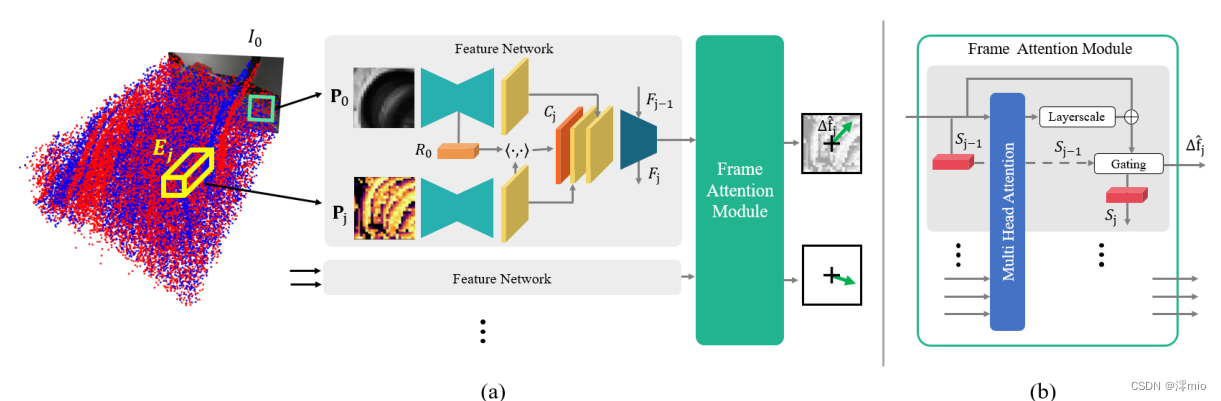
图2:如(a)所示,我们的事件跟踪器将灰度图像
I
0
I_0
I0中的参考补丁
P
0
P_0
P0和由时间步长
t
j
t_j
tj处的事件流
E
j
E_j
Ej构建的事件补丁
P
j
P_j
Pj作为输入,并预测相对特征位移
∆
f
j
^
∆\hat{f_j}
∆fj^。每个特征由特征网络单独处理,该特征网络使用状态为
F
F
F的ConvLSTM层来基于模板特征向量
R
0
R_0
R0和事件补丁的逐像素特征图来处理相关性图
C
j
C_j
Cj。为了在不同的特征轨迹之间共享信息,我们新的帧注意力模块(b)使用自注意力和时间状态
S
S
S融合图像中所有轨迹的处理后的特征向量,用于计算最终位移
∆
f
j
^
∆\hat{f_j}
∆fj^。
3.2. Frame Attention Module
为了在同一图像中的特征之间共享信息,我们引入了一种新的帧注意力模块,如图2所示。由于刚体上的点在图像平面中表现出相关的运动,因此在图像上的特征之间共享信息有很大的好处。为了实现这一点,我们的帧注意力模块将当前时间步长
t
j
t_j
tj的所有补丁的特征向量作为输入,并基于所有特征向量的自注意力加权融合来计算每个补丁的最终位移。具体来说,我们在时间上保持每个特征的状态
S
S
S,以便在注意力融合中利用先前时间步长的位移预测。时间信息应该有助于过去具有相似运动的特征的信息共享。通过这种方式,可以在具有挑战性的情况下通过自适应地将易受攻击的特征轨迹调节在相似的特征轨迹上来维持易受攻击特征轨迹。每个输入特征向量首先使用具有Leaky ReLU激活(MLP)的两个线性层与当前状态
S
j
−
1
S_{j−1}
Sj−1单独融合。然后,图像中所有得到的融合特征都被用作多头注意力层(MHA)[42]的key、query和value对,该层对图像中的每个特征执行自注意力。为了便于训练,我们在每个特征的多头注意力周围引入了跳跃连接,该跳跃连接在训练过程中由层尺度层[41](LS)自适应加权。然后在简单选通层中使用所得到的特征向量,以基于先前状态
S
j
−
1
S_{j−1}
Sj−1(GL)计算更新状态Sj,参见等式(3)。
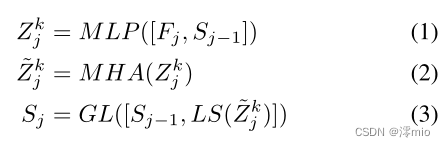
最后,更新后的状态
S
j
S_j
Sj由一个线性层处理,以预测最终位移
∆
f
j
^
∆\hat{f_j}
∆fj^。
3.3. Supervision
一般来说,跟踪器、提取器甚至流网络的监督仍然是一个开放的研究领域,因为包含像素对应关系作为基本事实的数据集很少。更糟糕的是,包含精确像素对应关系的基于事件的数据集更少。为了克服这一限制,我们在第一步中对来自Multiflow数据集[19]的合成数据进行训练,该数据集包含帧、合成生成的事件和GT像素流。然而,由于没有对噪声进行建模,合成事件与真实事件摄像机记录的事件有很大不同。因此,在第二步中,我们使用新的姿态监督损失来微调我们的网络,以缩小合成事件和真实事件之间的差距。
合成监督:合成数据的优点是它提供了GT特征跟踪。因此,基于L1距离的损失可以直接应用于预测相对位移和地面实况相对位移之间的每个预测步骤
j
j
j,见图3。预测的特征轨迹可能偏离模板补丁之外,使得下一个特征位置不在当前搜索中。因此,如果预测位移和地面实况位移之间的差
∣
∣
∆
f
j
^
−
∆
f
j
∣
∣
1
||∆\hat{fj}−∆f_j||_1
∣∣∆fj^−∆fj∣∣1超过补丁半径
r
r
r,我们不会将L1距离与最终损失相加,以避免在监督中引入噪声。我们的截断损失
L
r
p
L_{rp}
Lrp公式如下。
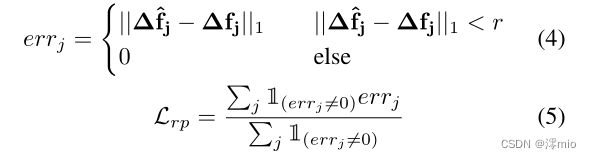
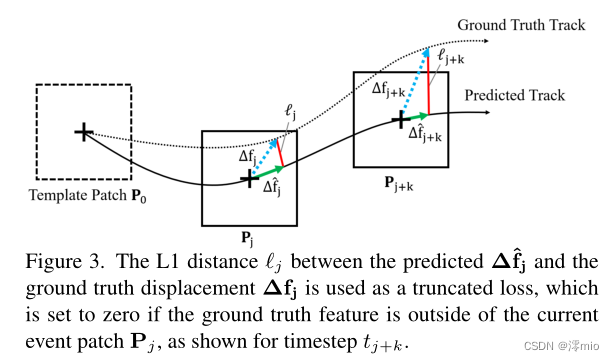
图3:L1距离
ℓ
J
ℓ_J
ℓJ如时间步长tj+k所示,如果GT特征在当前事件补丁
P
j
P_j
Pj之外,则预测的
∆
f
^
j
∆\hat{f}_j
∆f^j和GT位移
∆
f
j
∆f_j
∆fj之间的
ℓ
J
ℓ_J
ℓJ被用作截断损失,该截断损失被设置为零。
为了减少合成数据和真实数据之间的差距,我们在训练过程中应用了on-the-fly增强,这显著增加了运动分布。为了教导网络几何鲁棒表示,仿射变换 W W W被应用于当前事件补丁 P j P_j Pj,以在每个预测步骤获得增强补丁 P j a u g P^{aug}_j Pjaug,如等式(6)所示。在训练期间,从每个预测步骤的均匀分布中随机采样旋转、平移和尺度 θ = ( θ r , θ t , θ s ) θ=(θ_r,θ_t,θ_s) θ=(θr,θt,θs)的增强参数。然后,我们的跟踪器 T T T在给定增强补丁 P j a u g P^{aug}_j Pjaug原始模板补丁 P 0 P_0 P0的情况下预测相对位移 ∆ f ^ j − 1 a u g ∆\hat{f}^{aug}_{j−1} ∆f^j−1aug。然后计算预测位移 ∆ f ^ j − 1 a u g ∆\hat{f}^{aug}_{j−1} ∆f^j−1aug和通过应用相同的仿射变换W获得的增强地面实况 ∆ f j − 1 a u g ∆{f}^{aug}_{j−1} ∆fj−1aug之间的损失。
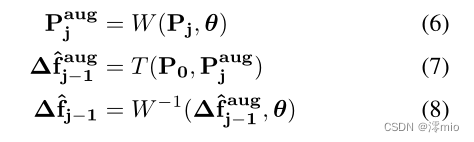
姿势监督:为了使网络适应真实事件,我们引入了一种新的姿势监督损失,该损失仅基于校准相机的真实姿势。使用来自运动算法的结构,例如COLMAP[36],或者通过外部运动捕捉系统,可以容易地获得稀疏时间步长tj的地面实况姿态。由于我们的监督策略依赖于基于姿势的3D点的三角测量,因此它只能应用于静态场景。
在微调的第一步中,我们的网络预测一个序列的多个特征轨迹。对于每个预测的轨迹
i
i
i,我们使用直接线性变换[1]计算相应的3D点
X
i
X_i
Xi。具体而言,对于每个特征位置
x
j
x_j
xj,我们可以使用相机姿态(表示为旋转矩阵
R
t
j
R_{t_j}
Rtj和平移向量
T
t
j
T_{t_j}
Ttj,在时间步长
t
j
t_j
tj)和校准矩阵
K
K
K来编写假设针孔相机模型的投影方程,参见等式(9)。得到的投影矩阵可以表示为矩阵
M
j
M_j
Mj,该矩阵
M
j
M_j
Mj由具有k∈{1,2,3}的列向量
m
j
k
T
m^{k^T}_j
mjkT组成。
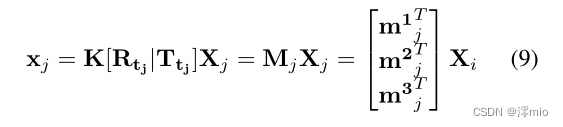
使用直接线性变换,我们可以将投影方程重新表述为方程中的齐次线性系统。(10)。通过使用SVD,我们获得了3D点Xj,这使方程的最小二乘误差最小化。(10)
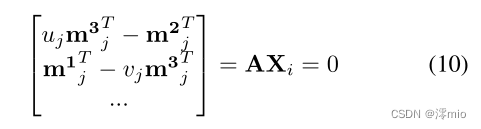
一旦计算出
X
i
X_i
Xi的3D位置,我们就可以使用透视投影公式(9)找到每个时间步长
t
j
t_j
tj的重投影像素点
x
^
j
\hat{x}_j
x^j。然后,基于在时间步长
t
j
t_j
tj处每个可用相机姿势的预测特征
x
^
j
\hat{x}_j
x^j和重投影特征KaTeX parse error: Undefined control sequence: \x at position 1: \̲x̲_j来构建最终姿势监督损失,如图4所示。与方程的监督设置一样。(5),如果重新投影的特征在事件补丁之外,我们使用截断的损失,该损失排除了损失贡献。
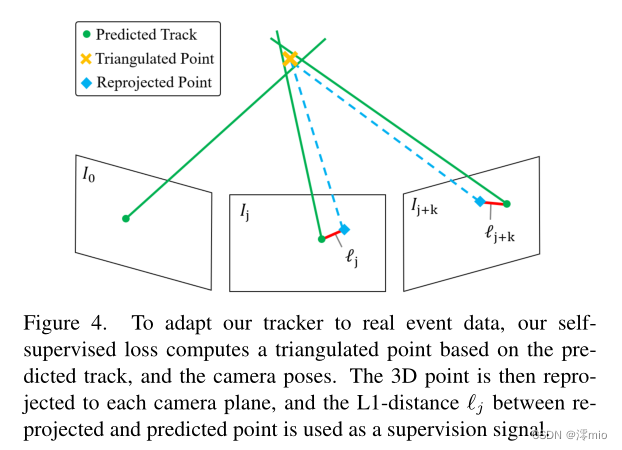
图4:为了使我们的跟踪器适应真实的事件数据,我们的自我监督损失根据预测的轨迹和相机姿势计算一个三角点。然后将3D点重新投影到每个相机平面,并且L1距离ℓj被用作监督信号。
4. Experiments
数据集:我们在常用的事件摄像机数据集[33](EC)上比较了我们提出的数据驱动跟踪器,该数据集包括APS帧(24 Hz)和使用DA VIS240C摄像机[6]记录的分辨率为240×180的事件。此外,该数据集从外部运动捕捉系统以200Hz的速率提供地面实况摄像机姿态。此外,为了评估新传感器设置的跟踪性能,我们在最新发布的事件辅助直接稀疏Odometry数据集[22](EDS)上测试了我们的方法。与EC相比,EDS数据集包含使用分束器设置捕获的更高分辨率的帧和事件(640×480像素)。与EC数据集类似,它包括来自外部运动捕捉系统的150 Hz速率的地面实况姿态。这两个数据集中的大多数场景都是静态的,因为EDS和EC的主要目的是评估相机姿态估计。关于具体的微调和测试顺序选择,我们参考补充。
5. Conclusion
我们为事件摄像机提供了第一个数据驱动的特征跟踪器,它利用低延迟事件来跟踪灰度帧中检测到的特征。通过我们新颖的帧注意力模块,它融合了特征轨迹之间的信息,我们的跟踪器在两个数据集上优于现有技术,同时在推理时间方面更快。此外,我们提出的方法不需要密集的手动参数调整,并且可以通过我们的自我监督策略适用于新的事件摄像机。最后,我们可以将基于事件的跟踪器与KLT跟踪器相结合,以预测具有挑战性的场景中的稳定轨迹。这种标准相机和事件相机的组合为基于跟踪质量的谨慎触发帧的概念铺平了道路,这是未来应用程序的关键工具,在这些应用程序中,运行时间和功耗至关重要。
6. Acknowledgment
作者要感谢Javier Hidalgo Carrió对EDS数据集的支持。这项工作得到了瑞士国家科学基金会通过国家研究能力中心(NCCR)机器人技术(拨款编号51NF40 185543)和欧洲研究委员会(ERC)根据第864042号拨款协议(AGILEFLIGHT)的支持。
Supplementary补充部分
7. Future Work & Limitations
由于EC和EDS数据集是为了对姿态估计算法进行基准测试而记录的,因此它们只包含静态场景。因此,我们没有评估我们的方法,尤其是我们的帧注意力模块在具有动态对象的场景中的表现。尽管如此,我们相信我们的帧注意力模块对于其他使用事件或标准相机的跟踪器来说是有用的。最后,我们的方法依赖于灰度图像中的特征检测质量,这在具有挑战性的场景中可能会受到影响。然而,我们的自我监督策略也为微调事件摄像机的特征检测器提供了可能性,以提高特征检测的稳健性。