目录
- 程序地址空间空间布局图
- 引入物理地址与虚拟地址的概念
- 虚拟地址空间
- 虚拟地址与物理地址是如何对应的?
- ※父子进程独立性的理解(重点)
- fork两个返回值的原理
- 地址空间为什么要存在?
- 补充理解
程序地址空间空间布局图
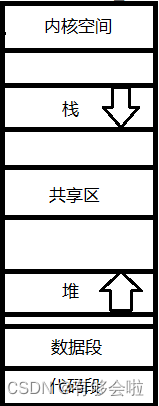
(这些划分都是在虚拟地址空间的划分)
引入物理地址与虚拟地址的概念
首先编写一个测试程序进行测试:
#include <stdio.h>
#include <assert.h>
#include <unistd.h>
int g_value = 100;
int main()
{
pid_t id = fork();
assert(id >= 0);
if(id == 0)
{
//子进程
while(1)
{
printf("这是子进程,ID=%d, 父进程ID=%d, g_value = %d, &g_value = %p\n", getpid(), getppid(), g_value, &g_value);
sleep(1);
g_value++;
}
}
else
{
//父进程
while(1)
{
printf("这是父进程,ID=%d, 父进程ID=%d, g_value = %d, &g_value = %p\n", getpid(), getppid(), g_value, &g_value);
sleep(1);
}
}
}
运行结果:
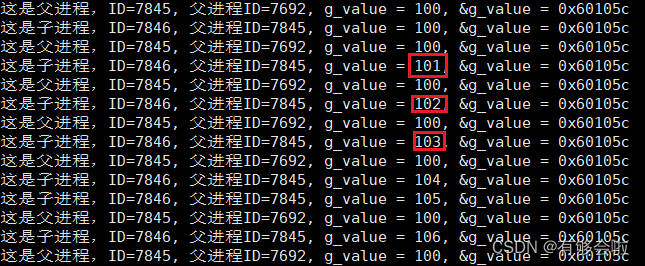
问题解析:
为什么子进程对变量进行修改的时候父进程中的变量不会变化?
—— 进程具有独立性! g_value是一个全局变量,当子进程对全局数据进行修改的时候,不会影响父进程。
进程 == 内核数据结构 + 代码和数据,进程具有独立性,就说明内核数据结构、代码和数据都要各自保持独立性。
那么数据如何保持独立性呢?
——写时拷贝!
同时发现父子进程g_value的地址都相同,但是打印时出现的值是不相同的,按理说应该存在两个不同的地址,为什么二者的地址相同呢?
——假设这个地址是“物理地址”,那就不可能读取同一个地址取到不同的值。所以这个地址不可能是物理地址!即我们平时在语言层面所使用的地址,就不是物理地址。
那么这个地址是什么地址?
——虚拟地址/线性地址
虚拟地址空间
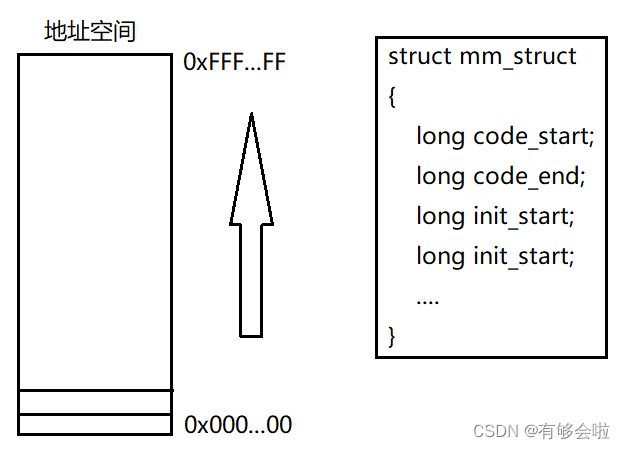
进程地址空间也需要被OS所管理,其本质就是一个内核数据结构struct mm_struct{},通过它来描述地址空间。
当我们创建一个进程时,会在内核定义一个task_struct对象,定义一个mm_struct对象(也在内核中),task_struct中存在一个指针指向进程对应的地址空间。
而这些虚拟的地址最终都要存放在物理内存当中。
那么我们要如何理解mm_struct中所划分的堆区、栈区、代码段…呢?
——地址空间本质是一个线性结构,其宽度为1字节(一个int形4字节占用4个地址),其编址为0x000…0~0xFFF…F,每个地址对应一个字节,地址是连续的。
所以在mm_struct中通过各自的start与end来划分各个区域。这些划分出来区域也就是虚拟地址。
所以堆区的扩大和栈区向下调整本质就是改变了对应的start与end对应的数据。(本质比较复杂,理解原理)
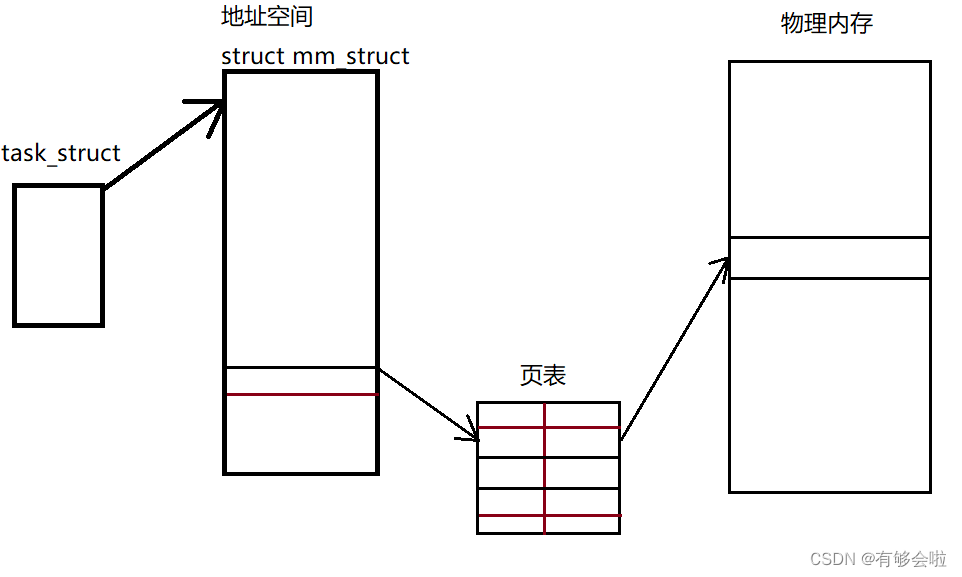
虚拟地址与物理地址是如何对应的?
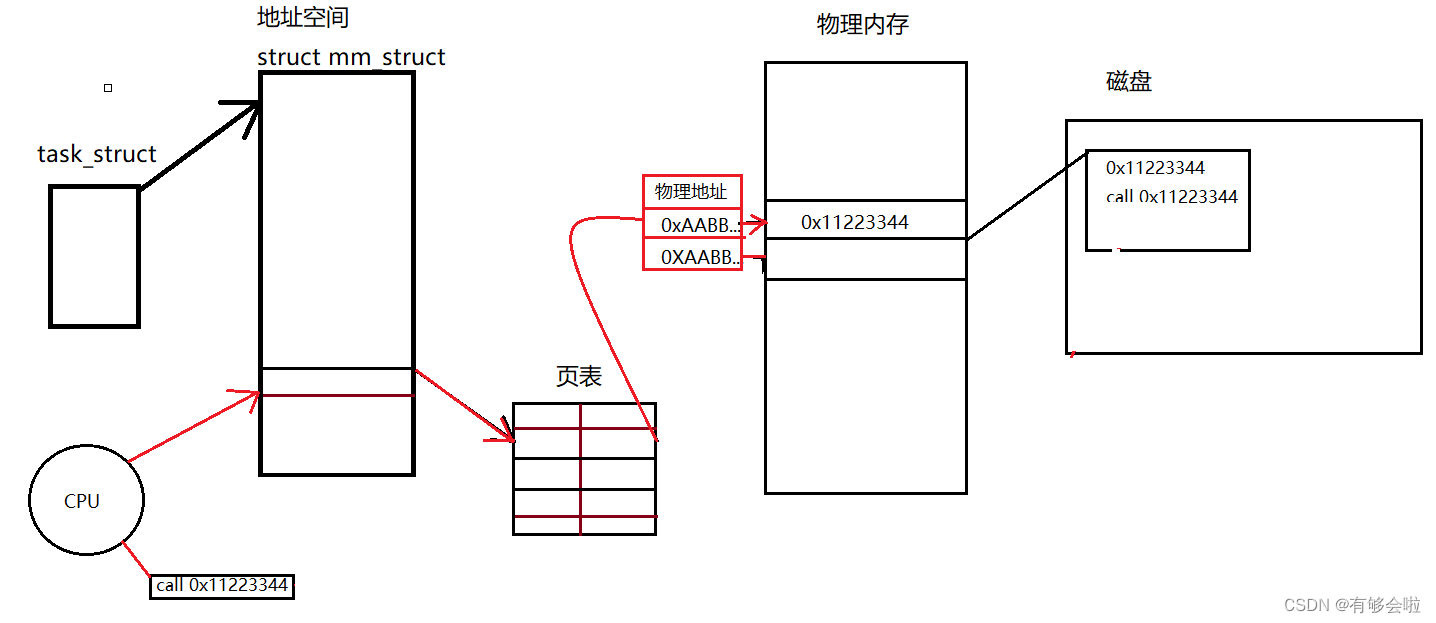
我们平时直接使用的地址都是虚拟地址,那么虚拟地址是如何找到物理地址中存储的数据的呢?
——通过页表,页表可以将虚拟地址转换为物理地址。可以将页表理解为KV映射,左侧是虚拟地址,右侧是物理地址,当我们使用虚拟地址时,会通过CPU将虚拟地址转换成物理地址,进而读取物理地址中的数据(在CPU内部有一个集成硬件MMU内存管理单元)。
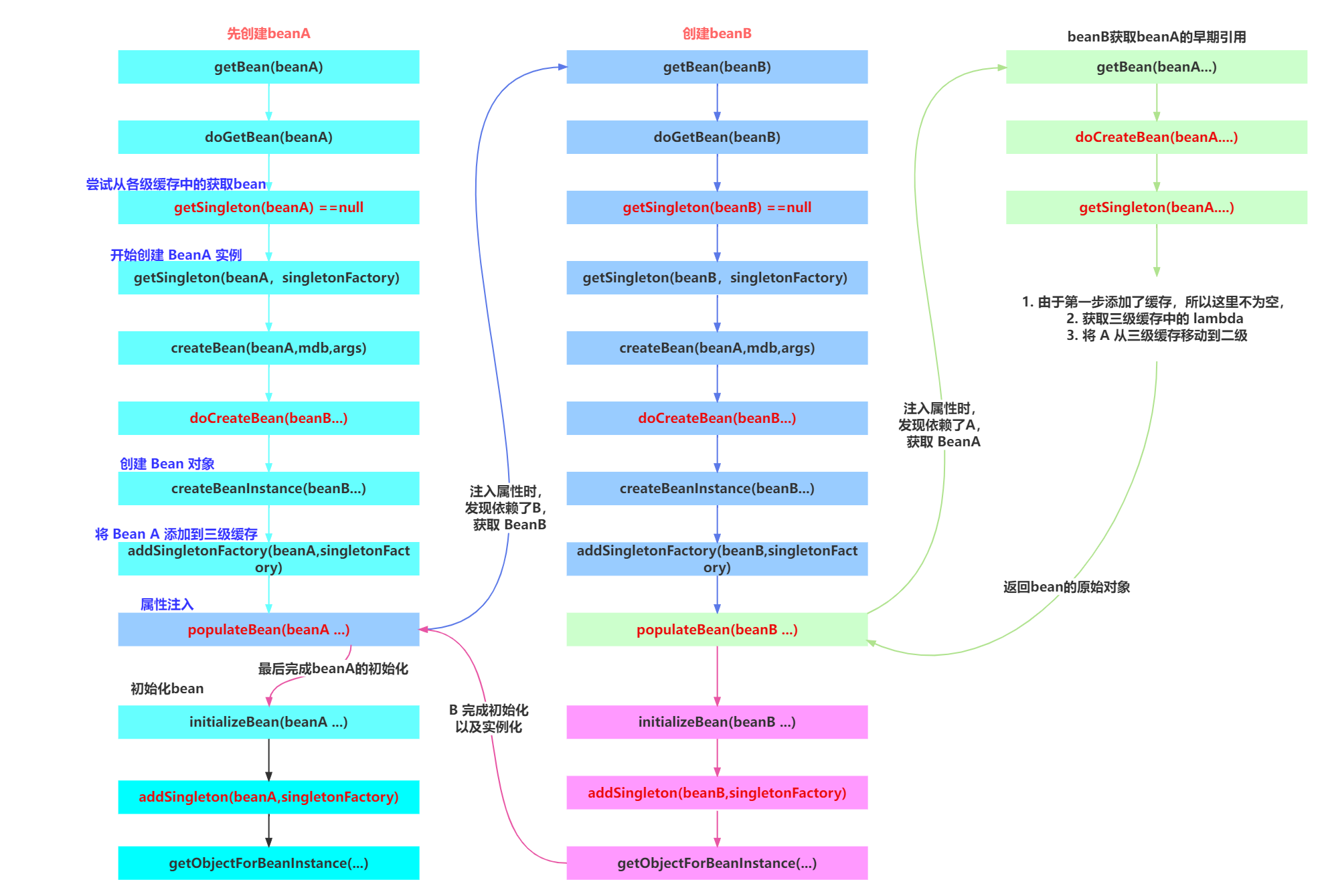
※父子进程独立性的理解(重点)
回到开头所写的测试代码问题,为什么在子进程中修改全局数据不会影响父进程中读取的数据?二者的地址明明是一样的。(虚拟地址)
解析:
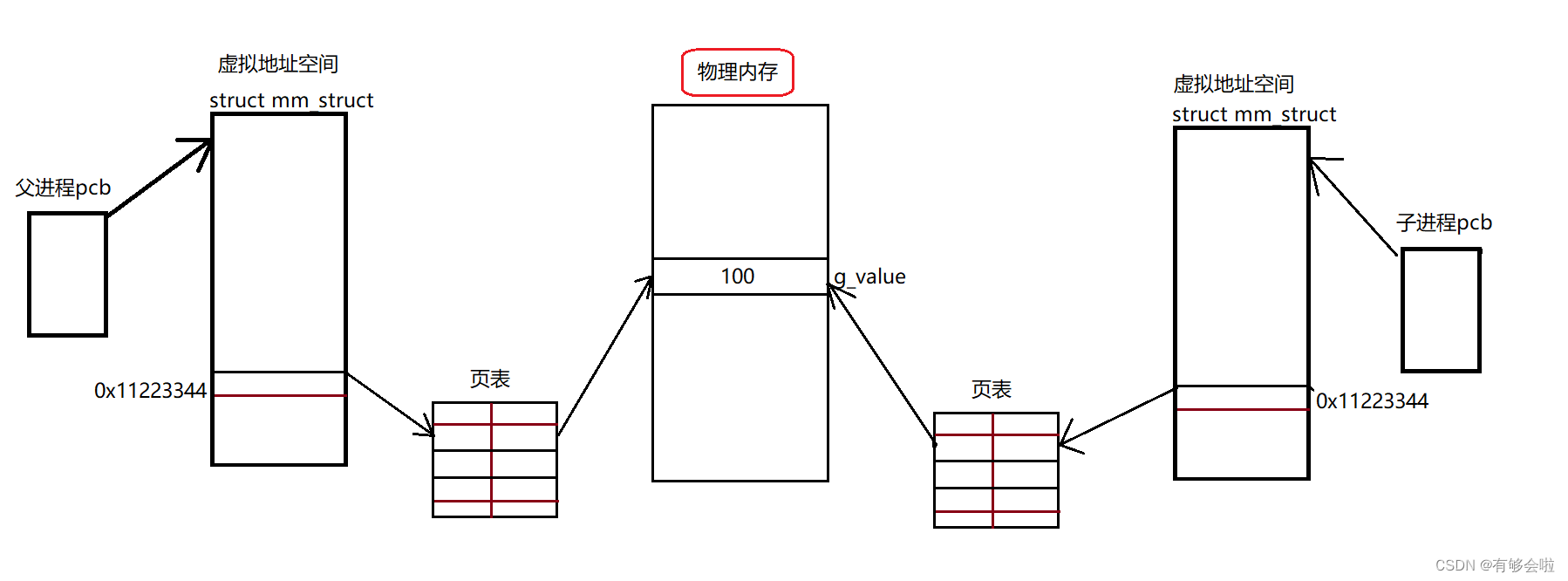
创建父进程时,在内核中维护父进程task_struck与父进程虚拟地址空间mm_struct,虚拟地址通过页表映射到物理地址中存储g_value = 100。
接下来fork创建了子进程,创建子进程的时候就要以父进程的pcb和mm_struct为模版,创建子进程的pcb和mm_struct地址空间并维护子进程对应的页表结构。
即子进程内核数据结构中的属性字段绝大部分会继承自父进程。(pcb与mm_struct)
所以二者打印的数据都是相同的,数据地址也是相同的,如下图所示:
而当子进程对数据进行修改的时候,如果在原物理地址进行修改,那么父进程读取的数据也会发生变化。
但是事实是子进程对数据的修改不能影响父进程。
所以当子进程想要修改数据的时候,OS会在内存中为其重新申请一块空间,并将原来空间的数据拷贝到新的空间,然后OS会重新构建子进程页表的映射关系,指向新的空间。所以当子进程修改数据的时候,不会影响父进程。
又因为修改的时候是在物理内存中申请空间,修改的是页表的映射关系,原来的虚拟地址不变,所以才有了之前观察到的地址相同而存储内容不同的现象。 如下图所示:
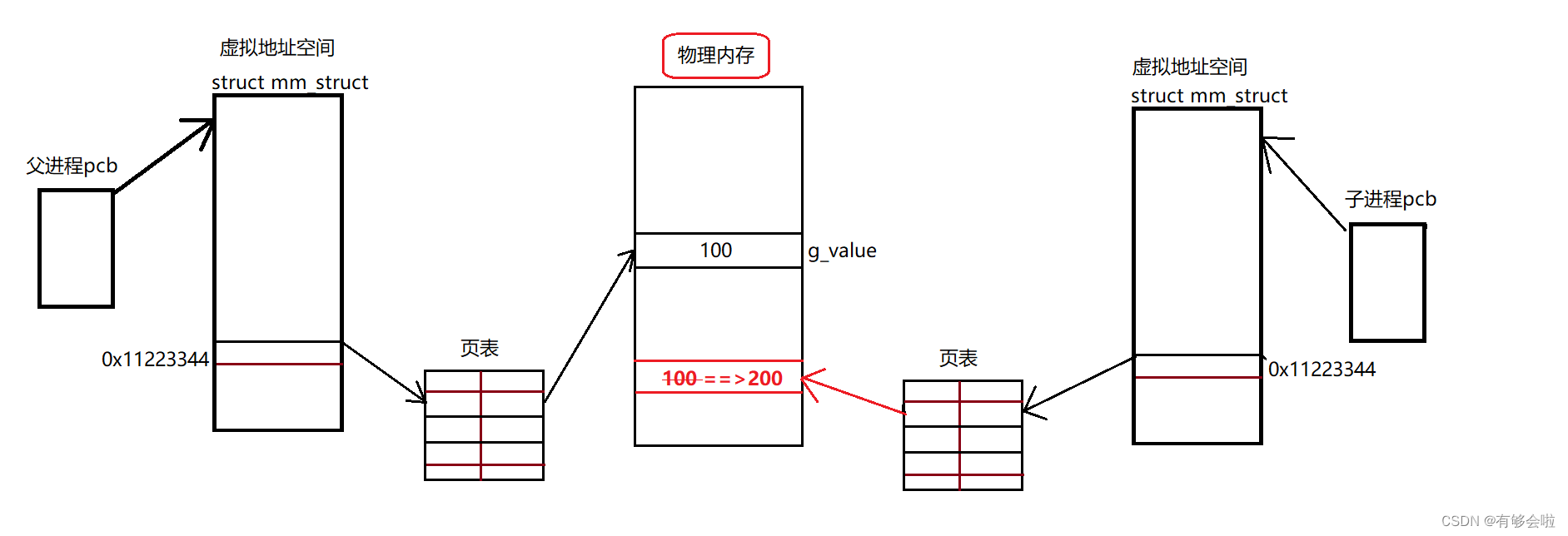
这就是进程独立性的一种表现方式:
PCB-地址空间-页表互相解耦,不会互相影响。
fork两个返回值的原理
fork函数在返回的时候,因为父子进程一定都已经创建完成了,所以其return语句会执行两次,而返回的本质就是写入,谁先返回,谁就让操作系统发生写时拷贝。
地址空间为什么要存在?
如果没有地址空间,OS如何工作?
当需要执行进程的时候,直接从磁盘读取代码数据到物理内存,然后CPU通过PCB直接找到物理内存中的代码进行运行,看似没有什么问题。
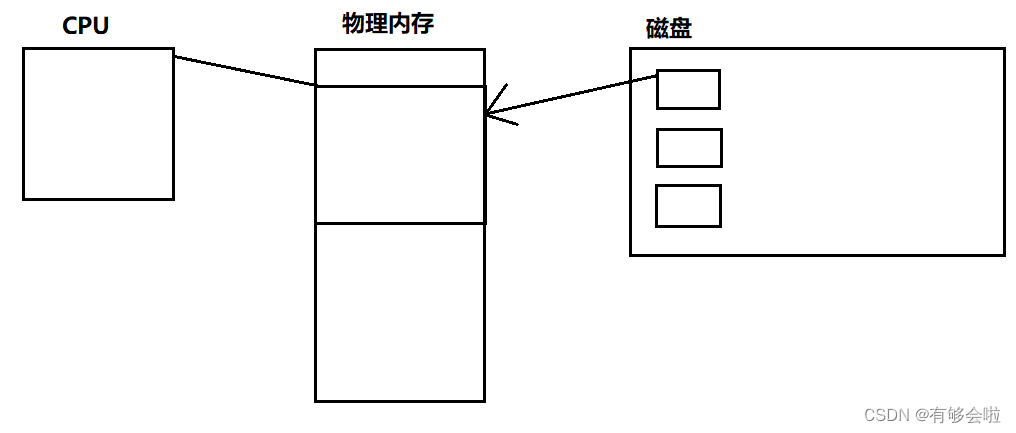
但是如果一个程序中有寻址的操作,并且这个程序写的有问题,发生了越界操作(野指针),访问到了下一个进程的物理内存区域,这时候如果是写入操作,就可能会导致下一个进程出现问题。这样就无法保证进程的独立性了。如下图所示。
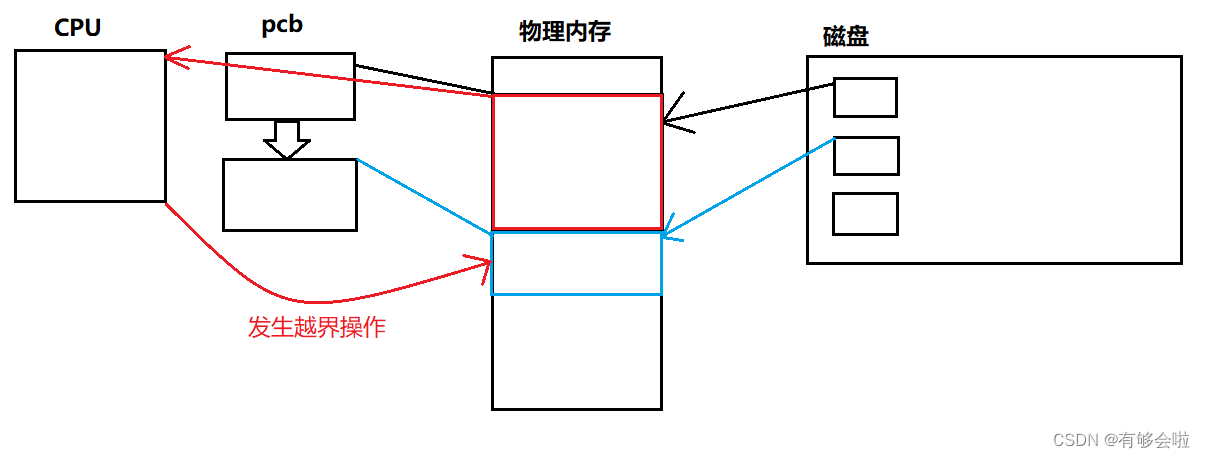
所以引入了页表和虚拟地址空间,访问物理空间就不再是直接访问而是要通过虚拟地址与页表的映射才能访问,但是只是添加一层映射并不能解决问题。
真正解决问题的原理是:添加的映射还可以决定程序能否成功去访问对应的物理空间,通过对应的映射只能访问自己进程所属的物理空间,会通过OS来检测访问是否合法,不合法会进行拦截(比如野指针),只会使自己崩溃,不会影响别的进程。
所以虚拟地址空间与页表其实就是添加了一层软件层,来保证进程的独立性。
总结: 虚拟地址空间存在的意义:
- 防止地址随意访问,保护了物理内存与其他进程。
- 将进程管理和内存管理解耦合。
- 可以让进程以统一的视角看待自己的代码和数据。(接收的都是虚拟地址)
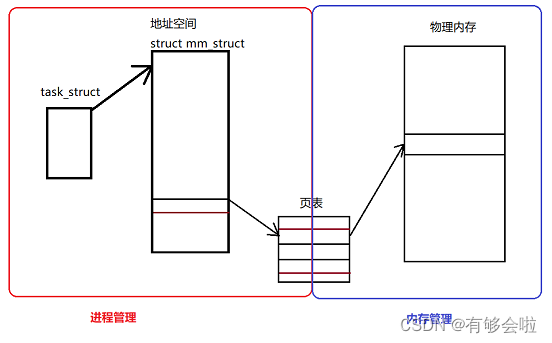
补充理解
1.为什么常量区的数据不能被修改?
——因为虚拟地址通过页表映射时,发现访问的数据在常量区,页表中给的权限都是r权限,只能读不能写。
2.malloc的本质,相OS申请空间的时候,是直接给你还是你需要的时候才给你呢?
——在需要的时候才给。
OS不允许任何浪费与不高效行为。当我们malloc在堆区申请空间的时候,不一定是申请了立马就用的,那么在你申请好但是没有使用的期间,这部分空间就处于闲置状态,如果内存中的进程多的话,就会出现低效的情况。
所以当我们malloc在堆区申请空间的时候,OS只会在虚拟地址空间中给我们申请空间(堆区扩大,向上增长,修改end指针即可),页表将虚拟地址填入K,而物理地址V侧暂时先不填任何东西,同时也不在物理地址申请空间,也就不用维护任何映射关系,直接返回虚拟地址空间的地址,当进程对这块空间进行写入时,OS再进行映射申请实际的物理空间。
这种行为称之为缺页中断。
3.重新理解地址空间
程序编译的时候,没有被加载到内存,这时候程序中有没有地址呢?
——有。
程序在磁盘上形成可执行程序的时候就已经有了一定的格式,比如代码段、已初始化全局数据区、未初始化全局数据区等。当它被加载到内存中的时候,分批式的将自己的数据段加载到地址空间中。
所以其实源代码在被编译的时候,就是已经按照虚拟地址空间的格式对代码和数据进行了编址。
虚拟地址这种策略不仅仅只会影响OS,编译器也遵守虚拟地址的规则!(这也是为什么反汇编中可以查看虚拟地址)
——所以在CPU中读到的数据中涵盖的地址,是虚拟地址,不是物理地址。(大致原理如下图所示)
4.进程的代码和数据必须一直在内存中吗?
——不一定,用多少加载多少,边加载边执行,这也是通过虚拟地址空间实现的。