引言
学习索引是一种新型的索引结构,可以帮助数据库更快地查找数据。学习索引的诞生可以追溯到 2017 年,由 Google Brain 团队的 Kraska 等人在论文[1]中首次提出,探讨了使用神经网络替代传统数据结构(如 B-Tree)来构建索引的可行性。其工作方式是通过机器学习算法学习数据分布规律,构建一个能够预测数据位置的函数。当需要查找某个数据时,只需要使用这个函数预测出数据的位置,然后直接访问即可,而不需要在整个数据集中进行搜索。因此,学习索引可以大大提高数据的访问速度,减少搜索时间。不仅如此,学习索引只需要存储习得的参数,不需要存储大量的内部卫星节点,显著地降低了存储空间地占用,这对于大规模数据存储和处理都非常有帮助。
在这几年里,学习索引的研究受到了广泛的关注和讨论。研究人员在模型的训练和优化、索引结构的设计和实现等方面做出了许多创新和改进。本篇聚焦学习索引结构设计,为读者归纳近几年知名会议或期刊上的学习索引结构,希望能对这方面的研究者有所启发和帮助。
RMI(开山鼻祖)[1]
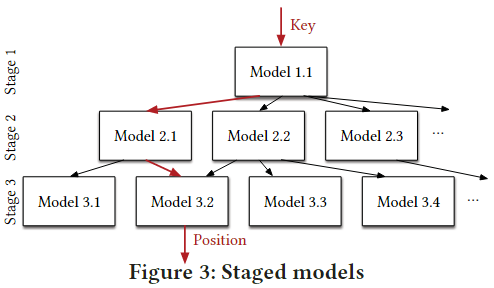
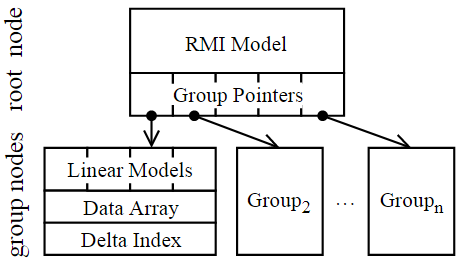
RMI 全名叫 Recursive Model Indexing,是一种经典的模型,由 Kraska 等人在 2018 年 SIGMOD 提出。RMI 模型是一种递归模型,它的主要思想是将数据集分成若干个子集(每个子集包含的数据量相等),并对每个子集训练一个能够预测数据位置的模型。这些模型被组织成一个树形结构,根节点是一个能够将查询分配到子集中的路由模型,叶节点则是最终的预测模型(集成学习的思想)。当需要查询数据时,RMI 模型使用路由模型将查询分配到合适的子集中,然后在该子集中使用相应的预测模型进行数据查找。
RMI 模型具有较高的预测精度和较快的查询速度。但是,RMI 训练需要大量的时间和计算资源,同时,不支持实时的更新和写入(需要重新训练模型)。
代码仓库:https://github.com/learnedsystems/RMI(作者开源)
FITing-Tree[2]
FITing-Tree 使用了 Linear Model 来拟合底层的数据分布,采用了 Bottom-Up 的方式建立索引。其整体的思想是保留了 B+树的内部节点(作为导航),把叶子节点替换成学习模型,不存储实际数据,而是存储学习模型的参数。因此,极大地降低了索引的存储开销。FITing-Tree 支持插入,其方式是在每个 Segment 内存储一个缓冲区,当缓冲区满,删除过时的 Segment,插入新的 Segment。从这篇工作以后,Linear Model 成为学习索引模型的首选(性能好、开销小)。
代码仓库:https://github.com/JiananYuan/FITing-Tree(民间实现)

ALEX[3]
ALEX 专门为了解决 RMI 学习索引不支持高效插入而设计。ALEX 的基本思想是在内部节点和叶子节点使用学习模型,并留了空隙(Gapped Array,简称 GA,scatter in node,而不是像 B+树那样,全部空隙都推到了后面)。在插入的时候,这些 GA 对于插入的数据有良好的“吸收”性能。当 GA 数量不足时,ALEX 会采取一定的方式进行节点调整。ALEX 是目前整体性能都比较好的学习索引之一,其代码设计也非常值得学习。
代码仓库:https://github.com/microsoft/ALEX(作者开源)

LIPP[4]
LIPP 基本结构类似 ALEX,但其设计的 insight 是:学习索引的“最后一公里”查询是查询瓶颈之一。LIPP 的基本思想是:只要计算得出 key 的预测值 pos,那么 key 就一定存在 array[pos]这个位置,不需要在上下误差界限内进行 the last mile search。当然,这种方法也有一定代价:在插入数据时,如果预测位置已有数据,需要触发节点调整。
代码仓库:https://github.com/Jiacheng-WU/lipp(作者开源)

PGM[5]
PGM 的基本节点单元使用 Linear Model,采用 Bottom-Up 的构建方式,上一层对下一层的代表数据(每个 Segment 的起始点)递归地使用线性回归来构建索引树,其插入采用了类似 LSM 层次合并的思想来设计。
代码仓库:https://github.com/gvinciguerra/PGM-index(作者开源)

RadixSpline[6]
样条回归也是拟合数据的一种方式。RS 索引是一种构建时间复杂度为 O(n)的结构,只需要从前往后扫描待索引的数据,索引即可建立。RS 模型会从前往后,计算出哪两个数据之间的全部数据,可以被端点数据用 spline 拟合,个人理解有点像数据蒸馏(图中蓝点)。接着,为了进一步加快在所有 spline points 检索到目标 point 的速度,添加了 Radix 表(前缀表),根据数据的前 prefix 位,定位到候选 spline points 的起始和终止位置。查询时,提取 key 的前 prefix 位,在起止 spline points 之间查询得到可能包含 key 的样条,再通过计算得到 key 的大致存储位置。
代码仓库:https://github.com/learnedsystems/RadixSpline(作者开源)

HERMIT[7]
HERMIT 被设计用于处理表格中大量列的索引,当这些列之间存在高度相关性时,索引存储开销变得不可忽视。HERMIT 的核心结构是 TRS-Tree,是一种基于树的索引结构,这种结构可以将一个列上面的数据映射到另外具有相关性的一列上面。TRS-Tree 避免了建立二级索引带来的存储开销,因其基于列相关性使用了轻量级的学习模型来替代重量级的传统节点。但其查询性能,尤其是点查询性能,却可能比基线(B+树)还差。
代码仓库:无开源

总的来说,目前学习索引的结构很大程度被限定在线性回归模型里面,没有见到其他行之有效的学习模型来替换。更多的工作是在如何组织这些训练出来的线性模型下功夫,抑或是将已有结构稍作变化或不做变化,应用在某个场景下,在查询性能或存储开销取得了优良的性能。典型论文如下但不局限于下文(以下代码仓库均为作者开源):
和 LSM-tree 结合
-
OSDI 20:From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
代码仓库:https://bitbucket.org/daiyifandanny/learned-leveldb/src/master/

-
TPDS 33(8):TridentKV: A Read-Optimized LSM-Tree Based KV Store via Adaptive Indexing and Space-Efficient Partitioning
代码仓库:https://github.com/emperorlu/Learned-RocksDB

支持 String
-
ApSys 20:SIndex: A Scalable Learned Index for String Keys
代码仓库:https://ipads.se.sjtu.edu.cn:1312/opensource/xindex/-/tree/sindex

并行并发/分布式/RDMA
-
OSDI 20:Fast RDMA-based Ordered Key-Value Store using Remote Learned Cache
代码仓库:https://github.com/SJTU-IPADS/xstore

-
FAST 23:ROLEX: A Scalable RDMA-oriented Learned Key-Value Store for Disaggregated Memory Systems
代码仓库:https://github.com/iotlpf/ROLEX

-
PPoPP 20:XIndex: A Scalable Learned Index for Multicore Data Storage
代码仓库:https://ipads.se.sjtu.edu.cn:1312/opensource/xindex
新型存储
-
VLDB 16(2):PLIN: A Persistent Learned Index for Non-Volatile Memory with High Performance and Instant Recovery
代码仓库:https://github.com/tawnysky/PLIN

-
VLDB 15(3):APEX: A High-Performance Learned Index on Persistent Memory,APEX 主要基于 ALEX 适配持久内存
代码仓库:https://github.com/baotonglu/apex
传统赛道打出新花样
-
ASPLOS 23:LeaFTL: A Learning-Based Flash Translation Layer for Solid-State Drives
代码仓库:https://github.com/platformxlab/LeaFTL

尾注
本片所述 learned index 的结构不涉及多维索引结构。
参考文献
[1] Kraska T, Beutel A, Chi E H, et al. The case for learned index structures[C]//Proceedings of the 2018 international conference on management of data. 2018: 489-504.
[2] Galakatos A, Markovitch M, Binnig C, et al. Fiting-tree: A data-aware index structure[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1189-1206.
[3] Ding J, Minhas U F, Yu J, et al. ALEX: an updatable adaptive learned index[C]//Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020: 969-984.
[4] Wu J, Zhang Y, Chen S, et al. Updatable Learned Index with Precise Positions. Proceedings of the VLDB Endowment, 2021, 14(8): 1276-1288.
[5] Ferragina P, Vinciguerra G. The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds[J]. Proceedings of the VLDB Endowment, 2020, 13(8): 1162-1175.
[6] Kipf A, Marcus R, van Renen A, et al. RadixSpline: a single-pass learned index[C]//Proceedings of the third international workshop on exploiting artificial intelligence techniques for data management. 2020: 1-5.
[7] Wu Y, Yu J, Tian Y, et al. Designing succinct secondary indexing mechanism by exploiting column correlations[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1223-1240.