老师发布作业链接:(429条消息) 【22-23 春学期】AI作业6-误差反向传播_HBU_David的博客-CSDN博客
目录
老师发布作业链接:(429条消息) 【22-23 春学期】AI作业6-误差反向传播_HBU_David的博客-CSDN博客
1.梯度下降
2.反向传播
3.计算图
4.使用Numpy编程实现例题
5.使用PyTorch的Backward()编程实现例题
1.梯度下降
梯度下降是一种最小化目标函数的优化算法,在机器学习中经常使用。其基本思想是通过反复迭代来逐步调整模型参数,使目标函数的值不断减小,从而达到最小化目标函数的目的。
在每一次迭代中,梯度下降算法会计算目标函数关于当前参数的梯度,即目标函数在当前参数点处的斜率,然后朝着梯度下降的方向调整参数,使得目标函数值减小。如果梯度为正,则参数向负方向移动;如果梯度为负,则参数向正方向移动。重复这个过程,直到找到局部或全局最小值,或者达到预定的停止条件。
梯度下降算法有不同的变种,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)、小批量梯度下降(Mini-Batch Gradient Descent)等。这些变种算法主要区别在于如何计算梯度和如何更新参数。
2.反向传播
反向传播(Backpropagation)是一种用于计算神经网络中每个参数对损失函数的导数的算法。它是训练神经网络中的权重和偏置的关键步骤。
在训练过程中,反向传播从输出层开始向前传播误差,通过链式法则计算每一层的误差贡献,然后再通过链式法则计算每个参数对误差的贡献,最终得到每个参数的梯度。这些梯度可以用于更新网络中的权重和偏置,使得损失函数得到最小化。
具体来说,反向传播的过程可以分为两个阶段:前向传播和反向传播。在前向传播阶段,神经网络将输入数据通过每一层的权重和偏置计算得到输出结果,然后计算与真实值的误差。在反向传播阶段,误差从输出层开始向前传播,通过链式法则计算每一层的误差贡献,最终计算得到每个参数的梯度。
通过反向传播算法,神经网络可以自动计算每个参数对损失函数的影响,并根据这些影响来更新参数,从而使神经网络逐步优化,提高预测精度。
3.计算图
计算图(Computational Graph)是一种图形化表示计算过程的方式。在机器学习中,计算图通常用于表示神经网络中的计算流程,从而方便进行求导和优化。
在计算图中,节点表示变量或操作,边表示数据流。计算图中的每个节点都对应一个数学运算,例如加法、乘法、卷积等。每个节点的输入和输出都是张量,可以是标量、向量、矩阵或高维张量。
计算图可以分为静态计算图和动态计算图两种类型。静态计算图在计算前需要预先定义好网络结构和参数,然后将整个计算流程编译为计算图,进行优化和求导。而动态计算图则是在运行时动态生成,每个计算步骤都可以根据需要重新构造计算图,可以更加灵活。
通过计算图,可以清晰地了解每个节点之间的依赖关系,从而更好地理解神经网络中的计算流程,方便进行求导和优化。同时,计算图还可以通过自动微分技术计算导数,为反向传播等算法提供基础支持。
4.使用Numpy编程实现例题
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
a = 1 / (1 + np.exp(-z))
return a
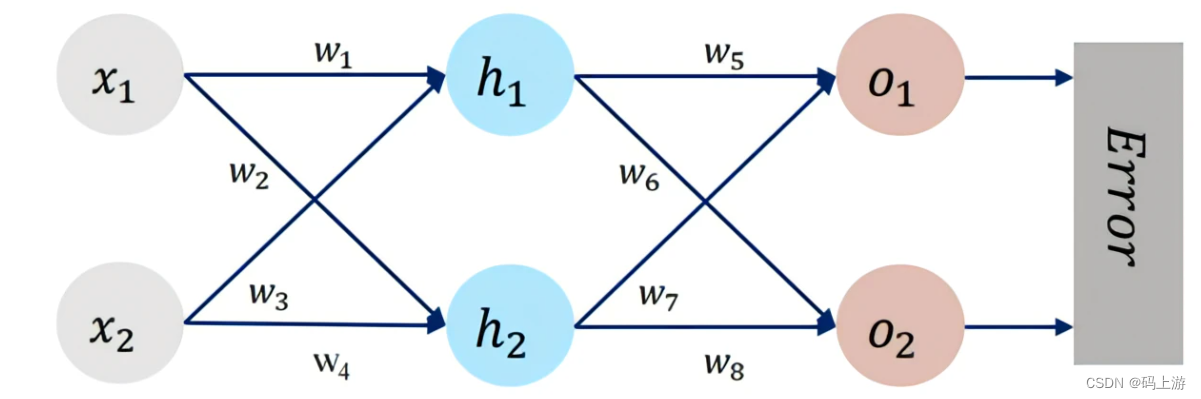
def forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8): # 正向传播
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2)
error = (1 / 2) * (out_o1 - y1) ** 2 + (1 / 2) * (out_o2 - y2) ** 2
return out_o1, out_o2, out_h1, out_h2, error
def back_propagate(out_o1, out_o2, out_h1, out_h2): # 反向传播
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
d_w5 = d_o1 * out_o1 * (1 - out_o1) * out_h1
d_w7 = d_o1 * out_o1 * (1 - out_o1) * out_h2
d_w6 = d_o2 * out_o2 * (1 - out_o2) * out_h1
d_w8 = d_o2 * out_o2 * (1 - out_o2) * out_h2
d_w1 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x1
d_w3 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x2
d_w2 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x1
d_w4 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x2
return d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8
def update_w(step,w1, w2, w3, w4, w5, w6, w7, w8): #梯度下降,更新权值
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
w1, w2, w3, w4, w5, w6, w7, w8 = 0.2, -0.4, 0.5, 0.6, 0.1, -0.5, -0.3, 0.8 # 可以给随机值,为配合PPT,给的指定值
x1, x2 = 0.5, 0.3 # 输入值
y1, y2 = 0.23, -0.07 # 正数可以准确收敛;负数不行。why? 因为用sigmoid输出,y1, y2 在 (0,1)范围内。
N = 10 # 迭代次数
step = 10 # 步长
print("输入值:x1, x2;",x1, x2, "输出值:y1, y2:", y1, y2)
eli = []
lli = []
for i in range(N):
print("=====第" + str(i) + "轮=====")
# 正向传播
out_o1, out_o2, out_h1, out_h2, error = forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8)
print("正向传播:", round(out_o1, 5), round(out_o2, 5))
print("损失函数:", round(error, 2))
# 反向传播
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8 = back_propagate(out_o1, out_o2, out_h1, out_h2)
# 梯度下降,更新权值
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(step,w1, w2, w3, w4, w5, w6, w7, w8)
eli.append(i)
lli.append(error)
plt.plot(eli, lli)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()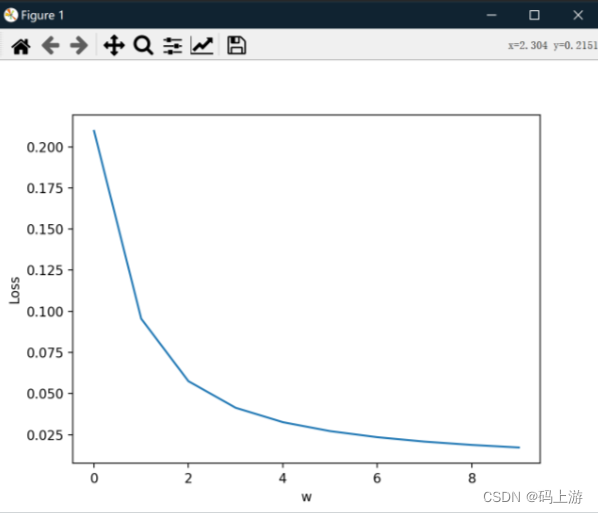
5.使用PyTorch的Backward()编程实现例题
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
#design model using class
"""
our model class should be inherit from nn.Module, which is base class for all neural network modules.
member methods __init__() and forward() have to be implemented
class nn.linear contain two member Tensors: weight and bias
class nn.Linear has implemented the magic method __call__(),which enable the instance of the class can
be called just like a function.Normally the forward() will be called
"""
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# construct loss and optimizer
# criterion = torch.nn.MSELoss(size_average = False)
criterion = torch.nn.MSELoss(reduction = 'sum')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # model.parameters()自动完成参数的初始化操作
# training cycle forward, backward, update
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
print(epoch, loss.item())
optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)