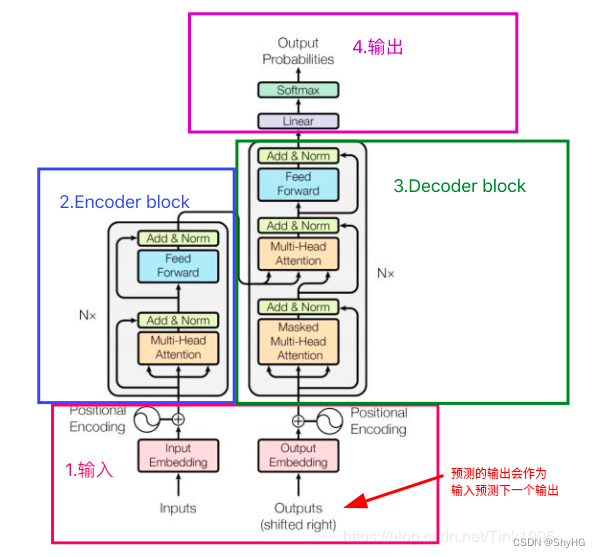
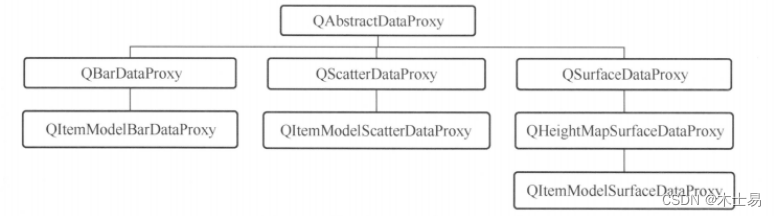
1. RNN存在的问题
- RNN对并行计算并不友好,下一输出依赖于上一输入,难以实现并行高效计算
- RNN相比较与self-attension模块,缺少对部分变量权重的预估,输出的数据默认拥有一致的权重
2. self-attension
self-attension是干嘛的?是为了弥补word2vec的不足,word2vec是采用统一的模式获取每个次的信息,使用的过程中忽略了在不同上下文的重要性,不同的词在不同的上下文中具有不同的重要性,但word2vec做的不好,所以使用self-attension,self-attension针对不同的上下文都做相应的计算,更灵活的获取了上下文信息。
需要三个训练矩阵, Q , K , V Q,K,V Q,K,V分别对应" query,要去查询的;key,等待被查的;value,实际特征信息"
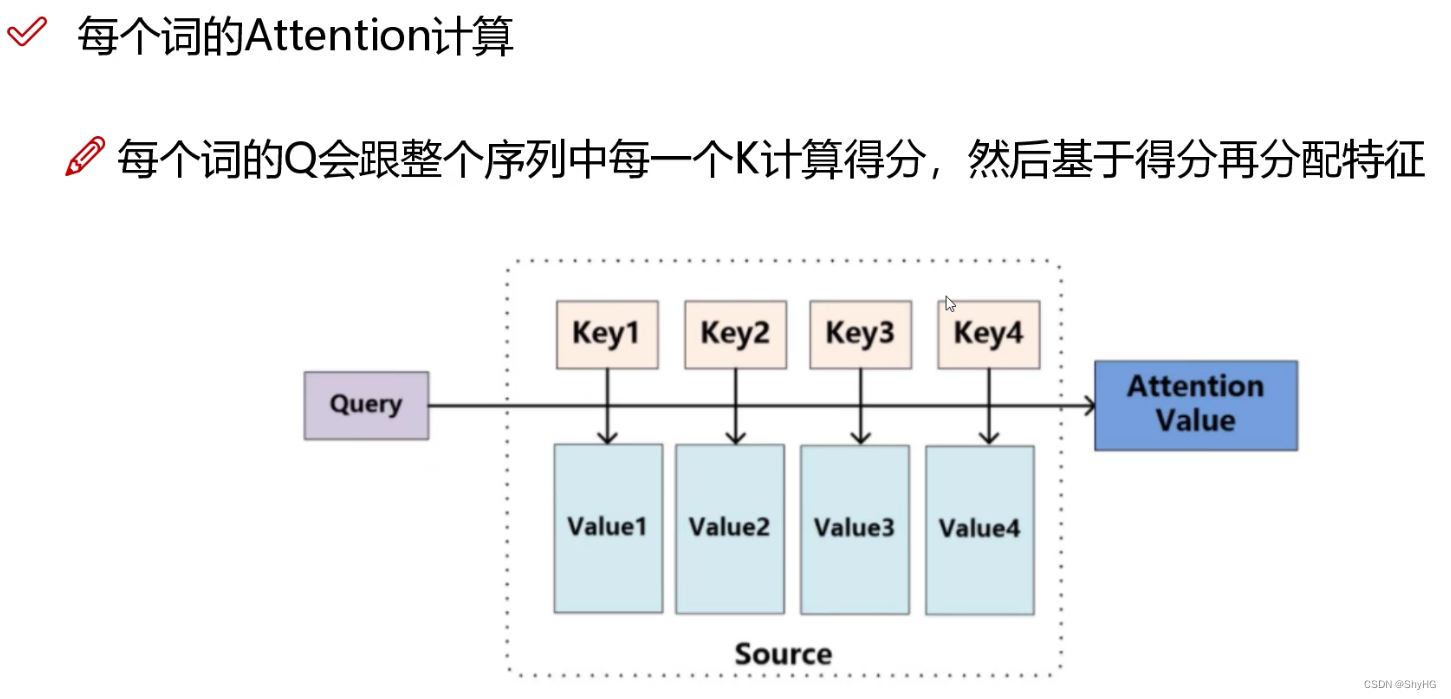
- Q Q Q和 K K K的内积表示有多匹配(内积相当于投影,相关性越大,内积越大)
- 注意图中的
d
k
\boxed{\sqrt{d_{k}}}
dk,为了保证维度不会影响分支,做了一个归一化


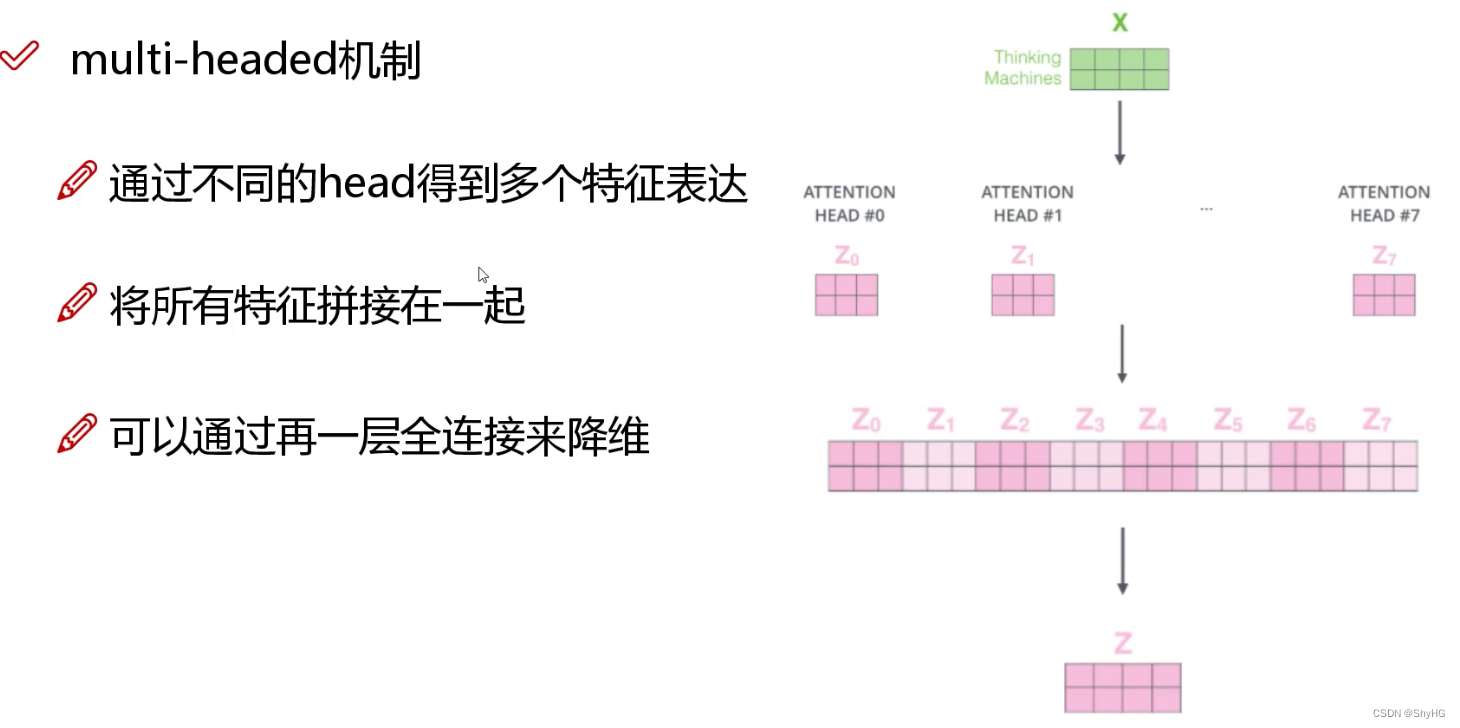
3. multi-headed多头机制
上面说到,一组
Q
,
K
,
V
Q,K,V
Q,K,V可以编码除一个
Z
Z
Z,尝试使用多组
Q
,
K
,
V
Q,K,V
Q,K,V生成多组
Z
Z
Z再做融合降维(参考卷积中的多卷积核),融合可以使用全连接的方式
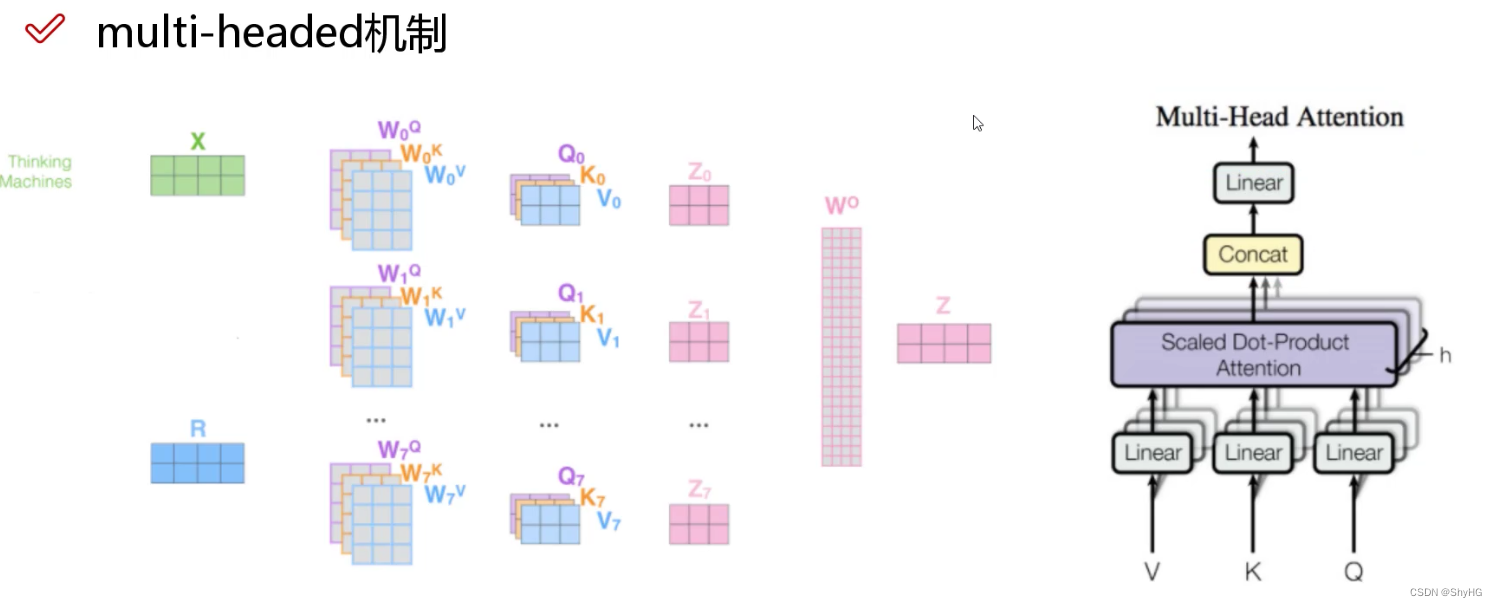
 最终的流程:一组
Q
,
K
,
V
Q,K,V
Q,K,V是有半部分图片中的一片,多组是多片,然后concat后利用全连接行程最终的Multi-Head Attension
最终的流程:一组
Q
,
K
,
V
Q,K,V
Q,K,V是有半部分图片中的一片,多组是多片,然后concat后利用全连接行程最终的Multi-Head Attension
4. 其他
- 上面说到,每个词都会考虑全局做编码,这就导致这个词不管在句子中的哪个位置,最终的编码结果都是一样的,这有悖于我们的认知,所以需要添加位置编码信息。对位置进行编码的方式有多种。
- LayerNormalization是针对每一层进行归一化,BN是在channel方向进行的归一化,而LN是在单channel方向进行的归一化。
- nask机制,在deconder解码的过程中,还需要将已经预测过的序列再次加入到模型中,针对当前的预测词,使用mask遮住
- bert的理解,bert就是tranformer中的encoder模块的功能,他不需要标签数据,而是使用mask方法,就是遮住部分输入再预测被遮住的部分,还有就是通过预测两个句子是否在一起。
5. 整体架构
总体思路就是:[ 编码(QKV+Pose)+输出(编码)] + 解码 + 输出,总体见下图(图源水印)