DataFrame 是什么
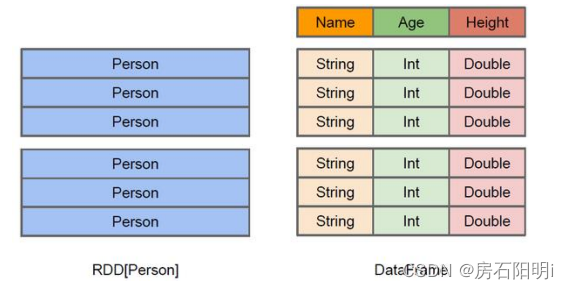
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中
的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame
所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构
信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性
的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的
具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
DataSet 是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame
的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark
SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter
等等)。
➢ DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
➢ 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
➢ 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到
DataSet 中的字段名称;
➢ DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
➢ DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将
DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
创建 DataFrame有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回
1.从 Spark 数据源进行创建
查看 Spark 支持创建文件的数据源格式
scala> spark.read.
csv format jdbc json load option options orc parquet schema
table text textFile
在 spark 的 bin/data 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
。。。。。
。。。。。
1.读取 json 文件创建 DataFrame
scala> val df = spark.read.json("data/user.json")
2.对 DataFrame 创建一个临时表
scala> df.createOrReplaceTempView("people")
3.通过 SQL 语句实现查询全表
scala> val sqlDF = spark.sql("SELECT * FROM people")
4.结果展示
scala> sqlDF.show
====
注意:普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时表。使
用全局临时表时需要全路径访问,如:global_temp.people
====
5.对于 DataFrame 创建一个全局表
scala> df.createGlobalTempView("people")
6.通过 SQL 语句实现查询全表
scala> spark.sql("SELECT * FROM global_temp.people").show()
或
scala> spark.newSession().sql("SELECT * FROM global_temp.people").show()
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图
1.创建一个 DataFrame
scala> val df = spark.read.json("data/user.json")
2.查看 DataFrame 的 Schema 信息
scala> df.printSchema
3.只查看"username"列数据
scala> df.select("username").show()
4.查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
scala> df.select($"username",$"age" + 1).show
scala> df.select('username, 'age + 1).show()
scala> df.select('username, 'age + 1 as "newage").show()
5.查看"age"大于"20"的数据
scala> df.filter($"age">20).show
6.按照"age"分组,查看数据条数
scala> df.groupBy("age").count.show
RDD 转换为 DataFrame
idea如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入
import spark.implicits._
spark-shell 中无需导入,自动完成此操作
scala> val idRDD = sc.textFile("data/test.txt")
scala> idRDD.toDF("id").show
通过样例类将 RDD 转换为 DataFrame
scala> case class User(name:String, age:Int)
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
DataFrame 转换为 RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
scala> val df = sc.makeRDD(List(("zhangsan",10), ("lisi",20))).map(t=>User(t._1, t._2)).toDF
scala> val rdd = df.rdd
scala> val array = rdd.collect
注意:此时得到的 RDD 存储类型为 Row
scala> array(0)
res28: org.apache.spark.sql.Row = [zhangsan,10]
scala> array(0)(0)
res29: Any = zhangsan
scala> array(0).getAs[String]("name")
res30: String = zhangsan
DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
创建 DataSet
1.使用样例类序列创建 DataSet
scala> case class Person(name: String, age: Long)
scala> val caseClassDS = Seq(Person("zhangsan",1)).toDS()
scala> caseClassDS.show
2.使用基本类型的序列创建 DataSet
scala> val ds = Seq(1,2,3,4,5).toDS
scala> ds.show
RDD 转换为 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结
构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。
scala> case class User(name:String, age:Int)
scala> sc.makeRDD(List(("zhangsan",1), ("lisi",2))).map(t=>User(t._1,
t._2)).toDS
DataSet 转换为 RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
scala> case class User(name:String, age:Int)
scala> sc.makeRDD(List(("zhangsan",1), ("lisi",2))).map(t=>User(t._1, t._2)).toDS
scala> val rdd = res11.rdd
scala> rdd.collect
DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
1.DataFrame 转换为 DataSet
scala> case class User(name:String, age:Int)
scala> val df = sc.makeRDD(List(("zhangsan",1), ("lisi",2))).toDF("name","age")
scala> val ds = df.as[User]
DataSet 转换为 DataFrame
scala> val ds = df.as[User]
scala> val df = ds.toDF
RDD、DataFrame、DataSet 三者的区别
- RDD
RDD 一般和 spark mllib 同时使用
RDD 不支持 sparksql 操作 - DataFrame
与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
DataFrame 与 DataSet 一般不与 spark mllib 同时使用
DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能注册临时表/视窗,进行 sql 语句操作
DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表头,这样每一列的字段名一目了然(后面专门讲解) - DataSet
Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
idea实例
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>scala-demo-project</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.11.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc-config -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc-config_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.69</version>
</dependency>
<dependency>
<groupId>ch.hsr</groupId>
<artifactId>geohash</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api-scala_2.11</artifactId>
<version>11.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.kgc.kafak.demo.ThreadProducer</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude><META-I></META-I>NF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
DataFrame:case class to DF
package SparkTest.SparkSql
import org.apache.spark.sql.SparkSession
case class Person(val name:String,val uid:Int,val score:Int)
object CreateDataFrame1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("sqltest1")
.master("local[*]")
.getOrCreate()
import session.implicits._
val sc = session.sparkContext
val lines = sc.parallelize(List("zhangssan,1,11", "lisi,2,22", "wangu,3,33", "xiaohong,4,44"))
val result = lines.map(line => {
val fields = line.split(",", -1)
Person(fields(0), fields(1).toInt, fields(2).toInt)
})
val df = result.toDF()
//DSL
// df.printSchema()
// df.show()
//SQL
df.createTempView("users")
session.sql(
"""
|
|
|
|select
|name,uid
|from
|users
|
|
|
""".stripMargin).show()
session.close()
}
}
//结果+---------+---+
| name|uid|
+---------+---+
|zhangssan| 1|
| lisi| 2|
| wangu| 3|
| xiaohong| 4|
+---------+---+
tuple–>toDF
package SparkTest.SparkSql
import org.apache.spark.sql.SparkSession
object CreateDataFrame2 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("sqltest2")
.master("local[*]")
.getOrCreate()
import session.implicits._
val sc = session.sparkContext
val lines = sc.parallelize(List("zhangssan,1,11", "lisi,2,22", "wangu,3,33", "xiaohong,4,44"))
val result = lines.map(line => {
val fields = line.split(",", -1)
(fields(0),fields(1).toInt,fields(2).toInt)
})
val df = result.toDF("name","uid","score")
//DSL
df.printSchema()
df.show()
//
//SQL
session.close()
}
}
//结果:+---------+---+-----+
| name|uid|score|
+---------+---+-----+
|zhangssan| 1| 11|
| lisi| 2| 22|
| wangu| 3| 33|
| xiaohong| 4| 44|
+---------+---+-----+
Row–> session.createDataFrame(rdd,schema)
package SparkTest.SparkSql
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
object CreateDataFrame3 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName("sqltest3")
.master("local[*]")
.getOrCreate()
import session.implicits._
val sc = session.sparkContext
val lines = sc.parallelize(List("zhangssan,1,11", "lisi,2,22", "wangu,3,33", "xiaohong,4,44"))
val result = lines.map(line => {
val fields = line.split(",", -1)
Row(fields(0),fields(1).toInt,fields(2).toDouble)
})
val schema=StructType(
List(
StructField("name", StringType),
StructField("uid", IntegerType),
StructField("score", DoubleType)
)
)
val df = session.createDataFrame(result,schema)
//DSL
//
df.printSchema()
df.show()
//
//SQL
session.close()
}
}
//结果:+---------+---+-----+
| name|uid|score|
+---------+---+-----+
|zhangssan| 1| 11.0|
| lisi| 2| 22.0|
| wangu| 3| 33.0|
| xiaohong| 4| 44.0|
+---------+---+-----+
处理json数据
json数据
json_test.txt
{"eventid": "applexxxEvent","event": {"pgId": "1","contentType": "Y","contentID": "1","contentTile": "","contentChannel": "","contentTag": "Y"},"user": {"uid": "123","account": "","email": "xxx@xxx.com","phoneNbr": "13xxxxxxxx0","isLogin": "lisi","gender": "y","phone": {"mac": "2x-xx-xx-xx-xx-xx-xx","osName": "ios","osVer": "15.0","resolution": "1024*768","uuid": "xxxxxxxxxxxxE"}},"timestamp": "1658155550000000"}{"eventid": "applexxxEvent","event": {"pgId": "2","contentType": "Y","contentID": "2","contentTile": "","contentChannel": "","contentTag": "Y"},"user": {"uid": "124","account": "","email": "xxx@xxx.com","phoneNbr": "13xxxxxxxx0","isLogin": "lisi2","gender": "x","phone": {"mac": "2x-xx-xx-xx-xx-xx-xx","osName": "ios","osVer": "15.0","resolution": "1024*768","uuid": "2xxxxxxxxxxxE"}},"timestamp": "1658155550000001"}
脚本CreateDataFrame4(读取json数据)
package SparkTest.SparkSql
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDataFrame4 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("4").getOrCreate()
val df: DataFrame = session.read.json("file:///F:/JavaTest/SparkDemo/data/json_test.txt")
df.printSchema()
df.show()
session.close()
}
}
//结果:+-----------+-------------+----------------+--------------------+
| event| eventid| timestamp| user|
+-----------+-------------+----------------+--------------------+
|[,1,Y,,Y,1]|applexxxEvent|1658155550000000|[,xxx@xxx.com,y,l...|
+-----------+-------------+----------------+--------------------+
读取csv文件
emp_test.csv
脚本CreateDataFrame5(读取csv文件)
package SparkTest.SparkSql
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDataFrame5 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("5").getOrCreate()
val df = session.read
.option("inferSchema", "true")
// .option("header", "true") //如果表内有字段名,开启这项
.csv("file:///F:/JavaTest/SparkDemo/data/emp_test.csv")
df.printSchema()
df.show()
session.close()
//或
/* val session = SparkSession.builder().master("local[*]").appName("5").getOrCreate()
val peopleDFCsv = session.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
// .option("header", "true") //如果表内有字段名,开启这项
.load("file:///F:/JavaTest/SparkDemo/data/emp_test.csv")
peopleDFCsv.printSchema()
peopleDFCsv.show()
session.close()
//结果:+--------------------+
//| _c0|
//+--------------------+
//|1,SMITH,CLERK,13,...|
//|2,ALLEN,SALESMAN,...|
//|3,WARD,SALESMAN,6...|
//|4,JONES,MANAGER,9...|
//|5,MARTIN,SALESMAN...|
//|6,BLAKE,MANAGER,9...|
//|7,CLARK,MANAGER,9...|
//|8,SCOTT,ANALYST,4...|
//|9,KING,PRESIDENT,...|
//|10,TURNER,SALESMA...|
//|11,ADAMS,CLERK,8,...|
//|12,JAMES,CLERK,6,...|
//|13,FORD,ANALYST,4...|
//|14,MILLER,CLERK,7...|
//+--------------------+*/
}
}
//结果:+---+------+---------+---+----------+----+----+---+
|_c0| _c1| _c2|_c3| _c4| _c5| _c6|_c7|
+---+------+---------+---+----------+----+----+---+
| 1| SMITH| CLERK| 13|2000/12/17| 800| \N| 20|
| 2| ALLEN| SALESMAN| 6| 2000/2/20|1600| 300| 40|
| 3| WARD| SALESMAN| 6| 2000/2/22|1200| 500| 30|
| 4| JONES| MANAGER| 9| 2000/4/2|2975| \N| 20|
| 5|MARTIN| SALESMAN| 6| 2000/9/28|1200|1400| 30|
| 6| BLAKE| MANAGER| 9| 2000/5/1|2800| \N| 30|
| 7| CLARK| MANAGER| 9| 2000/6/9|2400| \N| 10|
| 8| SCOTT| ANALYST| 4| 2000/7/13|3000| \N| 20|
| 9| KING|PRESIDENT| \N|2000/11/17|5000| \N| 10|
| 10|TURNER| SALESMAN| 6| 2000/9/8|1500| 0| 30|
| 11| ADAMS| CLERK| 8| 2000/7/13|1300| \N| 20|
| 12| JAMES| CLERK| 6| 2000/12/3| 950| \N| 30|
| 13| FORD| ANALYST| 4| 2000/12/3|2000| \N| 20|
| 14|MILLER| CLERK| 7| 2000/1/23|1500| \N| 10|
+---+------+---------+---+----------+----+----+---+
jdbc读取数据库,数据写入
package SparkTest.SparkSql
import java.util.Properties
import org.apache.spark.sql.{SaveMode, SparkSession}
object JdbcDemo {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("jdbcdemo").getOrCreate()
val df = session.read
.option("url", "jdbc:mysql://192.168.58.203:3306/testdb")
.option("dbtable", "testdb.user_test")
.option("user", "root")
.option("password", "123")
.format("jdbc").load()
df.printSchema()
df.show()
//写入 mysql(jdbc)
val props = new Properties()
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", "root")
props.setProperty("password", "123")
// df.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.58.203:3306/testdb", "user_test2", props);
//csv写入本地或hdfs上
// df.write.mode(SaveMode.Overwrite).csv("file:///F:/JavaTest/SparkIPMappingDemo/data/userout_test.csv") //最好写入到hdfs上 ("data/output/userout_test.csv")
//df.write.mode(SaveMode.Overwrite).parquet("file:///F:/JavaTest/SparkIPMappingDemo/data/userout") //最好写入到hdfs上 ("data/output/userout")
session.close()
}
}
//结果:+---------+------+
|user_name|number|
+---------+------+
| lisi| 123|
| lisi| 111|
| lisi| 222|
| wangwu| 456|
| wangwu| 333|
| zhangsan| 789|
| zhangsan| 444|
| zhangsan| 555|
| zhangsan| 666|
+---------+------+