第一章 Hadoop集群安装
1.1 集群规划
| 集群规划 | 规划 |
|---|---|
| 操作系统 | Mac、Windows |
| 虚拟软件 | Parallels Desktop(Mac)、VMWare(Windows) |
| 虚拟机 | 主机名: c1, IP地址: 192.168.10.101 主机名: c2, IP地址: 192.168.10.102 主机名: c3, IP地址: 192.168.10.103 |
| 软件包上传路径 | /root/softwares |
| 软件包安装路径 | /usr/local |
| JDK | Jdk-8u221-linux-x64.tar.gz |
| Hadoop | hadoop-2.7.6.tar.gz |
| 用户 | root |
ps:这里的ip要换成自己的ip,保持在一个子网下,可以互相ping通
1.1.1 服务器规划
因为搭建一个服务器集群需要至少一主两从,一共三台服务器,而且这三台服务器上很多配置和环境变量是重复的,所以我们可以配置好一些文件,省去我们后期的操作,主要包括下面的配置和环境:
- 安装对应的jdk和hadoop(hadoop有1x、2x、3x),并且分别配置jdk和hadoop的环境变量,并且使其环境变量生效
- 关闭防火墙,并关闭防火墙的自启动
- 确保/etc/hosts文件配置了IP和hosts的映射关系
- 确保三台机器的网络配置通畅(NAT模式、静态IP、主机名的配置),我们克隆服务器的时候,mac地址会重复,因此我们需要重新生成一下mac地址,这里要关闭DHCP(动态主机配置协议)
- 确保配置了三台机器的免密登录认证,生成自己的公钥和私钥
- 确保所有的机器时间同步,虚拟机关机的时候,时间会静止
- 新的centos虚拟机上只有vi,没有vim,介意的可以安装vim,vim用户体验更好一点。centos安装:
yum -y install vim*;ubuntu安装:sudo apt-get install vim-gtk
1.1.2 安装三台虚拟机
使用VMware安装三台centos,其中第一台需要手动创建,二三台直接复制第一台即可(右键虚拟机- - -管理- - -克隆),然后需要更改网络配置,随机生成新的mac地址,使用桥接模式配置网络
- 需要保证可以相互ping通,在同一子网段下
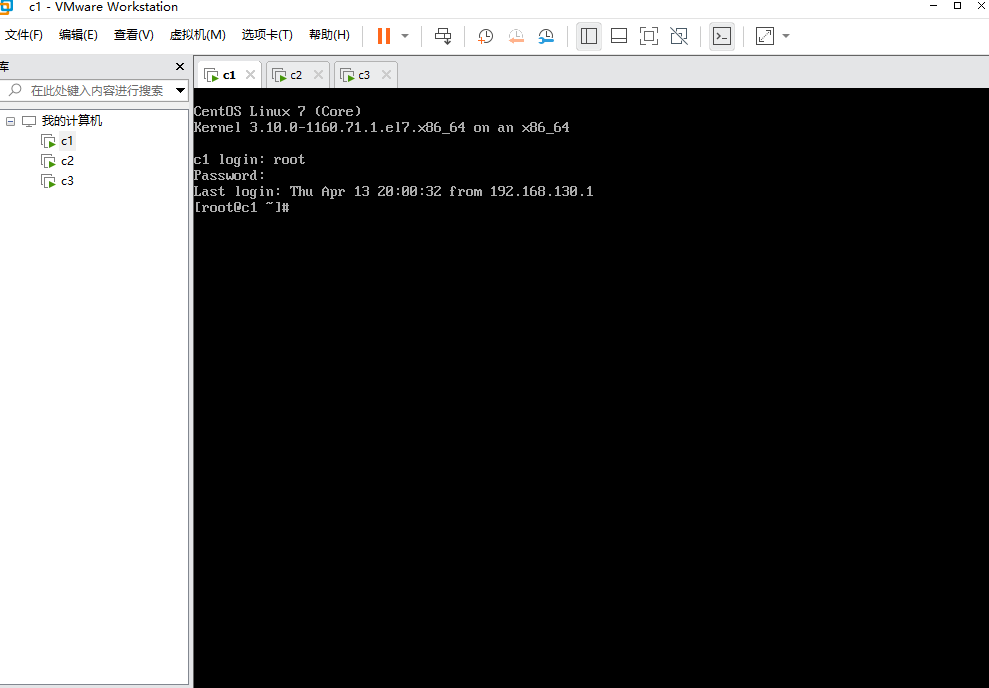
使用ssh工具连接三台服务器,这里使用FinalShell

1.2 安装JDK
1.2.1 检查一下是否已经安装过或者系统内置JDK,如果有内置的,将其卸载
[root@c1 ~]# rpm -qa | grep jdk # 如果有,请卸载
[root@c1 ~]# rpm -e xxxxxxxx --nodeps # 将查询到的内置jdk强制卸载
1.2.2 上传jdk1.8和hadoop2.6.7
将jdk-8u221-linux-x64.tar.gz上传到/root目录中
1.2.3 解压jdk和hadoop到/usr/local/下
[root@c1 ~]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local
1.2.4 更名jdk和hadoop
[root@c1 ~]# cd /usr/local
[root@c1 local]# mv jdk1.8.0_221/ jdk
1.2.5 配置Jdk的环境变量:/etc/profile
[root@c1 local]# vi /etc/profile
.........省略...........
#jdk environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
1.2.6 使当前窗口生效
[root@c1 local]# source /etc/profile
1.2.7 验证jdk环境
[root@c1 local]# java -version
[root@c1 local]# javac
1.3. 完全分布式环境需求及安装
1. 三台机器的防火墙必须是关闭的
2. 确保三台机器的网络配置通常(NAT模式、静态IP、主机名的配置)
3. 确保/etc/hosts文件配置了IP和hosts的映射关系
4. 确保配置了三台机器的免密登录认证
5. 确保所有的机器时间同步
6. JDK和Hadoop的环境变量配置
1.3.1 关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld
systemctl stop NetworkManager
systemctl disable NetworkManager
systemctl disable firewalld.service #关闭防火墙自启动
#最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled
[root@c1 ~]# vi /etc/selinux/config
.........
SELINUX=disabled
.........
1.3.2 静态IP和主机名配置
--1. 配置静态IP(确保NAT模式)
[root@c1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
............
BOOTPROTO=static # 将dhcp改为static,固定主机ip和主机名的映射
............
ONBOOT=yes # 将no改为yes
IPADDR=192.168.10.101 # 添加IPADDR属性和ip地址
PREFIX=24 # 添加NETMASK=255.255.255.0或者PREFIX=24
GATEWAY=192.168.10.2 # 添加网关GATEWAY
DNS1=114.114.114.114 # 添加DNS1和备份DNS
DNS2=8.8.8.8
--2. 重启网络服务
[root@c1 ~]# systemctl restart network
或者
[root@c1 ~]# service network restart
--3. 修改主机名(如果修改过,请略过这一步)
[root@localhost ~]# hostnamectl set-hostname c1
或者
[root@localhost ~]# vi /etc/hostname
c1
1.3.3 配置/etc/hosts文件
[root@c1 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 c1 #添加本机的静态IP和本机的主机名之间的映射关系
192.168.10.102 c2
192.168.10.103 c3
1.3.4 免密登录认证
-1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
[root@c1 ~]# cd ~
[root@c1 ~]# ssh-keygen -t rsa
-2. 进入~/.ssh目录下,使用ssh-copy-id命令
[root@c1 ~]# cd ~/.ssh
[root@c1 .ssh]# ssh-copy-id root@c1
-3. 进行验证
[hadoop@c1 .ssh]# ssh c1
#下面的第一次执行时输入yes后,不提示输入密码就对了
[hadoop@c1 .ssh]# ssh localhost
[hadoop@c1 .ssh]# ssh 0.0.0.0
注意:三台机器提前安装好的情况下,需要同步公钥文件。如果使用克隆技术。那么使用同一套密钥对就方便多了。
1.3.5 时间同步
# 1 选择集群中的某一台机器作为时间服务器,例如c1
# 2 保证这台服务器安装了ntp.x86_64。
# 3 保证ntpd 服务运行......
[root@c1 ~]# sudo service ntpd start
# 开机自启动:
[root@c1 ~]# chkconfig ntpd on
# 4 配置相应文件:
[root@c1 ~]# vi /etc/ntp.conf
# Hosts on local network are less restricted.
# restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# 添加集群中的网络段位
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
# server 0.centos.pool.ntp.org iburst 注释掉
# server 1.centos.pool.ntp.org iburst 注释掉
# server 2.centos.pool.ntp.org iburst 注释掉
# server 3.centos.pool.ntp.org iburst 注释掉
server 127.127.1.0 -master作为服务器
# 5 其他机器要保证安装ntpdate.x86_64
# 6 其他机器要使用root定义定时器
*/1 * * * * /usr/sbin/ntpdate -u c1
1.3.6 Hadoop安装与环境变量配置
# 1. 上传和解压两个软件包
[root@c1 ~]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/
[root@c1 ~]# tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/
# 2. 进入local里,给两个软件更名
[root@c1 ~]# cd /usr/local/
[root@c1 local]# mv 1.8.0_221/ jdk
[root@c1 local]# mv hadoop-2.7.6/ hadoop
# 3. 配置环境变量
[hadoop@c1 local]# vi /etc/profile
.....省略...........
#java environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
1.4. Hadoop的配置文件
1.4.1. 概述
我们需要通过配置若干配置文件,来实现Hadoop集群的配置信息
(这里Hadoop2.x和3.x配置信息略有不同,本文主要以2.x为主)。需要配置的文件有:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
在Hadoop安装完成后,会在$HADOOP_HOME/share路径下,有若干个*-default.xml文件,
这些文件中记录了默认的配置信息。同时,在代码中,我们也可以设置Hadoop的配置信息。
这些位置配置的Hadoop,优先级为: 代码设置 > *-site.xml > *-default.xml
集群规划:
+--------------+---------------------+
| Node | Applications |
+--------------+---------------------+
| c1 | NameNode |
| | DataNode |
| | ResourceManager |
| | NodeManagere |
+--------------+---------------------+
| c2 | SecondaryNameNode |
| | DataNode |
| | NodeManager |
+--------------+---------------------+
| c3 | DataNode |
| | NodeManager |
+--------------+---------------------+
1.4.2. core-site.xml
[root@c1 ~]# cd $HADOOP_HOME/etc/hadoop
[root@c1 hadoop]# vi core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。
在Hadoop2.x的版本中,默认使用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://c1:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
1.4.3. hdfs-site.xml
[root@c1 hadoop]# vi hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>c2:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>c1:50070</value>
</property>
</configuration>
1.4.4. mapred-site.xml
[root@c1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@c1 hadoop]# vi mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>c1:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>c1:19888</value>
</property>
</configuration>
1.4.5 yarn-site.xml
[root@c1 hadoop]# vi yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>c1</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>c1:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>c1:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>c1:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>c1:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>c1:8088</value>
</property>
</configuration>
1.4.6 hadoop-env.sh
[root@c1 hadoop]# vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
1.4.7 yarn-env.sh
[root@c1 hadoop]# vi yarn-env.sh
# some Java parameters
export JAVA_HOME=/usr/local/jdk
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
1.4.8 slaves
此文件用于指定datanode守护进程所在的机器节点主机名 ,3.x中是workers,配置不一样
[root@c1 hadoop]# vi slaves
c1
c2
c3
1.4.9 分发到另外两台节点
# 同步Hadoop到另外两台节点
[root@c1 ~]# cd /usr/local
[root@c2 local]# scp -r hadoop c2:$PWD
[root@c2 local]# scp -r hadoop c3:$PWD
# 同步profile到另外两台节点
[root@c1 ~]# scp /etc/profile c2:/etc
[root@c1 ~]# scp /etc/profile c3:/etc
# 检查slave节点上的jdk是否已安装
# 检查是否同步了/etc/hosts文件
1.5 格式化与启动
1.5.1 格式化集群
**1)**在c1机器上运行命令
[root@c1 ~]# hdfs namenode -format
**2)**格式化的相关信息解读
--1. 生成一个集群唯一标识符:clusterid
--2. 生成一个块池唯一标识符:blockPoolId
--3. 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
--4. 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
--5. 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
参考图片:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MHpY7J4z-1666016135908)(Hadoop.assets/image-20210401104441770.png)]](https://img-blog.csdnimg.cn/1934cd41ff9b45ee8d64918282d338b0.png)
1.5.2 启动集群
1) 启动脚本和关闭脚本介绍
1. 启动脚本
-- start-dfs.sh :用于启动hdfs集群的脚本
-- start-yarn.sh :用于启动yarn守护进程
-- start-all.sh :用于启动hdfs和yarn
2. 关闭脚本
-- stop-dfs.sh :用于关闭hdfs集群的脚本
-- stop-yarn.sh :用于关闭yarn守护进程
-- stop-all.sh :用于关闭hdfs和yarn
3. 单个守护进程脚本
-- hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode]
-- yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
**2) ** 启动HDFS
使用start-dfs.sh,启动 hdfs。
启动过程解析:
- 启动集群中的各个机器节点上的分布式文件系统的守护进程
一个namenode和resourcemanager以及secondarynamenode
多个datanode和nodemanager
- 在namenode守护进程管理内容的目录下生成edit日志文件
- 在每个datanode所在节点下生成${hadoop.tmp.dir}/dfs/data目录,参考下图:
注意!
如果哪台机器的相关守护进程没有开启,那么,就查看哪台机器上的守护进程对应的日志log文件,
注意,启动脚本运行时提醒的日志后缀是*.out,而我们查看的是*.log文件。
此文件的位置:${HADOOP_HOME}/logs/里
3) jps查看进程
--1. 在c1上运行jps指令,会有如下进程
namenode
datanode
--2. 在c2上运行jps指令,会有如下进程
secondarynamenode
datanode
--3. 在c3上运行jps指令,会有如下进程
datanode
**4) **启动yarn
使用start-yarn.sh脚本。
jps查看
--1. 在c1上运行jps指令,会多出有如下进程
resoucemanager
nodemanager
--2. 在c2上运行jps指令,会多出有如下进程
nodemanager
--3. 在c3上运行jps指令,会多出有如下进程
nodemanager
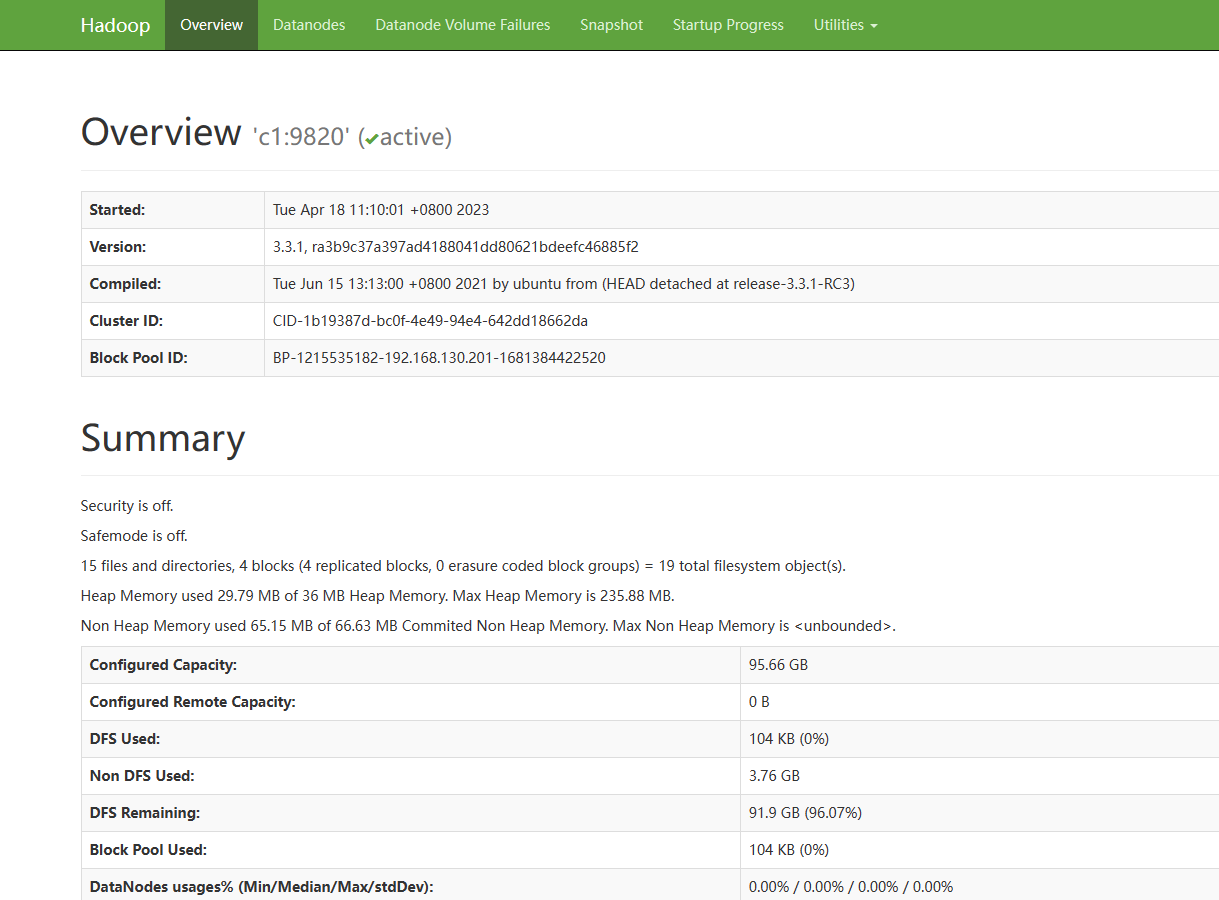
5) webui查看
HDFS: http://192.168.10.101:50070
YARN: http://192.168.10.101:8088
第二章 HDFS的Shell命令
HDFS其实就是一个分布式的文件系统,我们可以使用一些命令来操作这个分布式文件系统上的文件。
- 访问HDFS的命令:
hadoop dfs --- 已过时
替换为 --- hdfs dfs
- 小技巧
1. 在命令行中输入hdfs,回车后,就会提示hdfs后可以使用哪些命令,其中有一个是dfs。
2. 在命令行中输入hdfs dfs,回车后,就会提示dfs后可以添加的一些常用shell命令。
- 注意事项
分布式文件系统的路径在命令行中,要从/开始写,即绝对路径。
2.1 创建目录
[-mkdir [-p] <path> ...] #在分布式文件系统上创建目录 -p,多层级创建
调用格式: hdfs dfs -mkdir (-p) /目录
例如:
- hdfs dfs -mkdir /data
- hdfs dfs -mkdir -p /data/a/b/c
2.2 上传指令
[-put [-f] [-p] [-l] <localsrc> ... <dst>] #将本地文件系统的文件上传到分布式文件系统
调用格式:hdfs dfs -put /本地文件 /分布式文件系统路径
注意: 直接写/是省略了文件系统的名称hdfs://ip:port。
例如:
- hdfs dfs -put /root/a.txt /data/
- hdfs dfs -put /root/logs/* /data/
其他指令:
[-moveFromLocal <localsrc> ... <dst>] #将本地文件系统的文件上传到分布式文件系统
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
2.3 创建空文件
hdfs dfs [generic options] -touchz <path> ...
调用格式:hdfs dfs touchz /hadooptest.txt
2.4 向分布式文件系统中的文件里追加内容
[-appendToFile <localsrc> ... <dst>]
调用格式:hdfs dfs -appendToFile 本地文件 hdfs上的文件
注意:不支持在中间随意增删改操作
2.5 查看指令
[-ls [-d] [-h] [-R] [<path> ...]] #查看分布式文件系统的目录里内容
调用格式:hdfs dfs -ls /
[-cat [-ignoreCrc] <src> ...] #查看分布式文件系统的文件内容
调用格式:hdfs dfs -cat /xxx.txt
[-tail [-f] <file>] #查看分布式文件系统的文件内容
调用格式:hdfs dfs -tail /xxx.txt
注意:默认最多查看1000行
2.6 下载指令
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
注意:本地路径的文件夹可以不存在
[-moveToLocal <src> <localdst>]
注意:从hdfs的某个路径将数据剪切到本地,已经被遗弃了
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
调用格式:同copyToLocal
2.7 合并下载
hdfs dfs [generic options] -getmerge [-nl] <src> <localdst>
调用格式:hdfs dfs -getmerge hdfs上面的路径 本地的路径
实例:hdfs dfs -getmerge /hadoopdata/*.xml /root/test.test
2.8 移动hdfs中的文件(更名)
hdfs dfds [generic options] -mv <src> ... <dst>
调用格式:hdfs dfs -mv /hdfs的路径1 /hdfs的另一个路径2
实例:hfds dfs -mv /aaa /bbb 这里是将aaa整体移动到bbb中
2.9 复制hdfs中的文件到hdfs的另一个目录
hdfs dfs [generic options] -cp [-f] [-p | -p[topax]] <src> ... <dst>
调用格式:hdfs dfs -cp /hdfs路径_1 /hdfs路径_2
2.10 删除命令
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
注意:如果删除文件夹需要加-r
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
注意:必须是空文件夹,如果非空必须使用rm删除
2.11 查看磁盘利用率和文件大小
[-df [-h] [<path> ...]] 查看分布式系统的磁盘使用情况
[-du [-s] [-h] <path> ...] #查看分布式系统上当前路径下文件的情况 -h:human 以人类可读的方式显示
2.12 修改权限的
跟本地的操作一致,-R是让子目录或文件也进行相应的修改
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
2.13 修改文件的副本数
[-setrep [-R] [-w] <rep> <path> ...]
调用格式:hadoop fs -setrep 3 / 将hdfs根目录及子目录下的内容设置成3个副本
注意:当设置的副本数量与初始化时默认的副本数量不一致时,集群会作出反应,比原来多了会自动进行复制.
2.14 查看文件的状态
hdfs dfs [generic options] -stat [format] <path> ...
命令的作用:当向hdfs上写文件时,可以通过dfs.blocksize配置项来设置文件的block的大小。这就导致了hdfs上的不同的文件block的大小是不相同的。有时候想知道hdfs上某个文件的block大小,可以预先估算一下计算的task的个数。stat的意义:可以查看文件的一些属性。
调用格式:hdfs dfs -stat [format] 文件路径
format的形式:
%b:打印文件的大小(目录大小为0)
%n:打印文件名
%o:打印block的size
%r:打印副本数
%y:utc时间 yyyy-MM-dd HH:mm:ss
%Y:打印自1970年1月1日以来的utc的微秒数
%F:目录打印directory,文件打印regular file
注意:
1)当使用-stat命令但不指定format时,只打印创建时间,相当于%y
2)-stat 后面只跟目录,%r,%o等打印的都是0,只有文件才有副本和大小
2.15 测试
hdfs dfs [generic options] -test -[defsz] <path>
参数说明: -e:文件是否存在 存在返回0 -z:文件是否为空 为空返回0 -d:是否是路径(目录) ,是返回0
调用格式:hdfs dfs -test -d 文件
实例:hdfs dfs -test -d /shelldata/111.txt && echo "OK" || echo "no"
解释:测试当前的内容是否是文件夹 ,如果是返回ok,如果不是返回no