- 有监督目标检测: 拥有大规模带标签的数据,包括完整的实例级别的标注,即包含坐标和类别信息;
- 弱监督目标检测: 数据集中的标注仅包含类别信息,不包含坐标信息,如图一 b 所示;
- 弱半监督目标检测: 数据集中拥有部分实例级别的标注,大量弱标注数据,模型希望利用大规模的弱标注数据提升模型的检测能力;
- 半监督目标检测: 数据集中拥有部分实例级别的标注,大量未标注数据,模型希望利用大规模的无标注的数据提升模型的检测能力;
半监督目标检测
- 一致性学习(Consistency based Learning)
- 伪标签(Pseudo-label based Learning)
https://paperswithcode.com/task/semi-supervised-object-detection
一致性学习
论文: Consistency-based Semi-supervised Learning for Object Detection (https://papers.nips.cc/paper/2019/hash/d0f4dae80c3d0277922f8371d5827292-Abstract.html)
代码:https://github.com/soo89/CSD-SSD (pytorch)
概要:
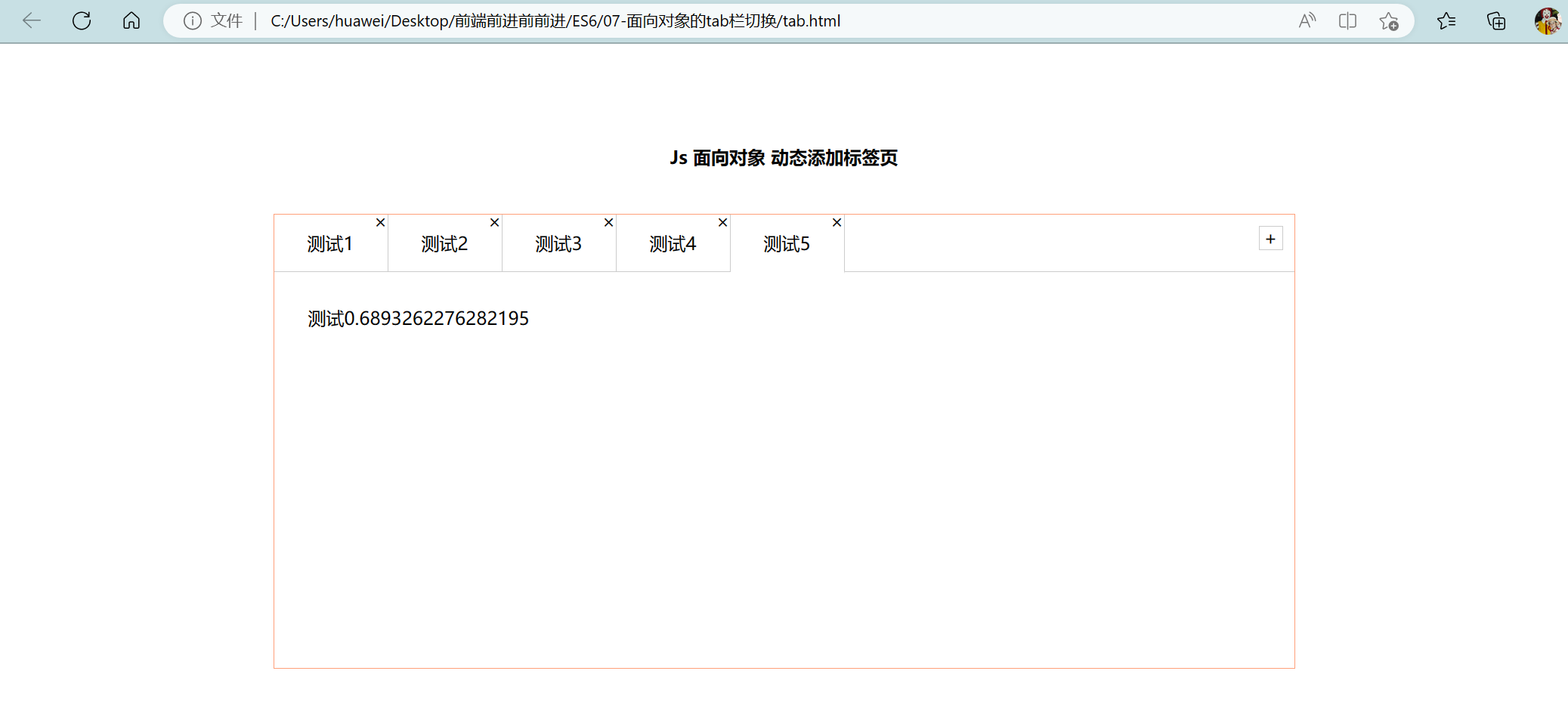
CSD训练的损失函数主要包括两个部分,labeled sample 的监督损失和 unlabeled samples 的 Consistency loss。针对 unlabeled samples,首先将图像水平翻转,然后分别送入网络当中,得到对应的 Feature map,由于两张翻转的图像的空间位置是可以一一对应的,因此可以在对应的位置计算一致性损失。分类部分,利用 JS 散度作为 consistency loss;定位部分,利用 L2 loss 作为 consistency loss。
通过数据增强计算无标签数据集的一致性损失
伪标签
- 论文:A Simple Semi-Supervised Learning Framework for Object Detection (https://arxiv.org/abs/2005.04757)
代码:https://github.com/google-research/ssl_detection(tensorflow)
概要:
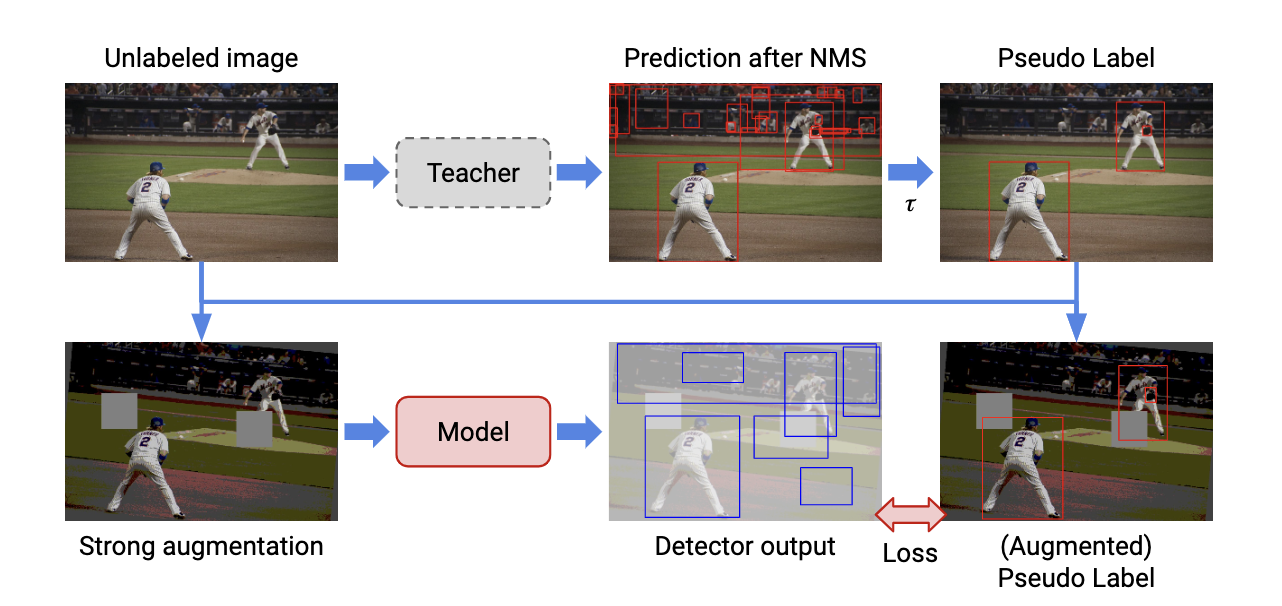
- 首先利用 labeled data 训练一个 Teacher 模型;
- 生成 pseudo label, 将 unlabeled data 输入进 Teacher 网络中,得到大量的目标框预测结果,利用 NMS 消除大量的冗余框,最后使用阈值来挑选高置信度的 pseudo label;
- 应用 strong data augmentation。得到 pseudo label 后与 unlabeled image 图像相结合,包括图像级别的颜色抖动、geometric transformation(平移、旋转、剪切)、box-level transformation(小幅度的平移、旋转、剪切);
- 计算无监督 loss (pseudo label)和监督学习 loss
类似于蒸馏,使用Teacher网络对无标签数据打伪标签,用于训练Student网络

2 论文:Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework (https://arxiv.org/abs/2103.11402)
代码:未开源
概要:
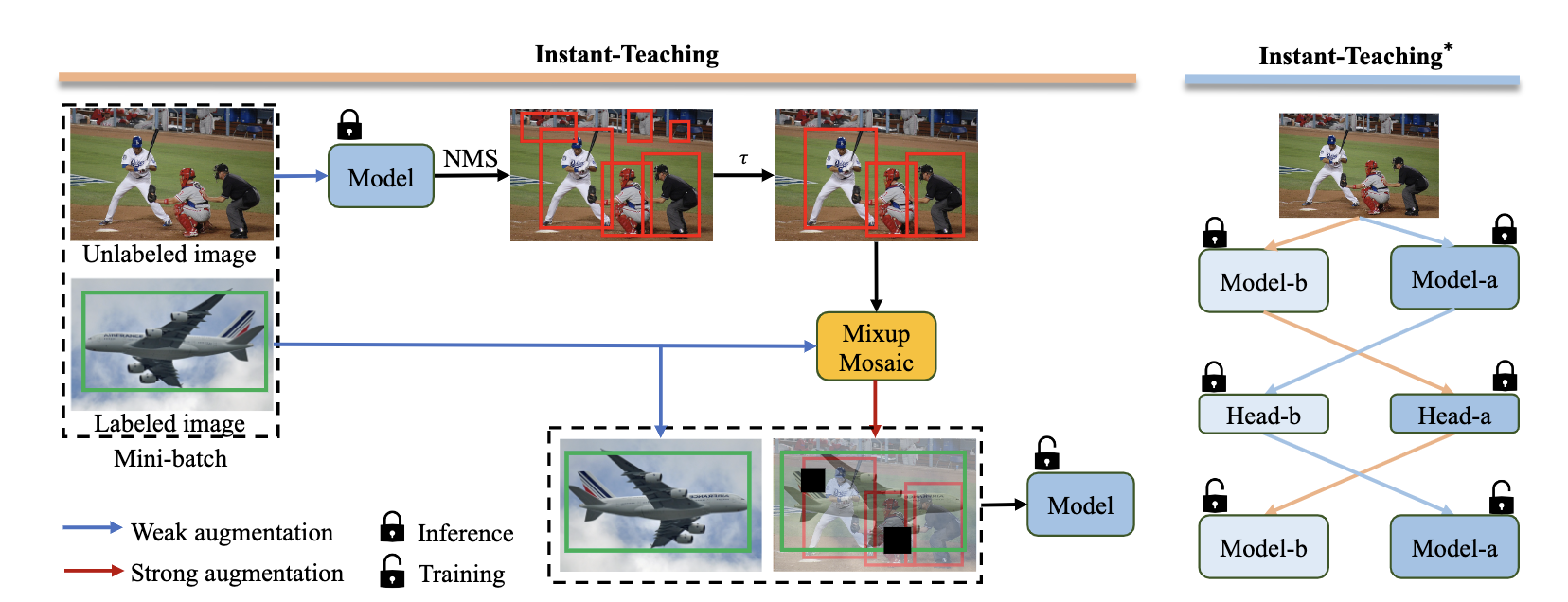
- 采用在线伪标注更新的方式。随着模型训练收敛,模型的精度提升的同时,在线生成的pseudo labels的质量也会得到及时的提高,从而反过来进一步促进模型的学习。
- 为了更有效的对unlabel images 进行数据增强,采用在labeled images 和 unlabeled images 之间进行Mixup和Mosaic增强。
- 针对confirmation bias 问题,提出了Co-rectify的方案,即同时训练两个模型,两个模型分别为彼此检查和纠正pseudo labels,从而有效抑制错误预测的累积,提高模型精度。值得注意的是,虽然在训练时,需要同时训练两个模型,但是infernece时,只需要使用单个模型即可,因此,不影响模型推理的速度
主要在SATC的基础上进行修改,Teacher网络在训练中会进行更新

3 论文:Unbiased Teacher for Semi-Supervised Object Detection (https://arxiv.org/abs/2102.09480)
代码:https://github.com/facebookresearch/unbiased-teacher (pytorch)
概要:
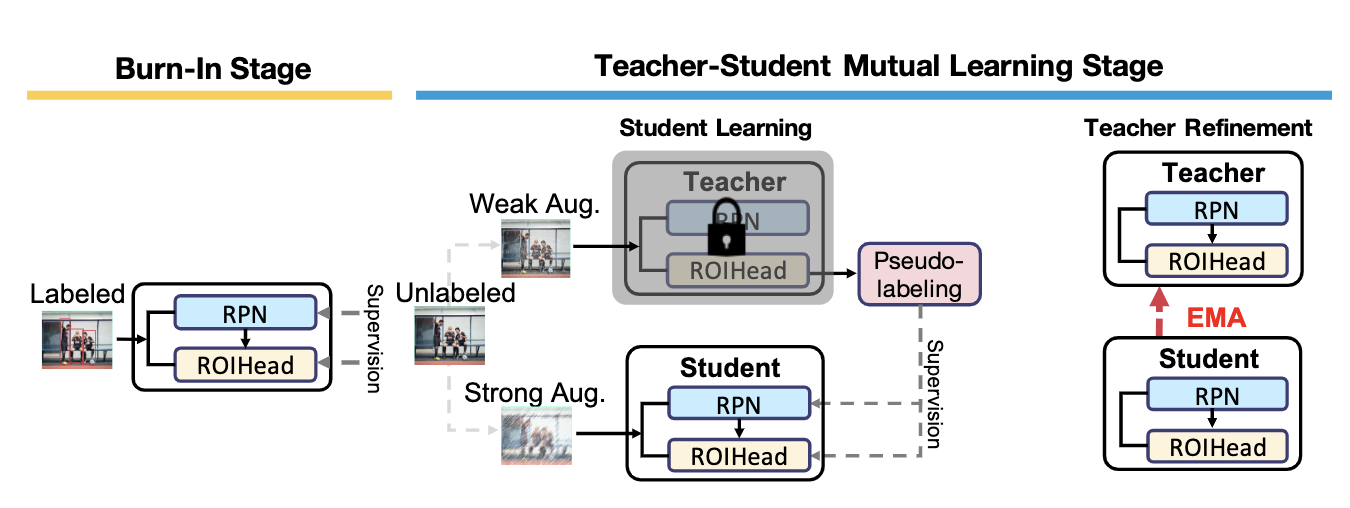
一开始训练用标注数据(burn-in),联合训练包括两步:固定teacher产生伪标注,用以训练student,而基于exponential moving average (EMA),学习的知识迁移给渐渐进步的teacher。半监督目标检测算法生成的标签具有 bias,将原本的 cross entropy loss 替换为 Focal loss 来解决 pseudo label bias 问题,即 class imbalance
主要在SATC的基础上进行修改,Teacher网络在训练中进行更新和Focal loss
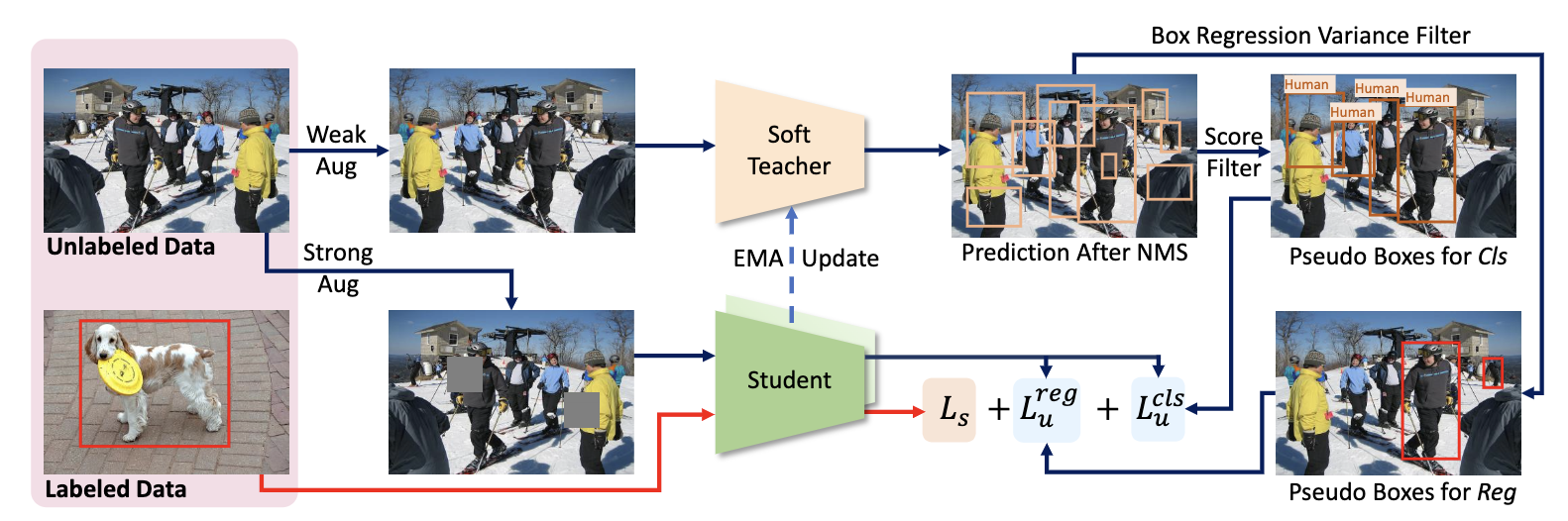
4 论文:End-to-End Semi-Supervised Object Detection with Soft Teacher (https://arxiv.org/abs/2106.09018)
代码:https://github.com/microsoft/SoftTeacher (pytorch mmdetection)
概要:
-
教师模型和学生模型是两个完全相同的结构,因为要进行 EMA 更新,两者都是带有预训练的随机初始化
-
有标签图片采用常规的 pipeline 流程,利用学生模型进行预测,计算得到有标签的 loss,包括分类和回归分支 loss
-
参考 FixMatch 做法,无标签数据会经过强和弱两种不同的 aug pipeline,其中弱增强线输入到教师模型,而强增强线用于学生模型
-
使用可靠性度量来加权每个“背景”候选框的损失,而实测发现教师模型产生的背景检测分数可以很好地作为可靠性度量。这种监督方式实测效果远好于 hard 标签(按阈值筛选)训练方式,所以本文才称为 soft teacher
-
通过框抖动 box jittering 选择可靠的边界框来训练学生模型的定位分支,这种方法首先多次抖动伪前景框候选; 然后在利用教师模型对这些抖动框进行回归(实际上是 rcnn 分支进一步 refine ),并将这些回归框的方差用作可靠性度量;最后将具有足够高可靠性的 box 候选用于学生定位分支的训练。
-
强增强线学生模型的无标签分类和回归分支的伪标签是不一样的。教师模型采用 Mean teachers 方法进行更新
和论文3类似,对Teacher网络在训练中进行更新,增加了soft teacher 和 box jittering trick来提升效果

6 论文:Towards Open World Object Detection (https://arxiv.org/abs/2103.02603)
代码:https://github.com/JosephKJ/OWOD (pytorch)
概要:
- 在没有提供相关监督的情况下将无法分类的目标检测出来标记为unknown (对RPN中与GT的IOU不高的,但是softmax分数很高的进行排序,取k个作为潜在的未知物体)
- 能够在后续提供这些标签时,不忘记之前的类别同时渐进地学得这些unknown的类别
概要
- 在没有显式监督的情况下确认未知目标;
- 步进地学习这些确认的未知类,这些对应数据的标注渐进地收到,这样能够不会忘记之前学习的类。ORE(Open World Object Detector), 主要是基于一种聚类,即contrastive clustering,和基于能量的模型,即Energy based models (EBMs),对未知目标确认。
对RPN输出的ROI特征聚类,并且修改了分类层为能量模型,比较适合增量训练