文章目录
- 1. 分区副本分配
- 2. 手动调整分区副本
- 3. Leader Partition 负载平衡
- 4. 增加副本因子
1. 分区副本分配
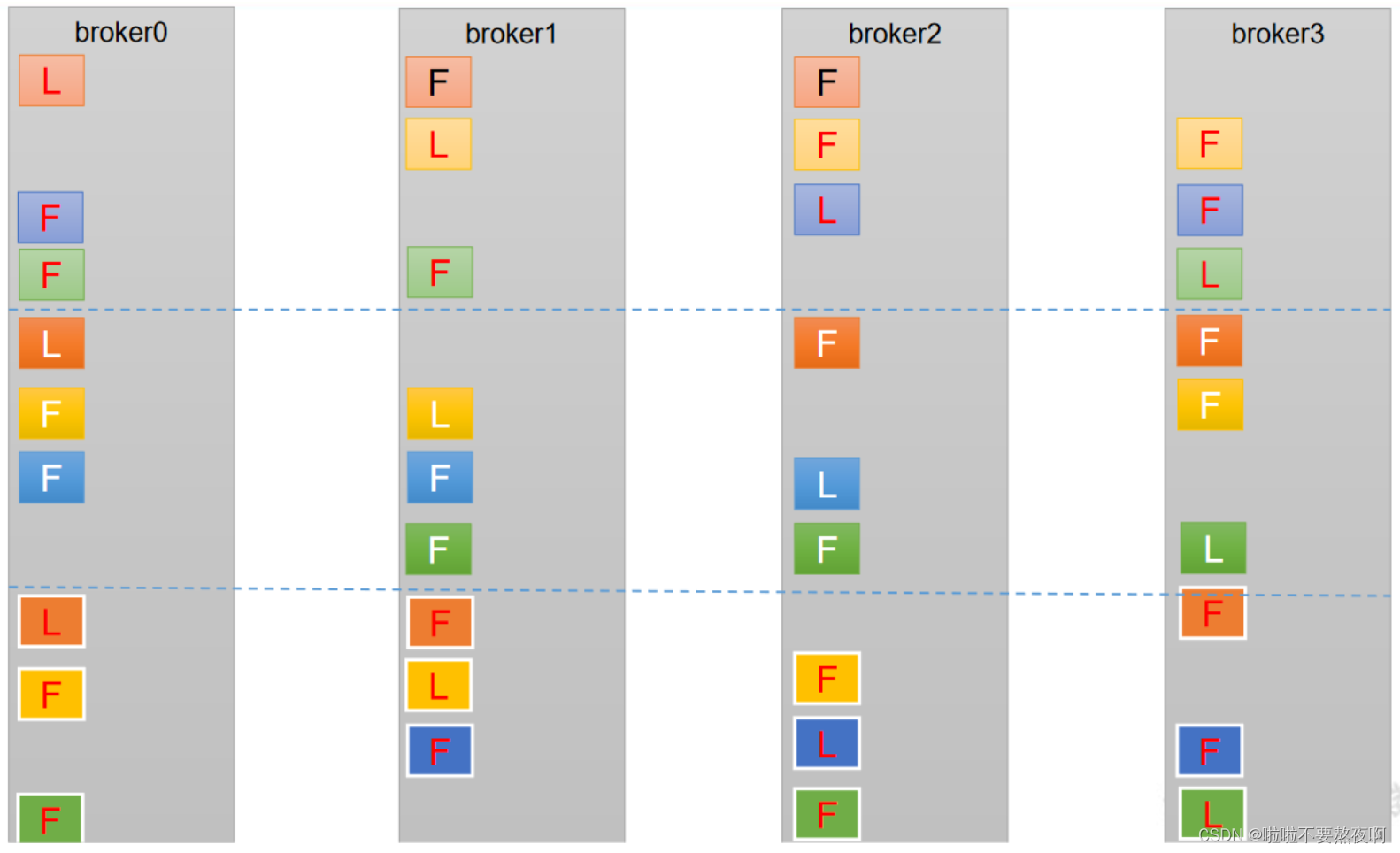
如果 kafka 服务器只有 4 个节点,那么设置 kafka 的分区数大于服务器台数,在 kafka底层如何分配存储副本呢?
① 创建 16 分区,3 个副本
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --create --partitions 16 --replication-factor 3 --topic test4
② 查看分区和副本情况
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic test4
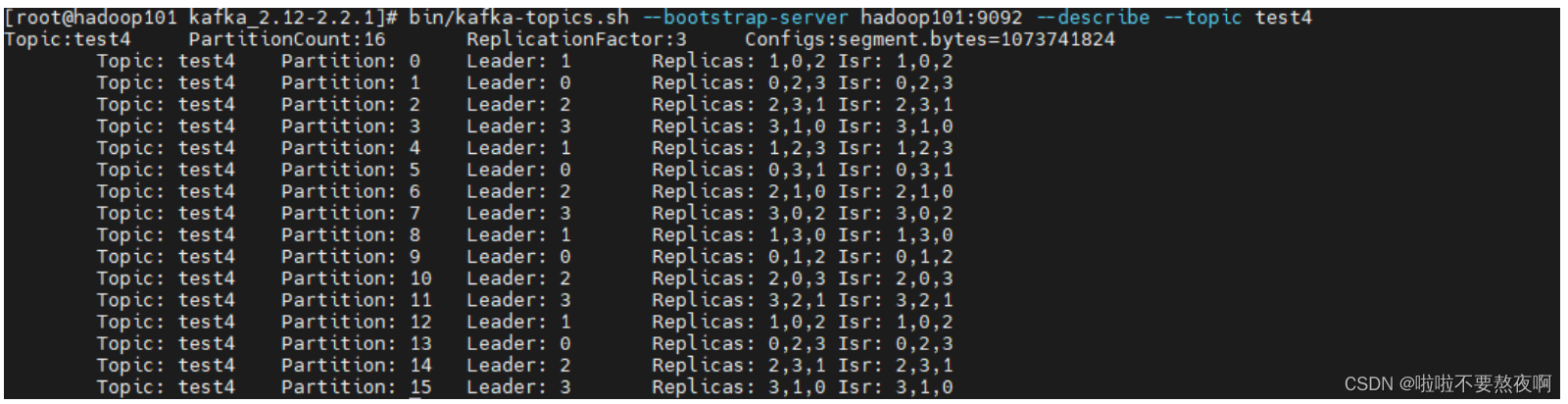
这样是为了leader和follower均匀的分配在每个服务器上,尽量不让每个分区的leader和follower都分配在某几个服务器上,比如只分配在broker0、broker1、broker2上,那么这三个服务器挂掉后,数据就丢失了,这样分配的好处是除非四个服务器都挂掉,不然就还可以从broker3同步数据。
2. 手动调整分区副本
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
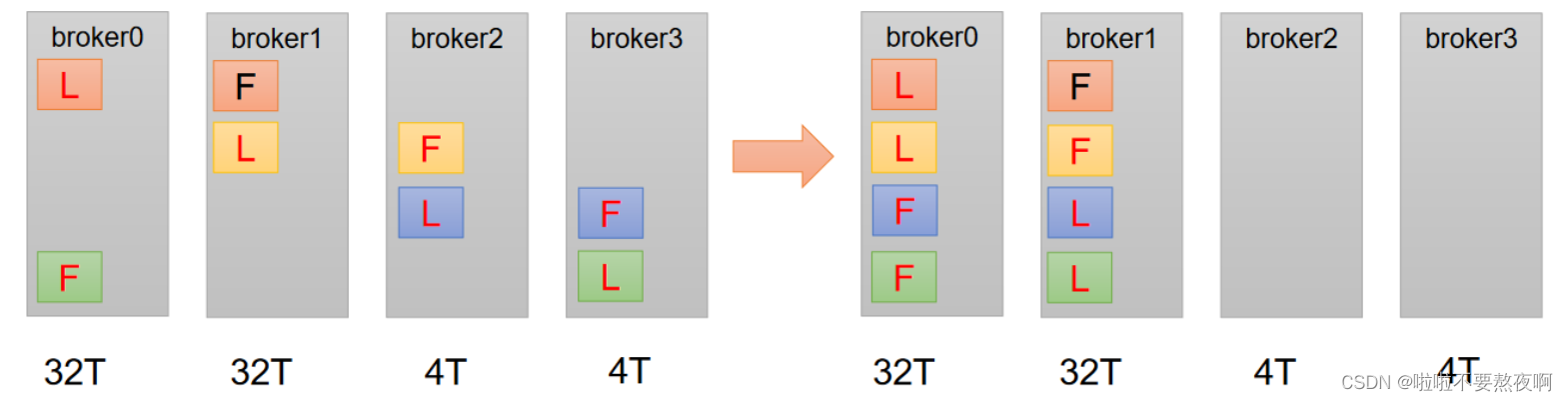
创建一个新的topic,4个分区,两个副本,将该topic的所有副本都存储到broker0和broker1两台服务器上。
手动调整分区副本存储的步骤如下:
① 创建一个新的topic,4个分区,两个副本
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --create --partitions 4 --replication-factor 2 --topic test5
② 查看分区副本存储情况
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic test5

③ 创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)
[root@hadoop101 kafka_2.12-2.2.1]# vi increase-replication-factor.json
{
"version":1,
"partitions":[{"topic":"test5","partition":0,"replicas":[0,1]},
{"topic":"test5","partition":1,"replicas":[0,1]},
{"topic":"test5","partition":2,"replicas":[1,0]},
{"topic":"test5","partition":3,"replicas":[1,0]}]
}
④ 执行副本存储计划
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test5","partition":2,"replicas":[3,1],"log_dirs":["any","any"]},{"topic":"test5","partition":1,"replicas":[2,3],"log_dirs":["any","any"]},{"topic":"test5","partition":3,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"test5","partition":0,"replicas":[0,2],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
⑤ 验证副本存储计划
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition test5-0 completed successfully
Reassignment of partition test5-1 completed successfully
Reassignment of partition test5-2 completed successfully
Reassignment of partition test5-3 completed successfully
⑥ 查看分区副本存储情况
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic test5

3. Leader Partition 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
① auto.leader.rebalance.enable,默认是true。自动Leader Partition 平衡
② eader.imbalance.per.broker.percentage,默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。
③ leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。
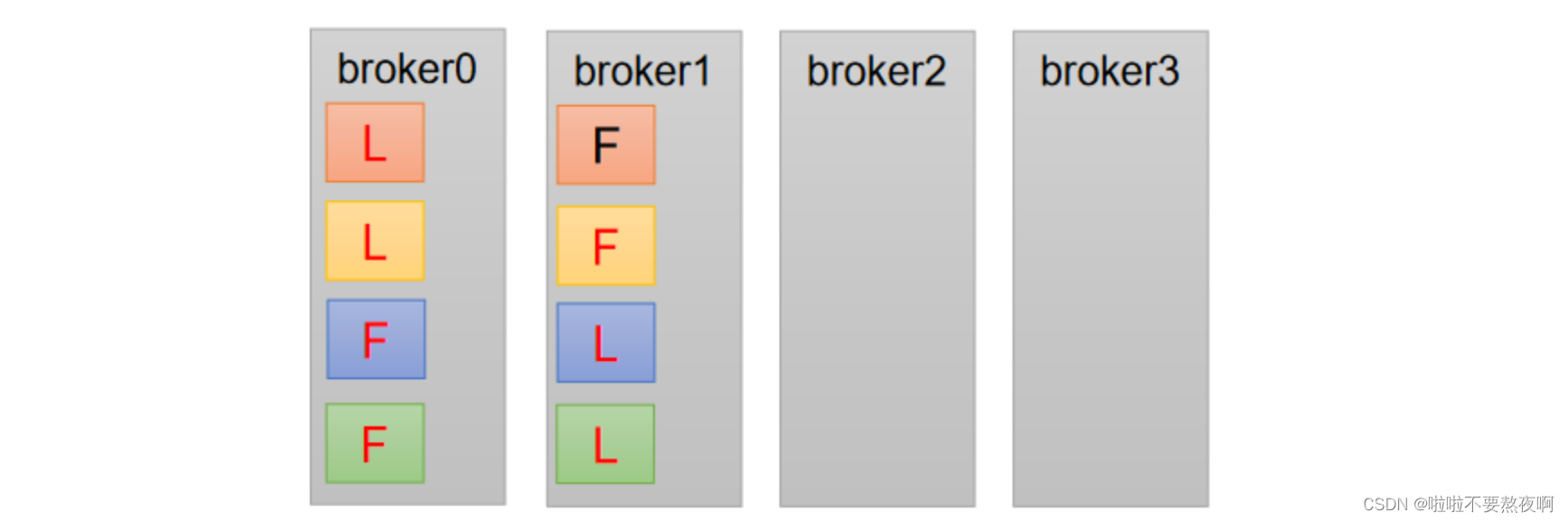
下面拿一个主题举例说明,假设集群只有一个主题如下图所示:

针对broker0节点,分区2的AR优先副本是0节点,但是0节点却不是Leader节点,所以不平衡数加1,AR副本总数是4,所以broker0节点不平衡率为1/4>10%,需要再平衡。
broker2和broker3节点和broker0不平衡率一样,需要再平衡,broker1的不平衡数为0,不需要再平衡。
4. 增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
① 创建 topic
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --create --partitions 3 --replication-factor 1 --topic test6
② 创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)
[root@hadoop101 kafka_2.12-2.2.1]# vi increase-replication-factor.json
{
"version":1,
"partitions":[{"topic":"test6","partition":0,"replicas":[0,1,2]},
{"topic":"test6","partition":1,"replicas":[0,1,2]},
{"topic":"test6","partition":2,"replicas":[0,1,2]}]
}
③ 执行副本存储计划
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test6","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"test6","partition":1,"replicas":[1],"log_dirs":["any"]},{"topic":"test6","partition":0,"replicas":[3],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
⑤ 验证副本存储计划
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition test6-0 completed successfully
Reassignment of partition test6-1 completed successfully
Reassignment of partition test6-2 completed successfully
⑥ 查看分区副本存储情况
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic test6
Topic:test6 PartitionCount:3 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: test6 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,2,1
Topic: test6 Partition: 1 Leader: 1 Replicas: 0,1,2 Isr: 1,2,0
Topic: test6 Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,2,1
![[附源码]计算机毕业设计springboot高校学生宿舍管理系统](https://img-blog.csdnimg.cn/66f009a62de9431caf25c20c5259e2c5.png)
![[附源码]计算机毕业设计springboot港口集团仓库管理系统](https://img-blog.csdnimg.cn/6fb308034bb049abab0a85d1118d05f9.png)


![[附源码]计算机毕业设计SpringBoot海南与东北的美食文化差异及做法的研究展示平台](https://img-blog.csdnimg.cn/6bd78494217845f5821e685b27a05df8.png)